





知其然,
知其所以然。
摘要:本文由以数据之名分享,正所谓“无论为哀为乐,为怨为怒,为恋为骇,为忧为惭,常若知其然而不知其所以然”。前面的那篇文章“Kettle知识库问答系列之三十而立”,叙述了使用Kettle作为ETL开发的常见组件使用说明、业务场景实现逻辑以及组件性能优化相关内容名。今天,我们跟着小编的节奏,继续探讨Kettle知识库问答系列之四十不惑篇,做到“知其然,亦知其所以然”。

第031问:插入更新有没有什么合适的替代方案?
第031答:首先,我们必须承认插入更新组件是数据增量清洗的必不可少的组件,它的组件效率不能主观地说很低,这跟我们的使用(场景依据&使用方式&实际数据)有密不可分的关联。前面我们已经讲过如何优化插入更新组件的执行效率,下面我们继续探讨平行方案:
1、先删除,后插入。每批次数据(N)都是全量(删除N),数据库碎片太多 ;
2、先插入,异常数据再更新(适合同批次数据更新较少,插入较多的情况)。但目标数据库服务端冲突插入异常较多,异常数量跟数据冲突成正相关。总结:三种方案具体执行效率高低,跟数据有关,不能一概而论。
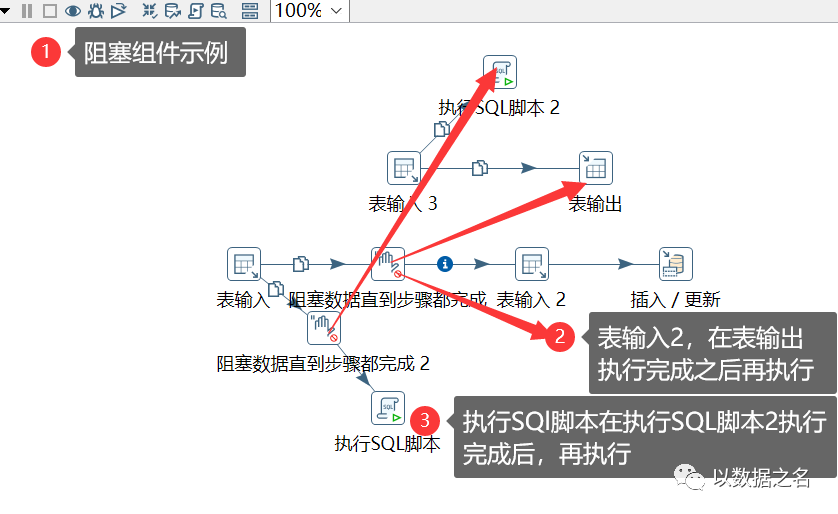
第032问:kettle阻塞组件如何使用?
第032答:转换内使用阻塞组件,要遵循以下两个原则:
1、必须有两个及以上的分支,使用阻塞才会生效;
2、阻塞组件只能阻塞另一分支的某个步骤,且保证该步骤执行完成后,才执行阻塞组件当前所在分支后面的步骤;
3、如果要在输入input组件或者Sql脚本组件前加阻塞,需要双重输入才可以控制,如果没有需要如图虚构一个输入(比如此处表输入,输出一个常量值“A”;作为后面的输入和SQL脚本的参数,虚构一个where条件如"A=?")
4、3的虚构输入,主要目的是为了控制参数绑定成功后,再执行后续的输入或SQL脚本操作,以保证业务逻辑事务的先后顺序。
5、示例获取,关注回复block,获取具体下载方式

第033问:Kettle6.x或7.x版本,自带默认的es插件为什么连接服务端es6或es7异常?
第033答:
kettle6.x或7.1自带的es插件,是无法正常连接到es6以上的服务端的。因为自带插件包es客户端版本2.X太低啦,跟服务端高版本的ES不匹配。
旧-> 新->
新-> 
第034问:具体es插件配置那个端口?
第034答:
这个要看你的es插件代码,如果是通过低阶的transportclient访问es,用的9300端口;如果是通过高阶的resthighlevelclient,用的是9200端口。
具体参考下,我写的es插件文章“Kettle插件开发之Elasticsearch篇”。6.x版本用的低阶API(参考版本匹配:客户端es版本6.3.0,具体参考下,我写的es插件文章“参考版本匹配:客户端es版本7.2.0,服务端es版本是7.4.0)

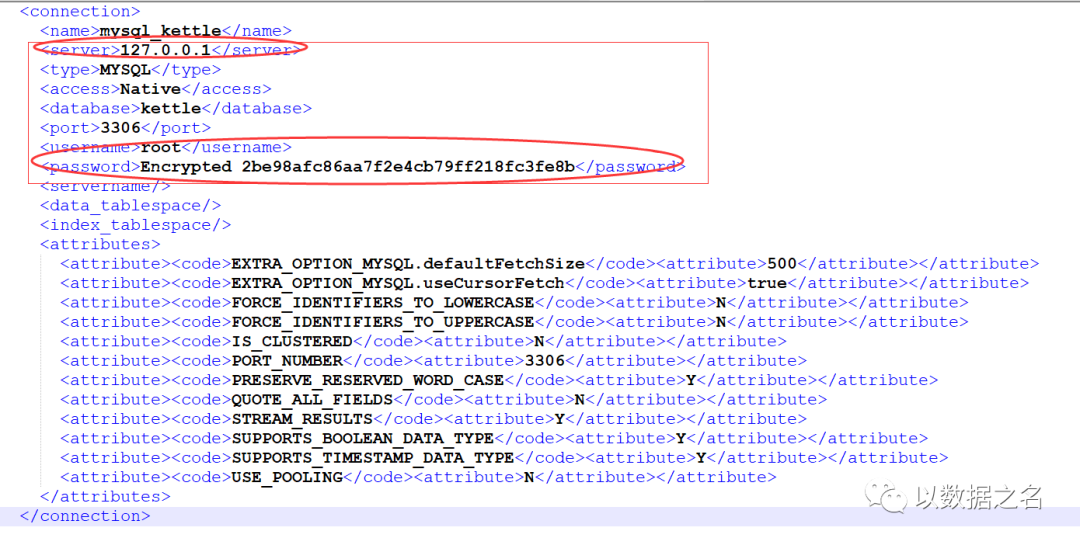
第035问:连接配置信息如何批量替换?
第035答:linux修改server配置信息,具体脚本如下:
sed -i "s:<server>127.0.0.1</server>:<server>127.0.0.2</server>:g" `grep "<server>127.0.0.1</server>" -rl ./`
port、username、password配置修改命令,同步调整,但注意配置检查唯一性,防止修改过度。其中password修改注意先使用工具加密哦
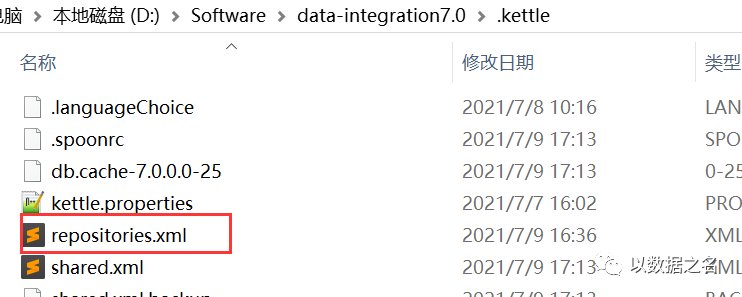
第036问:连接配置信息批量替换也很麻烦,有没有更简单的操作?
第036答:在保证连接名称不变的情况下,实际上是可以高效完成配置变更的,具体有以下几种操作:
1、开发时使用文件资源库或数据库资源,连接配置repositories.xml统一管理和维护,一次变更即可,批量导出和导入即可,建议使用资源库模式运行任务。但如果使用文件模式运行,需要每次变更所有文件;
2、连接方式使用JNDI,统一配置文件jdbc.properties,每次变更只需修改该文件即可

3、连接方式使用JDBC,动态连接配置尽量全部使用参数,运行时用“-param”动态传参绑定即可,调整运行脚本即可。这里也可以把连接配置放到数据库等介质,运行前获取参数动态绑定,就可以做到配置统一配置,一次修改,终身受益。
第037问:kettle 数据流中空字符串为什么会莫名的转为null?
第037答:这是因为Kettle默认把空字符串处理成NULL,即认为两者相同,具体由下面参数确定,可通过调整参数值来改变。
变量名:KETTLE_EMPTY_STRING_DIFFERS_FROM_NULL ,
默认值:N,
描述:NULL vs Empty String. If this setting is set to Y, an empty string and null are different. Otherwise they are not.
NULL与空字符串。如果将此设置设置为Y,则空字符串和null是不同的。否则空字符串就默认赋值为NULL。

第038问:开并发复制模式可以提高效率嘛?
第038答:答案是肯定的,但具体的复制模式的使用场景,必须要了解清楚。
1、输入是不能开的,数据会重复取N倍。
2、中间数据流组件多分支后面的第一个组件不可以开,会重复N倍。
3、输出也要适当设置,因为连接数过大,服务端压力就越大,
4、同时,如果前面的数据流行数越少,那均分到不同的线程,数据行就越少。甚至大部分线程没数据,连接超时的可能性就越大。

第039问:kettle Linux环境如何创建资源库?
第039答:数据库资源库可以通过跳板机远程创建,文件资源库和数据库资源库都可以直接修改repositories.xml文件,具体步骤如下:
数据库资源库:
1、先新增connection标签,及连接配置信息,参考windows客户端,或者转换作业JDBC连接配置信息。
name:连接名称
server:ip或域名
type:数据库类型
access:连接方式,Native即JDBC、ODBC、JNDI

port:端口号
username:用户名
password:密码(Encrypted为前缀,必须添加;后面为真实密码加密后的结果)
……,剩余参数不再一一介绍,自己脑补吧。
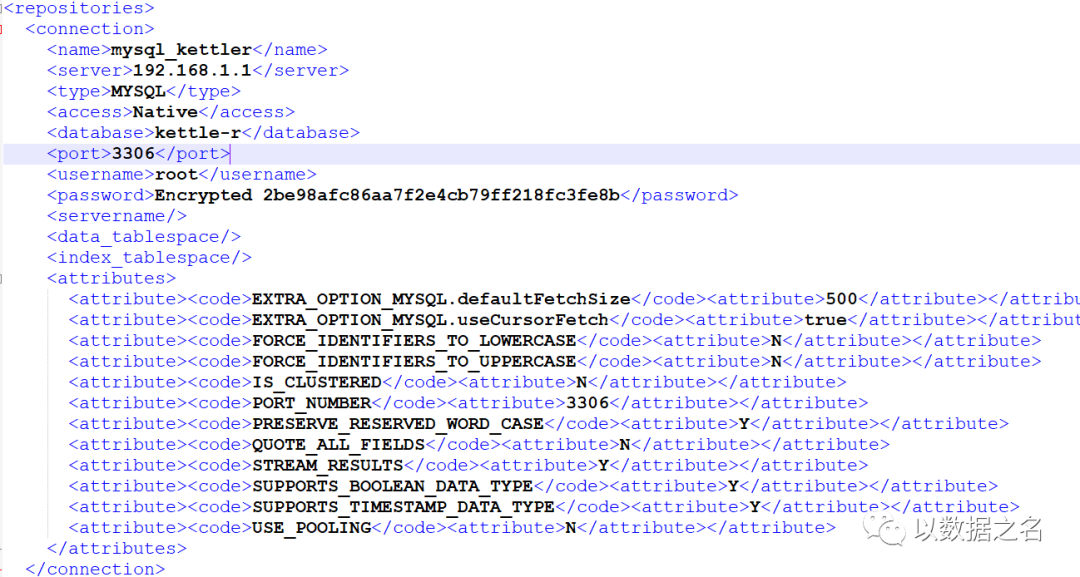
2、再新增repository标签,其中id属性KettleDatabaseRepository(*****),标记此资源库为数据库资源库

name:自定义资源库名称
description:资源库描述信息
is_default:默认false
connection:对应上面的连接配置信息的name属性值(*****)
文件资源库
1、文件资源库不需要connection连接配置,直接新增repository标签,其中id属性KettleFileRepository(*****),标记此资源库为文件资源库

name:自定义资源库名称
description:资源库描述信息
is_default:默认false
base_directory:文件资源库根目录(*****)
read_only:是否只读(或者是否修改对应作业或转换),默认N
hides_hidden_files:是否显示隐藏文件夹,默认N

第040问:Kettle可以用到数据仓库的哪些层?
第040答:首先我们要了解下数据仓库分层结构,具体如下:
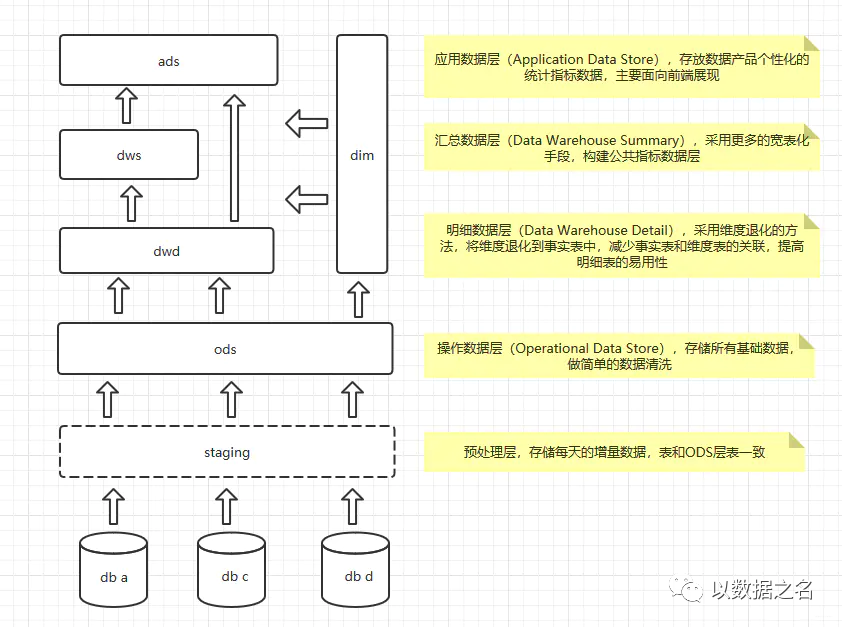
DWD可以和ODS层(贴源层,和源库一致的模型 )合并,也可以是架在ODS层之上的明细层,这层可以做一些轻度的维度退化,减少事实表和维度表的关联。
DWB层,可以看做C层,中间层或者叫中心层,存一些轻度汇总数据。
再上层是DWS层,高度汇总聚合层,一般采用宽表构建综合指标数据。
最上层是ADS层,即应用层,存放不同产品的统计指标数据,直接对外提供原子化服务。
那么中间需要数据转换的步骤,都可以使用Kettle来进行数据清洗,当然前提是数据时效可以满足的情况。

Kettle插件开发之KafkaConsumerAssignPartition篇
Kettle插件开发之KafkaConsumerAssignPartition篇
虽小编一己之力微弱,但读者众星之光璀璨。小编敞开心扉之门,还望倾囊赐教原创之文,期待之心满于胸怀,感激之情溢于言表。一句话,欢迎联系小编投稿您的原创文章!
回复1,获取全平台解压缩密钥
回复2,获取kettle快速入门示例
回复kettle,获取离线和实时数据仓库资料和视频
回复code,获取全平台Kettle插件及实例源码
回复plugin,获取全平台插件Release包
回复ppt,获取全平台分享精彩PPT模板
回复etl,获取Kettle知识库系列资料
回复mysql,获取MySQL中英文指导学习手册
回复mail,获取Kettle实战系列之动态邮件附件
回复block,获取Kettle阻塞组件使用示例

