




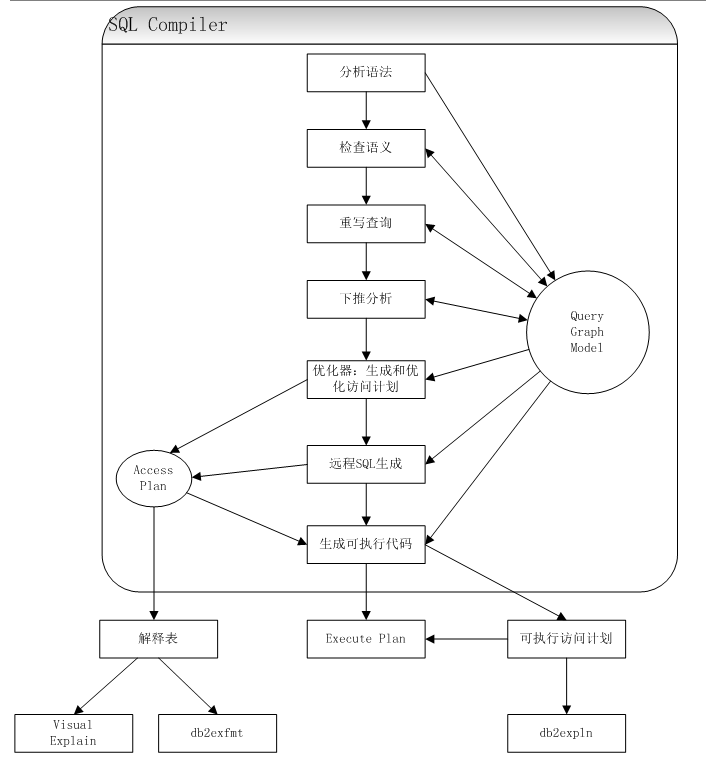
SQL访问计划详解及案例
1SQL编译过程
1.1 分析语法
编译器从语法层面分析SQL语句,如果检测到任何语法错误,就会停止处理,返回相应的错误提示给用户。经过语法分析后,SQL语句就被转换成内部表示形式,即QGM(Query Graph Model),QGM用图结构来表示SQL语句,后续的编译过程将围绕QGM展开。
1.2 检查语义
编译器从语义层面分析SQL语句,例如类型检查、参照完整性约束、触发器和检查约束等,语义分析的对象也加到QGM中。
1.3 重写查询
在不改变语义的基础上,对查询进行等价变换。例如,将谓词下推到基本表作为局部谓词;用MQT重写查询;将子查询转换成连接。
1.4 下推分析
处理联邦查询独有的步骤,其主要任务是确定查询中的哪些操作可以放到远程数据源执行
创建联邦数据库:
db2 update dbm cfg using FEDERATED YES
db2stop force
db2start
db2 connect to hqbbdb
db2 "catalog tcpip node N137 REMOTE 182.119.148.137 SERVER 50000"
db2 "catalog db bitscn at node N137"
db2 "create wrapper drda"
db2 "create server uat_s type db2/udb version 10.1 wrapper drda authorization \"db2obits\" password \"8545bdnc\" options (dbname 'bitscn')"
db2 "create user mapping for \"db2ihqbb\" server uat_s options (remote_authid 'db2obits',remote_password '8545bdnc')"
db2 "create nickname test for uat_s.db2ibits.test"
db2 "create view test_view as select * from test"
db2 "select id,count(id) from test_view group by id"
查看访问计划:
Original Statement:
------------------
select id, count(id) from test_view group by id
Optimized Statement:
-------------------
SELECT Q3."ID" AS "ID", Q3.$C1 FROM
(SELECT Q2."ID", COUNT(Q2."ID") FROM
(SELECT Q1."ID" FROM DB2IHQBB.TEST AS Q1 ) AS Q2
GROUP BY Q2."ID") AS Q3
Access Plan:
-----------
Total Cost: 50.0187
Query Degree: 1
Rows
RETURN
( 1)
Cost
I/O
|
2
GRPBY
( 2)
50.0183
2
|
2
TBSCAN
( 3)
50.0182
2
|
2
SORT
( 4)
50.0177
2
|
2
SHIP
( 5)
50.0168
2
|
2
NICKNM: DB2IHQBB
TEST
Q1
5) SHIP : (Ship)
Cumulative Total Cost: 50.0168
Cumulative CPU Cost: 68759
Cumulative I/O Cost: 2
Cumulative Re-Total Cost: 0.00126073
Cumulative Re-CPU Cost: 5166
Cumulative Re-I/O Cost: 0
Cumulative First Row Cost: 25.0128
Estimated Bufferpool Buffers: 2
Remote Total Cost: 9.85938
Remote Communication Cost: 5.90625
Arguments:
---------
CSERQY : (Remote common subexpression)
FALSE
DSTSEVER: (Destination (ship to) server)
- (NULL).
RMTQTXT : (Remote statement)
SELECT A0."ID" FROM "DB2IBITS"."TEST" A0 FOR READ ONLY
SRCSEVER: (Source (ship from) server)
UAT_S
STREAM : (Remote stream)
FALSE
Input Streams:
-------------
1) From Object DB2IHQBB.TEST
Estimated number of rows: 2
Number of columns: 2
Subquery predicate ID: Not Applicable
Column Names:
------------
+Q1.$RID$+Q1."ID"
Output Streams:
--------------
2) To Operator #4
Estimated number of rows: 2
Number of columns: 1
Subquery predicate ID: Not Applicable
Column Names:
------------
+Q2."ID"
具体详见附件:1db2exfmt.txt
1.5 生成和优化访问计划
优化器分析QGM,根据表和索引上的统计信息,并参考当前数据库的各种参数配置,估计各种访问计划的成本,然后选择成本最小的计划作为最终的访问计划。
以SQL语句作为输入:优化器将重点考虑SQL中谓词的处理效率和表的连接方式
系统与数据库的设置:优化器会充分考虑CPU速度、存储的I/O速度、并行方式(NONE、分区内并行、分区间并行)、并发环境(AVG_APPLS=1)、优化级别(DFT_QUERYOPT=5)、缓冲池和排序堆大小等。
表和索引统计信息:统计信息是优化器进行SQL语句优化的基础。
生成最优访问计划:优化器充分考虑表访问方式、连接方法以及操作顺序,生成各种可能的访问计划,并根据成本模型计算每个访问计划的成本,最后选择一个总成本最小的访问计划。
1.6 远程SQL生成
处理联邦查询时独有的步骤,编译器会根据远程表的访问计划,生成用于在远程数据源执行的SQL语句。即联邦数据库执行select id,count(id) from test_view group by id,就会生成一条类似的SQL在源数据库执行:
SELECT A0."ID" FROM "DB2IBITS"."TEST" A0 FOR READ ONLY。
1.7 生成可执行代码
编译器根据访问计划和QGM生成一个可由DB2引擎执行的二进制代码段(section)供DB2运行时使用。这个代码段不可读,其中包含的访问计划信息可以通过工具db2expln查看。
Package(程序包):程序包是一个存储过程、静态SQL语句或者UDF编译后生成的可执行二进制代码。当一个存储过程被编译时,每一条SQL编译成一个可执行的二进制代码段(section),这些二进制代码段加上其他的一些必要信息组织成一个DB2程序包,并存储在DB2编目表中。当存储过程被调用时,DB2从编目表中读取相应的DB2程序包直接执行。产生的方案存储在syscat.packages和syscat.statements中。syscat.packages存储概要信息,syscat.statements存储具体的执行计划。比如syscat.packages指明该绑定的程序含有多少section(即多少条SQL语句,每条SQL语句产生一个SECTION),所以如果syscat.packages的列TOTAL_SEC=3,则syscat.statements会有3条记录。
动态SQL编译后生成的可执行二进制代码段(即访问计划)存储在Package Cache内存中,每个SQL的编译结果大小在100KB左右。
流程图如下:
2SQL访问计划
2.1 查看访问计划
2.1.1、db2expln
db2expln:打印出代码段(section)中的访问计划信息
(1) 解释动态SQL(dynexpln已经被db2expln取代)
db2expln -d sample -q "select * from employee" -t -g
db2expln -d sample -f db2expln.sql -g -o 1db2expln.txt
db2expln -d sample -cache <AnchID>,<StmtUID>,<EnvID>,<VarID> -t -g
db2expln -d sample -cache 1023,3653,2,1 -t –g
<AnchID>,<StmtUID>,<EnvID>,<VarID>的值可以通过
db2pd -d sample –dyn获取,如下:
Dynamic SQL Variations:
Address | AnchID | StmtUID | EnvID | VarID | NumRef
0x0A000E00B270C420 | 1023 | 3653 | 2 | 1 | 2
结果类似于:
Statement:
SELECT NEXT_TRX_CODE, COUNTRY_NUM_CODE, REG_DATA
FROM REG_EVENTT
WHERE EVENT_NO =?
Optimizer Plan:
Operator
(ID)
RETURN
( 1)
|
FETCH
( 2)
-/ \
IXSCAN Table:
( 3) DB2IHQB
| REG_EVENTT
Index:
SYSIBM
SQL140109104925160
(2) 解释存储过程中静态SQL语句的访问计划
首先根据存储过程名字找到程序包名,假定存储名字为GETN,则可以根据如下语句找到编译后生成的包(package):
SELECT
r.routineschema,
r.routinename,
d.bname,
d.bschema
FROM
syscat.routines r,
syscat.routinedep d
WHERE
r.routineschema='DB2IHQB'
AND r.routinename='GETN'
AND r.specificname=d.specificname
AND d.btype='K';
为
DB2IHQB GETN P1837332765 DB2IHQB
(
SELECT * FROM SYSCAT.STATEMENTS WHERE PKGNAME='P1837332765'
)
接着,打印出程序包P1837332765的访问计划:
db2expln -d sample –g -c DB2IHQB -p P1837332765 -s 0 -o 1db2expln.txt
-g是指给出存取计划的图形输出
-c表示包创建者ID
-s 0是指分析所有的SQL命令
注意:
db2expln.sql中的SQL语句不要用分号(;)结尾
db2expln工具不需要使用解释表支持
2.1.2、db2exfmt
db2exfmt:用于直接处理已收集并存储在解释表中的解释数据。
给定数据库名和其他限定信息,db2exfmt工具将在解释表中查询信息、格式化结果,并生成一份基于文本的报告,此报告可直接显示在终端上或写入ascii文件。
首先进入/home/db2ihqb/sqllib/misc,执行db2 -tvf EXPLAIN.DDL
产生EXPLAIN_INSTANCE等解释结果存储表,表创建在任意表空间中,但非SYSTOOLSPACE表空间。
创建解释表的另一种方式是调用下面的存储过程,其中第二个参数”C”的含义为创建。相应的,如果传入参数”D”即删除解释表。
解释表的删除与创建,是创建在表空间SYSTOOLSPACE下。
db2 "call sysproc.sysinstallobjects('EXPLAIN','D','',CURRENT SCHEMA)"
db2 "call sysproc.sysinstallobjects('EXPLAIN','C','',CURRENT SCHEMA)"
补充:
用户表空间SYSTOOLSPACE和用户临时表空间SYSTOOLSTEMPSPACE通常用于通过下列向导、实用程序或函数自动创建的表:
自动维护
设计顾问程序(两个都没有也不会报错)
控制中心数据库信息面板
SYSINSTALLOBJECTS存储过程(如果未指定表空间输入参数的话)
GET_DBSIZE_INFO存储过程(两个都没有也不会报错,执行的时候会自动创建SYSTOOLSPACE表空间)
手工创建:
Create regular tablespace systoolspace in IBMCATGROUP MANAGED BY SYSTEM USING (‘SYSTOOLSPACE’)
CREATE USER TEMPORARY TABLESPACE SYSTOOLSTEMPSAPCE IN IBMCATGROUP MANAGED BY SYSTEM USING (‘SYSTOOLSTEMPSAPCE’)
(1) 获取访问计划到解释表
A)、explain all语句
db2 "explain all with snapshot for select * from test"记录信息最全
db2 "explain all for snapshot for select * from test"只填充表的SNAPSHOT列,其余列都不填充
db2 "explain all for select * from test"不填充表的SNAPSHOT列,其余列都填充
EXPLAIN_INSTANCE表中的SNAPSHOT_TAKEN列(值为Y\N\0,Y表示有快照、N表示不带快照、0表示只有快照)表示每一条被解释的语句是否有一个Visual Explain快照。
B)、使用解释专用寄存器
DB2用两个解释专用寄存器来收集动态SQL语句的解释信息,这些专用寄存器是:
CURRENT EXPLAIN MODE 获取解释信息,不获取快照信息
CURRENT EXPLAIN SNAPSHOT 获取快照信息,不获取解释信息
下面的语句用来设置解释专用寄存器的值:
SET CURRENT EXPLAIN MODE option
SET CURRENT EXPLAIN SNAPSHOT option
解释寄存器的option(选项)有:
NO 不获取动态SQL语句的解释信息和快照信息
YES 当执行动态SQL语句时,获取解释信息或快照信息并返回结果
EXPLAIN 获取动态SQL语句的解释信息或快照信息,无需执行SQL语句。
一旦把寄存器设置成YES或EXPLAIN,将对后续的动态SQL语句进行解释,直到寄存器重置为NO为止。
下面两个选项只对CURRENT EXPLAIN MODE寄存器有效
RECOMMENT INDEXES
EVALUATE INDEXES
等同于db2advis,即获取解释信息的同时推荐索引和评估推荐索引的提升性能。
(2) 格式化二进制访问计划成ascii文本格式
获取的二进制访问计划存放在EXPLAIN_INSTANCE表中,可以使用db2exfmt格式化成ascii文本格式,有如下两种格式化方式:
db2exfmt -d sample -g tic -e DB2IHQB -n % -s % -w % -# 0 -o 1db2exfmt.txt
这种方式能格式化explain_instance中的所有访问计划
获取访问计划的简单有效方式:
db2exfmt -d sample -l –o 1db2exfmt.txt
这种方式只能格式化一条访问计划,默认格式化explain_instance中的最新访问计划,如果在交互的时候,对如下询问项输入了explain_instance中某一行这四列的值,那么就获取对应行的访问计划,而不是固定的只格式化最新访问计划。
Enter up to 26 character Explain timestamp (Default -1) ==>
Enter up to 128 character source name (SOURCE_NAME, Default %%) ==>
Enter source schema (SOURCE_SCHEMA, Default %%) ==>
Enter section number (0 for all, Default 0) ==>
(3) 获取动态SQL和静态SQL访问方案
A)、解释动态SQL
在解释SQL语句时使用snapshot选项,DB2将编译SQL语句时使用的统计信息也包含在访问计划的输出中,这样大大方便了对访问计划的分析。
db2 set current explain mode explain
db2 set current explain snapshot explain
db2 "select ..."
db2 set current explain mode no
db2 set current explain snapshot no
db2exfmt -d sample -l -o 1db2exfmt.txt
B)、解释存储过程中静态SQL语句的访问计划
要通过db2exfmt抓取存储过程的访问计划,需要在创建存储过程之前设置EXPLAIN YES这个编译选项。有两种方法来设置这个选项:
调用存储过程SET_ROUTINE_OPTS设置EXPLAIN YES编译选项,于是在当前会话中创建的SQL存储过程,DB2会将其访问计划写入到解释表中,从而可以用db2exfmt工具获取。在每次rebind的时候,该存储过程中的SQL语句会重新编译,其访问计划也将重新被写入到解释表;但如果rebind指定的项为REOPT ALWAYS,则rebind的时候不会生成访问计划,在执行call的时候才生成访问计划到解释表中。
db2 connect to sample
db2 "CALL SET_ROUTINE_OPTS('EXPLAIN YES')"
例子一:
--执行存储过程的rebind,每执行一次,都会生成新的访问计划存放到解释表中
db2 "call sysproc.rebind_routine_package('P','DB2IHQB.GETN','REOPT NONE')"
例子二:
--使用rebind选项REOPT ALWAYS执行存储过程的rebind
db2 "call sysproc.rebind_routine_package('P','DB2IHQB.GETN','REOPT ALWAYS')"
此时不会生成新的访问计划,只有在真正执行存储过程的时候(比如:db2 "call GETY('156',?,?)")才会生成访问计划并存放到解释表中。
设置注册变量DB2_SQLROUTINE_PREPOPTS,这需要重新启动DB2实例才能生效,随后创建的SQL存储过程将能用db2exfmt抓取访问计划。
db2set DB2_SQLROUTINE_PREPOPTS="EXPLAIN YES"
当发现存储过程访问计划不是最新时,可使用如下语句重新绑定这个存储过程:
-- any表示保留当前编译选项,只是利用最新统计信息重新编译
db2 "rebind package DB2IHQB.P1837332765 resolve any"
或
db2 "call sysproc.rebind_routine_package('P','DB2IHQB.GETN','ANY')"
在syscat.routines的PRECOMPILE_OPTIONS选项存放编译选项
例子三:
db2 "create table test(id int,name char(10))"
db2 "CALL SET_ROUTINE_OPTS('EXPLAIN YES') "
db2 -td@ -vf proc.sql
db2 "call sysproc.rebind_routine_package('P','HUANGH.proc_test','REOPT NONE')"
create procedure proc_test(v1 int)
begin
declare time int default 0;
while(time<v1)
do
insert into test values (1,'testlog');
set time=time+1;
end while;
end@
2.2 解读访问计划
db2exfmt输出信息主要包含下面的部分
(1) 全局上下文信息:包括数据库配置、优化级别和隔离级别等
包括:
DB2版本和生成访问计划的时间
******************** EXPLAIN INSTANCE ********************
DB2_VERSION: 10.01.5
SOURCE_NAME: SQLC2J25
SOURCE_SCHEMA: NULLID
SOURCE_VERSION:
EXPLAIN_TIME: 2016-11-04-16.55.33.287981
EXPLAIN_REQUESTER: DB2IBITS
数据库管理器和数据库的配置:并行方式、CPU速度和通信带宽、缓冲池、排序堆、AVG_APPLS(平均有多少用户连接这个数据库,根据这个参数分配可用的内存资源和锁资源)
Database Context:
----------------
Parallelism: None
CPU Speed: 2.086187e-07(millisec/instruction)
Comm Speed: 100(MB/sec)
Buffer Pool size: 1000
Sort Heap size: 256
Database Heap size: 1200
Lock List size: 4096
Maximum Lock List: 10
Average Applications: 1
Locks Available: 13107
语句级别上下文:优化级别、隔离级别、并行度(db2 SET CURRENT DEGREE \'4\')。优化级别可以为0、1、2、3、5、7、9,默认为5。优化级别越高,优化器需要考虑的访问计划也就越多,编译时间也就越长(set current quey optimization=5)。
Package Context:
---------------
SQL Type: Dynamic
Optimization Level: 5
Blocking: Block All Cursors
Isolation Level: Cursor Stability
---------------- STATEMENT 1 SECTION 201 ----------------
QUERYNO: 3
QUERYTAG: CLP
Statement Type: Select
Updatable: No
Deletable: No
Query Degree: 1
(2) SQL语句文本:包括原始SQL语句和优化后的SQL语句
Original Statement:
------------------
select
A.FIRSTNME,
A.JOB,
B.DEPTNAME
from
employee A,
DEPARTMENT B
WHERE
A.WORKDEPT=B.DEPTNO * <OPTGUIDELINES> <NLJOIN> <IXSCAN TABLE='A' INDEX='PK_EMPLOYEE'/> <IXSCAN TABLE='B'/> </NLJOIN> </OPTGUIDELINES> */
Optimized Statement:
-------------------
SELECT
Q2."FIRSTNME" AS "FIRSTNME",
Q2."JOB" AS "JOB",
Q1."DEPTNAME" AS "DEPTNAME"
FROM
DB2IBITS.DEPARTMENT AS Q1,
DB2IBITS.EMPLOYEE AS Q2
WHERE
(Q2."WORKDEPT" = Q1."DEPTNO")
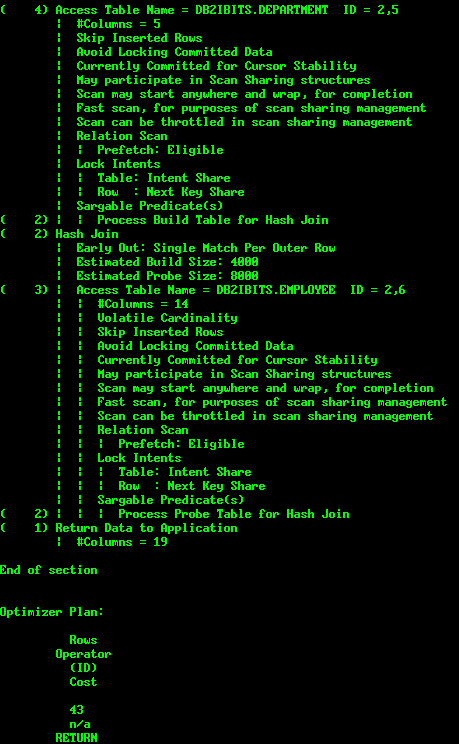
(3) 访问计划:包含访问计划图和每个操作符的细节信息,访问计划中用到的对象以及统计信息,包括表、索引等。
用树型图表示访问计划,包含的节点分为操作节点和对象节点,其中非页节点为操作节点,叶子节点为对象节点。操作节点 描述每个操作的具体信息,从上到下依次为:返回的行数、操作符名称、编号、累计的成本和IO成本;对象节点包括基本表、索引、临时表和表函数等。
Access Plan:
-----------
Total Cost: 20.624
Query Degree: 1
Rows
RETURN
( 1)
Cost
I/O
|
42
^NLJOIN
( 2)
20.624
3
-----------+-----------\
42 1
FETCH FETCH
( 3) ( 5)
6.83929 6.81706
1 1
----+----\ ----+----\
42 42 1 14
IXSCAN TABLE: DB2IBITS IXSCAN TABLE: DB2IBITS
( 4) EMPLOYEE ( 6) DEPARTMENT
0.0234154 Q2 0.0089656 Q1
0 0
| |
42 14
INDEX: DB2IBITS INDEX: DB2IBITS
PK_EMPLOYEE PK_DEPARTMENT
Q2 Q1
访问计划图中操作符的成本是累计的,是该操作符及其子树成本的总和。因此,在分析访问计划时,应该关注成本增长最大的操作符。
操作符描述如下表:
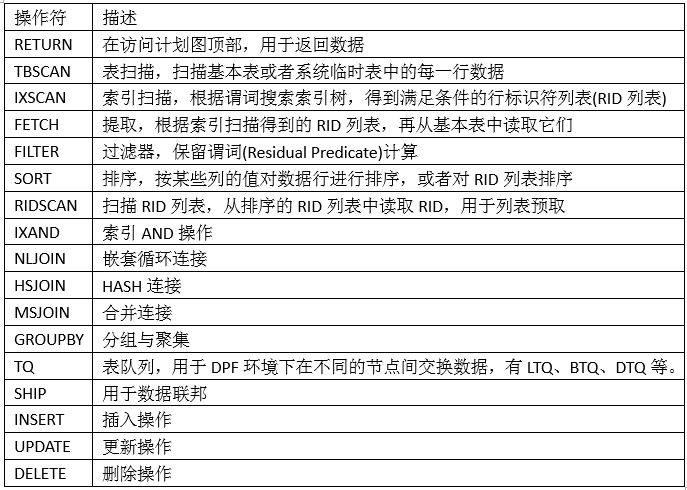
访问计划图后面紧接着是每个操作符的详细信息,包括操作符的成本明细、参数和谓词。需要特别注意谓词的类型和过滤因子。
(4) 访问计划中用到的表和索引等数据库对象
3表连接
如果需要连接两个以上的表,优化器每次也最多只能连接两个表,并保存中间结果,再与其他表做两两连接,优化器在考虑两个表的连接操作时,主要考虑三种连接方法:嵌套循环连接、合并连接和HASH连接。
对于两两连接方法,连接的两个表一个为外表,另一个为内表,外表也称为驱动表,处理连接时,对于外表的每一行,都会去内表中查找是否有相应的匹配行,优化器根据所选连接方法的类型和成本决定哪个是外表、哪个是内表。
3.1 嵌套循环连接
两层循环处理连接,适用于外表较小且内表较小或者内表上可以使用索引扫描的场景。对于不等谓词(即>、<、>=、<=和!=)的连接,只能使用嵌套循环连接。对于两个表的笛卡尔积(即没有连接谓词),也只能使用嵌套循环连接,如select * from t1,t2。
在解释执行话中,左边的表为外表,右边的表为内表,如下图:
db2expln -d sample -q "select * from employee a,department b" -g -t -i|more
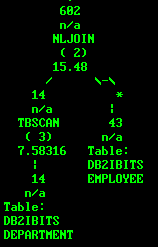
外表为:department
内表为:employee
如果通过db2exfmt来看优化后的SQL语句,排在前面的是外表,排在后面的是内表,如:
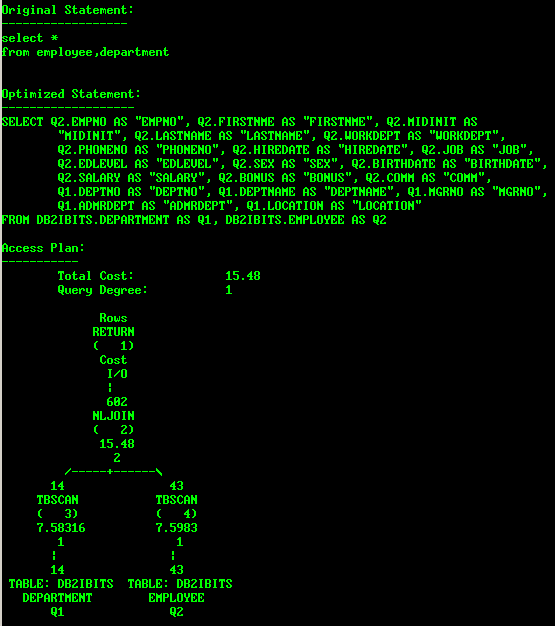
如上判断内外表的方法对HASH连接也是有效的。
对外表中符合条件的行进行扫描,对于在外部表中找到的每一行,将循环一遍内部表。所以,DB2优化器一般选择行数较小的表作为外部表。
如果内部表上连接列有索引,那嵌套循环连接会更有效,这是主要的。
如果外部表上连接列有索引,那嵌套循环连接也有效,因为可以使外部表有序,但是次要的。
所以,建议在连接列上,外部表和内部表都有索引,在索引不能创建太多的情况下,考虑对内部表的连接列建立索引。
3.2 合并连接
合并连接能处理多个连接等式谓词,内表和外表都需要有序,这可以用显式的SORT来保证,也可以是索引中本来就是有序的数据。
当连接表的连接列上没有可用索引时,通常使用该连接方法。
连接开始之前,如果有过滤条件,那么数据库服务器首先会应用它们,然后对连接列上每个表中的行进行排序。因为将所有的连接表排序,所以成本通常极高。
如:MSJOIN
select e.*,d.* from employee e,department d where e.workdept=d.deptname
3.3 HASH连接
当一个表或多个连接表上没有索引时,或者当数据库服务器必须从所有连接表中读取大量行时,就使用HASH连接。
HASH连接的连接谓词只能是等于谓词,可处理多个等于谓词,要求连接谓词两端的字段类型相同,且不能含有表达式。就CHAR类型而言,长度必须相同;就DECIMAL类型而言,精度和小数位必须相同。
DB2 V10增强了HASH连接的能力,能将含有表达式或者字段类型不匹配的连接谓词作为HASH连接的连接谓词,比如T1.C1=T2.C2+1,或者T1.C1_INT=T2.C2_DECIMAL等,不过从性能上考虑,应该避免使用复杂表达式或者类型不匹配的连接谓词。。
HASH连接通常比MSJOIN连接快,因为它没有涉及排序操作。
内表一般较小,用内表构建HASH表。对于外表的每一行,在这个HASH表中进行快速查找,
HASH连接的运行原理:
构建HASH表(build table):首先扫描内表,根据连接谓词的字段计算HASH键(hash key),构建一个HASH表(key为连接谓词,value过滤后的行的某些列)。HASH表被分为几个分区,如果内存中没有足够的空间容纳整个表,则有些分区将被写入磁盘上的临时表。构建HASH表时使用的内存池为SORTHEAP,如果SORTHEAP的内存不够,则会溢出到磁盘上,导致磁盘IO溢出。因此,为了提高HASH连接的性能,避免IO溢出,应该适当调整SORTHEAP的大小。
探测表(probe table):扫描外表,对于外表的每一行,对连接列应用同一HASH算法计算HASH键,然后根据HASH键在HASH表中查找内表的匹配记录。如果HASH键对应的HASH表分区在内存中,则立即返回匹配连接的结果。如果该分区被写入到磁盘上的临时表中,则外表的行也被写入临时表。
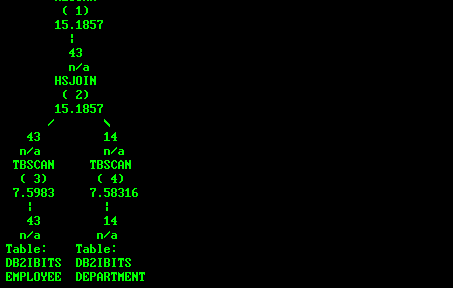
如下为一个散列连接的例子:
db2expln -d sample -q "select * from employee a,department b where a.workdept=b.deptno" -g -t -i|more
4统计信息和基数估计
优化器依赖于准确的统计信息来进行基数估计,凭借基数估计来计算每个操作符的成本以及整个查询的成本,基于成本来评估候选的访问计划,因此,统计信息是优化器的导航仪。
DB2中的统计信息主要包括以下内容:
基本统计信息:包括表、列和索引的统计信息
分布统计信息:频率统计信息和分位数统计信息
列组统计信息:计算具有相关性的列组统计信息,为联合谓词的过滤因子更精确的估计
db2 "runstats on table db2obits.c_acctday and indexes all"
只有基本统计信息的情况下,DB2优化器认为所有的数据都是均匀分布的,优化器对下面三类谓词的过滤因子计算公式如下所示:
局部等于谓词(如C1=7)
ff(Filter Factor)=1/colcard(C1)
范围谓词(如key1<C1<=key2)
ff=(key2-key1)/(high2key-low2key)(仅供参考)
连接谓词(如C1=C2)
ff=1/MAX(colcard(C1),colcard(C2))
对于单个表T上的谓词条件,相应的基数计算公式为:
card(T)*ff
对于两个表T1和T2上的连接谓词,相应的基数计算公式为:
card(T1)*card(T2)*ff
4.2 分布统计信息与基数估计
列上某个值的数目比较多或者某区间上的数据比较多,使用均匀分布进行基数估计就不准确了,需要利用分布统计信息对基数估计进行修正。
DB2提供了两种分布统计信息:频率统计信息和分位数统计信息
db2 "runstats on table db2obits.c_acctday with distribution and indexes all"
如果SQL语句中的谓词使用的是参数,比如C1=?,则优化器用不上分布统计信息,只能使用基本统计信息来估计基数,但使用REOPT ALWAYS后,能够使用分布统计信息。
(1) 频率统计信息
runstats on table employee with distribution on columns (job num_freqvalues 10) and indexes all
频率统计信息记录出现频率最高的几个值以及出现次数。例如EMPLOYEE表上列JOB的频率统计信息如下所示:
JOB COUNT(JOB)
-------- ------------------
DESIGNER 10
CLERK 8
MANAGER 7
OPERATOR 6
FIELDREP 5
ANALYST 3
SALESREP 2
PRES 1
对于查询select count(*) from employee where job='DESIGNER',如果使用基本统计信息,表的基数为42,列JOB的基数为8,则基数估计为card*1/colcard(job)=42/8=5.25。如果使用频率统计信息,则能精确地得到基数为10
(2) 分位数统计信息
分位数统计信息实际上就是统计数据的区间分布。例如列C1包含下面的值,其数据分布区间不是均匀的:
0
1
3
1
2
4
5
1
6
0
db2 "runstats on table test with distribution on columns (c1 num_quantiles 4) and indexes all"
分位数统计信息如下所示,数据按从小到大排列后,处于第一个位置的为0.0,第3个位置的为6.3等。
k k-quantile
1 0.0
3 6.3
7 8.5
10 100.0
用基本统计信息和分位数统计信息分别计算下面两个谓词的基数:
C1<=8.5:表上共有7条记录满足这个谓词
使用基本统计信息,基数估计为:(key2-key1)/(HIGH2KEY-LOW2KEY)*Card=(8.5-5.1)/(93.6-5.1)*10=0.38,存在很大偏差。而使用分位数统计信息,由于第7个位置的值为8.5,直接得到基数为7,与实际情况完全一致。
C1<=10:表上共有8条记录满足这个谓词
使用基本统计信息,基数估计为:(key2-key1)/(HIGH2KEY-LOW2KEY)*Card=(10-5.1)/(93.6-5.1)*10=0.55,存在很大偏差。而使用分位数统计信息,需要将这个谓词作为两部分来进行估算:C1<=8.5的基数为7,而C1>8.5 AND C1<=10的基数估计为(10-8.5)/(100-8.5)*(10-7)=0.05,因此,谓词C1<=10估计为7.05,比使用基本统计信息要精确得多。
4.3 列组统计信息与基数估计
如果SQL语句中有两个或多个谓词,优化器在估计基数时假定这两个谓词是独立的。但是,在某些情况下,这两个谓词或者多个谓词并不独立,也就是说这些列上的数据具有相关性,这时,优化器估计的基数就会存在偏差。
假如:EMPLOYEE表上共有42条记录,满足谓词JOB=’ANALYST’的数据行数为3,而满足WORKDEPT=’C01’的行数为4。在收集了分布统计信息后,优化器能精确地估计这两个谓词的过滤因子,分别为3/42=0.0714286和4/42=0.0952381。
对于查询select * from employee where job='ANALYST' and workdept='C01',优化器会假定这两个谓词是独立的,于是估计基数为Card*(3/42)*(4/42)=0.28571。其访问计划如下所示:
0.285714
TBSCAN
( 2)
6.844
1
|
42
TABLE: DB2IHQBB
EMPLOYEE
Q1
但是,这个查询实际返回行数为3。这里的基数估计偏差正是由于workdept和job的数据具有相关性导致的。这时可以在workdept和job上收集列组统计信息,修正优化器的基数估计。
runstats on table employee on all columns and columns((workdept,job)) with distribution and indexes all
这样,再查看SQL语句的访问计划,如下所示,估计的基数为2.8,与实际行数非常接近。
2.8
TBSCAN
( 2)
6.844
1
|
42
TABLE: DB2IHQBB
EMPLOYEE
Q1
当多个列的数据具有相关性时,列组统计信息不仅能优化上述局部谓词的基数估计,也能对多个列连接谓词的基数进行更精确的估计。
4.4 自动runstats
设置AUTO_MAINT、AUTO_TBL_MAINT、AUTO_RUNSTATS为ON
DB2针对每张表维护一个UDI计数器,UDI计数器记录该表上发生update、delete、insert的记录数,该表每执行一次runstats,UDI计数器就被重置为0。所以,自从上次收集统计信息以来表有多少数据发生改变, 是判断表是否需要runstats的重要依据。
UDI计数器通过如下命令查看,
db2pd -d sample –tcbstats
TCB Table Information:
Address TbspaceID TableID PartID MasterTbs MasterTab TableName
0x0000002AD24FCED8 3 2 n/a 3 2 T1
0x0000002AD24FBA58 3 3 n/a 3 3 T2
TCB Table Stats:
Address TableName Scans UDI
0x0000002AD24FCED8 T1 1 3
0x0000002AD24FBA58 T2 1 3
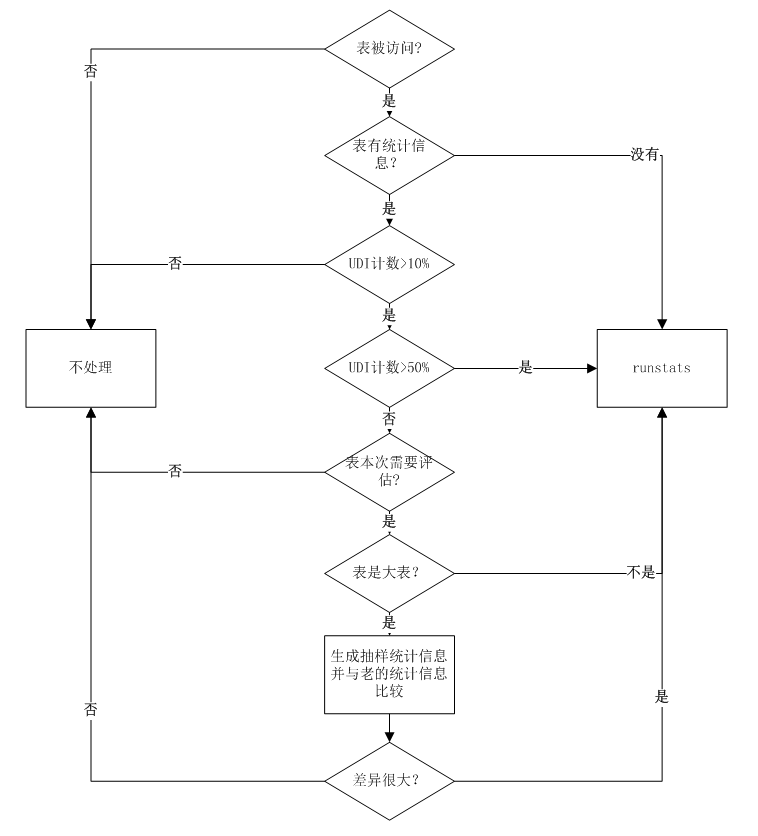
启用自动收集统计信息后,第一次runstats评估发生在数据库激活后的两个小时,之后每两个小时评估一次是否需要执行新的runstats。
(1) 检查表是否被访问
(2) 检查表是否有统计信息,如果没有统计信息,执行runstats
(3) 检查UDI是否大于10%
(4) 检查UDI是否大于50%,如果大于,执行runstats
(5) 检查表是否属于本次需要评估runstats的表,如果不是,直接跳过。对每个表,一个内部表记录该表历史统计信息改变的多少,如果检测到表的统计信息在一段时间内发生了很多的改变,那么该表被评估的频率将加快(最快两小时一次);相反地,如果一个表统计信息没有发生变化,该表被评估的频率将减少(最慢可能几个月都不评估)。
(6) 如果表数据页不多,属于小表,就runstats
(7) 如果表数据页大于4000页,就抽样部分数据并收集该部分数据的统计信息,与当前统计信息比较,如果差异很大,就收集该表的统计信息。
流程图如下:
表第一次统计信息基于表大小决定是否抽样生成统计信息,之后每次收集统计信息是使用
SELECT SUBSTR(STATISTICS_PROFILE, 1, 150) AS STATISTICS_PROFILE FROM SYSCAT.TABLES里面的统计概要文件,如果没有概要文件,那就用如下语句收集统计信息:
runstats on table db2obits.tabname with distriution and sampled detailed indexes all;
使用7%的系统资源
不对VOLATILE表收集统计信息
检查健康快照,看自动收集统计信息过程中,哪些表出现了错误(统计信息不一致(表与索引不一致)、锁超时(5秒钟)、STAT_HEAP_SZ对大小不够(建议15000个页面));或者没有启用自动收集统计信息,查看哪些表需要runstats。
db2 get health snapshot for db on sample WITH FULL COLLECTION
关注db.tb_runstats_req指示器。
默认情况下,健康监视器和db.tb_runstats_req都是启用的。可通过如下方法检查:
db2 get dbm cfg|findstr i heal
监视实例和数据库的运行状况 (HEALTH_MON) = OFF
通过如下命令启用
db2 update dbm cfg using HEALTH_MON ON
查看db.tb_runstats_req是否启用
GET ALERT CONFIG FOR DATABASE ON SAMPLE
指示器名称 = db.tb_runstats_req
缺省值 = 是
类型 = 基于集合状态的
灵敏度 = 0
操作 = Disabled
阈值或状态检查 = Enabled
《阈值或状态检查 = Enabled》表示启用
如果没有启用,使用如下命令启用db.tb_runstats_req
UPDATE ALERT CONFIG FOR DATABASE ON sample USING db.tb_runstats_req SET THRESHOLDSCHECKED YES
DB2 V8.2的自动收集统计信息日志会打印在db2diag.log中,不管DIAGLEVEL的值。DB2 V9以后,必须设置DIAGLEVEL=4,该日志信息才会出现在db2diag.log中。
手动收集runstats时,目标表不允许drop或alter,但自动收集runstats时,如果发出drop或alter操作,会强制断开自动收集runstats的连接操作,允许drop或alter执行。
4.5 联邦表统计信息收集
db2 "call sysproc.nnstat('HIS','BDPOUSER','CAP_BTP_HIS',NULL,NULL,0,'/tmp/1.txt',?)"
参数分别为:SERVER、SCHEMA、NICKNAME、COLNAMES、INDEXNAMES、METHOD、LOG_FILE_PATH、OUT_TRACE
其中/tmp/1.txt是日志信息
如果要收集HIS下的所有昵称信息,命令为:
db2 "call sysproc.nnstat('HIS','','',NULL,NULL,0,'/tmp/1.txt',?)"
如果源表表结构发生了变化,或者新增加了索引等,就最好进行一次runstats,然后重建昵称,这样才能把表结构信息和索引信息及统计信息反映在联邦表,如果要重建昵称,登录的时候最好把用户和密码带上,例如:
db2 connect to bdpo user bdpouser using bdpouser
5疑惑解答与案例演示
案例一:编译使用100%的CPU
案例二:企业年金算税SQL优化
具体详见附件
附件共享:https://pan.baidu.com/s/1c37n5kc
供稿 | 黄海 编辑 | lin

