




一、环境
| 主机名 | IP | 角色 | 端口 | nodename | 数据目录 |
| gtm | 192.168.80.230 | GTM | 6666 | gtm | /DATA/gtm |
| pg1 | 192.168.80.220 | Coordinator | 5432 | coord1 | /DATA/coord |
| Datanode | 5433 | dn1 | /DATA/dn | ||
| Gtm Proxy | 6666 | gtm_proxy1 | /DATA/gtm_proxy | ||
| pg2 | 192.168.80.221 | Coordinator | 5432 | coord2 | /DATA/coord |
| Datanode | 5433 | dn2 | /DATA/dn | ||
| Gtm Proxy | 6666 | gtm_proxy2 | /DATA/gtm_proxy | ||
| pg3 | 192.168.80.223 | Coordinator | 5432 | coord3 | /DATA/coord |
| Datanode | 5433 | dn3 | /DATA/dn | ||
| Gtm Proxy | 6666 | gtm_proxy3 | /DATA/gtm_proxy |
二、Postgres-XL集群进程状态
2.1 执行insert操作时进程状态
下面通过任选一个coordinate节点执行insert操作时,各节点进程状态情况来举例说明:
先创建一个表,该表有两列,该表数据分布采用hash方式,分布列为第一列,命令如下:
create table test_hash(a integer ,y character(3)) DISTRIBUTE BY hash(a) TO NODE (dn1,dn2,dn3);通过一条insert语句,往该表中中插入若干行数据(此处为了便于观察每个节点的pgxl各进程状态,故插入100W行,且字符串采用随机方式生成,从而延长插入时间),其中第一列采用generate_series函数生成1~100W的序列数,第二列采用自定义的random_string函数生成随机字符串;在pg2的coord2上执行如下插入语句:
insert into test_hash select generate_series(1,1000000),random_string(3);此时观察pg1、pg2、pg3三个节点上coordinate和datanode进程的情况,分别如下:
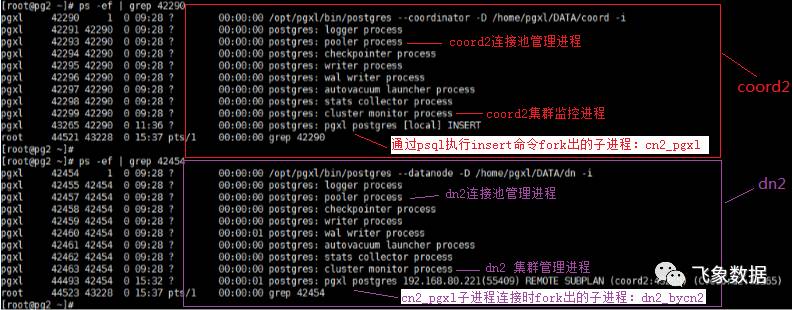
pg2节点的coord2和dn2进程情况如下图所示
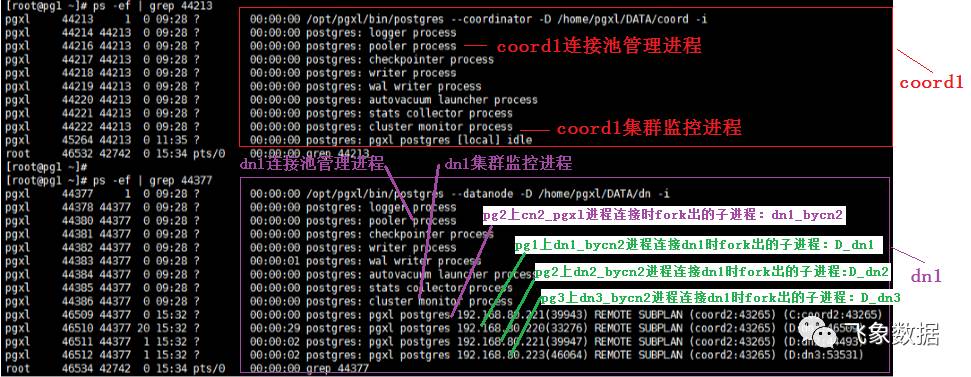
pg1节点的coord1和dn1进程情况如下图所示:
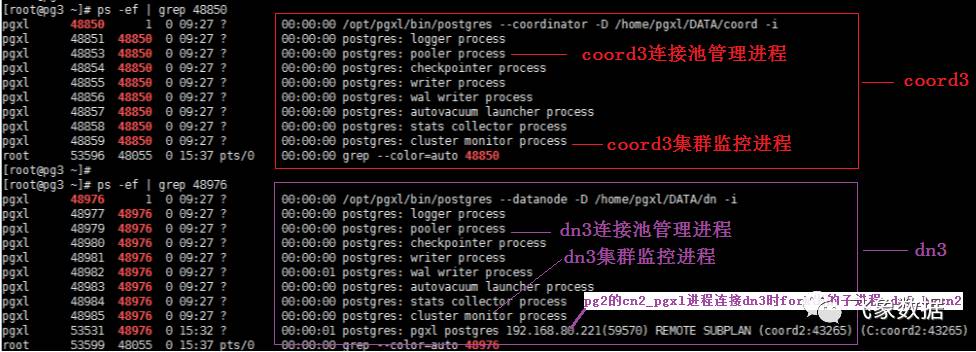
pg3节点的coord3和dn3进程情况如下图所示:
2.2 pgxl和postgres进程数对比
所以,如果该insert操作涉及到N个datanode,而有num个客户端同时执行该insert操作,那么将会增加(1 + 2N)num 个进程数(相比于空闲状态下);
注:因为此例的insert操作不涉及表之间的关联操作,一旦涉及到表关联操作,其新增加的进程数会成倍增加,比如如下一条insert,当涉及3个datanode时,即使一个insert操作,也会增加(1+23)3 = 21个由三个datanode进程fork出的子进程:
insert into test0 select test1.* from test1,test2 where test1.y=test2.y and test2.a < 110;

2.3 执行insert操作时datanode进程fork出的两类子进程
第一类:由coordinate进程fork出的子进程连接datanode,从而使该datanode进程fork出一个子进程,具体步骤为:
步骤1、当前处理insert操作的coordinate进程会fork出一个子进程cn_pgxl,用于处理该insert请求;
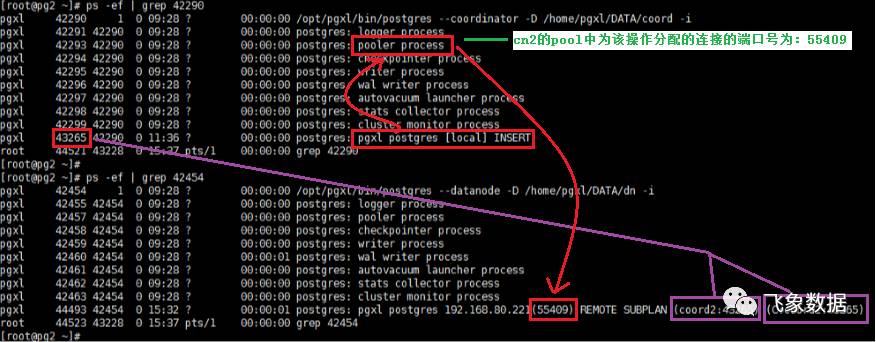
步骤2、该子进程cn_pgxl会从coordinate的连接池cn_pool中选择一个空闲连接(若没有则新建),使其连接datanode监听端口(此处5433);
步骤3、datanode进程接到连接请求后,会fork出一个子进程dn_bycn,用于和cn_pgxl进行数据交互。 注1:此处datanode进程fork出的子进程dn_bycn,是为了实现分布式事务两阶段提交中最后一步提交操作,同时他也会在某些特定情况下生成执行计划(后面会叙述)。 注2:若该操作涉及N个datanode,那么cn_pgxl进程会通过cn_pool选择N个可用连接,分别和N个datanode节点重复执行步骤2和步骤3,从而使得每个datanode上都会fork出一个子进程用于和cn_pgxl进程进行交互。
第二类:进程dn_bycn和datanode进行连接,使其fork出一个子进程D_dn,具体步骤如下。
步骤4、在前面步骤3中fork出的子进程dn_bycn,会从其所在datanode的连接池dn_pool中选择一个空闲连接(若没有则新建),使其连接此次操作选择出的主datanode(注:选择策略暂时未知,后续研究)的监听端口(此处5433);
步骤5、主datanode接到连接请求后,会fork出一个子进程D_dn,让其处理dn_bycn进程的请求,并和其进行数据交互。 注1、此处datanode进程fork出的子进程D_dn,是为了实现分布式事务两阶段提交中保证分布式事务原子性的,它专门用于让事务在提交前尽可能地完成所有能完成的工作,这样,最后的提交阶段将是一个耗时极短的微小操作,这种操作在一个分布式系统中失败的概率是非常小的。 注2、若该操作涉及有N个datanode,则每个datanode上fork出的子进程dn_bycn都会和此次选中的主datanode(不固定)进行连接,从而在主datanode上会fork出N个D_dn子进程,用于和dn_bycn进行数据交互。
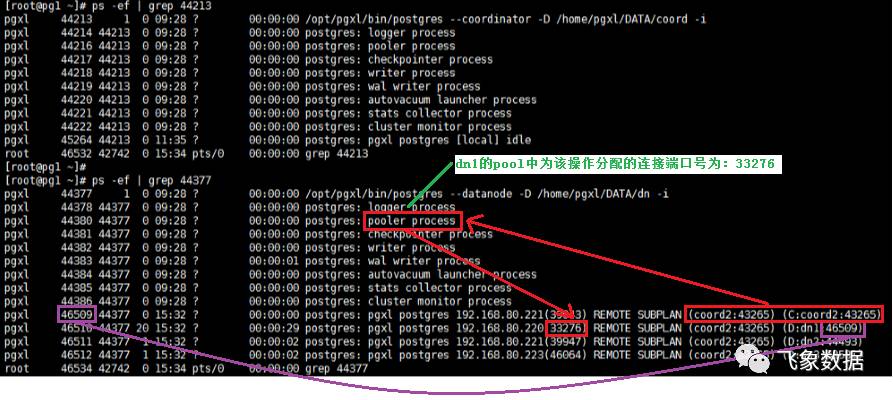
从上图中可以看出,因为有三个datanode,所以在pg1的dn1中fork出了三个子进程D_dn1、D_dn2、D_dn3。
扫码关注了解更多

