




内容整理自2019年7月21日巨杉TechDay技术沙龙活动。
在All in Cloud的云计算时代,业务和应用正在不断“云化”。大型金融企业,例如互金和银行等,需要基础软件和数据平台能够实现原生的云化,以满足微服务架构的需求。本次演讲将主要探讨数据库在云化架构下的技术与架构设计实践。

演讲实录

今天主要跟大家分享一下云架构下分布式数据库的设计和实践的技术点。

>>>微服务需求下数据库的演进
在微服务架构下,我们可以看到,对数据库访问的模式发生了变迁。这时候的数据库应该如何设计,以应用微服务架构的变迁呢?目前业界有三种方法:
第一种办法是集中数据库存储。这样的话,每个微服务从数据接口上的访问不需要多少变化,可以快速适配。而它带来的不足就是,数据集中存储在后端数据库上,数据解耦合,每个微服务之间互相会有影响。一来影响数据读取本身,二是资源,对数据访问模式不一样,对分析、高并发、低延时会有影响。而且集中数据库存储后,数据弹性扩张会有问题,传统的数据库更换还会导致所有微服务都受到影响。
第二种办法是每一个微服务拥有独立存储。当每个微服务都有其独立的数据库之后,开发微服务变得非常简单。但同样会带来几个问题:一是每个微服务独立数据库存储后,每个企业有成百上千的微服务,我应该如何做统一的治理,统一的数据视图。像有些互联网厂商,有2万多个MySQL数据库,管理成本非常高。二是这么多数据,里面有一些数据要共享、重用,数据产生严重的碎片化。
而第三种办法,原生分布式数据库也就应运而生,其架构相较于以上两种架构的优势在于两点。第一是解决了数据的弹性扩张问题,使每个微服务不受底层数据存储限制。第二,解决微服务应用架构中数据严重碎片化的问题。同时,分布式数据库技术趋势需要从传统技术兼容性以及新技术前瞻性两个维度进行评判,其中ACID数据安全与SQL完整性是传统技术兼容性的重要指标,而弹性扩展能力、多模式引擎、以及HTAP则是新技术前瞻性的几个重要衡量标准。
那么在云架构下对分布式数据库的架构有什么要求呢?接下来我会详细谈谈巨杉数据库在整个架构和数据库能力上,如何应对云架构下的挑战。
>>>巨杉数据库架构
巨杉数据库的逻辑架构,底层是统一的分布式存储层,可以看做是资源池,也是可弹性伸缩的数据库平台。上层是数据库接口层——也就是实例,我们可以创建成千上万个数据库实例,并且可以根据业务接口选择MySQL,PostgreSQL或SparkSQL实例。同时还包括非结构化的实例,例如S3或者文件系统。底层数据统一存储在分布式存储层,上层业务可以直接访问数据库实例。数据库实例可以做到动态扩容,微服务在云架构下可以不断的根据动态调度。一个微服务可以创建一个数据库实例,形成可共享的数据库实例组。而在某一个微服务上创建一个表,另一个微服务也一样可用,保证了数据在数据库实例层的共用。
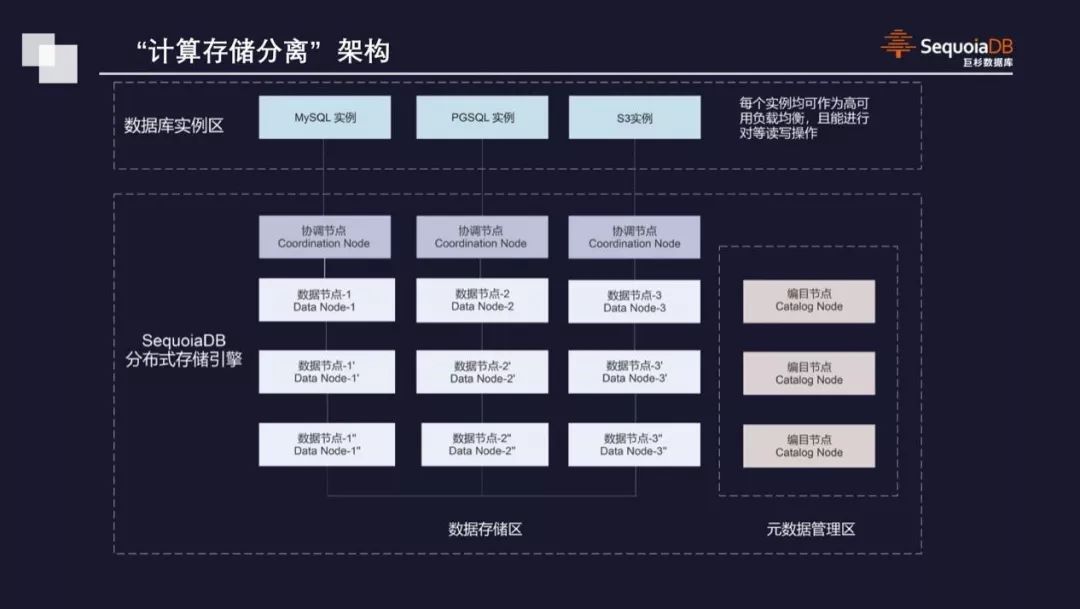
在我们的底层架构,数据库实例组通过协调节点做到负载均衡。在分布式数据库的底座上有一层协调节点,这一层负责分布式数据库的路由和数据库计算。右边是分布式元数据管理,一个元数据换了,另一个元数据自然有人接管。每一页都有分区,这是分布式存储节点。每一个分区下有很多个数据节点,在一个分区内是一主多从的方式来保持数据的一致。当一个分区内的主节点故障后,根据选举算法产生新的主节点。水平扩容很简单,纵向增加分区,存储能力可以不断扩张。纵向是一个分区内可以加副本,保证数据纵向数据中副本的控制,保证数据性能和数据的可靠性。
>>>巨杉数据库技术特性
接下来谈谈SequoiaDB巨杉数据库的技术优势:
>>数据分片能力
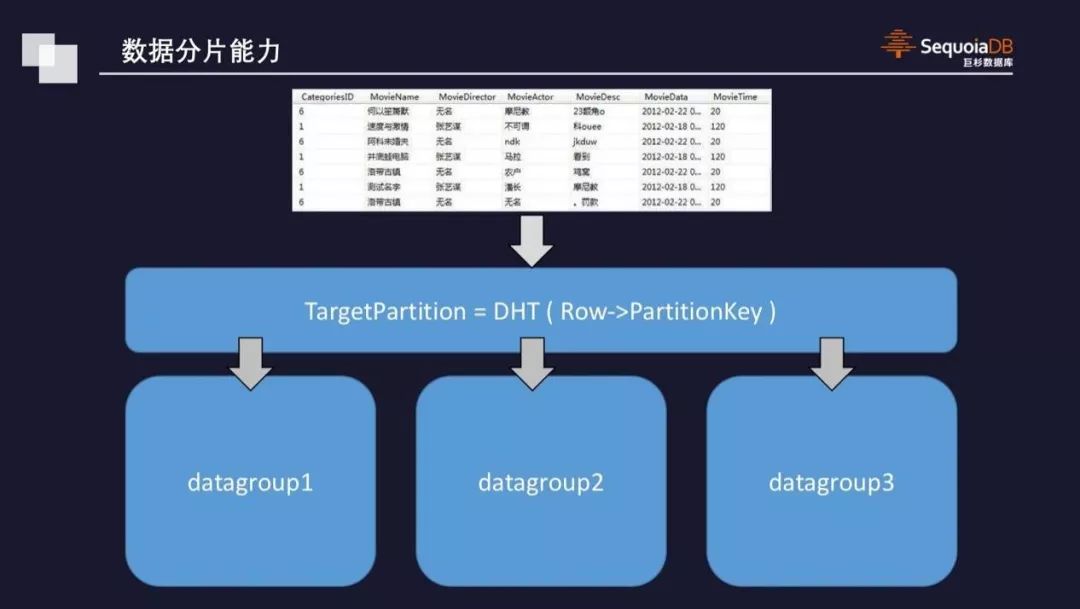
这是分布式数据库的基本能力。要实现数据水平扩张和弹性伸缩,数据就要做分区。分区后,我们采用的是比较典型的哈希算法,将数据映射到分区上。
>>高可用和一致性的能力
一个分区是以一主多从的方式,保证数据绝对的一致。选举机制可以保障分区组中,随时只存在一个主节点。当该主节点宕机后会在其余从节点之间自动选举出主节点,进行读写操作。所以,选举机制的核心为节点状态监测。分区组内所有的节点会定期向组内其它成员发送自身状态,当主节点宕机后,所有的从节点间会进行投票,当时最匹配原主节点的节点即当选新的主节点。选举成功的前提条件是,为了避免“双主”问题,组内必须拥有超过半数以上的节点参与投票,否则将无法进行选举。任何时刻如果组内成员不足半数,则当前的主节点会自动降级为从节点,同时断开当前节点的所有用户连接。
>>水平扩展能力
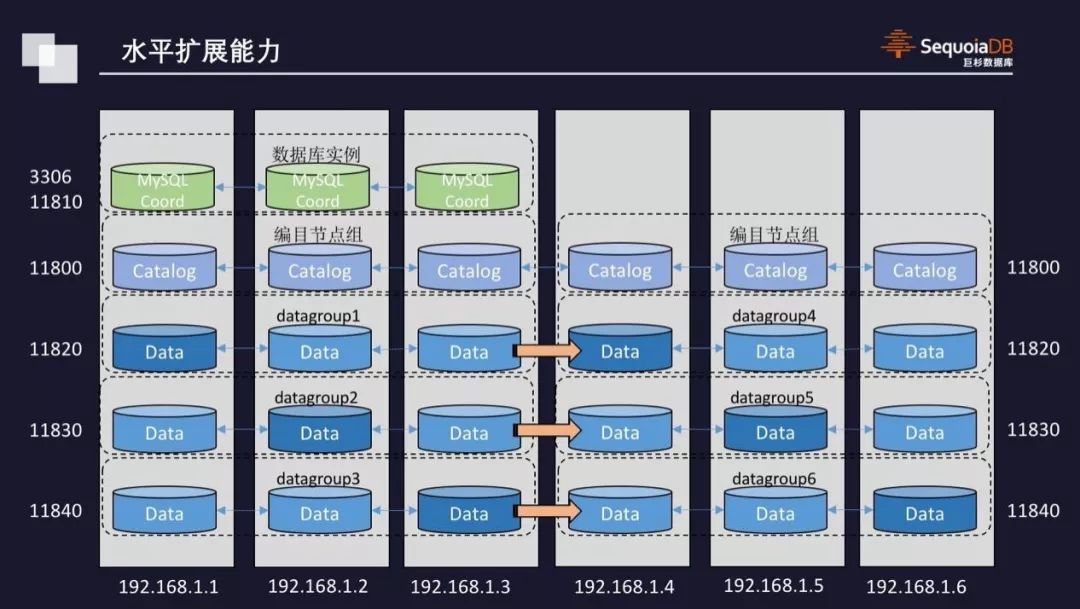
一个集群中可以配置多个分区组。通过增加分区组,充分利用物理设备进行水平扩展,SequoiaDB 可以做到线性的水平扩展能力。
>>MySQL兼容能力
SequoiaDB 巨杉数据库100%兼容行业标准的MySQL、PostgreSQL以及SparkSQL语法及协议。从兼容层面来讲,主要是三个方面:一是语法的兼容,传统的应用基于这个语法,不需要改动。二是通讯协议,不仅要兼容应用接口能跑、能运行,还要从体系工具上兼容。三是访问计划,对访问计划进行兼容,包括统计信息的收集、访问结构的完全兼容。
>>HTAP读写分离能力
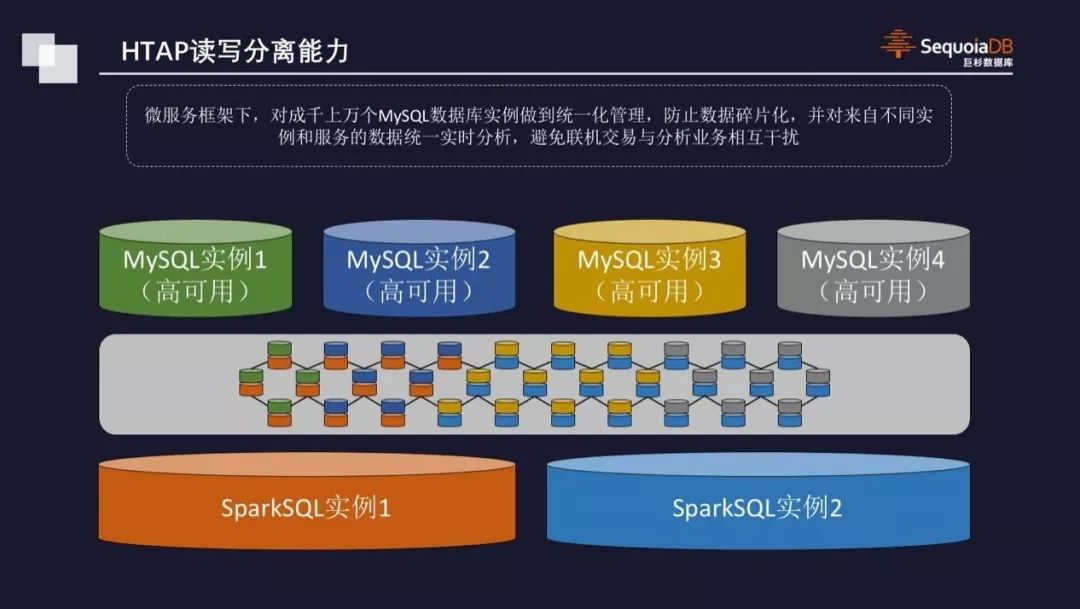
SequoiaDB通过SQL的完全支持以及Spark的整合,实现HTAP混合事务和分析处理,快速实现业务应用的弹性开发,应对更多复杂应用场景。同时,通过分布式数据库多副本机制,将在线交易和离线分析业务物理隔离,实现同一组数据在应对不同类型业务时互不干扰。
>>多租户多模能力
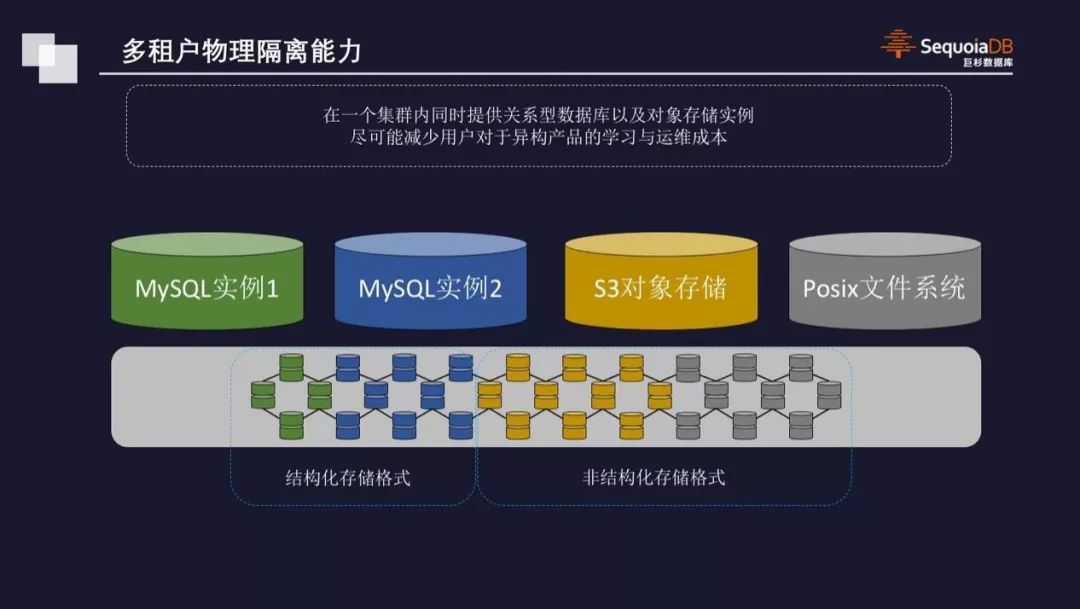
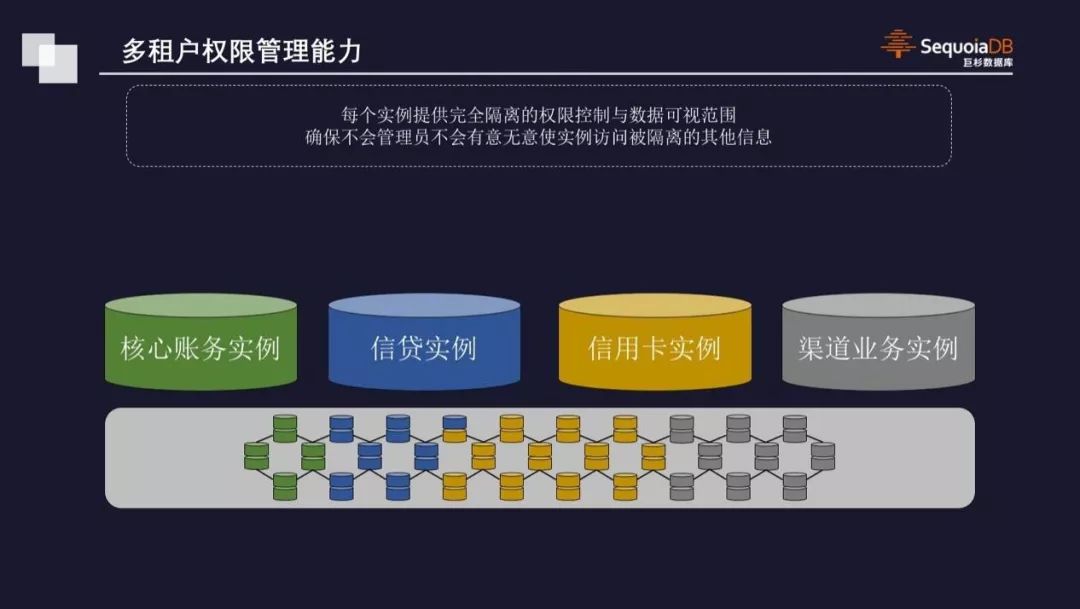
对于分布式数据库来说,其存在的价值,不仅仅在于解决单点数据量大的问题。在应用程序微服务化的今天,分布式数据库需要以一种平台化(PaaS)的形式,对上层大量的应用与微服务同时提供数据访问能力。在这种情况下,做到不同微服务之间所对应的底层数据逻辑与物理隔离,可以保障云环境中分布式数据库安全、可靠和性能稳定。在 SequoiaDB 巨杉数据库中,数据域可以用于在复杂集群环境中,对资源进行逻辑和物理的划分与隔离。例如,在极为重要的核心交易型账务类应用中,可以将其物理资源与审计后督类业务完全隔离,以确保不管在任何情况下,审计类业务的复杂压力都不会影响到核心账务系统的稳定运行。
>>多中心容灾能力
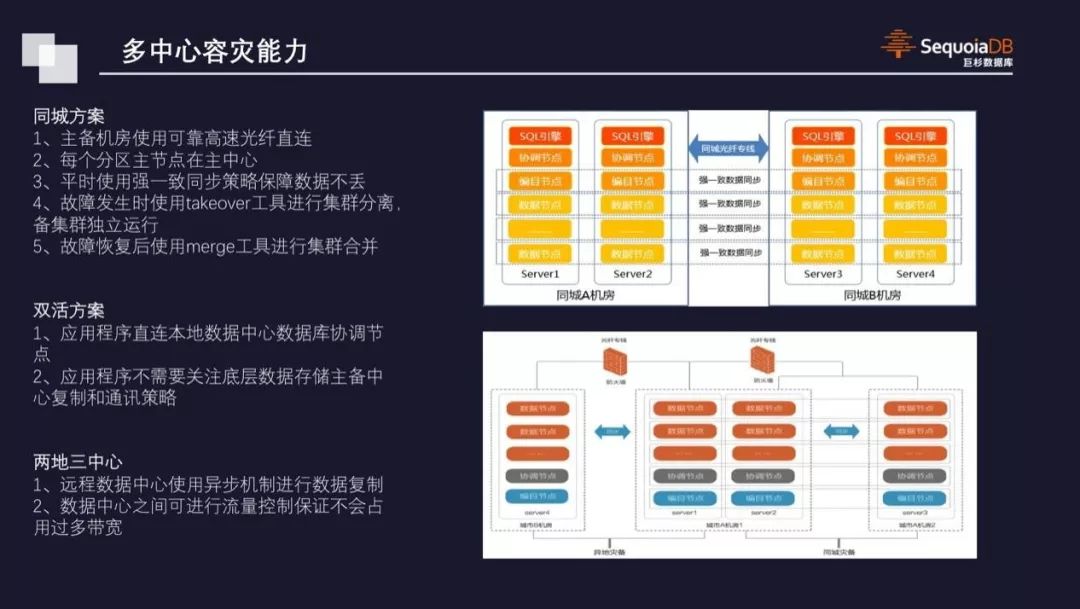
从多活架构的角度看,巨杉数据库秉承着计算存储分离的设计思路,其SQL的解析和执行器,与数据存储和事务控制会分别运行在不同的进程中。在这种情况下,利用巨杉数据库自身分布式与三副本复制的特性,将数据打散放置在多个数据中心内,每个数据中心配置本地SQL服务节点。从应用程序的角度看不需要关注底层数据库的主从架构,仅需要通过JDBC连接到本地的SQL服务节点进行读写操作即可。在这种架构下,每个SQL节点完全对等,并均可以处理读写操作,所有的事务控制、一致性控制、锁等待等机制都由底层的分布式数据库直接提供。
>>>小结
最后,我们做一个结束语,非常感谢大家来参加这次活动。巨杉Techday的每一场都会分享我们的战略特点、业务能力和技术能力,会在后期逐步跟大家深入交流和分享。

关注巨杉数据库SequoiaDB公众号
回复“0721”即可下载完整PPT

<MORE>



点击阅读原文,获取更多精彩内容~
