




本文主要介绍OpenGauss中常见的索引结构,索引相关元数据,并结合代码重点讲解B-tree索引使用过程中的重要流程,希望对大家理解OpenGauss中的索引有所帮助。
索引方法
B-Tree索引
B-tree索引适合比较查询和范围查询,当查询条件使用(>,=,<,>=,<=)时,可以使用B-tree索引。B-tree索引是PostgreSQL和OpenGauss的默认索引方式。
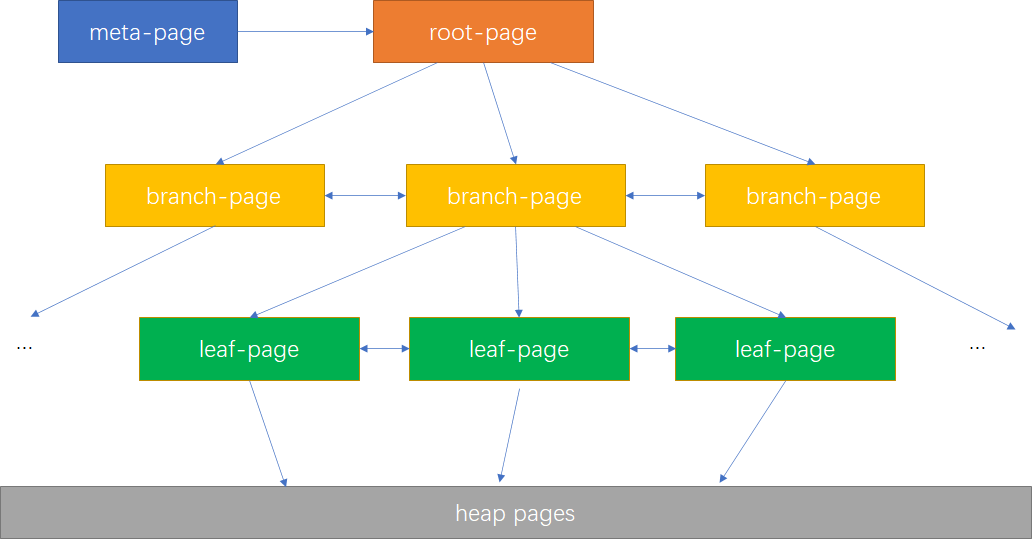
图-1 B-tree索引结构
B-tree索引页分为几种:meta-page、root-page、branch-page和leaf-page,如图-1所示。
meta-page: B-tree索引的元数据页,主要存储B-tree索引的元数据信息,可以通过meta page找到root page信息。
root-page:B-tree的根节点。
branch-page:内部节点,B-tree中根节点和叶子节点外的其他节点。
leaf-page:叶子节点,其中的ctid指向heap tuple,非叶子节点的ctid指向其子节点。
安装pageinspect后,可以通过
select * from bt_metap(‘tab_pkey’) 查看meta-page 信息
select * from bt_page_stats(‘tab_pkey’,1) 查看索引页信息
select * from bt_page_items(‘tab_pkey’,1) 查看页内tuple信息
index page 结构如图-2所示,
High-Key表示此page的右兄弟节点的最小值,由于page之间数据是有序的,当前page内所有key <= High-Key的值。对unique index而言,当前page内所有key < High-Key的值。
每一层的最右侧节点,由于没有右兄弟节点,因此page内没有High-Key。
Special Space为索引页特有,由于存储每个page左右两边page的页号,可通过Special Space找到左右page。

图-2 B-tree索引页结构
以上是行存引擎的B-tree索引结构,列存的B-tree索引整体结构上与行存相同。leaf-page上行存存储的是key到ctid的映射关系,行存可以直接ctid中的block number及offset找到heap tuple的位置。列存的ctid中记录的是(cu_id, offset),还需要再对应的CUDesc表中根据cu_id列的索引找到对应的CUDesc记录,打开对应的CU文件,根据offset找到数据。
列存上的B-tree索引不支持创建表达式索引、部分索引和唯一索引。
GiST索引
GiST(Generalized Search Tree)也是一棵平衡树,B-tree和比较语义强关联,适用于(>、>=、=、<=、<)这五个操作符。但现代数据库中存储的一些数据,如地理位置、图像数据等这五个操作符可能没有实际意义,GiST索引允许定义规则来将数据分布到平衡树中,并允许定义方法来访问数据。例如,GiST索引可以定义一棵存储空间数据的R-Tree,支持相对位置运算符(如 位于左侧、右侧、包含等)。
GiST屏蔽了数据库的内部工作机制,比如锁的机制和预写日志,使得实现新的GiST索引实例(或称作索引操作符类)的工作相对比较轻松。基于GiST架构的索引操作符类只需实现预定义的几个接口。
GIN索引
Generalized Inverted Tree倒排索引。主要用于多值类型,如数组、全文索引等。如果对应的TID的列表很小,可以和元素放在一个页面内(称为posting list)。如果TID列表很大,需要使用更高效的数据结构B-tree,这棵B-tree存储在单独的页面中(称为posting tree)。
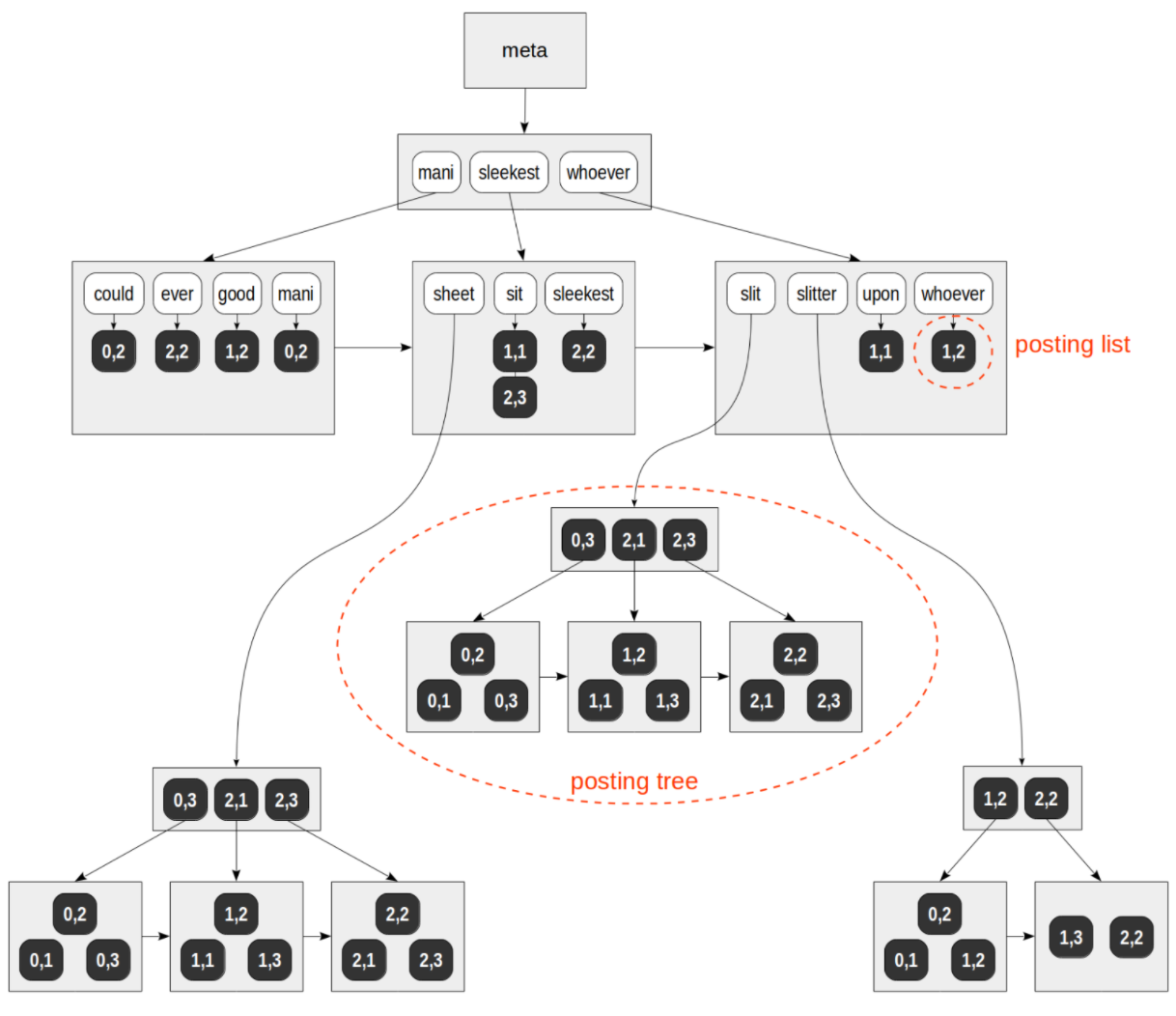
图-3 GIN索引结构
行存表支持的索引类型:B-tree(缺省值)、GIN、GiST。列存表支持的索引类型:Psort(缺省值)、B-tree、GIN。
索引相关系统表
pg_am
PG_AM系统表存储有关索引访问方法的信息。系统支持的每种索引访问方法都有一行。表中各个字段的含义可以参考官方文档:https://opengauss.org/zh/docs/2.0.0/docs/Developerguide/PG_AM.html
pg_index
PG_INDEX系统表存储索引的一部分信息,其他的信息大多数在PG_CLASS中。
对于分区表的partition local index,除了在pg_index中有一行数据外,每个分区的索引信息存储在pg_partition中。
表中具体字段含义参考官方文档:
https://opengauss.org/zh/docs/2.0.0/docs/Developerguide/PG_INDEX.html
其中indisvalid、indisready、indcheckxmin等字段会在后续内容详细介绍。
除了上述两张表外,索引使用流程中涉及的相关的系统表还有很多,如 pg_class、pg_attribute、pg_depend、pg_constraint等不一一介绍了,大家参考官方文档。
索引使用流程
创建索引
创建索引入口函数
DefineIndex
- 创建索引相关参数检查及校验
- 调用index_create 完成索引创建主要工作。所有索引创建都需要调用index_create,通过入参决定是不是需要构建索引结构。有一些流程,如create index concurrently,或者 分区表的partition local index,在这一步实际只是创建索引相关元数据,构建索引结构在后续流程完成。非分区表的index、分区表的global index构建索引结构在这一步完成。
- 如果是创建分区表的partition local index ,遍历所有分区,逐个分区调用 partition_index_create 创建分区索引。
- 如果是create index concurrently,执行create index concurrently的流程。此流程中表上加的锁类型是ShareUpdateExclusiveLock,不会阻塞对表的read及DML操作,普通建索引流程加的锁类型是ShareLock,会阻塞DML操作。分区表不允许create index concurrently。
index_create
- 参数检查及校验
- 创建 index tuple descriptor,tuple descriptor用于描述tuple的结构,index tuple descriptor中很多属性是从对应的表的tuple descriptor中拷贝过来的。最终relcache中索引的tuple descriptor很多信息来自这里创建的tuple descriptor。 ConstructTupleDescriptor
- 为索引生成新的 OID。 GetNewRelFileNode
- 将索引信息插入relcache中;在磁盘上创建索引文件,新建索引文件会记录WAL,新建索引时relfilenode设置为和OID相同;如果是concurrent create index或者创建分区表的partition local index,会跳过创建索引文件。heap_create
- 插入 pg_class 、pg_attribute、pg_index、pg_constraint、pg_depend等系统表。
- 执行构建索引流程,非分区表的index,及分区表的global index会在这一步真正构建索引结构。分区表的partition local index,会跳过这一步;如果是create index concurrently,跳过这一步。 index_build
- 在pg_object中记录索引创建时间。
index_build
执行构建索引,在调用index_build之前,索引相关元数据已经插入,空的索引文件已经创建。index_build根据pg_am中ambuild指定的创建索引的处理函数,执行构建索引的流程。
- 根据pg_am和索引类型找到构建索引对应的procedure,例如:btree索引的ambuild是btbuild、gin索引的ambuild是ginbuild。调用对应的处理函数。index_build_storage
- 索引构建完成后,如果构建过程中不是hot safe的,需要将pg_index中索引的indcheckxmin设置为true。设置indcheckxmin的目的是告诉其他事务,本索引可能是unsafe的。对应的事务在生成执行计划的收,如果发现索引的indcheckxmin标记为true,则需要比较创建索引的事务和当前事务的先后顺序,决定是否能使用索引。
- 更新 pg_class 中表和索引相关字段,如表中是否有索引的字段relhasindex设置为true,relallvisible 设置为true。
btbuild
不同类型的索引,对应的建索引的处理函数不同。btbuild是B-tree索引对应的处理函数。
- 构建一个BTBuildState对象,用于btbuild。BTBuildState中包含两个BTSpool对象指针,用于将heap tuple加载到内存中,以及heap tuple的排序。BTSpool中包含一个Tuplesortstate 类型的指针,Tuplesortstate 中用于记录tuple sort过程中的状态,维护tuple sort所需的内存空间/磁盘空间。
- 执行heap scan。如果是普通建索引,需要读取所有heap tuple(SNAPSHOT_ANY),然后判断heap tuple是否需要被索引。如果是create index concurrently 基于MVCC snapshot读取heap tuple(SNAPSHOT_MVCC),每个读取出来的heap tuple抽取出索引需要的列信息。 对于heap-only-tuple,index tuple中的tid指向hot-chain的root。IndexBuildHeapScan ? GlobalIndexBuildHeapScan
- 对扫描出的heap tuple进行排序;基于排完序的index tuple,构建完整的B-tree索引。_bt_leafbuild
_bt_leafbuid
- 对index tuple进行排序。tuplesort_performsort
- 基于排完序的index tuple,构建完整的B-tree索引。_bt_load
_bt_load
- 遍历所有排好序的index tuple,逐个调用_bt_buildadd加入到B-tree page中。B-tree从叶子节点开始构建,每一层从左向右构建。如果page写满了会触发下盘,同时创建同层右侧page;如果上层父page不存在,还会创建父page;如果已经存在父page,则将本page 的minkey 和 页号插入父节点。插入父节点的过程和插入子节点类似,可能触发父节点下盘等动作。index page会在special space记录左右两侧page的页号。每个page都会记WAL。
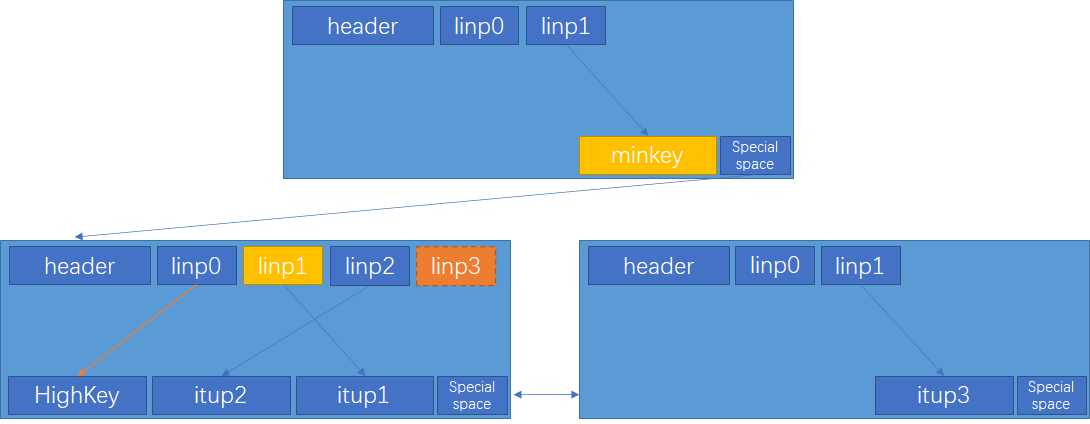
图-4 B-tree索引页构建
- 由于构建B-tree的过程是自左向右、自底向上,触发page下盘是page写满时,所以所有index tuple遍历完后,每一层的最右侧page可能还没有下盘及加入父节点。因此所有index tuple遍历完成后,还需要对每一层的最右侧节点做一次处理。每一层的最右侧节点没有HK,所以最终所有的ItemPointer需要向左移动一个位置。 B-tree索引构建完成后,还需要构建meta-page,所有page都会写WAL,在流程结束前会主动调一次fsync,让WAL下盘。 _bt_uppershutdown
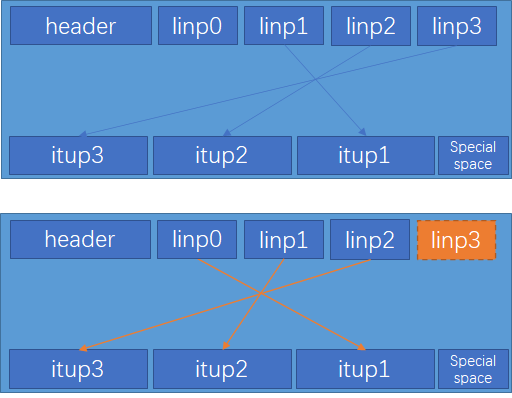
图-5 B-tree索引每层最右侧page结构
partition_index_create
用于创建分区表的partition local index。创建分区表的partition local index时,先获取分区信息,然后遍历每一个分区执行partition_index_create。
- 为partition local index生成新的OID
- 向partcache中插入索引相关信息,创建partition local index索引文件,记录WAL。 heapCreatePartition
- 在pg_partition中插入partition local index相关信息。insertPartitionEntry
- 执行索引构建。index_build
- 更新pg_class中表和索引信息。
create index concurrently
用于在不阻塞DML操作的情况下创建索引。
Phase 1
- 开启事务 tx1
- 插入relcache,插入索引相关元数据pg_class… ,和普通建索引相同,只是其中 pg_index 的 indisvalid、indisready 设置为false
- 在表上 加一个 session-level ShareUpdateExclusiveLock,加锁目的是防止在建索引的流程中表和索引元数据被其他流程修改
- 提交事务 tx1。tx1 提交后,新开启的事务将会看到索引信息,索引状态为不可读(indisvalid = false)、不可写(indisready = false),看到索引元数据的事务在插入数据时会考虑HOT-safe。
Phase 2 - 开启事务 tx2
- 等待当前在执行的DML事务结束。具体实现是:找出当前所有持有的锁与ShareLock冲突的事务ID,等待这些事务提交或者Abort 。这一步等待的目的是什么? 举例:表有两列{id, name},数据如图-6所示,在id字段建索引。在Phase 1结束前开始的事务tx,无法看到索引元数据,所以在更新数据时做HOT update;Case1:由于流程中没有等待事务结束,建索引流程扫描heap tuple时,对应的heap tuple 为{id:3,name: ‘dd’},index中对应的key是3,tx在索引扫描完后更新{id:3,name: ‘dd’} 这行数据为 {id:4,name: ‘dd’},因此索引中的数据实际是错误的。普通建索引流程,因为阻塞DML操作,因此不会出现该问题。 Case2: 如果 tx是一个在Phase 1之后开启的事务,由于索引元数据可见,update操作发现对应的列上有索引,在更新数据时知道这不是一个HOT update,此时因为建索引和update的执行顺序,也会出现索引数据遗漏,索引数据如图-7所示。 由于现在索引本身还是一个中间状态,对读写操作都不可见,所以这里数据有偏差不是什么大问题,只需要最终索引数据正确即可。Case2索引数据出现的遗漏,会在Phase 3中补全;而Case1出现的错误不会被修复,因为一条hot-chain上的所有tuple只会有一个index entry。
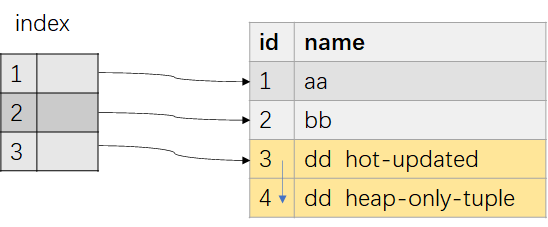
图-6 不等待Phase 1之前的DML结束导致的索引数据错误
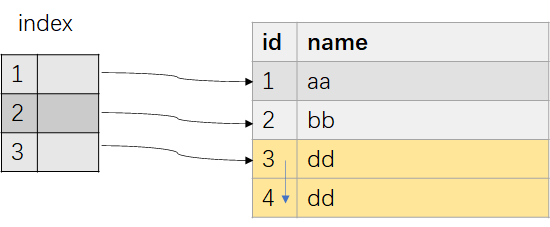
图-7 不等待Phase 1之后的DML结束导致的索引数据遗漏
- 获取快照 snapshot1
- 扫描表中的所有可见元组,构建索引
- 设置索引的 indisready 为 true(索引对写操作可见)
- 提交 tx2。tx2提交后新开启的事务更新数据时,会同时更新索引。
Phase 3 - 开启事务 tx3
- 等待当前在执行的DML事务结束。这里时为了等待Phase 2结束前开始的事务,这些事务看不到索引indisready = true,在更新数据时没有更新索引。
- 获取快照 snapshot2
- 为Phase2开始后没有更新索引的DML操作执行索引更新。 validate_index
- 记录 snapshot2’s 中的xmin
- 提交事务 tx3
Phase 4 - 开启事务 tx4
- 等待Phase 3之前开启的事务结束,这些事务可能持有一个比较老的snapshot,如果不等待这些事务结束就将索引的indisvalid 设置为true,这些事务可能出现读不一致的情况。如图-8所示,事务 txA 在Phase 3之前开启,读取数据r1,紧接着 txB delete r1;Phase 3中tx3 执行建索引时,由于对应的数据删除了,因此索引中没有r1的记录,tx3提交后索引的indisvalid设置为true,索引读可见,t’xA第二次读数据时使用索引,发现没有对应的数据,出现数据读一致的情况。为防止这种情况,需要在把索引的indisvalid设置为true之前,等待这些事务结束。
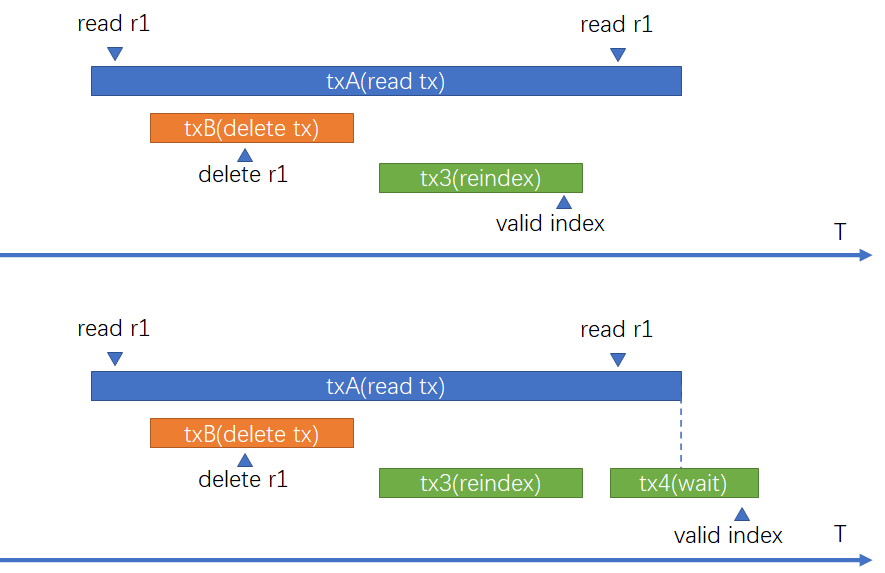
图-8 等待读事务结束
- 将索引的indisvalid 设置为true
- 提交 tx4
删除索引
和创建索引类似,删除索引也有concurrent和非concurrent两种方式,对应的加锁类型分别是ShareUpdateExclusiveLock和AccessExclusiveLock。
index_drop
concurrently
- 开启事务 tx1
- 索引indisvalid设置为false,记WAL。index_set_state_flags(indexId, INDEX_DROP_CLEAR_VALID)
- 表的relcache失效,表和索引上加会话级别的ShareUpdateExclusiveLock,防止流程执行期间,其他流程修改元数据,例如 drop table
- 提交事务 tx1。tx1提交后,新的事务查询不会使用该索引。
- 开启事务tx2
- 等待所有的事务结束,有一些事务在tx1提交前已经开启,要确保没有事务查询使用该索引,需要等这些事务结束。
- 设置索引的indisready为false,indisvalid为true ? 有疑问,表的relcache失效
- 提交事务tx2
- 开启事务tx3
- 等待所有的事务结束,有一些事务在tx2提交前已经开启,要确保没有事务更新该索引,需要等这些事务结束。
- 表加ShareUpdateExclusiveLock,索引上加AccessExclusiveLock,为删除索引文件做准备
- 删除索引文件
- 删除pg_index中索引数据,删除pg_class、pg_attribute中索引相关数据,刷新缓存
- 释放会话级ShareUpdateExclusiveLock
非concurrent删除索引流程上更简单一些,在表和索引上加AccessExclusiveLock,删除索引文件和相关元数据,刷新缓存。
限于篇幅,索引相关其他内容,如重建索引,索引插入,索引的读写并发等内容下次再补充。
