





有朋友问了我如下这样一个问题,最后的解决过程挺有意思的,让我发现了直方图统计信息里我之前没有注意到的两个知识点,这里跟大家分享一下。
数据库的版本是11.2.0.3:
创建一个测试表T1:
SQL> create table t1 as select *
from dba_users;
Table created
从如下查询结果中我们可以看到,表T1的OBJECT_ID是104192:
SQL> select object_id from dba_objects
where owner=’SCOTT’
and object_name=’T1′;
OBJECT_ID
——————-
104192
表T1的列user_id所对应的INTCOL#是2:
SQL> select name,intcol# from sys.col$
where obj#=104192
and name=’USER_ID’;
NAME INTCOL#
—————— ———-
USER_ID 2
从如下结果里可以看到,SYS.COL_USAGE$现在还没有列USER_ID的使用记录:
SQL> select obj#,intcol#,
equality_preds
from sys.col_usage$
where obj#=104192;
OBJ# INTCOL# EQUALITY_PREDS
我们现在来使用一下列USER_ID:
SQL> select count(*) from t1
where user_id=5;
COUNT(*)
—————–
1
使用完后,我们发现SYS.COL_USAGE$还是没有列USER_ID的使用记录:
SQL> select obj#,intcol#,
equality_preds
from sys.col_usage$
where obj#=104192;
OBJ# INTCOL# EQUALITY_PREDS
———- ———- ————–
这个是正常的,这里不是没有列USER_ID的使用记录,是已经有了但只是还没有被持久化到SYS.COL_USAGE$中,这里需要我们手工执行一下dbms_stats.gather_table_stats,这样就能将USER_ID的使用记录flush到SYS.COL_USAGE$中了,然后我们就能看到了:
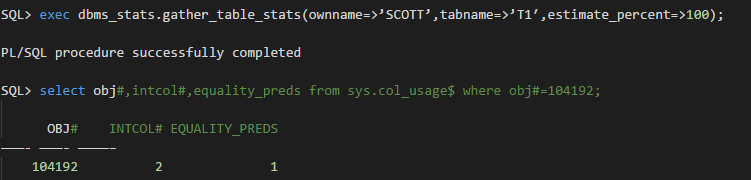
但现在的问题是无论我们怎么执行dbms_stats.gather_table_stats,列user_id上的直方图统计信息就是没有(这也是那位朋友问的问题):
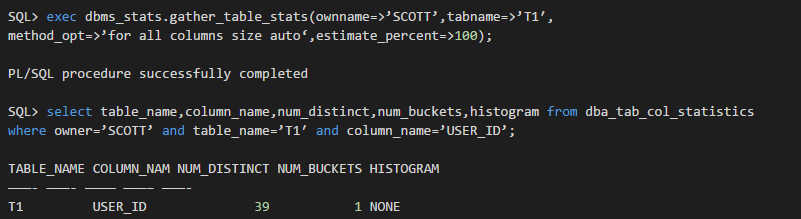
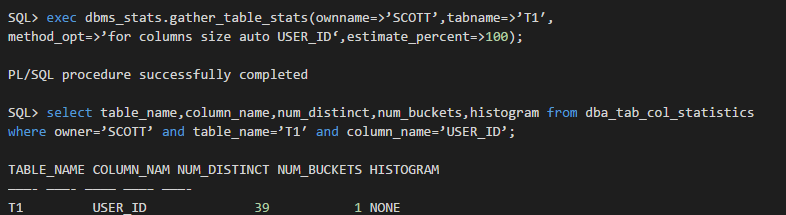
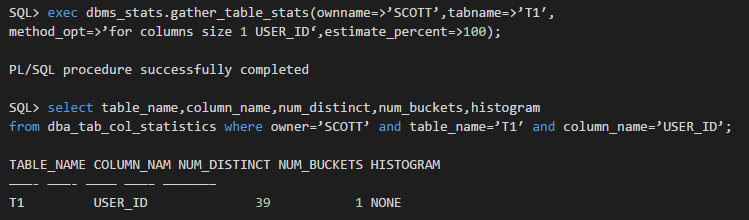
这里除非我们手工指定user_id列所用的bucket的数量:
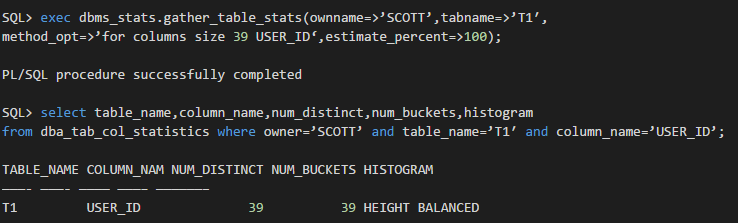
手工指定了直方图统计信息的bucket的数量为39后,明明列user_id的distinct值的数量也是39,为什么这里直方图的类型居然是HEIGHT BALANCED?按道理讲应该是FREQUENCY啊!
当看到上述测试结果的时候,我意识到一定是什么地方出了问题。
因为上述现象的出现已经颠覆了我之前对直方图统计信息的如下两个认识:
1、我原先一直以为如果METHOD_OPT的值是默认的“FOR ALL COLUMNS SIZE AUTO”的话,那么只要SYS.COL_USAGE$中有目标列的使用记录,则Oracle在自动收集直方图统计信息的时候就会去收集该列的直方图统计信息;
2、在手工收集直方图统计信息的时候,如果我手工指定的bucket的数量等于目标列的distinct值的数量,且这个值是小于等于254的话,那么Oracle此时收集的直方图统计信息的类型应该是FREQUENCY。

到底是什么地方出了问题?
我们来复习一下Oracle关于自动收集直方图统计信息的定义:
Oracle在“SIZE Clause in METHOD_OPT Parameter of DBMS_STATS Package (Doc ID 338926.1)”中明确指出,METHOD_OPT的值中的AUTO的含义为如下所示:
AUTO: Oracle determines the columns to collect histograms based on data distribution and the workload of the columns.
这里的“workload of the columns”指的应该就是目标列是否在SYS.COL_USAGE$中有使用记录。
注意到Oracle这里还提到了另外一个条件——“based on data distribution”(这也是我之前没有注意到的条件),但这里的具体含义是什么?
“based on data distribution”直译过来就是目标列数据的分布。说白了就是目标列的数据分布确实得是倾斜的,只有满足这个前提条件,再加上该目标列在SYS.COL_USAGE$中有使用记录,Oracle在自动收集直方图统计信息的时候才会对该列收集直方图统计信息。
Oracle是怎么来判断某列的数据分布是否是倾斜的呢?
就是判断目标列的distinct值的数量是否和目标表的数据量相同,如果相同,Oracle就认为该列的数据分布不是倾斜的,否则就是倾斜的。
如果目标列的distinct值的数量和目标表的数据量相同,即使该目标列在SYS.COL_USAGE$中有使用记录,Oracle在自动收集直方图统计信息的时候也不会对该列收集直方图统计信息。
搞清楚了上述知识点,那位朋友问的问题自然就有答案了——对于表T1的列user_id而言,其distinct值的数量和表T1的数据量相同,所以这里即使user_id在SYS.COL_USAGE$中有使用记录,Oracle在自动收集直方图统计信息的时候也不会对user_id收集直方图统计信息:
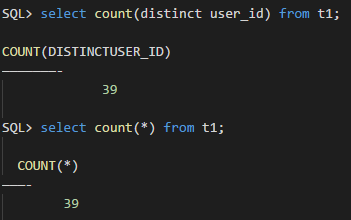
现在我们来验证一下上述理论,往表T1中插入一条记录,使得user_id的distinct值的数量小于表T1的数据量,这样当我们再次对表T1收集统计信息的时候,user_id列的直方图统计信息应该就有了。
先把之前对user_id列手工指定bucket数量收集的直方图统计信息删掉:
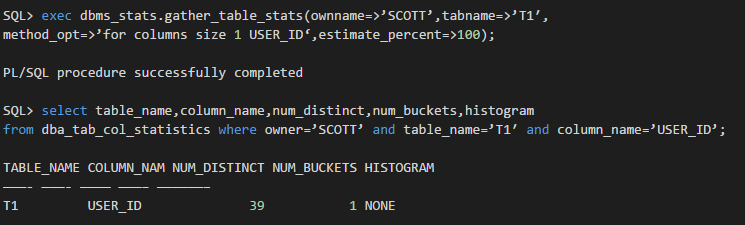
对表T1插入一条user_id列的值和现有值重复的记录:
SQL> insert into t1 select *
from t1 where user_id=5;
1 row inserted
SQL> commit;
Commit complete
现在user_id列的distinct值的数量已经小于表T1的数据量了:
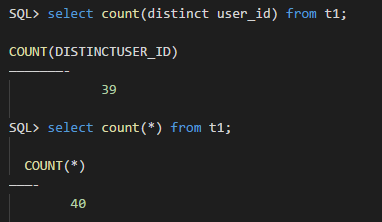
此时对表T1再次收集统计信息:
SQL> exec dbms_stats.
gather_table_stats
(ownname=>’SCOTT’,
tabname=>’T1′,estimate_percent=>100);
PL/SQL procedure successfully completed
从如下查询结果里我们可以看到,现在user_id列上终于有了直方图统计信息,且其类型就是FREQUENCY,这就和我们以前的认知匹配上了,同时也验证了我们刚才的分析结论:

再次删除user_id列上的直方图统计信息:
我们再次以手工指定bucket数量的方式收集user_id列上的直方图统计信息:
SQL> exec dbms_stats.gather_table_stats
(ownname=>’SCOTT’,tabname=>’T1′,
method_opt=>’for columns size 39 USER_ID‘,estimate_percent=>100);
PL/SQL procedure successfully completed
从如下查询结果我们可以看到,现在user_id列上的直方图统计信息的类型已经不是之前的HEIGHT BALANCED了,而是变成了FREQUENCY:

这说明我们之前的认识(在手工收集直方图统计信息的时候,如果我手工指定的bucket的数量等于目标列的distinct值的数量,且这个值是小于等于254的话,那么Oracle此时收集的直方图统计信息的类型应该是FREQUENCY)成立的前提条件是该列的数据分布是倾斜的。
通过这篇文章,我们介绍了如下两个关于直方图统计信息的有趣知识点:
1、如果目标列的distinct值的数量和目标表的数据量相同,即使该目标列在SYS.COL_USAGE$中有使用记录,Oracle在自动收集直方图统计信息的时候也不会对该列收集直方图统计信息;
2、在手工收集直方图统计信息的时候,如果我手工指定的bucket的数量等于目标列的distinct值的数量,且这个值是小于等于254的话,那么Oracle此时收集的直方图统计信息的类型应该是FREQUENCY——这个结论成立的前提条件是该列的数据分布是倾斜的。
分享
【线上分享 第48期】Spark 背景介绍
恩墨大数据讲堂每周三八点与您相约。恩墨大讲堂邀请恩墨学院大数据产品总监孟硕老师,为你讲述Spark 背景介绍 。主要为您阐述:
1、 Spark 组件产生的原因;2、 Spark 组件在大数据生态系统中的位置;3、 Spark 组件在大数据生态系统中的作用;
参与方式:扫描下图的二维码。


