




zeppelin集成impala,是通过继承通用jdbc解释器来实现。
创建Interpreter
选择Interpreter
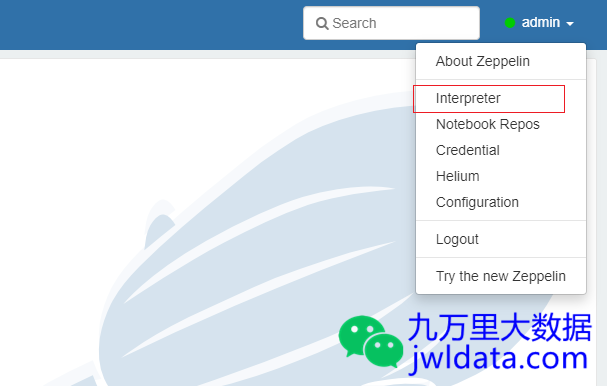
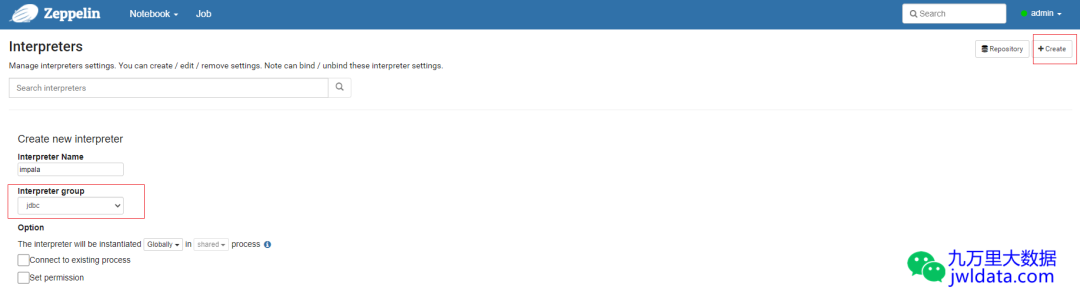
选择Create,Interpreter group选择jdbc,Interpreter Name自己随便起个名。
配置Properties
注意,将jdbc:impala://X.X.X.X:21050/default的jdbc连接串中的X.X.X.X替换成自己集群impala daemon的IP地址。
| Name | Value |
| default.driver | com.cloudera.impala.jdbc41.Driver |
| default.url | jdbc:impala://X.X.X.X:21050/default |
| default.user | hive |
配置Dependencies
需要配置hadoop的依赖jar包。在配置后,zeppelin会下载相关依赖jar包到zeppelin-0.9.0-bin-all的local-repo目录下。根据下载网速不同,可能需要等待几分钟到几十分钟不等。具体的Dependencies配置如下:
| Artifact | Exclude |
| org.apache.hadoop:hadoop-common:2.6.0 |
放置jdbc的jar包
通过https://downloads.cloudera.com/connectors/impala_jdbc_2.6.4.1005.zip下载ImpalaJDBC41.jar,放到zeppelin-0.9.0-bin-all/interpreter/jdbc目录下。
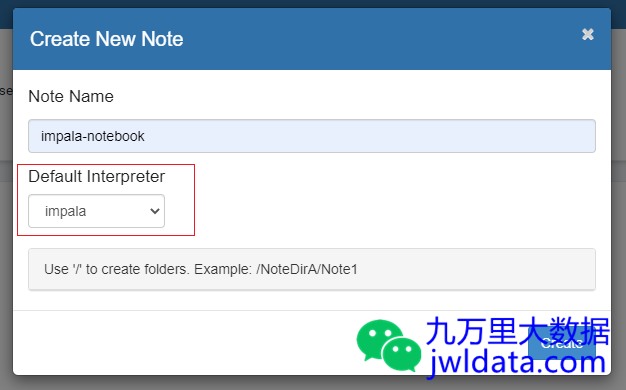
创建Noteboook
欢迎关注我的公众号“九万里大数据”,原创技术文章第一时间推送。欢迎访问原创技术博客网站 jwldata.com[1],排版更清晰,阅读更爽快。

引用链接
[1]
jwldata.com: https://www.jwldata.com
文章转载自九万里大数据,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
