




SQL优化及案例
1SQL优化步骤
1.1 通过监控发现存在性能问题的关键SQL
以下所有数据都来自PCKCACHESZ内存
需要打开快照监控开关
--命令行
db2 get snapshot for dynamic sql on sample
--动态性能视图,显示时间分布信息从少到多
SELECT * FROM SYSIBMADM.LONG_RUNNING_SQL;
SELECT * FROM SYSIBMADM.TOP_DYNAMIC_SQL;
SELECT * FROM SYSIBMADM.SNAPDYN_SQL;
不需要打开快照监控开关
--表函数,直接获取PCKCACHESZ内存中的SQL信息
select * from TABLE(MON_GET_PKG_CACHE_STMT ( 'D', NULL, NULL, -2)) as T
1.2 在测试环境重现SQL执行慢的场景
在测试环境重现SQL执行慢的场景,并保存该场景(一般是数据库备份与恢复的方式进行保存与复原),以备反复使用该场景。如果不能重现场景,通常的原因是生产环境与测试环境表结构不一致(包括使用的表空间和缓冲池)导致的,如果表结构比较后也难做到一致,那就获取生产环境镜像恢复到测试库进行场景重现。这一步很重要。
1.3 生成基准信息
重现SQL慢的场景后,执行db2exfmt获取带表统计信息的访问计划,执行db2batch获取SQL真实执行时间及应用程序快照,执行db2advis获取推荐的索引。这些都是基准信息,方便优化过程中及优化后与这些信息进行比较,一步一步的实施优化,达到优化目标,如果失去基准信息,优化文档难编写,优化取得的效果也缺少根据。
1.4 对表执行reorg和runstats
使用reorg和runstats获取最新统计信息,这是优化的起点,确保了数据及索引不存在碎片并且统计信息是最新的,通常而言,这步优化效果不大,但意义重大,确保了访问计划的正确性。reorg和runstats语句类似如下:
db2 "reorg table db2ihqb.EMPLOYEE"
db2 "runstats on table db2ihqb.EMPLOYEE with distribution and sampled detailed indexes all"
这是第一轮优化。
执行db2exfmt、db2batch、db2advis获取第一轮优化后的信息。
1.5 评估db2advis推荐的索引
如果第(4)步推荐的索引总体能提高20%以上的性能,每个索引大小不超过500M,对部分复合索引包含列太多情况进行微调(减少组合列个数),并创建这些索引后表包含的索引个数不超过5个(OLTP数据库)。那么可以创建这些推荐的或微调后的索引。
这是第二轮优化。
执行db2exfmt、db2batch、db2advis获取第二轮优化后的信息。
1.6 使用db2batch查看SQL执行时间分布
如果使用推荐的索引后执行时间仍不达标,或根本没有推荐索引,那就查看db2batch中的应用程序快照来确定SQL执行时间的分布。得到SQL执行时间分布后,大多数情况下就能估计出哪些参数不当影响了该SQL的执行,比如:数据库参数、统计信息、缓冲池、排序堆等的影响,然后对这些参数进行调整。
这是第三轮优化。
执行db2exfmt、db2batch、db2advis获取第三轮优化后的信息。
1.7 访问计划调整与定制
查看db2exfmt生成的访问计划中的明显可调优点(表扫描、表连接、内表外表的选择),如果期望使用某个索引,但因为编译器的原因,特殊的情况下总使用不到,那么就使用优化概要来定制访问计划。
如果找不到明显可调优点,那么就获取真实基数,并通过db2exfmt重新打印在访问计划的每个节点上,看哪个节点存在基数明显误估,那么就针对性的收集该表上某些列组的统计信息提高基数估计的准确率。
如果基数估计也正确,产生基数大的原因是谓词不能下推到基本表,导致中间结果集很大,那么就改写该SQL,此种现象一般存在于SQL非常长,并且子查询非常多的情况。改写的方式有多种,典型的一种是使用WITH TEMP,例如:
WITH TEMP(C1,C2) AS (values (6,66),(7,77),(8,NULL)) SELECT * FROM TEMP ORDER BY 2 DESC
这是第四轮优化。
执行db2exfmt、db2batch、db2advis获取第四轮优化后的信息。
如上步骤实施完毕,一般都能把SQL优化到期望的效果。
如果仍没有达到期望效果,那就要考虑启用表压缩(一般情况下建议开启,默认是未开启状态)、创建MQT(物化查询表)(通常使用在OLAP数据库环境)、MDC(多维集群表) (通常使用在OLAP数据库环境)、表分区、找出热点磁盘、重新规划表空间使用容器等方式进行优化。
这些都不行,就需要从业务层面考虑,从业务层面简化需求,使SQL变的简单。
接下来分别讲解如下SQL优化工具:
db2adivs
db2batch
db2exfmt
真实基数
访问概要定制
2SQL优化工具
2.1 db2advis
db2advis -d sample -i 1.sql -n db2ihqb -q db2ihqb -m MICP –o 1db2advis.idx>1db2advis.txt
1.sql内容如下:
--#SET FREQUENCY 100
SELECT COUNT(*) FROM EMPLOYEE;
SELECT * FROM EMPLOYEE WHERE LASTNAME='HAAS';
--#SET FREQUENCY 100为设置语句的执行频率
其中
-d sample 标识数据库的名称
-i 1.sql标识 db2advis 的输入文件的名称
-n db2ihqb指定推荐创建对象的模式为db2ihqb
-q db2ihqb指定1.sql中SQL的表模式为db2ihqb
-m MICP 是 db2advis 命令的伪指令,用于生成以下提高性能的建议:
M 新的物化查询表
I 新的索引
C 将标准表转换为多维集群表 (MDC)
P 对现有表重新分区
默认为I。
这里只推荐索引,所以命令应该为:
db2advis -d sample -i 1.sql –n db2ihqb -q db2ihqb -m I -o 1db2advis.idx>1db2advis.txt
或
db2advis -d sample -i 1.sql –n db2ihqb -q db2ihqb -o 1db2advis.idx> 1db2advis.txt
2.2 db2batch
通过如下db2batch语句获取结果:
db2batch -d sample -f 1.sql -o p 5 f -1 r -1 -iso ur -car cc -i complete -r 1db2batch.txt
默认的iso为RR,car的选项有:cc - Currently Commited、wfo - Wait for Outcome
通过db2batch获得了某SQL的执行时间,如下:
Prepare Time is: 0.286 seconds
Execute Time is: 126.595 seconds
Fetch Time is: 8.979 seconds
Elapsed Time is: 135.860 seconds
从获取的应用程序快照中得到如下信息:
Total buffer pool read time (ms) = 21313
Total buffer pool write time (ms) = 18
Time waited for prefetch (ms) = 75949
Total User CPU time used by agent (s) = 27.761703 seconds
Total System CPU time used by agent (s) = 1.532227 seconds
这是SQL执行时间分布,这5部分相加,值为:126.573
SQL执行时间为Execute Time is: 126.595 seconds
两者是吻合的。
然后从应用程序快照中还能得到如下信息:
Total sort time (ms) = 10076
排序时间10076包括排序活动时间+排序等待的时间,而排序活动时间是用的纯CPU时间,排序等待时间一般都是等待IO,所以10076这个时间已经在Total User CPU和Total buffer pool read time已经包括了,故可以不考虑。
从时间来看,消耗时间的大头为Time waited for prefetch,如下:
Time waited for prefetch (ms) = 75949
2.3 db2exfmt
db2exfmt:用于直接处理已收集并存储在解释表中的解释数据。
给定数据库名和其他限定信息,db2exfmt工具将在解释表中查询信息、格式化结果,并生成一份基于文本的报告,此报告可直接显示在终端上或写入ascii文件。
首先进入/home/db2ihqb/sqllib/misc,执行db2 -tvf EXPLAIN.DDL
产生EXPLAIN_INSTANCE等解释结果存储表,表创建在任意表空间中,但非SYSTOOLSPACE表空间。
创建解释表的另一种方式是调用下面的存储过程,其中第二个参数”C”的含义为创建。相应的,如果传入参数”D”即删除解释表。
解释表的删除与创建,是创建在表空间SYSTOOLSPACE下。
db2 "call sysproc.sysinstallobjects('EXPLAIN','D','',CURRENT SCHEMA)"
db2 "call sysproc.sysinstallobjects('EXPLAIN','C','',CURRENT SCHEMA)"
补充:
用户表空间SYSTOOLSPACE和用户临时表空间SYSTOOLSTEMPSPACE通常用于通过下列向导、实用程序或函数自动创建的表:
自动维护
设计顾问程序(两个都没有也不会报错)
控制中心数据库信息面板
SYSINSTALLOBJECTS存储过程(如果未指定表空间输入参数的话)
GET_DBSIZE_INFO存储过程(两个都没有也不会报错,执行的时候会自动创建SYSTOOLSPACE表空间)
手工创建:
Create regular tablespace systoolspace in IBMCATGROUP MANAGED BY SYSTEM USING (‘SYSTOOLSPACE’)
CREATE USER TEMPORARY TABLESPACE SYSTOOLSTEMPSAPCE IN IBMCATGROUP MANAGED BY SYSTEM USING (‘SYSTOOLSTEMPSAPCE’)
(1) 获取访问计划到解释表
A)、explain all语句
db2 "explain all with snapshot for select * from test"记录信息最全
db2 "explain all for snapshot for select * from test"只填充表的SNAPSHOT列,其余列都不填充
db2 "explain all for select * from test"不填充表的SNAPSHOT列,其余列都填充
EXPLAIN_INSTANCE表中的SNAPSHOT_TAKEN列(值为Y\N\0,Y表示有快照、N表示不带快照、0表示只有快照)表示每一条被解释的语句是否有一个Visual Explain快照。
B)、使用解释专用寄存器
DB2用两个解释专用寄存器来收集动态SQL语句的解释信息,这些专用寄存器是:
CURRENT EXPLAIN MODE 获取解释信息,不获取快照信息
CURRENT EXPLAIN SNAPSHOT 获取快照信息,不获取解释信息
下面的语句用来设置解释专用寄存器的值:
SET CURRENT EXPLAIN MODE option
SET CURRENT EXPLAIN SNAPSHOT option
解释寄存器的option(选项)有:
NO 不获取动态SQL语句的解释信息和快照信息
YES 当执行动态SQL语句时,获取解释信息或快照信息并返回结果
EXPLAIN 获取动态SQL语句的解释信息或快照信息,无需执行SQL语句。
一旦把寄存器设置成YES或EXPLAIN,将对后续的动态SQL语句进行解释,直到寄存器重置为NO为止。
下面两个选项只对CURRENT EXPLAIN MODE寄存器有效
RECOMMENT INDEXES
EVALUATE INDEXES
等同于db2advis,即获取解释信息的同时推荐索引和评估推荐索引的提升性能。
(2) 格式化二进制访问计划成ascii文本格式
获取的二进制访问计划存放在EXPLAIN_INSTANCE表中,可以使用db2exfmt格式化成ascii文本格式,有如下两种格式化方式:
db2exfmt -d sample -g tic -e DB2IHQB -n % -s % -w % -# 0 -o 1db2exfmt.txt
这种方式能格式化explain_instance中的所有访问计划
获取访问计划的简单有效方式:
db2exfmt -d sample -l –o 1db2exfmt.txt
这种方式只能格式化一条访问计划,默认格式化explain_instance中的最新访问计划,如果在交互的时候,对如下询问项输入了explain_instance中某一行这四列的值,那么就获取对应行的访问计划,而不是固定的只格式化最新访问计划。
Enter up to 26 character Explain timestamp (Default -1) ==>
Enter up to 128 character source name (SOURCE_NAME, Default %%) ==>
Enter source schema (SOURCE_SCHEMA, Default %%) ==>
Enter section number (0 for all, Default 0) ==>
(3) 获取动态SQL和静态SQL访问方案
A)、解释动态SQL
在解释SQL语句时使用snapshot选项,DB2将编译SQL语句时使用的统计信息也包含在访问计划的输出中,这样大大方便了对访问计划的分析。
db2 set current explain mode explain
db2 set current explain snapshot explain
db2 "select ..."
db2 set current explain mode no
db2 set current explain snapshot no
db2exfmt -d sample -l -o 1db2exfmt.txt
B)、解释存储过程中静态SQL语句的访问计划
要通过db2exfmt抓取存储过程的访问计划,需要在创建存储过程之前设置EXPLAIN YES这个编译选项。有两种方法来设置这个选项:
调用存储过程SET_ROUTINE_OPTS设置EXPLAIN YES编译选项,于是在当前会话中创建的SQL存储过程,DB2会将其访问计划写入到解释表中,从而可以用db2exfmt工具获取。在每次rebind的时候,该存储过程中的SQL语句会重新编译,其访问计划也将重新被写入到解释表;但如果rebind指定的项为REOPT ALWAYS,则rebind的时候不会生成访问计划,在执行call的时候才生成访问计划到解释表中。
db2 connect to sample
db2 "CALL SET_ROUTINE_OPTS('EXPLAIN YES')"
例子一:
--执行存储过程的rebind,每执行一次,都会生成新的访问计划存放到解释表中
db2 "call sysproc.rebind_routine_package('P','DB2IHQB.GETN','REOPT NONE')"
例子二:
--使用rebind选项REOPT ALWAYS执行存储过程的rebind
db2 "call sysproc.rebind_routine_package('P','DB2IHQB.GETN','REOPT ALWAYS')"
此时不会生成新的访问计划,只有在真正执行存储过程的时候(比如:db2 "call GETY('156',?,?)")才会生成访问计划并存放到解释表中。
设置注册变量DB2_SQLROUTINE_PREPOPTS,这需要重新启动DB2实例才能生效,随后创建的SQL存储过程将能用db2exfmt抓取访问计划。
db2set DB2_SQLROUTINE_PREPOPTS="EXPLAIN YES"
当发现存储过程访问计划不是最新时,可使用如下语句重新绑定这个存储过程:
-- any表示保留当前编译选项,只是利用最新统计信息重新编译
db2 "rebind package DB2IHQB.P1837332765 resolve any"
或
db2 "call sysproc.rebind_routine_package('P','DB2IHQB.GETN','ANY')"
在syscat.routines的PRECOMPILE_OPTIONS选项存放编译选项
例子三:
db2 "create table test(id int,name char(10))"
db2 "CALL SET_ROUTINE_OPTS('EXPLAIN YES') "
db2 -td@ -vf proc.sql
db2 "call sysproc.rebind_routine_package('P','HUANGH.proc_test','REOPT NONE')"
create procedure proc_test(v1 int)
begin
declare time int default 0;
while(time<v1)
do
insert into test values (1,'testlog');
set time=time+1;
end while;
end@
2.4 真实基数
使用Section Actuals分析执行计划
(1) 启用Section Actuals
db2 update db cfg using SECTION_ACTUALS base
创建工作量管理器和activities事件监视器
(2) 创建工作量管理器和事件监视器
必须为真实段创建一个workload和事件监视器。可以使用下列命令创建一个workload,也可以使用默认的的workload管理器。
db2 "create workload MYWORKLOAD current client_acctng('MYWORKLOAD') service class sysdefaultuserclass collect activity data on all database partitions with details,section"
db2 "grant usage on workload MYWORKLOAD to public"
db2 "create event monitor MYMON for activities write to table"
(3) 收集相关语句的Section Actuals
db2 "delete from ACTIVITYSTMT_MYMON"
db2 "call wlm_set_client_info(null,null,null,'MYWORKLOAD',null)"
db2 "set event monitor MYMON state 1"
采用db2 set current explain mode yes来执行语句(如果语句不实际执行,是不能被activities事件监视器捕获的,所以这里要用yes,不能用explain。)
执行类似如下的语句
db2 "select * from db2obits.wf_task where nodeid='ManuNode_REG'"
db2 set current explain mode no
db2 "set event monitor MYMON state 0"
db2 "call wlm_set_client_info(null,null,null,null,null)"
(4) 确定数据的Application、UOW和Activity ID
db2 " select appl_id,uow_id,activity_id,varchar(stmt_text,500) as stmt from ACTIVITYSTMT_MYMON"

(5) 将数据输入到EXPLAIN表中
调用explain_from_activity过程来将有关语句输入到EXPLAIN表中。首先是3个输入Application、UOW_ID和Activity_ID,它们是根据步骤4输出中的有关语句来确定的。第4个输入是步骤3中设置的活动事件监视器的标识符,第5个输入是EXPLAIN表的模式名称,在这里,EXPLAIN表的模式是DB2IBITS。
db2 "call explain_from_activity('*LOCAL.DB2IBITS.140228014048',28,1,'MYMON','DB2IBITS',?,?,?,?,?)"
运行db2exfmt获取执行计划
db2exfmt -d sample -l -o db2exfmt.txt
结果类似于:

2.5 优化概要
启用优化概要前必须设置DB2_OPTPROFILE注册表变量为YES并重启DB2服务器。
2.5.1、嵌入方式
将优化概要嵌入在SQL语句中,如果需要在SQL调优的过程中对单条SQL语句尝试各种不同的访问计划,那么这种方式就很适合。
例如:如下所示的SQL语句使用了嵌入式优化概要,它对优化器生成访问计划作出了这样的指示:访问employee表使用索引扫描,由优化器根据成本模式为其选择合适的索引。
db2 "select * from db2ihqb.employee c
/* <OPTGUIDELINES><IXSCAN TABLE='c'/></OPTGUIDELINES> */"
用db2exfmt工具打印出这个SQL语句的访问计划,如下:
Access Plan:
-----------
Total Cost:6.89812
Query Degree: 1
Rows
RETURN
( 1)
Cost
I/O
|
1
FETCH
( 2)
6.89812
1
----+----\
1 1
IXSCAN TABLE: DB2IHQB
( 3) EMPLOYEE
0.00967936 Q1
0
|
1
INDEX: SYSIBM
SQL140519122655970
Q1
参考1:定制访问计划
Q9表作为外表,嵌套循环连接Q8表,得到的结果集作为外表,Q9表是使用表扫描还是索引扫描由优化器决定,Q8表使用索引扫描,并且指定使用PERIOD_UIDX索引。表prd是HSJOIN的内表,表prd使用表扫描。每执行该SQL都重新生成访问计划,即使包缓存中存在该访问计划。
/*<OPTGUIDELINES>
<HSJOIN>
<NLJOIN>
<ACCESS TABID=’Q9’/>
<IXSACN TABLE=' Q8' INDEX='PERIOD_UIDX'/>
</NLJOIN>
<TBSCAN TABLE='prd'/>
</HSJOIN>
<REOPT VALUE='ALWAYS'/>
</OPTGUIDELINES>*/
注意:优化概要中的表名,如果在SQL语句中对表名使用了别名,那么在优化概要中也必须使用别名,忽略大小写。
2.5.2、独立方式
将优化概要嵌入到SQL语句中,在实际项目中并不是一个好的方式,因为数据是变化的,在某一时刻使用这个访问计划是最优的,在另一个时刻,却可能很差,这时再来修改应用中的SQL语句的优化概要,很不方便。独立方式可以解决这个问题,它用独立的文件存储SQL语句和相应的优化概要,并注册到DB2中。这样,当需要改变访问计划时,不用修改SQL语句本身,只要修改独立文件的内容就行了。
下面介绍使用独立方式的四个步骤。
(1)创建OPT_PROFILE表
通过SYSINSTALLOBJECTS存储过程或者使用CREATE TABLE语句手工创建表SYSTOOLS.OPT_PROFILE,该表存储优化概要文件。
db2 "call sysinstallobjects('opt_profiles','c','','' )"
(2)创建OPT_PROFILE文件
优化概要文件是一个标准的XML文件。如下所示,名为Prof1.xml的优化概要文件中,根节点为OPTPROFILE,其下可以有多个STMTPROFILE,每个STMTPROFILE指定一条SQL语句的优化概要。STMTPROFILE主要由两部分组成,STMTKEY包含SQL语句,而OPTGUIDELINES指定相应的优化概要,在STMTKEY中可以用属性SCHEMA指定SQL语句所引用表的默认模式,比如例子中指定默认模式为DB2IHQB。
<?xml version="1.0" encoding="UTF-8"?>
<OPTPROFILE VERSION="10.1.0.3">
<STMTPROFILE ID="Query 0">
<STMTKEY SCHEMA="DB2IHQB">
<![CDATA[select * from employee c]]>
</STMTKEY>
<OPTGUIDELINES>
<IXSCAN TABLE="C"/>
</OPTGUIDELINES>
</STMTPROFILE>
</OPTPROFILE>
注意:优化概要文件的SQL语句匹配能忽略大小写和空格,但其他方面必须一致。在匹配之前,DB2将去除冗余空格和控制字符。
(3)注册优化概要
注册优化概要,即将优化概要文件存储到第一步创建的SYSTOOLS.OPT_PROFILE表中。首先编辑如下内容,并保存到profileData.del(详见附件)中。这里的内容与表SYSTOOLS.OPT_PROFILE结构一致,第一个值指定优化概要的模式DB2IHQB,第二个值指定优化概要的名字PROF1,第三个值指定优化概要文件的名字,示例中为Prof1.xml(详见附件)。
--文件profileData.del
"DB2IHQB","PROF1","Prof1.xml"
然后使用下面的IMPORT命令将profileData.del中的内容导入到表systools.opt_profile中,这样就完成了这个优化概要的注册,所使用的命令如下所示:
db2 "import from profileData.del of del modified by lobsinfile insert_update into systools.opt_profile"
注册概要文件后,使用下面的flush命令刷新缓存中的优化概要
flush optimization profile cache
如果从这个表中更新或删除一个指南,操作完后,也需发出flush optimization profile cache语句更新缓存,使之生效可以被使用。
(4)使用优化概要
最后,使用set current optimization profile命令设置当前要使用的优化概要。优化概要由systools.opt_profile中schema和name组合主键标识,示例中为DB2IHQB.PROF1,于是接下来的查询就能用到这个优化概要:
db2 flush optimization profile cache all
db2 set current optimization profile DB2IHQB.PROF1
db2 set current schema db2ihqb
db2 set current explain mode explain
db2 "select * from c_employee c"
db2 set current explain mode no
db2exfmt -d sample -l -o db2exfmt.txt
查看db2exfmt.txt,结果如下:
Profile Information:
--------------------
OPT_PROF: (Optimization Profile Name)
DB2IHQB.PROF1
STMTPROF: (Statement Profile Name)
Query 0
Access Plan:
-----------
Total Cost: 6.89812
Query Degree: 1
Rows
RETURN
( 1)
Cost
I/O
|
1
FETCH
( 2)
6.89812
1
----+----\
1 1
IXSCAN TABLE: DB2IHQB
( 3) EMPLOYEE
0.00967936 Q1
0
|
1
INDEX: SYSIBM
SQL140519122655970
Q1
如果在应用程序中加载优化概要文件,代码实现如下:
stmt.execute("flush optimization profile cache all ");
stmt.execute("set current optimization profile DB2IHQB.PROF1");
参考1:强制表employee的访问使用索引和MQT,而且MQT对多个STMTPROFILE生效
<?xml version="1.0" encoding="UTF-8"?>
<OPTPROFILE VERSION="10.1.0.3">
<OPTGUIDELINES>
<MQT NAME="DB2IHQB.ADEFUSR"/>
</OPTGUIDELINES>
<STMTPROFILE ID="Query 0">
<STMTKEY SCHEMA="DB2IHQB">
<![CDATA[select * from employee]]>
</STMTKEY>
<OPTGUIDELINES>
<IXSCAN TABLE='employee' INDEX='PK_EMPLOYEE'/>
</OPTGUIDELINES>
</STMTPROFILE>
</OPTPROFILE>
3SQL谓词
谓词包括在以 WHERE 或 HAVING 开头的子句中,用于缩小查询返回的结果集,可以将谓词分为四类,按性能最佳到最差排列:
(1) 范围定界谓词:用于限制索引扫描的范围,提供了索引扫描的起始位置
(2) 索引控制(Index-Sargable)谓词:Sargable (searchable argument),谓词中的字段是索引的一部分,可以从索引中估计出来。会减少访问数据页的数目,但是并不能减少索引页的访问量。这类谓词一般为=、>、<等谓词。
(3) 数据控制(Data-Sargable)谓词:索引管理器无法起作用,但是数据管理服务可以进行条件过滤,通常这些谓词需要访问基表。这类谓词一般为<>、 LIKE等。
(4) 保留 (residual)谓词:所需的IO非常大,已经超过了对基表的访问成本。这类谓词一般为:相关子查询(NOT EXISTS)、无关子查询(ANY、ALL、SOME)或者读取LONG VARCHAR、LOB等数据。
谓词类型的特征
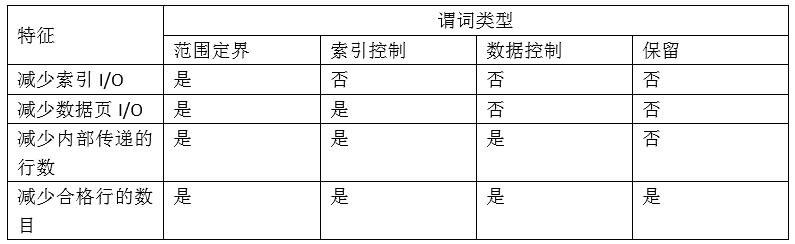
范围定界谓词和索引控制谓词
范围定界谓词用于限制索引扫描范围。它们提供索引搜索的开始和停止键值。索引控制谓词无法限制搜索范围,但可根据索引进行求值,该谓词中引用的列是索引键的组成部分。
例如:在EMPLOYEE上创建如下索引:
create index em_i2 on employee(firstnme asc,workdept asc,job asc,salary asc,hiredate asc) allow reverse scans collect sampled detailed statistics
执行如下查询:
select * from employee where firstnme = 'CHRISTINE' and workdept = 'A00' and hiredate > '1963-08-23'
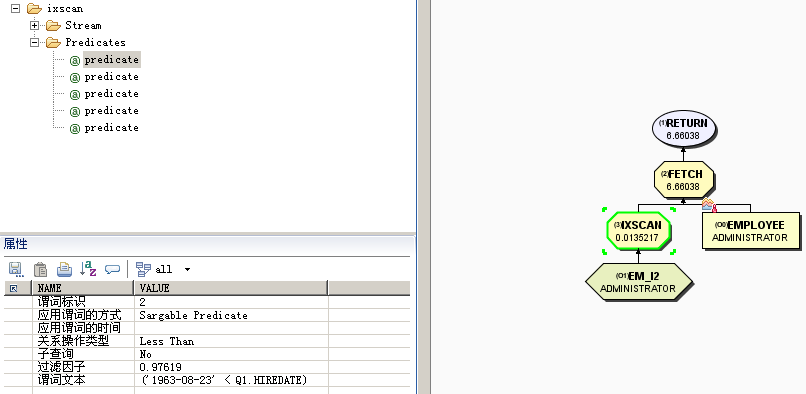
前两个谓词(firstnme = 'CHRISTINE' and workdept = 'A00')是范围定界谓词,而 hiredate > '1963-08-23'是索引 SARGable 谓词。
优化器对这些谓词进行求值时,将使用索引数据,而不是读取基本表。索引控制谓词可减少需要从表中读取的行数,但需要从第一个索引叶子页读到最后一个索引叶子页,一个不落的进行判断,记录下符合条件RID。
数据控制谓词
无法由索引管理器求值但可以由数据管理服务(DMS)求值的谓词称为数据控制谓词。这些谓词通常需要访问表中的各行。
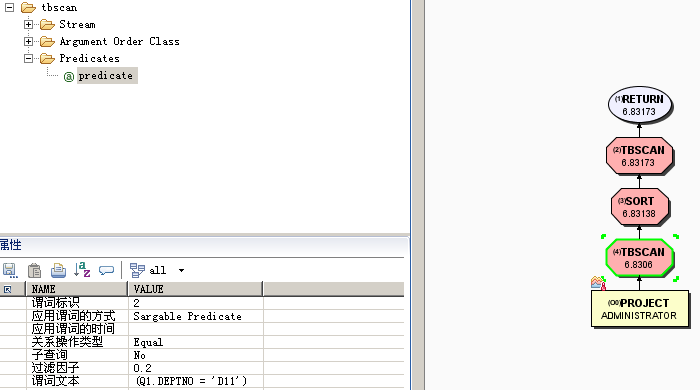
例如,PROJECT 表有索引:
INDEX PK_PROJECT:PROJNO ASC
在以下查询中,deptno = 'D11' 被视为数据 SARGable 谓词。
select projno, projname, respemp from project where deptno = 'D11' order by projno
保留谓词(residual)
这种谓词由关系数据服务(RDS)进行求值,在I/O 成本方面,保留谓词比表扫描更高。如下场景会出现保留谓词的使用:
1)、部分相关子查询,如NOT EXISTS
2)、部分无关子查询,如 ANY、ALL、SOME
3)、读取 LONG VARCHAR 或 LOB 数据
比如:表EMP_RESUME的字段RESUME是CLOB类型,执行如下查询:
SELECT * FROM EMP_RESUME WHERE RESUME LIKE '%September 15%'

4访问路径
访问表的方式称为访问路径(Access Path),访问路径分索引扫描和表扫描,一般来讲,索引扫描比表扫描快。具体来说,有如下几种:
表扫描:TBSCAN
索引扫描:IXSCAN+FETCH
索引列表预取:IXSCAN+List Prefetch
索引与操作:IXSCAN+IXAND,能利用多个索引进行与操作
索引或操作:IXSCAN+SORT+RIDSCAN,能利用多个索引并进行或操作
4.1 索引列表预取
先通过索引扫描得到满足谓词条件的所有RID,然后将这些RID进行排序,再用它们访问数据页。这样可以对相邻的数据行进行连续的访问,从而通过预取减少IO次数。与随机IO相比,这种方式的开销要小得多,因为如果缓冲池没法放下所有的页,随机访问可能导致一个页面从磁盘中读入多次。
下面是List Prefetch的例子:访问计划中的SORT操作用于将索引扫描得出的RID进行排序,然后再用预取的方式读取基本表的数据。预取能够减少磁盘IO次数,从而提高数据访问的性能。
854.727
FETCH
( 15)
94.251
60.264
/-----+---\
854.727 1.2356e+06
RIDSCN TABLE: QYNUSER
( 16) GRZFMX
34.423
2.63392
|
854.727
SORT
( 17)
34.4227
2.63392
|
854.727
IXSCAN
( 18)
34.2096
2.63392
|
1.2356e+06
INDEX: QYNUSER
INDEX_ZFJYRQ
4.2 索引AND运算
当SQL语句在同一个表上有多个谓词,并可以使用多个索引扫描时,DB2使用IXAND操作符来执行索引与操作。索引与操作将多个索引得到的RID列表合并,只取共同存在的RID。
create index em_i4 on employee(salary asc) allow reverse scans collect detailed statistics
create index em_i5 on employee(comm asc) allow reverse scans collect detailed statistics
执行如下查询:
select * from employee where salary between 20000 and 30000 and comm between 1000 and 3000
访问计划如下,IXAND节点将两个IXSCAN连接起来,而在IXAND上采取了List Prefetch。
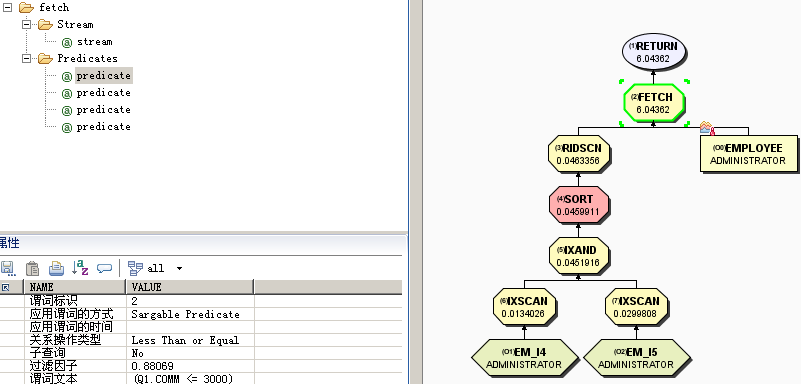
参考:单列索引VS复合索引
大多数情况下,组合索引比单字段索引用途广。从性能上考虑:
(1)单列索引性能要比复合索引差。因为多个单列索引作为谓词,需要参与动态位图AND运算,在如上示例中,扫描索引EM_I4(相当于构建表)将生成满足salary between 20000 and 30000谓词的位图,扫描EM_I5(相当于探测表)并探测EM_I4(employee(salary asc))的位图将生成满足这两个谓词的合格RID的列表,为了提升动态位图AND的性能,可能需要增加SORTHEAP的大小。这与HSJOIN的原理一致(内表作为构建表存储在sortheap中,外表作为探测表)
(2)复合索引能够对谓词相关性收集列组统计信息,避免看成独立谓词错误评估基数
一般而言,应该优先设计组合索引
如果索引都是单列,那么统计信息可能需要考虑列相关性。
(3)访问计划对比来看,复合索引比单列索引更有利于查询
(4)复合索引占用较多磁盘空间,因为复合索引的影响DML操作性能会有所降低。
总体而言,创建索引优先考虑复合索引。
4.3 索引OR运算
如果SQL语句中的多个谓词是OR组合在一起,并同时可以使用多个索引。这时,DB2通过Index Oring,将多个索引扫描得到的RID进行合并,并将重复的RID去掉。索引或操作没有显示的操作符。
employee表已经存在如下索引:
INDEX XEMP2: WORKDEPT ASC
create index em_i2 on employee(job asc,hiredate asc) allow reverse scans collect sampled detailed statistics
select * from employee where workdept = 'A00' or (job = 'MANAGER' and HIREDATE >= '2003-10-10')
访问计划如下,使用了两个索引扫描,并且对每个索引扫描得到的RID进行排序,然后对两个RID列表上直接做RIDSCAN进行RID的合并操作,最后从基本表上提取数据。
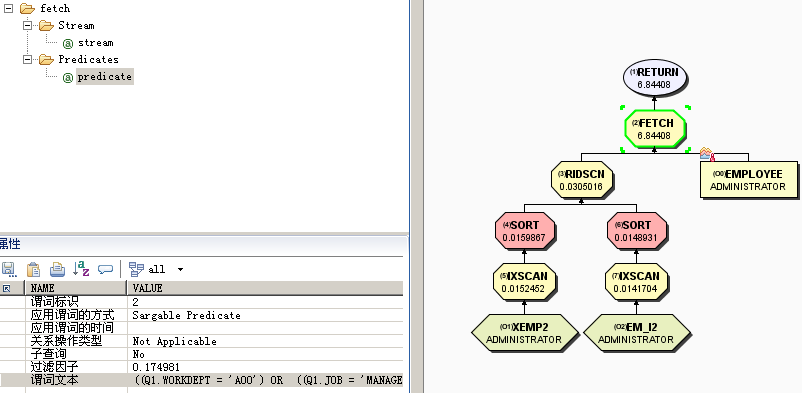
5疑惑解答与案例演示
5.1 利用IBM DATA STUDIO工具调优SQL
比如,如下SQL:查找在部门名称为'OPERATIONS'的部门下工作的员工
select empno, firstnme, lastname, phoneno
from employee where workdept in
(select deptno from department
where deptname = 'OPERATIONS')
经优化器重写后,SQL为:
SELECT
Q2.EMPNO AS "EMPNO",
Q2.FIRSTNME AS "FIRSTNME",
Q2.LASTNAME AS "LASTNAME",
Q2.PHONENO AS "PHONENO"
FROM
DB2IHQB.DEPARTMENT AS Q1,
DB2IHQB.EMPLOYEE AS Q2
WHERE
(Q1.DEPTNAME = 'OPERATIONS') AND
(Q2.WORKDEPT = Q1.DEPTNO)
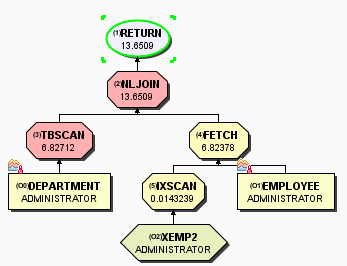
存取方案图为:
此时,表的索引为:
DEPARTMENT:
INDNAME TABNAME COLNAMES UNIQUERULE
------------------------ ------------------- ---------------------------- --------------------
PK_DEPARTMENT DEPARTMENT +DEPTNO P
XDEPT2 DEPARTMENT +MGRNO D
XDEPT3 DEPARTMENT +ADMRDEPT D
EMPLOYEE:
INDNAME TABNAME COLNAMES UNIQUERULE
------------------- ---------------- -----------------------------------------
PK_EMPLOYEE EMPLOYEE +EMPNO P
XEMP2 EMPLOYEE +WORKDEPT D
DEPARTMENT没有索引扫描,是因为没有DEPTNAME列的索引;
之所以出现 这个运算符,是因为EMPLOYEE只能从索引中获取WORKDEPT,还需要通过I/O去数据页获取这些行的如下列PHONENO、LASTNAME、FIRSTNME、EMPNO。
这个运算符,是因为EMPLOYEE只能从索引中获取WORKDEPT,还需要通过I/O去数据页获取这些行的如下列PHONENO、LASTNAME、FIRSTNME、EMPNO。
第一步优化目标:让DEPARTMENT由表扫描变成索引扫描
创建如下索引:
db2 "create index de_i4 on department(deptname) allow reverse scans collect sampled detailed statistics"
存取方案图如下:
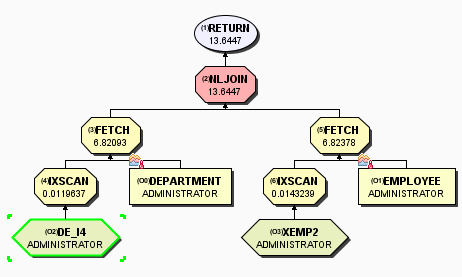
COST由13.6509变成13.6447
DEPARTMENT的数据访问方式变成了索引扫描
第二步优化目标:消除 运算符
运算符
之所以出现,是因为通过索引扫描后得到了行RID,去数据页定位数据,获取需要的列PHONENO、LASTNAME、FIRSTNME、EMPNO。如果我们创建一个针对如下列的索引,那么这些列的数据就都能从索引中获取,不需要再通过表数据页了。创建如下索引:
db2 "create index XEMP2 ON employee(workdept,phoneno,lastname,firstnme,empno) allow reverse scans collect sampled detailed statistics"
存取方案图如下:
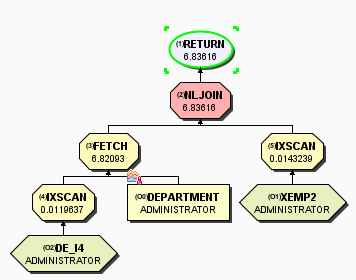
COST由13.6447变成6.83616
已经不存在,所有数据都能从索引获取到。
第三步优化目标:消除 运算符
运算符
与上面的分析类似,创建如下索引:
db2 "create index de_i4 on department(deptname,deptno) allow reverse scans collect sampled detailed statistics"
存取方案图如下:
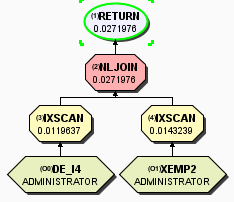
COST由6.83616变成0.0271976
已经不存在,所有数据都能从索引获取到。
最终索引为:
DEPARTMENT:
INDNAME TABNAME COLNAMES UNIQUERULE
------------- ---------- ---------------- ----------
PK_DEPARTMENT DEPARTMENT +DEPTNO P
XDEPT2 DEPARTMENT +MGRNO D
XDEPT3 DEPARTMENT +ADMRDEPT D
DE_I4 DEPARTMENT +DEPTNAME+DEPTNO D
EMPLOYEE:
INDNAME TABNAME COLNAMES UNIQUERULE
----------- -------- ----------------------------------------- ----------
PK_EMPLOYEE EMPLOYEE +EMPNO P
XEMP2 EMPLOYEE +WORKDEPT+PHONENO+LASTNAME+FIRSTNME+EMPNO D
接下来,我们把新建和修改的索引恢复成最初的模样,方便后面的案例演示。
db2 "drop index de_i4"
db2 "drop index xemp2"
db2 "create index xemp2 on employee(workdept) allow reverse scans collect sampled detailed statistics"
通过设计顾问程序来调优SQL案例
上面提到的SQL,如果通过设计顾问程序来调优呢,看如下的操作:
创建一个文件名称为:tune.sql,该文件包含该SQL语句,即:
select empno, firstnme, lastname, phoneno from employee where workdept in (select deptno from department where deptname = 'OPERATIONS')
执行如下命令:
db2advis -d sample -i tune.sql -q DB2IHQB -o 1db2advis.idx>1db2advis.txt
查看1db2advis.txt文件,发现有如下建议:
--RUNSTATS ON TABLE "DB2IHQB"."EMPLOYEE" FOR SAMPLED DETAILED INDEX --"DB2IHQB"."XEMP2" ;
--DROP INDEX "DB2IHQB"."XDEPT2";
--DROP INDEX "DB2IHQB"."XDEPT3";
但性能提高的结果如下:
[ 14.0000] timeron(没有建议)
[ 14.0000] timeron(对于当前解决方案)
[0.00%] 提高
从这个结论我们分析建议的合理性:
DROP INDEX这个操作应该不能进行,因为这些索引可能是调优其它SQL时创建的,不能调整了这个SQL的性能而影响了之前调整过的SQL性能,所以,这个DROP动作需要综合考虑,不能直接采纳。
COST为14,没有像人工分析的那样调优结果可以降低到0.0271976。
所以,调优SQL时,建议我们先用设计顾问程序,然后继续用人工分析的方式微调设计顾问程序的建议。
注意:
用db2exfmt工具运行的结果与IBM DATA STUDIO的结果,很相似,容易读。
用db2expln工具运行的结果不容易读
在调优SQL时,建议选择工具db2exfmt或IBM DATA STUDIO,前者是命令行+文本界面型,适合AIX等UNIX环境操作;后者是GUI型,适合Windows环境操作。
5.2 for update with rs导致SQL执行慢
附件共享:https://pan.baidu.com/s/1ht7fvVm
供稿 | 黄海 编辑 | lin

