





文章转载自公众号:PostgreSQL学徒
作者:熊灿灿
前言
今天群里有位童鞋提到,我不小心删除了一条数据,怎么找回呢?群里的各位大仙各显神通,一阵操作,大概统计了一下,不下五六种方法,方方面面,十分完备。不过遗憾的是,对于新人来说可能不太友好。实际运维过程中,我们肯定也遇到过开发人员或者我们自身,由于各种原因不小心删除了数据,那么有没有后悔药呢?
恢复大法
备份大法
最先想到的当然就是备份大法了,PostgreSQL提供了多种备份方式:
pg_dump/pg_dumpall + psql/pg_restore和copy逻辑备份
pg_basebackup物理备份
第三方备份工具
pg_probackup:支持并行、一致性校验和备份压缩登,不过pg_probackup有一个严重的bug,其寻址范围最大只支持4GB,也就意味着不管你什么文件备份下来最大只有4GB,假如修改了segment size 并且大于4GB,也就意味着备份是不完整的,数据不可靠
pg_backrest:支持S3和Azure兼容对象存储、一致性校验
pg_barman:可提供可靠的监控信息、备份加密
pg_rman:不支持流复制协议,意味着只能和数据节点跑在一
文件系统级的备份,比如ZFS snapshot、Logical Volume Manager等
再结合归档,实现PITR(Point-in-Time Recovery)
postgres=# select name from pg_settings where name like '%recovery%'; name ---------------------------recovery_end_commandrecovery_min_apply_delayrecovery_targetrecovery_target_actionrecovery_target_inclusiverecovery_target_lsnrecovery_target_namerecovery_target_timerecovery_target_timelinerecovery_target_xid
不过需要确保有误操作前的全量备份和所有WAL归档,因此RTO和RPO的选择至关重要。
pg_resetwal
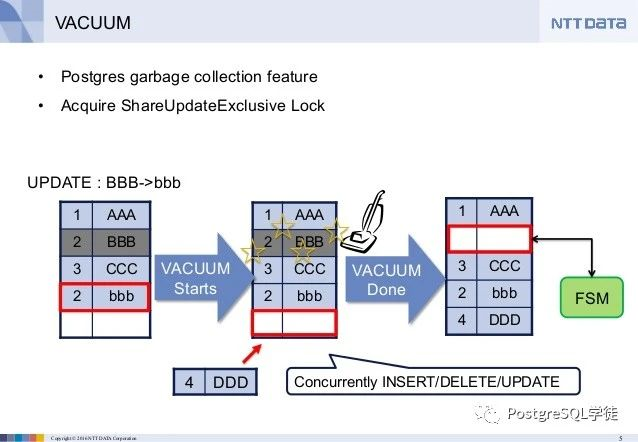
我们知道PostgreSQL的多版本原理是旧数据并不删除:
对于删除数据的操作,只是把行上的xmax改成当前的事务id
对于更新操作,只是把原先行上xmax改成当前的事务id,并插入一个新行,而新行上的xmin置为当前的事务id
所以,假如数据还没有被vacuum进程清理掉的话,那么就可以找回来。演示一下,表级关闭autovacuum,防止数据被vacuum掉了:
postgres=# create table test(id int,info text);CREATE TABLEpostgres=# alter table test set (autovacuum_enabled = off);ALTER TABLEpostgres=# insert into test values(1,'test');INSERT 0 1postgres=# insert into test values(2,'test');INSERT 0 1postgres=# insert into test values(3,'test');INSERT 0 1postgres=# select xmin,xmax,id from test;xmin | xmax | id---------+------+----4491454 | 0 | 14491455 | 0 | 24491456 | 0 | 3(3 rows)postgres=# delete from test where id = 2;DELETE 1postgres=# select xmin,xmax,id from test;xmin | xmax | id---------+------+----4491454 | 0 | 14491456 | 0 | 3(2 rows)
使用pageinspect插件观察一下,可以看到,第二行数据被4491457事务删除了
postgres=# select * from heap_page_items(get_raw_page('test','main', 0));lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data ----+--------+----------+--------+---------+---------+----------+--------+-------------+------------+--------+--------+-------+---------------------- 1 | 8152 | 1 | 33 | 4491454 | 0 | 0 | (0,1) | 2 | 2306 | 24 | | | \x010000000b74657374 2 | 8112 | 1 | 33 | 4491455 | 4491457 | 0 | (0,2) | 8194 | 1282 | 24 | | | \x020000000b74657374 3 | 8072 | 1 | 33 | 4491456 | 0 | 0 | (0,3) | 2 | 2306 | 24 | | | \x030000000b74657374(3 rows)
使用pg_resetwal篡改一下事务号,-x, --next-transaction-id=XID set next transaction ID,当然pg_resetwal还有其他很多骚操作,比如修改oid的下一个值,让oid重复(oid重复不会像事务ID回卷那么严重),篡改了事务ID之后,之前的那一条数据就回来了,其实这个还是因为PostgreSQL MVCC实现原理的体现(删除的事务是未来的,所以删除数据的事务还未发生,也即可见)所以在某些非常规的情况下可以使用这种方法来应急找到还没来得及被vacuum掉的死元组记录内容。
[postgres@xiongcc ~]$ pg_ctl -D pgdata/ stopwaiting for server to shut down.... doneserver stopped[postgres@xiongcc ~]$ pg_resetwal -x 4491454 -D pgdata/Write-ahead log reset[postgres@xiongcc ~]$ pg_ctl -D pgdata/ startwaiting for server to start....2021-07-08 22:52:13.868 CST [10336] LOG: redirecting log output to logging collector process2021-07-08 22:52:13.868 CST [10336] HINT: Future log output will appear in directory "log".doneserver started[postgres@xiongcc ~]$ psqlpsql (13.2)Type "help" for help.postgres=# select * from test;id | info----+------(0 rows)postgres=# select txid_current();txid_current-------------- 4491454(1 row)postgres=# select * from test;id | info----+------ 1 | test(1 row)postgres=# select txid_current();txid_current-------------- 4491455(1 row)postgres=# select * from test;id | info----+------ 1 | test 2 | test(2 rows)
pg_tm_aux
这个之前逻辑复制有介绍,超级复制槽pg_tm_aux,可以创建指定LSN的复制槽,不过唯一遗憾的是,需要有复制标识才能解析出删除和更新的动作,而这恰恰又是逻辑复制才会去特别设置的。看下效果:
postgres=# begin;BEGINpostgres=*# select pg_current_wal_lsn();pg_current_wal_lsn--------------------6/47008F18(1 row)postgres=*# insert into test values(1);INSERT 0 1postgres=*# insert into test values(2);INSERT 0 1postgres=*# insert into test values(3);INSERT 0 1postgres=*# commit ;COMMITpostgres=# begin;BEGINpostgres=*# select pg_current_wal_lsn();pg_current_wal_lsn--------------------6/47009168(1 row)postgres=*# delete from test where id = 2;DELETE 1postgres=*# commit ;COMMIT
然后创建删除之前的复制槽,进行解析,可以看到成功解析了出来,删除了id = 2,自己拼装成undo SQL即可,lsn可以通过pg_waldump相应时间段的WAL日志,获取一个大概时间点的LSN,进行解析。
postgres=# select pg_create_logical_replication_slot_lsn('myslot','decoder_raw',false,pg_lsn('6/47008F18'));pg_create_logical_replication_slot_lsn----------------------------------------(myslot,6/47008F18)(1 row)postgres=# select * from pg_logical_slot_get_changes('myslot', NULL, NULL); lsn | xid | data ------------+---------+---------------------------------------6/47009168 | 4491487 | DELETE FROM public.test WHERE id = 2;(1 row)
pg_waldump
pg_waldump的原理是类似的,通过解析WAL日志,找到大概的误操作事务号,然后使用pg_resetwal篡改事务号,比如如下DELETE,找到对应的事务号为710。
pg_waldump -s 2/C001CA88 -p /opt/thunisoft/abdata/6.0/abase1/pg_wal/rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 2/C001CA88, prev 2/C001CA60, desc: RUNNING_XACTS nextXid 710 latestCompletedXid 709 oldestRunningXid 710rmgr: Heap len (rec/tot): 54/ 54, tx: 710, lsn: 2/C001CAC0, prev 2/C001CA88, desc: DELETE off 6 KEYS_UPDATED , blkref #0: rel 1663/13231/25679 blk 0rmgr: Heap len (rec/tot): 54/ 54, tx: 710, lsn: 2/C001CAF8, prev 2/C001CAC0, desc: DELETE off 7 KEYS_UPDATED , blkref #0: rel 1663/13231/25679 blk 0rmgr: Heap len (rec/tot): 54/ 54, tx: 710, lsn: 2/C001CB30, prev 2/C001CAF8, desc: DELETE off 8 KEYS_UPDATED , blkref #0: rel 1663/13231/25679 blk 0rmgr: Heap len (rec/tot): 54/ 54, tx: 710, lsn: 2/C001CB68, prev 2/C001CB30, desc: DELETE off 9 KEYS_UPDATED , blkref #0: rel 1663/13231/25679 blk 0rmgr: Heap len (rec/tot): 54/ 54, tx: 710, lsn: 2/C001CBA0, prev 2/C001CB68, desc: DELETE off 10 KEYS_UPDATED , blkref #0: rel 1663/13231/25679 blk 0rmgr: Transaction len (rec/tot): 34/ 34, tx: 710, lsn: 2/C001CBD8, prev 2/C001CBA0, desc: COMMIT 2021-06-09 15:30:35.334034 CSTrmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 2/C001CC00, prev 2/C001CBD8, desc: RUNNING_XACTS nextXid 711 latestCompletedXid 710 oldestRunningXid 711rmgr: XLOG len (rec/tot): 24/ 24, tx: 0, lsn: 2/C001CC38, prev 2/C001CC00, desc: SWITCHrmgr: XLOG len (rec/tot): 106/ 106, tx: 0, lsn: 2/C1000028, prev 2/C001CC38, desc: CHECKPOINT_SHUTDOWN redo 2/C1000028; tli 1; prev tli 1; fpw true; xid 0:711; oid 25682; multi 1; offset 0; oldest xid 563 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 0; shutdownrmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 2/C1000098, prev 2/C1000028, desc: RUNNING_XACTS nextXid 711 latestCompletedXid 710 oldestRunningXid 711pg_waldump: FATAL: error in WAL record at 2/C1000098: invalid record length at 2/C10000D0: wanted 24, got 0
当然也可以通过PITR恢复,指定具体的xid即可,前提是有个基础备份 + 连续时间WAL归档。
recovery_target_inclusive = truerestore_command = 'cp /archive_dir/%f %p'recovery_target_xid = '710'recovery_target_timestandby_mode = onpause_at_recovery_target = true
pg_filedump
postgres=# create table test(id int,info text);CREATE TABLEpostgres=# insert into test select n,'test' from generate_series(1,10) as n;INSERT 0 10postgres=# select pg_relation_filepath('test');pg_relation_filepath----------------------base/13578/80076(1 row)postgres=# checkpoint ;CHECKPOINT
使用pg_filedump看一下具体的数据,可以看到COPY行的就是具体的数据了
[postgres@xiongcc ~]$ pg_filedump -D int,text pgdata/base/13578/80076******************************************************************** PostgreSQL File/Block Formatted Dump Utility** File: pgdata/base/13578/80076* Options used: -D int,text*******************************************************************Block 0 ********************************************************<Header> -----Block Offset: 0x00000000 Offsets: Lower 64 (0x0040)Block: Size 8192 Version 4 Upper 7792 (0x1e70)LSN: logid 6 recoff 0x4700f6b0 Special 8192 (0x2000)Items: 10 Free Space: 7728Checksum: 0x0000 Prune XID: 0x00000000 Flags: 0x0000 ()Length (including item array): 64<Data> -----Item 1 -- Length: 33 Offset: 8152 (0x1fd8) Flags: NORMALCOPY: 1testItem 2 -- Length: 33 Offset: 8112 (0x1fb0) Flags: NORMALCOPY: 2testItem 3 -- Length: 33 Offset: 8072 (0x1f88) Flags: NORMALCOPY: 3testItem 4 -- Length: 33 Offset: 8032 (0x1f60) Flags: NORMALCOPY: 4testItem 5 -- Length: 33 Offset: 7992 (0x1f38) Flags: NORMALCOPY: 5testItem 6 -- Length: 33 Offset: 7952 (0x1f10) Flags: NORMALCOPY: 6testItem 7 -- Length: 33 Offset: 7912 (0x1ee8) Flags: NORMALCOPY: 7testItem 8 -- Length: 33 Offset: 7872 (0x1ec0) Flags: NORMALCOPY: 8testItem 9 -- Length: 33 Offset: 7832 (0x1e98) Flags: NORMALCOPY: 9testItem 10 -- Length: 33 Offset: 7792 (0x1e70) Flags: NORMALCOPY: 10test*** End of File Encountered. Last Block Read: 0 ***
删除一条数据
postgres=# delete from test where id = 10;DELETE 1postgres=# checkpoint ;CHECKPOINTpostgres=# select * from test;id | info----+------ 1 | test 2 | test 3 | test 4 | test 5 | test 6 | test 7 | test 8 | test 9 | test(9 rows)
继续dump,可以发现还是有10条数据
<Data> -----Item 1 -- Length: 33 Offset: 8152 (0x1fd8) Flags: NORMALCOPY: 1testItem 2 -- Length: 33 Offset: 8112 (0x1fb0) Flags: NORMALCOPY: 2testItem 3 -- Length: 33 Offset: 8072 (0x1f88) Flags: NORMALCOPY: 3testItem 4 -- Length: 33 Offset: 8032 (0x1f60) Flags: NORMALCOPY: 4testItem 5 -- Length: 33 Offset: 7992 (0x1f38) Flags: NORMALCOPY: 5testItem 6 -- Length: 33 Offset: 7952 (0x1f10) Flags: NORMALCOPY: 6testItem 7 -- Length: 33 Offset: 7912 (0x1ee8) Flags: NORMALCOPY: 7testItem 8 -- Length: 33 Offset: 7872 (0x1ec0) Flags: NORMALCOPY: 8testItem 9 -- Length: 33 Offset: 7832 (0x1e98) Flags: NORMALCOPY: 9testItem 10 -- Length: 33 Offset: 7792 (0x1e70) Flags: NORMALCOPY: 10test
加一个 -o Do not dump old values即可,可以看到第10行被删除了 tuple was removed by transaction #4491493,重新插入这条数据即可
<Data> -----Item 1 -- Length: 33 Offset: 8152 (0x1fd8) Flags: NORMALCOPY: 1testItem 2 -- Length: 33 Offset: 8112 (0x1fb0) Flags: NORMALCOPY: 2testItem 3 -- Length: 33 Offset: 8072 (0x1f88) Flags: NORMALCOPY: 3testItem 4 -- Length: 33 Offset: 8032 (0x1f60) Flags: NORMALCOPY: 4testItem 5 -- Length: 33 Offset: 7992 (0x1f38) Flags: NORMALCOPY: 5testItem 6 -- Length: 33 Offset: 7952 (0x1f10) Flags: NORMALCOPY: 6testItem 7 -- Length: 33 Offset: 7912 (0x1ee8) Flags: NORMALCOPY: 7testItem 8 -- Length: 33 Offset: 7872 (0x1ec0) Flags: NORMALCOPY: 8testItem 9 -- Length: 33 Offset: 7832 (0x1e98) Flags: NORMALCOPY: 9testItem 10 -- Length: 33 Offset: 7792 (0x1e70) Flags: NORMALtuple was removed by transaction #4491493
pageinspect
这个是PostgreSQL自带的一款插件,原理也是类似,可以解析出t_data的十六进制的值
postgres=# create table test(id int,info varchar(4));CREATE TABLEpostgres=# insert into test values(1,'test');INSERT 0 1postgres=# insert into test values(2,'test');INSERT 0 1postgres=# delete from test where id = 2;DELETE 1postgres=# select * from heap_page_items(get_raw_page('test', 'main', 0));lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data ----+--------+----------+--------+---------+---------+----------+--------+-------------+------------+--------+--------+-------+---------------------- 1 | 8152 | 1 | 33 | 4491509 | 0 | 0 | (0,1) | 2 | 2306 | 24 | | | \x010000000b74657374 2 | 8112 | 1 | 33 | 4491510 | 4491511 | 0 | (0,2) | 8194 | 258 | 24 | | | \x020000000b74657374(2 rows)
然后使用tuple_data_split解析一下,74657374则是test,02000000则是 2,说明删除的是id = 2,info = test
postgres=# SELECT tuple_data_split('test'::regclass, t_data, t_infomask, t_infomask2, t_bits) FROM heap_page_items(get_raw_page('test', 0)); tuple_data_split ---------------------------------{"\\x01000000","\\x0b74657374"}{"\\x02000000","\\x0b74657374"}(2 rows)


walminer
这个是一个对标MySQL中的binlog2sql的日志解析工具,
https://gitee.com/movead/XLogMiner
通过walminer,可以逆向解析出undo sql,如下,比如误删一条数据,那么拿出相应的undo sql重新insert一下即可,和decoder_raw是十分类似的。
postgres=# select * from walminer_contents;-[ RECORD 1 ]-------------------------------------------------------------sqlno | 1xid | 268435484topxid | 0sqlkind | 1minerd | ttimestamp | 2020-06-18 11:14:45.380952+08op_text | INSERT INTO public.t1(i ,j ,k) VALUES(3 ,1 ,'after truncate')undo_text | DELETE FROM public.t1 WHERE i=3 AND j=1 AND k='after truncate'complete | t
pg_fix
事务的状态是记录在commit log中的,如果事务提交,只是把commit log中相应的事务状态改成"已提交状态",如果事务回滚,则把commit log中的事务状态改成"事务回滚",所以从理论上说,只要把在commit log中刚提交事务状态从"TRANSACTION_STATUS_COMMITTED"改成"TRANSACTION_STATUS_ABORTED",原先的事务就会做废,就能回到事务之前的状态。但同时tuple上面还由于有infomask标志位的存在,加速获取事务状态。所以要想恢复数据,还需要把相应表文件中各行上的t_infomask状态中的hint标志位给清除掉之后,数据才能恢复回来。为此,唐成老师专门写了一个工具,pg_fix,https://github.com/osdba/pg_fix,直接修改表中数据和commit log中事务的状态,注意生产上慎用。
pg_dirtyread
可以读取未被vacuum的dead数据,https://github.com/df7cb/pg_dirtyread
The pg_dirtyread extension provides the ability to read dead but unvacuumed rows from a relation. Supports PostgreSQL 9.2 and later. (On 9.2, at least 9.2.9 is required.)
CREATE EXTENSION pg_dirtyread; CREATE TABLE foo (bar bigint, baz text); ALTER TABLE foo SET ( autovacuum_enabled = false, toast.autovacuum_enabled = false);INSERT INTO foo VALUES (1, 'Test'), (2, 'New Test'); DELETE FROM foo WHERE bar = 1; SELECT * FROM pg_dirtyread('foo') as t(bar bigint, baz text);bar │ baz─────┼────────── 1 │ Test 2 │ New Test
控制vacuum
我们知道在PostgreSQL的MVCC实现方式中,死元组并不会立即删除,而是由后台vacuum进程去定期清理那些"不可见"的死元组。所以还有一种操作是,把autovacuum设为off,关闭后台自动清理进程,由自己手动去执行vacuum的动作,这样那些未执行过vacuum的表里的死元组就会一直保留,然后通过pg_resetwal"篡改"数据库的事务号,达到数据可见的目的。注意关闭autovacuum会导致表膨胀,除非你知道自己在干什么,否则不要关闭autovacuum,对更新频繁的数据库或表更要慎重使用这一技巧。并且这种方式不适用于drop table,vacuum full和truncate等DDL,会提示/base/xxx not exists,因为原来的数据文件已经被删了。
另外一个可以控制vacuum的参数较vacuum_defer_cleanup_age,延迟多少个事务进行清理,比如设置为100,也不会立马删除,留下抢救的时机。当然还有一些歪门邪道,比如备库上跑个大查询,同时打开hot_standby_feedback,让发回的xmin特别小,这样主库即时vacuum开着,也会手下留情,不去vacuum删除那些行,也给我们留下了抢救的余地。
全日志
这个就简单了,假如设置了log_statement = all的话,日志里就会有记录,不过要考虑清楚,日志量会很大
postgres=# create table test(id int);CREATE TABLEpostgres=# insert into test values(generate_series(1,10));INSERT 0 10postgres=# delete from test where id = 9DELETE 1
日志记录很清楚
2021-07-09 00:00:04.961 CST,"postgres","postgres",10890,"[local]",60e720e2.2a8a,6,"idle",2021-07-08 23:59:30 CST,3/18,0,LOG,00000,"statement: delete from test where id = 9;",,,,,,,,,"psql","client backend"
pg_stat_monitor
这个也是一个类似的原理,得益于pg_stat_monitor的Capture Actual Parameters in the Queries功能,通过配置参数,就可以看到具体的参数了,而不是类似于扩展协议绑定变量这种,看到的都是$1 $2这种云云,在我们定位问题中,往往都会随便传入一两个值,这样的话就很有可能因为参数传入不对导致数据倾斜未走索引。
其他能达到类似审计效果的比如pg_audit、pg_log_userqueries、pgreplay等,也是类似原理,记录在审计日志中。
postgres=# select query from pg_stat_monitor where query like '%delete%'; query ----------------------------------------------------------------select * from pg_stat_monitor wher query like '%delete%';delete from test where id = 9;(2 rows)
延迟备库
对于实际生产环境,肯定会使用流复制构建高可用,在PostgreSQL,还提供了一个强大功能,延迟备库,也就是这个参数做的事情,recovery_min_apply_delay,该参数指定延迟备库,设置备库延迟重做WAL的时间,而备库依然及时接收主库发送的WAL日志流,只是不是一接收到WAL后就立即应用,而是等待此参数设置的值再进行应用。所以如果你在主机执行了一个没有条件筛选的delete操作,幡然醒悟。这时delete操作还没有同步到备机,可以赶紧采取紧急措施补救数据。不过,官方文档写的很清楚:
Warning
Synchronous replication is affected by this setting when synchronous_commit is set to remote_apply; every COMMIT will need to wait to be applied.
也就是说,延迟备库场景下,
synchronous_commit 为 remote_apply 时,会造成主库上面的事务的提交的阻塞,每一条事务都会等待这么久才提交,
synchronous_commit 为 on 时,备库写入到WAL文件时就返回,不会阻塞,好在这也是默认值。
此处推荐看一下昨日墨天轮新鲜出炉的文章:《基于PostgreSQL流复制的容灾库架构设想及实现》
闪回
Oracle支持强大的闪回,闪回特性使用场景:
flashback database:数据库闪回;多用于数据库恢复,数据库、用户、表空间误删。
flashback table:表闪回;用于数据表恢复;数据表误删。
flashback query:闪回查询;应用于修复误操作数据。
此处可以参考德哥的文章,PostgreSQL中的一系列闪回方法:PgSQL 应用案例 PostgreSQL flashback(闪回) 功能实现与介绍
垃圾回收站
pgtrashcan垃圾回收工具,https://github.com/petere/pgtrashcan,就像windows中的回收站,删除了文件后,是放在回收站的,可以选择还原,找回相关文件。同样,当我们删除PostgreSQL表后,表并不会立即物理删除,而是先保存到回收站中,在需要时可以恢复表。当DROP TABLE命令执行后,表会被移到一个名为"Trash"的schema下,如果想永久删除此表,可以删除"Trash"模式下的这张表或者删除整个"Trash" 模式,这个pgtrashcan仅对表有效,其它数据库对像被删除后不会转移到"Trash"模式。
小结
总之,备份还是最简单粗暴的,再搭配上各种各样的工具,其实论原理,基本还是从MVCC的实现方式上去实现了数据的找回。





新闻|Babelfish使PostgreSQL直接兼容SQL Server应用程序

更多新闻资讯,行业动态,技术热点,请关注中国PostgreSQL分会官方网站
https://www.postgresqlchina.com
中国PostgreSQL分会生态产品
https://www.pgfans.cn
中国PostgreSQL分会资源下载站
https://www.postgreshub.cn


点击此处阅读原文
↓↓↓
