




0x01 环境安装配置
1.Prometheus 安装方式
2.Prometheus 服务安装
3.Node Exporter 指标安装
4.cAdvisor 容器监控安装
5.Grafana 图像化展示接入
6.在k8s中安装部署上述组件
0x01 环境安装配置
1.Prometheus 安装方式
描述: 上面的prometheus组件里常规的安装方式有如下几种;
Using pre-compiled binaries :二进制可执行文件
From source : 源码编译(需要安装gcc 和 g++ 和 Make)
# prometheus_server
$ mkdir -p $GOPATH/src/github.com/prometheus
$ cd $GOPATH/src/github.com/prometheus
$ git clone https://github.com/prometheus/prometheus.git
$ cd prometheus
$ make build
$ ./prometheus -config.file=your_config.yml
# prometheus_alertmanager
$ git clone https://github.com/prometheus/alertmanager.git
$ cd alertmanager
$ make build
$ ./alertmanager -config.file=<your_file>
Using Docker : 依赖于Docker进行安装,注意在Quay.io或Docker Hub上Docker图像的形式提供。
最重要的Docker主机和容器度量的简单概述(cAdvisor/普罗米修斯)参考地址: https://grafana.com/grafana/dashboards/893
Using configuration management systems : 使用配置管理系统进行安装;
参考地址: https://prometheus.io/docs/prometheus/latest/installation/
2.Prometheus 服务安装
描述: 此次为了方便部署和测试我在Docker容器环境中利用 docker-compose的方式部署 prometheus
、 alertmanager
、grafana
进行安装以及准备好文件,以及相应服务的配置文件。
Step 1.准备好持久化数据目录的创建与权限赋予
# (1) 此为NFS共享存储便于后面多台主机的
/nfsdisk-31/monitor# mkdir -vp nfsdisk-31/monitor/prometheus/{conf,data} grafana/data
# mkdir: created directory '/nfsdisk-31/monitor/prometheus'
# mkdir: created directory 'prometheus/conf'
# mkdir: created directory 'prometheus/data'
# mkdir: created directory 'grafana'
# mkdir: created directory 'grafana/data'
# (2) grafana 服务数据存储目录所属者设置(否则报错:GF_PATHS_DATA='/var/lib/grafana' is not writable.)
chown 472:root -R nfsdisk-31/monitor/grafana/data
chmod 777 nfsdisk-31/monitor/prometheus/data
Step 2.配置文件目录
tree -L 3
.
├── docker-compose.yml
├── grafana
│ └── data
└── prometheus
├── conf
│ ├── alertmanager.yaml
│ ├── alert.rules
│ └── prometheus.yml
└── data
Step 3.docker 创建指定网络名称monitor;
docker network create -d bridge monitor
# 527a8953a9d57c64e2d728d817f46ea735b104e6f0f2c342f1c7844eebe8ad87
docker network ls
# NETWORK ID NAME DRIVER SCOPE
# 4fe5982b8449 bridge bridge local
# 484bfd6f8556 host host local
# 527a8953a9d5 monitor bridge local
# 0b83b3436078 none null local
Step 4.Docker-compose 资源清单描述进行prometheus以及grafana容器的创建, 以及相应的配置文件。
tee nfsdisk-31/monitor/prometheus/conf/docker-compose.yml <<'END'
version: '3.2'
services:
prometheus:
image: prom/prometheus:v2.26.0
container_name: prometheus_server
environment:
TZ: Asia/Shanghai
volumes:
- nfsdisk-31/monitor/prometheus/conf/prometheus.yml:/etc/prometheus/prometheus.yml
- nfsdisk-31/monitor/prometheus/conf/alert.rules:/etc/prometheus/alert.rules
- nfsdisk-31/monitor/prometheus:/prometheus
- etc/localtime:/etc/localtime
command:
- '--config.file=/etc/prometheus/prometheus.yaml'
- '--storage.tsdb.path=/prometheus/data'
- '--web.enable-admin-api'
- '--web.enable-lifecycle'
ports:
- '30090:9090'
restart: always
networks:
- monitor
pushgateway:
image: prom/pushgateway
container_name: prometheus_pushgateway
environment:
TZ: Asia/Shanghai
volumes:
- etc/localtime:/etc/localtime
ports:
- '30091:9091'
restart: always
networks:
- monitor
alertmanager:
image: prom/alertmanager:v0.21.0
container_name: prometheus_alertmanager
environment:
TZ: Asia/Shanghai
volumes:
- nfsdisk-31/monitor/prometheus/conf/alertmanager.yaml:/etc/alertmanager.yaml
- nfsdisk-31/monitor/prometheus/alertmanager:/alertmanager
- etc/localtime:/etc/localtime
command:
- '--config.file=/etc/alertmanager.yaml'
- '--storage.path=/alertmanager'
ports:
- '30093:9093'
restart: always
networks:
- monitor
grafana:
image: grafana/grafana:7.5.5
container_name: grafana
user: "472"
environment:
- TZ=Asia/Shanghai
- GF_SECURITY_ADMIN_PASSWORD=weiyigeek
volumes:
- nfsdisk-31/monitor/grafana/data:/var/lib/grafana
ports:
- '30000:3000'
restart: always
networks:
- monitor
dns:
- 223.6.6.6
- 192.168.12.254
networks:
monitor:
external: true
END
Step 5.prometheus 和 alertmanager 依赖的相关配置文件。
cd nfsdisk-31/monitor/prometheus/conf/
# prometheus 监控服务
tee prometheus.yml <<'EOF'
global:
# pull 频率
scrape_interval: 120s
# 超时时间
scrape_timeout: 15s
# 外部标签
external_labels:
monitor: 'current-monitor'
scrape_configs:
# 工作组名称
- job_name: 'prometheus'
# 监控的主机地址与端口信息
static_configs:
- targets: ['localhost:9090']
# 报警规则
rule_files:
- 'alert.rules'
EOF
# 报警服务
tee alertmanager.yaml <<'EOF'
# 默认采用哪种方式进行预警
route:
group_by: ['alertname']
receiver: 'default-receiver'
receivers:
- name: 'default-receiver'
#接收者为webhook类型
webhook_configs:
#webhook的接收地址
- url: 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=4e1165c3-55c1-4bc4-8493-ecc5ccda9275'
EOF
# 报警规则
tee alert.rules <<'EOF'
groups:
- name: node-alert
rules:
- alert: service_down
expr: up == 0
for: 3m
- alert: high_load
expr: node_load1 > 1.0
for: 5m
EOF
Step 6.根据需求配置好相关信息之后使用
docker-compose up -d
启动容器,注意进行相应端口的防火墙规则调整通行。
docker-compose ps
# Name Command State Ports
# -----------------------------------------------------------------------------------------------------
# grafana run.sh Up 0.0.0.0:30000->3000/tcp
# prometheus_alertmanager bin/alertmanager --config ... Up 0.0.0.0:30093->9093/tcp
# prometheus_server bin/prometheus --config.f ... Up 0.0.0.0:30090->9090/tcp
Step 7.所有的容器状态都 UP 之后,打开浏览器访问以下服务查看是否正常。
# prometheus 监控主服务 - 提供简陋的管理页面
http://192.168.12.107:30090/
# prometheus Alertmanager 服务 - 提供简陋的管理页面
http://192.168.12.107:30093/
# grafana UI 服务 - 提供数据专业化展示 (默认账户密码: admin/weiyigeek)
http://192.168.12.107:30000/login
点击 - insert metric at cursor
选择框,选额 go_info
,再点击 Execute
按钮查看是否有监控指标输出即安装成功go_info{instance="localhost:9090", job="prometheus", version="go1.16.2"}
。

3.Node Exporter 指标安装
描述: 该组件主要用于机器指标导出。
Step 1.在Github的Release中下载
node_exporter
可直接运行的二进制包。
# 1.解压二进制文件
cd opt
wget https://github.com/prometheus/node_exporter/releases/download/v1.1.2/node_exporter-1.1.2.linux-amd64.tar.gz
tar -xvf node_exporter-1.1.2.linux-amd64.tar.gz
sudo cp -a node_exporter usr/local/bin/node_exporter
# 2.创建配置文件
sudo mkdir etc/node_exporter/
sudo tee etc/node_exporter/exporter.conf <<'EOF'
# 官方建议添加环境变量 `/etc/node_exporter/exporter.confr` ,内容如下:
# OPTIONS="--collector.textfile.directory var/lib/node_exporter/textfile_collector"
EOF
Step 2.创建
/usr/lib/systemd/system/node_exporter.service
systemd unit 文件
# > systemd 可用于监控系统服务,需要在 node_exporter 启动时添加 --collector.systemd 参数开启,默认是关闭的。
sudo tee usr/lib/systemd/system/node_exporter.service <<'EOF'
[Unit]
Description=Node Exporter Clinet
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
StandardError=journal
ExecStart=/usr/local/bin/node_exporter --web.listen-address=:9100
Restart=on-failure
RestartSec=3s
[Install]
WantedBy=multi-user.target
EOF
# EnvironmentFile=/etc/node_exporter/exporter.conf
sudo chmod 754 usr/lib/systemd/system/node_exporter.service
Step 3.重载systemd与开机自启node_exporter服务
# 重载&开机自启
sudo systemctl daemon-reload
sudo systemctl enable node_exporter.service
sudo systemctl start node_exporter.service
# 日志查看
sudo systemctl status node_exporter.service
● node_exporter.service - Node Exporter Clinet
Loaded: loaded (/lib/systemd/system/node_exporter.service; disabled; vendor preset: enabled)
Active: active (running) since Fri 2021-04-30 22:49:33 CST; 10s ago
Main PID: 1238901 (node_exporter)
Tasks: 12 (limit: 19111)
Memory: 11.4M
CGroup: system.slice/node_exporter.service
└─1238901 usr/local/bin/node_exporter --collector.systemd
Apr 30 22:49:33 weiyigeek-107 node_exporter[1238901]: level=info ts=2021-04-30T14:49:33.154Z caller=node_exporter.go:113 collector=thermal_zone
......
Apr 30 22:49:33 weiyigeek-107 node_exporter[1238901]: level=info ts=2021-04-30T14:49:33.154Z caller=node_exporter.go:113 collector=zfs
Apr 30 22:49:33 weiyigeek-107 node_exporter[1238901]: level=info ts=2021-04-30T14:49:33.154Z caller=node_exporter.go:195 msg="Listening on" address=:9100
Apr 30 22:49:33 weiyigeek-107 node_exporter[1238901]: level=info ts=2021-04-30T14:49:33.155Z caller=tls_config.go:191 msg="TLS is disabled." http2=false
netstat -tlnp | grep "9100"
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp6 0 0 :::9100 :::* LISTEN -
weiyigeek@weiyigeek-107:~$
Step 4.通过
node exporter
的http服务查看该主机的metrics信息
curl -s http://192.168.12.107:9100/metrics | head -n 20
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 2.4814e-05
go_gc_duration_seconds{quantile="0.25"} 5.1128e-05
go_gc_duration_seconds{quantile="0.5"} 9.3675e-05
go_gc_duration_seconds{quantile="0.75"} 0.000131435
go_gc_duration_seconds{quantile="1"} 0.000767665
go_gc_duration_seconds_sum 0.015132517
go_gc_duration_seconds_count 135
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 8
# HELP go_info Information about the Go environment.
# TYPE go_info gauge
go_info{version="go1.15.8"} 1
# HELP go_memstats_alloc_bytes Number of bytes allocated and still in use.
# TYPE go_memstats_alloc_bytes gauge
go_memstats_alloc_bytes 3.019424e+06
# HELP go_memstats_alloc_bytes_total Total number of bytes allocated, even if freed.
# TYPE go_memstats_alloc_bytes_total counter
Step 5.配置 prometheus.yml 添加如下Job工作
vi nfsdisk-31/monitor/prometheus/conf/prometheus.yml
- job_name: 'node-resources'
scrape_interval: 120s
static_configs:
- targets: ['192.168.12.107:9100'] # 指定安装和启动后 node_exporter 的主机
Step 6.重新
prometheus
容器进行更新配置,之后访问http://192.168.12.107:30090/targets
页面查看目标是否可以正常监控了(UP上线)。
/nfsdisk-31/monitor# docker-compose restart prometheus
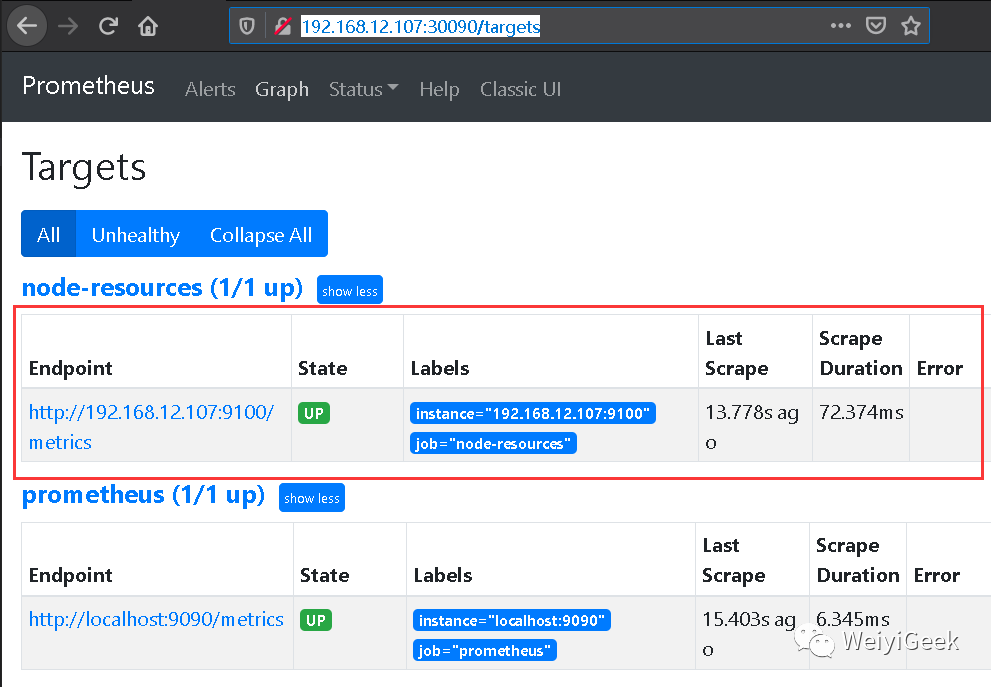
Step 7.监控该主机系统相关信息,我们可以在UI首页进行系统空闲磁盘大小查看
# PromQL 表达式: 获取系统空闲磁盘的空间大小(单位 GB)
node_filesystem_free_bytes{fstype!="tmpfs"} (1024*1024*1024)
# 结果
{device="/dev/mapper/ubuntu--vg-lv--0", fstype="ext4", instance="192.168.12.107:9100", job="node-resources", mountpoint="/"}
76.21196365356445
{device="/dev/sda2", fstype="ext4", instance="192.168.12.107:9100", job="node-resources", mountpoint="/boot"}
0.6655235290527344
{device="192.168.10.30:/nask8sapp", fstype="nfs", instance="192.168.12.107:9100", job="node-resources", mountpoint="/nfsdisk-31"}
2275.9747009277344

4.cAdvisor 容器监控安装
描述: cAdvisor 英 [Kədˈvaɪzə]
使用Go语言开发,利用Linux的cgroups获取容器的资源使用信息, 可以对节点机器上的资源及容器进行实时监控和性能数据采集,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况,还提供基础查询界面和http接口,方便其他组件如Prometheus进行数据抓取.
cAdvisor原生支持Docker容器,并且对任何其他类型的容器能够开箱即用,它也是基于lmctfy的容器抽象,所以容器本身是分层嵌套的。
优缺点:
优点:谷歌开源产品,监控指标齐全,部署方便,而且有官方的docker镜像。
缺点:是集成度不高,默认只在本地保存1分钟数据,但可以集成InfluxDB等存储
项目地址: https://github.com/google/cadvisor/
学习参考地址: https://docs.huihoo.com/apache/mesos/chrisrc.me/dcos-admin-monitoring-docker.html
cAdvisor 结构图:
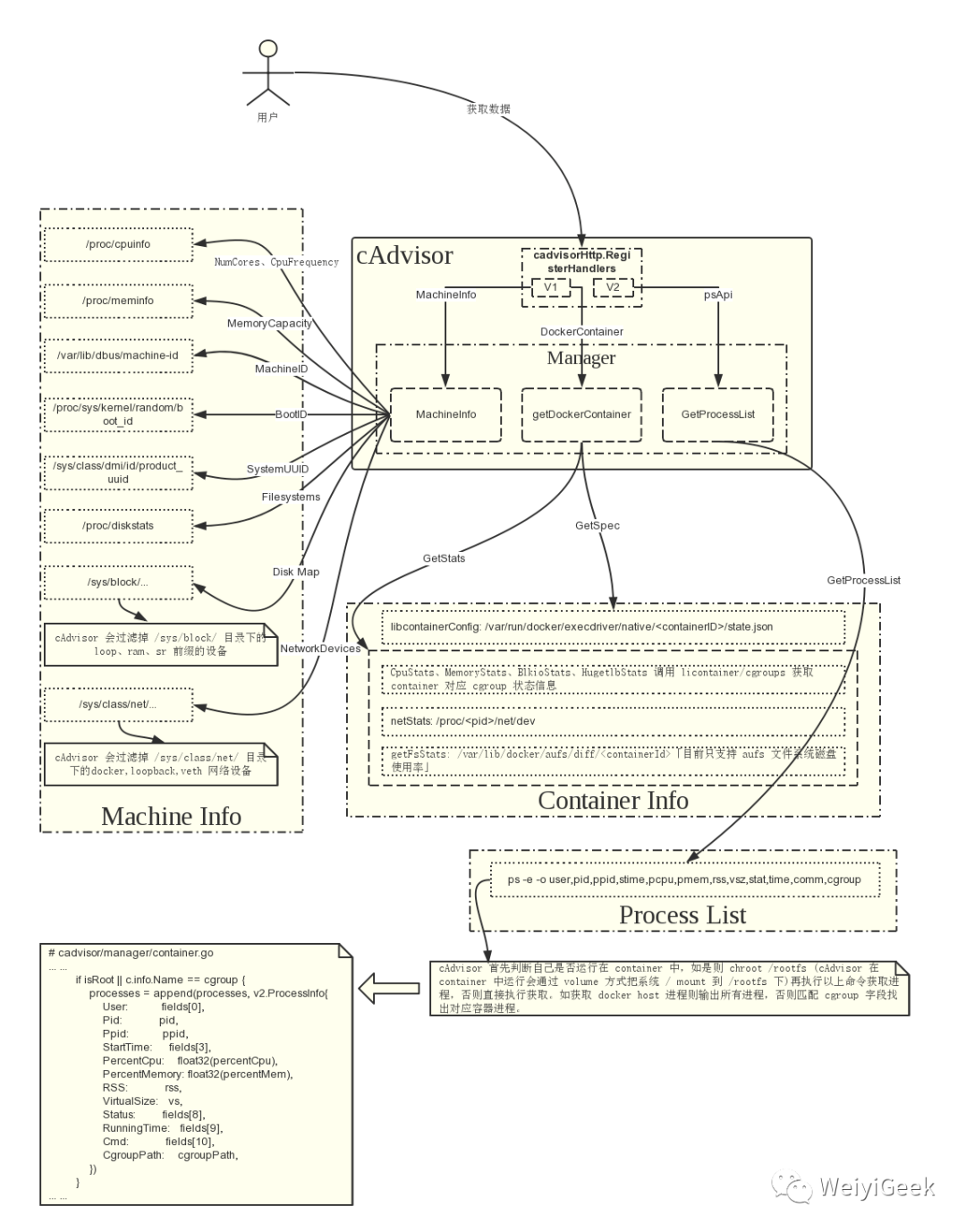
安装方式:
二进制部署
下载二进制:https://github.com/google/cadvisor/releases/latest
本地运行:./cadvisor -port=8080 &>>/var/log/cadvisor.log
使用docker部署
docker run \
--volume=/var/run:/var/run:rw \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=9100:8080\
--detach=true \
--name=cadvisor \
google/cadvisor:latest
# 8fa36cd105ebce5c9cc334f2bfaae781833ddce396bfb96bd775a18706c9e1f3
# 注意:在Ret Hat,CentOS, Fedora 等发行版上需要传递如下参数,因为 SELinux 加强了安全策略:
--privileged=true
# 可选参数
--volume=/:/rootfs:ro \
启动后访问
http://192.168.12.108:9100/containers
查看 CAvisor 监控页面;

然后访问:
http://192.168.12.108:9100/metrics
查看其暴露给 Prometheus 的所有数据;
# HELP cadvisor_version_info A metric with a constant '1' value labeled by kernel version, OS version, docker version, cadvisor version & cadvisor revision.
# TYPE cadvisor_version_info gauge
cadvisor_version_info{cadvisorRevision="8949c822",cadvisorVersion="v0.32.0",dockerVersion="19.03.14",kernelVersion="5.4.0-60-generic",osVersion="Alpine Linux v3.7"} 1
# HELP container_cpu_load_average_10s Value of container cpu load average over the last 10 seconds.
# TYPE container_cpu_load_average_10s gauge
container_cpu_load_average_10s{container_label_annotation_io_kubernetes_container_hash="",container_label_annotation_io_kubernetes_container_ports="",container_label_annotation_io_kubernetes_container_restartCount="",container_label_annotation_io_kubernetes_container_terminationMessagePath="",container_label_annotation_io_kubernetes_container_terminationMessagePolicy="",
.......
我们将cAdvisor配置接入到
prometheus
之中,修改后重新启动容器。
vim nfsdisk-31/monitor/prometheus/conf/prometheus.yml
scrape_configs:
- job_name: 'node-resources'
scrape_interval: 120s
static_configs:
- targets: ['192.168.12.107:9100','192.168.12.108:9100']
# 将 cAdvisor 添加到监控数据采集任务目标当中
# - job_name: cadvisor
# static_configs:
# - targets:
# - 10.10.107.234:9060
# 重启容器
docker restart prometheus_server
# prometheus_server
访问Prometheus后台页面查看target以及查询验证。

Tips : 在CentOS上运行cAdvisor时,需要添加 --privileged=true
和 --volume=/cgroup:/cgroup:ro
两项配置。
CentOS/RHEL对其上的容器做了额外的安全限定,cAdvisor需要通过Docker的socket访问Docker守护进程,这需要
--privileged=true
参数。某些版本的CentOS/RHEL将cgroup层次结构挂载到了
/cgroup
下,cAdvisor需要通过--volume=/cgroup:/cgroup:ro
获取容器信息。
Tips : 如果碰到Invalid Bindmount
错误,可能是由于Docker版本较低所致,可以在启动cAdvisor时不挂载--volume=/:/rootfs:ro
。
Tips :总结正是因为 cadvisor 与 Prometheus 的完美结合,所以它成为了容器监控的第一选择,或者cadvisor + influxdb + grafna
搭配使用。
5.Grafana 图像化展示接入
描述: 在简单的配置好node-export被监控主机以及cAdvisor容器监控之后,将其监控采集的数据接入到Grafana进行展示。
Step 1.点击首页
Create a data source
按钮选择Prometheus
导入Prometheus
监控数据源(注:由于搭建的版本不同位置名称可能由些许不同)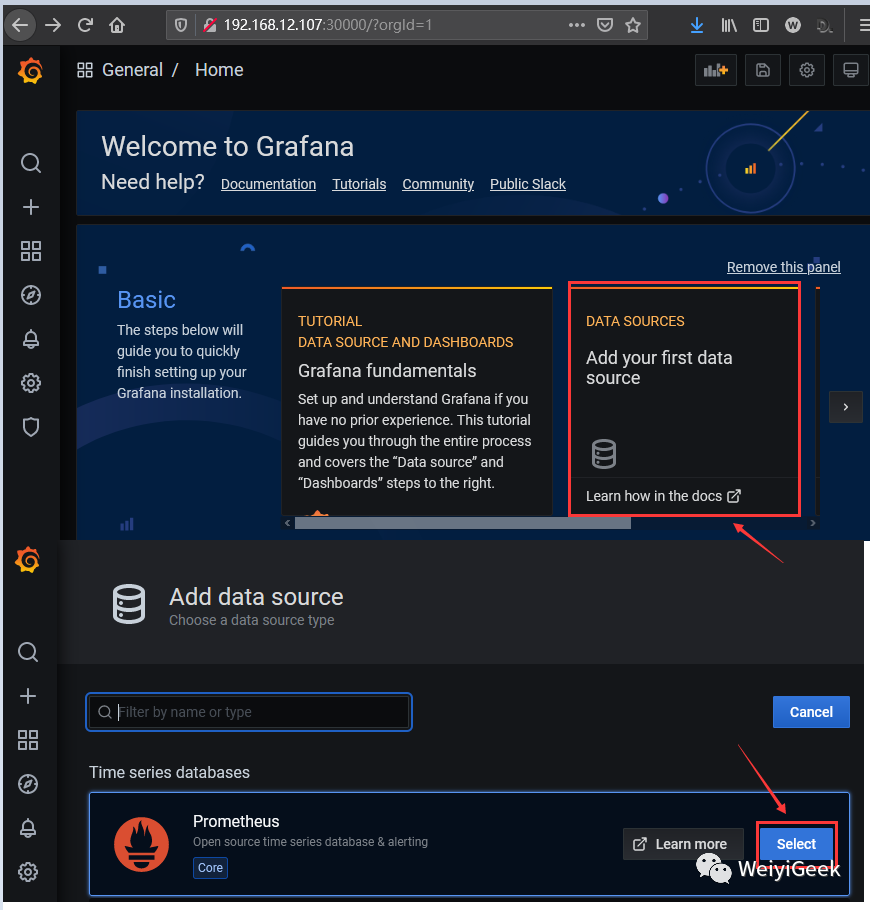
Step 2.进入 Prometheus 的 Data Sources 设置页面之后, 设置 URL 为的
http://192.168.12.107:30090
, 其余的默认即可 Auth 方式稍后使用 nginx 进行用户访问权限验证处理。Step 3.配置好信息之后点击底部的
Save & test
按钮,测试是否能正常获取的Prometheus
监控数据源
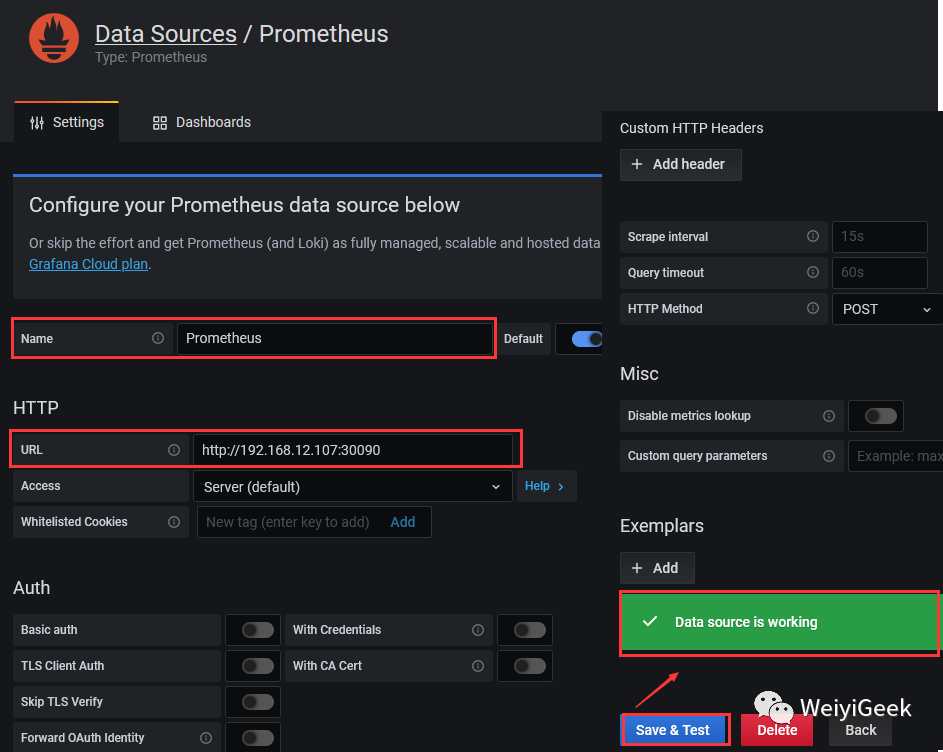
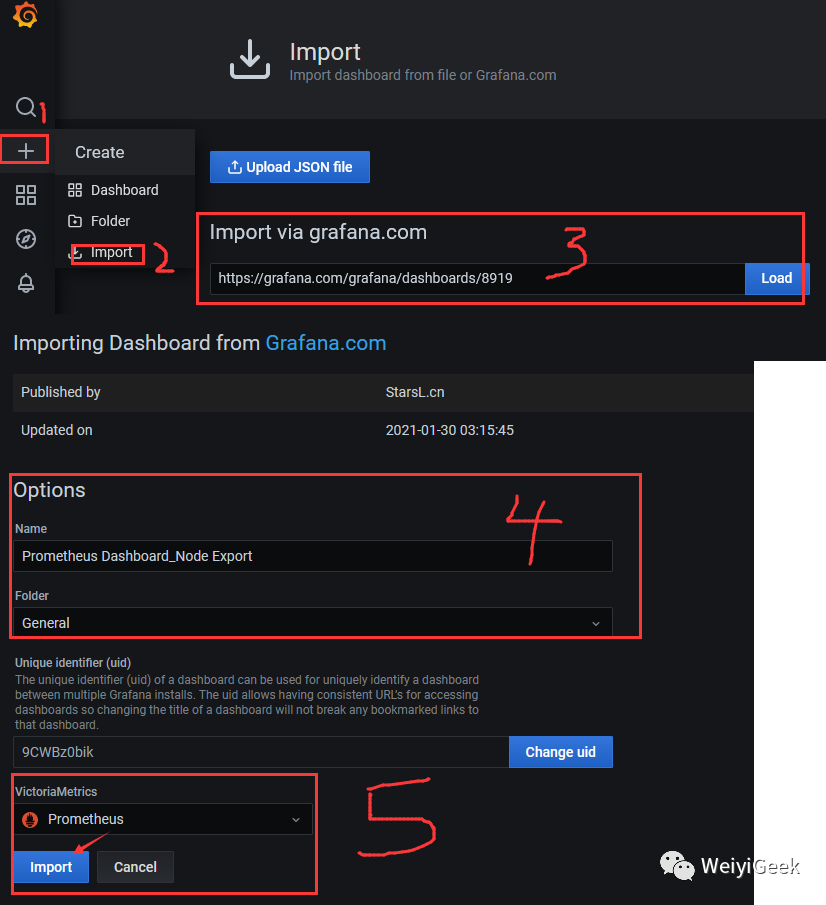
Step 4.点击右上角
+
按钮 —>Import dashboard
然后在Import via grafana.com
输入栏中输入https://grafana.com/grafana/dashboards/8919
再点击Load
,之后会自动跳转到该 dashboard 的配置页面。Step 5.设置好名称,并在
Prometheus Data Source
选择之前配置好的数据源,然后点击import
即可。
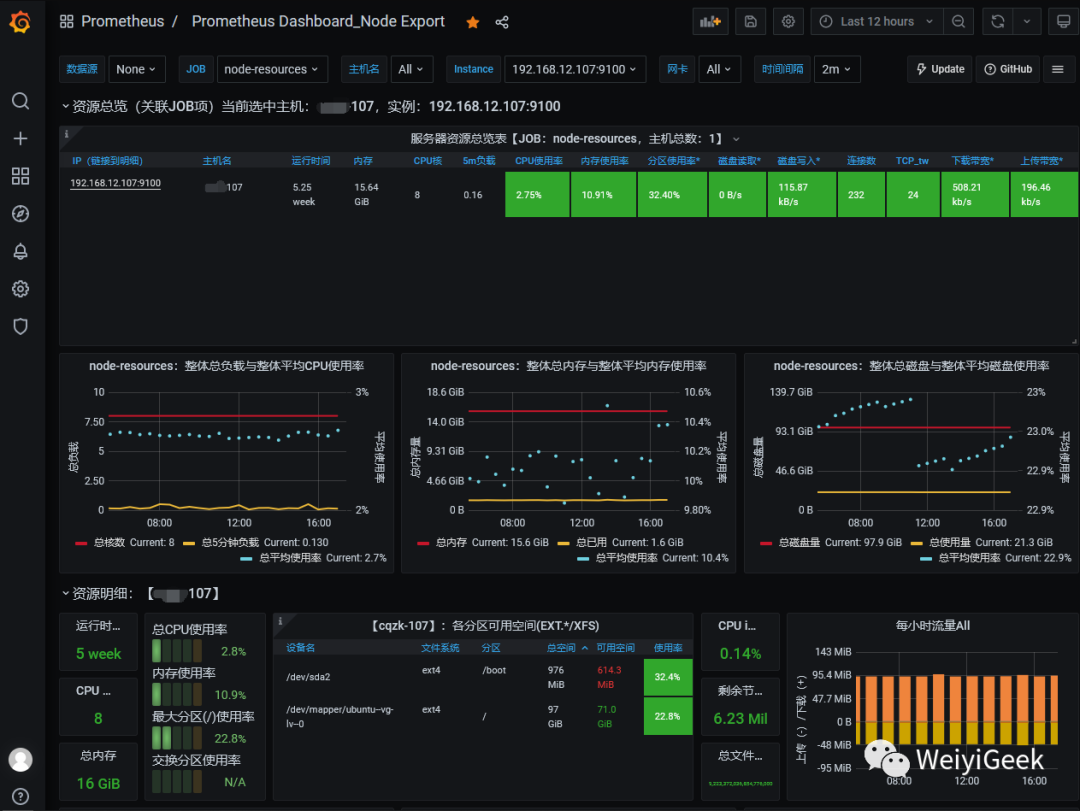
Step 6.回到 grafana 的主页面,页面
Recently viewed dashboards
会有出现我们刚刚导入的 dashboard, 点击进入后会出现以下监控信息。
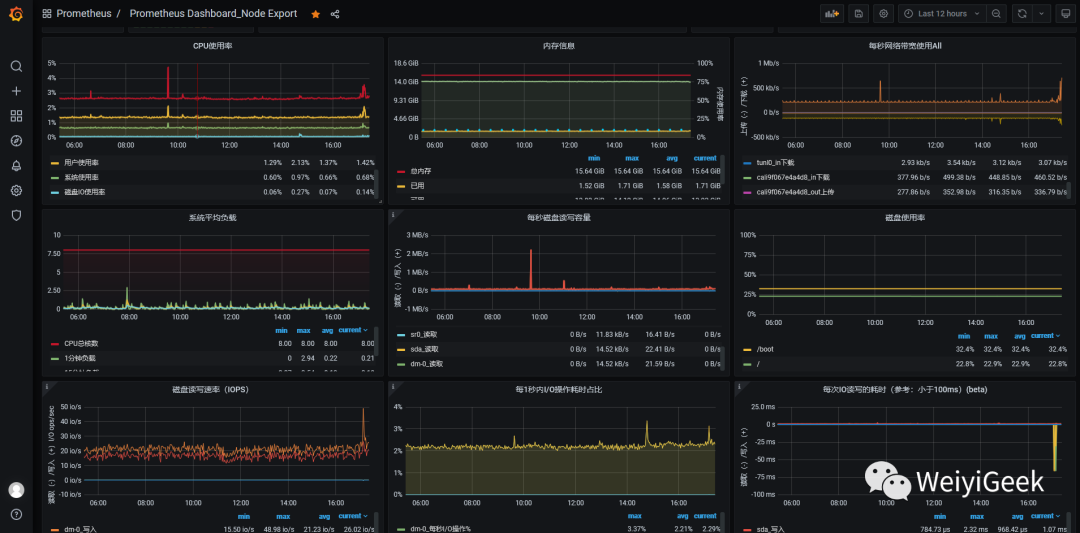
6.在k8s中安装部署上述组件
描述: 该存储库将Kubernetes清单、Grafana仪表板和Prometheus规则与文档和脚本结合起来,通过Prometheus使用Prometheus操作符来提供易于操作的端到端Kubernetes集群监控。
Prometheus github 地址: https://github.com/prometheus-operator/kube-prometheus#quickstart
Prometheus github 地址: https://github.com/coreos/kube-prometheus
组件说明:
1.MetricServer: 是kubernetes集群资源使用情况的聚合器,收集数据给kubernetes集群内使用,如 kubectl,hpa,scheduler等。
2.PrometheusOperotor:是一个系统监测和警报工具箱,用来存储监控数据
3.NodeExporter:用于各node的关键度量指标状态数据。
4.KubeStateMetrics:收集kubernetes集群内资源对象数 据,制定告警规则。
5.Prometheus::采用pull方式收集apiserver, scheduler, controller-mandger, kubelet组件数 据,通过http协议传输。
6.Grafana:是可视化数据统计和监控平台。
操作流程:
Step 0.拉取 kube-prometheus 在 Github 中的项目文件;
# PS : 设置当前代理为 http://127.0.0.1:1080 或 socket5://127.0.0.1:1080 (此处为了加快拉取速度我采用自己的VPS搭建的梯子)
git config --global http.proxy 'socks5://127.0.0.1:1080'
git config --global https.proxy 'socks5://127.0.0.1:1080'
git clone https://github.com/coreos/kube-prometheus.git
~/K8s/Day10/kube-prometheus$ ls
build.sh DCO example.jsonnet experimental go.sum jsonnet jsonnetfile.lock.json LICENSE manifests OWNERS scripts tests
code-of-conduct.md docs examples go.mod hack jsonnetfile.json kustomization.yaml Makefile NOTICE README.md sync-to-internal-registry.jsonnet test.sh
Step 1.由于GFW的原因我们需要将资源清单中的quay.io仓库以及k8s.gcr.io仓库镜像地址进行换成国内(
PS:建议在国外买VPS然后PULL下载后打包回国内
)以及type访问类型
~/K8s/Day10/kube-prometheus/manifests/setup$ grep "quay.io/" *
# prometheus-operator-deployment.yaml: - --prometheus-config-reloader=quay.io/prometheus-operator/prometheus-config-reloader:v0.44.0
# prometheus-operator-deployment.yaml: image: quay.io/prometheus-operator/prometheus-operator:v0.44.0
# prometheus-operator-deployment.yaml: image: quay.io/brancz/kube-rbac-proxy:v0.8.0
~/K8s/Day10/kube-prometheus/manifests/setup$ sed -i "s#quay.io/#quay.mirrors.ustc.edu.cn/#g" *
~/K8s/Day10/kube-prometheus/manifests/$ sed -i "s#quay.io/#quay.mirrors.ustc.edu.cn/#g" *
# 修改访问方式为`type: NodePort`以及NodePort暴露的端口
# ---~/K8s/Day10/kube-prometheus/manifests$ cat alertmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
alertmanager: main
name: alertmanager-main
namespace: monitoring
spec:
type: NodePort # 修改点1
ports:
- name: web
port: 9093
targetPort: web
nodePort: 30070 # 修改点2
selector:
alertmanager: main
app: alertmanager
sessionAffinity: ClientIP
# ---~/K8s/Day10/kube-prometheus/manifests$ cat prometheus-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
prometheus: k8s
name: prometheus-k8s
namespace: monitoring
spec:
type: NodePort # 修改点1
ports:
- name: web
port: 9090
targetPort: web
nodePort: 30090 # 修改点2
selector:
app: prometheus
prometheus: k8s
sessionAffinity: ClientIP
# ---~/K8s/Day10/kube-prometheus/manifests$ cat grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: grafana
name: grafana
namespace: monitoring
spec:
ports:
- name: http
port: 3000
targetPort: http
nodePort: 30080 # 修改点2
selector:
app: grafana
type: NodePort # 修改点1
Step 2.使用manifests/setu的清单目录中的配置创建监视堆栈
~/K8s/Day10/kube-prometheus/manifests/setup$ kubectl create -f .
# namespace/monitoring created
# customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com created
# customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created
# customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created
# customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com created
# customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created
# customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created
# customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
# customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created
# clusterrole.rbac.authorization.k8s.io/prometheus-operator created
# clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
# deployment.apps/prometheus-operator created
# service/prometheus-operator created
# serviceaccount/prometheus-operator created
~/K8s/Day10/kube-prometheus/manifests/setup$ kubectl get pod -n monitoring -o wide --show-labels
# NAME READY STATUS RESTARTS AGE IP NODE LABELS
# prometheus-operator-5bff4cfb76-dtvjj 2/2 Running 0 50m 10.244.2.59 k8s-node-5 app.kubernetes.io/component=controller,app.kubern etes.io/name=prometheus-operator,app.kubernetes.io/version=v0.44.0,pod-template-hash=5bff4cfb76
Step 3. 完成上一步资源清单的创建后继续进行manifests中grafana、alertmanager、node-exporter资源清单的建立
~/K8s/Day10/kube-prometheus$ kubectl create -f manifests/
# alertmanager.monitoring.coreos.com/main created
# secret/alertmanager-main created
...... # 此处略去
# servicemonitor.monitoring.coreos.com/kubelet created
~/K8s/Day10/kube-prometheus$ kubectl get pod -n monitoring -o wide
# NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
# alertmanager-main-0 2/2 Running 0 105m 10.244.2.60 k8s-node-5 <none> <none>
# alertmanager-main-1 2/2 Running 0 105m 10.244.1.157 k8s-node-4 <none> <none>
# alertmanager-main-2 2/2 Running 0 105m 10.244.2.61 k8s-node-5 <none> <none>
# grafana-79f4b5649f-6sjg5 1/1 Running 0 105m 10.244.1.159 k8s-node-4 <none> <none>
# kube-state-metrics-58c88f48b7-frqb2 3/3 Running 0 105m 10.244.1.160 k8s-node-4 <none> <none>
# node-exporter-4nmsz 2/2 Running 0 105m 10.10.107.214 k8s-node-4 <none> <none>
# node-exporter-7x6bm 2/2 Running 0 105m 10.10.107.215 k8s-node-5 <none> <none>
# node-exporter-98crd 2/2 Running 0 105m 10.10.107.202 ubuntu <none> <none>
# prometheus-adapter-69b8496df6-7mqcv 1/1 Running 0 105m 10.244.2.63 k8s-node-5 <none> <none>
# prometheus-k8s-0 2/2 Running 1 105m 10.244.1.158 k8s-node-4 <none> <none>
# prometheus-k8s-1 2/2 Running 0 105m 10.244.2.62 k8s-node-5 <none> <none>
# prometheus-operator-5bff4cfb76-dtvjj 2/2 Running 0 5h26m 10.244.2.59 k8s-node-5 <none> <none>
Step 4.查看Services资源清单得到
prometheus、grafana、alertmanager
暴露的端口
~/K8s/Day10/kube-prometheus/manifests$ kubectl get svc -n monitoring -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
prometheus-adapter ClusterIP 10.100.45.247 <none> 443/TCP 122m name=prometheus-adapter
prometheus-operator ClusterIP None <none> 8443/TCP 5h42m app.kubernetes.io/component=controller,app.kubernetes.io/name=prometheus-operator
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 122m app.kubernetes.io/name=kube-state-metrics
prometheus-operated ClusterIP None <none> 9090/TCP 122m app=prometheus
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 122m app=alertmanager
node-exporter ClusterIP None <none> 9100/TCP 122m app.kubernetes.io/name=node-exporter
alertmanager-main NodePort 10.100.233.132 <none> 9093:30070/TCP 122m alertmanager=main,app=alertmanager
prometheus-k8s NodePort 10.103.33.255 <none> 9090:30090/TCP 122m app=prometheus,prometheus=k8s
grafana NodePort 10.104.211.111 <none> 3000:30080/TCP 122m app=grafana
应用IP端口访问列表:
prometheus 对应的 nodeport 端口为 30080 访问 http://10.10.107.202:30080
grafana 对应的 nodeport 端口为 30080 访问 http://10.10.107.202:30080
alertmanager 对应的 nodeport 端口为 30070 访问 http://10.10.107.202:30070
PS : 下面验证上述服务能否正常访问
Step 5.访问 prometheus
Web UI
可以看到其已经与K8S的Api-Server连接成功;
URL: http://10.10.107.202:30090/graph?g0.range_input=1h&g0.expr=sum(rate(container_cpu_usage_seconds_total{image!%3D""}[1m]))%20by%20(pod_name%2C%20namespace)&g0.tab=0
# Prometheus 自己的指标prometheus 的 WEB 界面上提供了基本的查询 K8S 集群中每个 POD 的 CPU 使用情况,查询条件如下
sum(rate(container_cpu_usage_seconds_total{image!=""}[1m])) by (pod_name, namespace) # PS:内置函数后面细讲
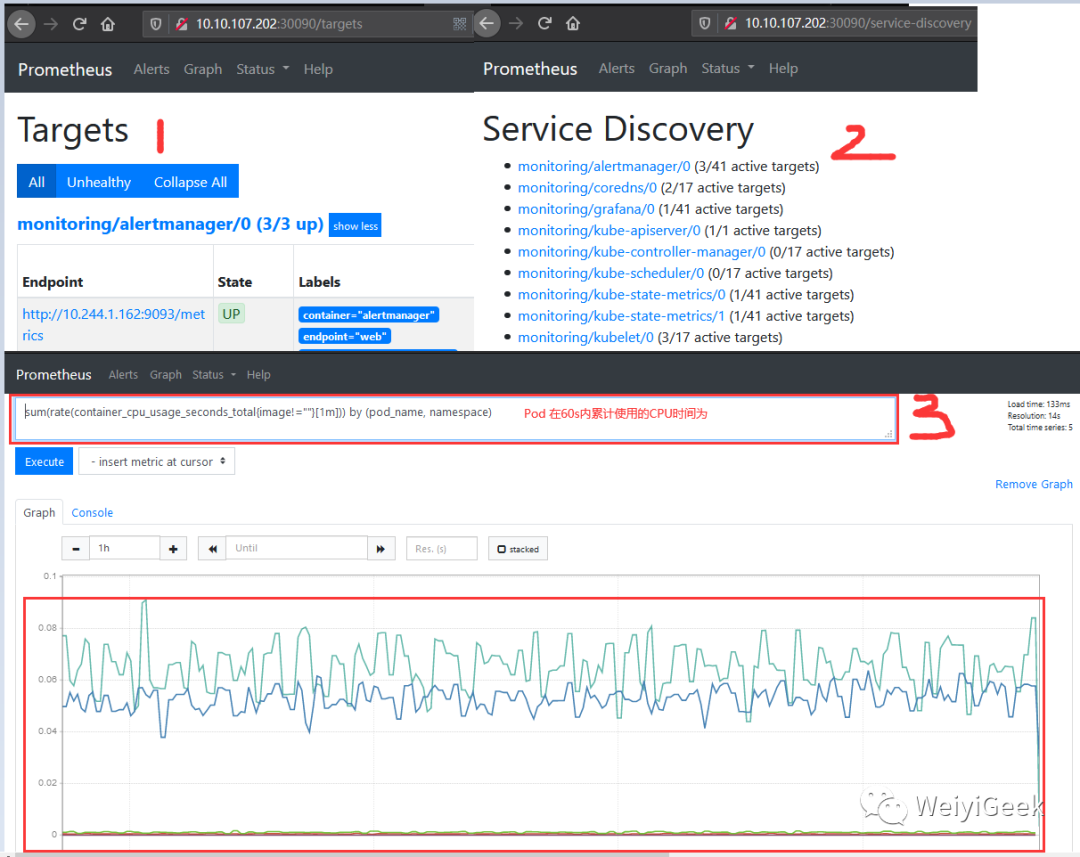
PS : 上述的查询有出现数据说明node-exporter往Prometheus中写数据是正常的,接下来查看你我们的grafana组件实现更友好的数据展示
Step 6.访问grafana Web UI进行数据图形化展示,缺省账号密码admin、admin,登录后要设置新的密码weiyigeek;
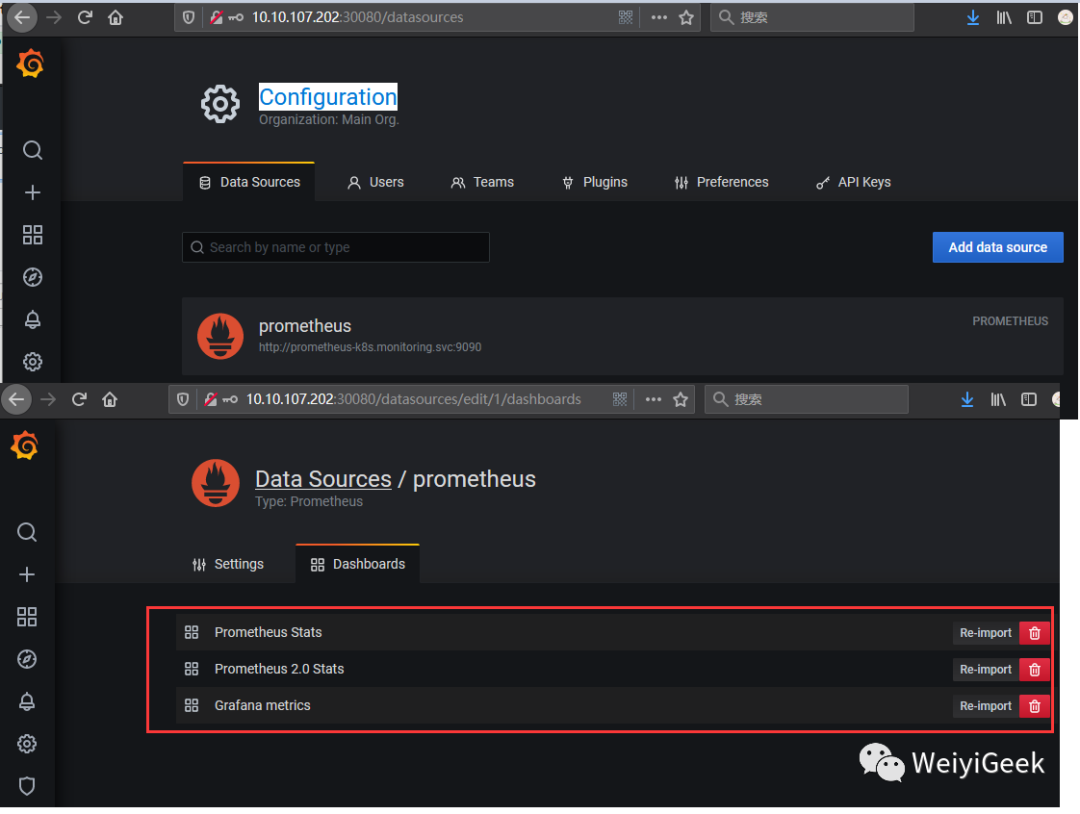
随后在Grafana中添加Prometheus
数据源进行数据的展示: Configuration -> Data Source -> prometheus -> 导入指定 prometheus
;
采用 Grafana 展示的 Prometheus 数据: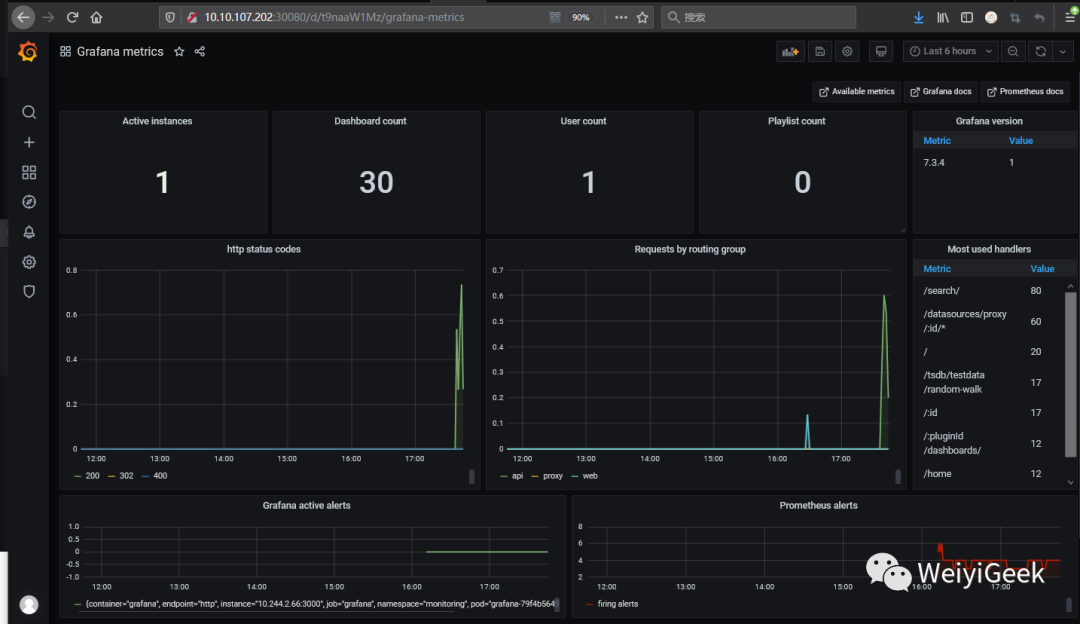
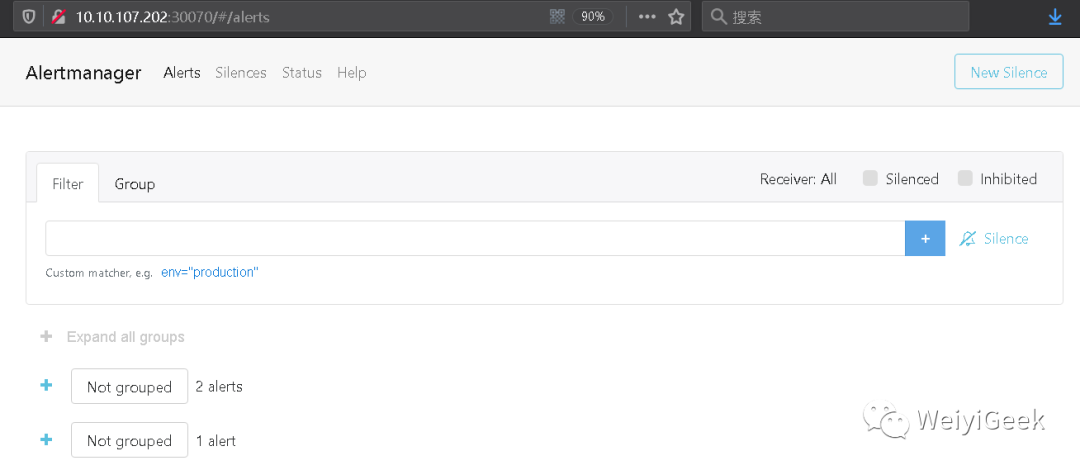
Step 7.访问 alertmanager 的 Web UI 进行查看预警;
Step 8.至此采用Helm安装Prometheus完成,但是它仅仅是个示例我们需要对其做完整的安全保护(访问限制、访问认证可以在Nginx中进行配置)
# 关注 WeiyiGeek 微信公众号

历史文章:
3-Kubernetes入门之CentOS上安装部署k8s集群
4-Kubernetes入门之Ubuntu上安装部署k8s集群
