




数据库维护与数据迁移详解
1数据库维护
1.1、 runstats
1.1.1、runstats原理
在系统运行一个查询的时候,优化器需要决定用某种方式来访问数据。但是DB2基于什么原理来判断如何选择访问数据的顺序呢?答案就是统计信息。只有当DB2对表中的数据有一个大概的了解,才能知道每一步操作大约需要处理多少数据,返回多少行。当优化器了解了这些信息后,就会根据一系列运算,判定出各种访问途径所需要消耗的资源,然后从中选择一个消耗资源最少的方法。
DB2收集统计信息的命令就是runstats。
执行runstats时,需要扫描表数据页和索引页,读入到对应的缓冲池中,CPU对缓冲池中的数据和索引信息进行计算,得出表和索引中有多少行数据,有多少不同的数值,及进一步的数据分布信息(频率采样、百分比采样)。表扫描和索引扫描消耗IO,计算统计信息消耗CPU。
runstats命令有allow write access和allow read access选项,allow write access选项是默认行为,表示runstats表时,其他应用可以读取和修改该表数据;allow read access选项则表示在runstats表时,其他应用只能读取该表数据,而无法修改。当指定allow write access选项时,DB2会在runstats的表上加IN锁,而指定allow read access时,会在runstats表上加S锁。
理论上,统计信息收集得越细致越好。但是过于细致的统计信息(尤其是数据分布信息)可能会导致DB2在优化SQL时需要处理更多的信息,并占用更多的系统存储空间,可能会导致性能的下降。因此,一般情况下对数据分布信息使用默认的数据分布采样设置,即频率采样为10,百分比采样为20。
1.1.2、什么时候需要runstats
在下列情况下,需要使用RUNSTATS命令来收集统计信息
当向表装入(import\load)数据时
当用reorg命令重新组织表和索引时
当存在大量影响表的DML操作时
当在表中创建新的索引时。可以在创建索引时通过添加COLLECT STATISTICS子句收集统计信息。或创建索引成功后,单独对该索引收集统计信息,命令类似:runstats on table db2ibits.test for indexes test_i1,test_i2
数据库固定周期收集统计信息,比如一周收集一次,系统表也需要做runstats。
1.1.3、表抽样和索引抽样
当执行大数据量的统计信息收集时,可能出现sql2310N使应用程序不能生成统计信息,返回-930错误,原因是STAT_HEAP_SZ空间不够,建议设置为类似AUTOMATIC(4384),另一种解决方法是采用抽样统计减少需要统计的数据量,抽样包括表抽样和索引抽样。。
在DB2 V8.2中,提供了对表数据进行抽样的两种新方法:行级的贝努里(Bernoulli)抽样和系统页级(system)的抽样,V10.1之后,也可以对索引抽样。
例子:收集10%的数据页上的表统计信息和10%的索引页上的索引统计信息,在10%的索引页的基础上进一步通过抽样计算详细的索引统计信息,通过抽样可以减少为获得详细索引统计信息而执行的后台计算量
db2 "runstats on table db2obits.wf_task and sampled detailed indexes all tablesample system(10) INDEXSAMPLE system(10)"
1.1.4、如何提高runstats的效率
统计信息堆(STAT_HEAP_SZ)的大小指定了使用RUNSTATS命令收集统计信息中所用内存堆的最大值。它是在启动RUNSTATS命令时分配的,然后当它完成时释放。分配更多内存,这样能确保RUNSTATS命令能够更快完成。比如:STAT_HEAP_SZ设置值AUTOMATIC(4384)
仅对用来连接表的列或WHERE、GROUP BY以及查询的类似子句中的列收集统计信息。如果对这些列建立了索引,那么可以用RUNSTATS命令的ON KEY COLUMNS子句指定列。类似:runstats on table db2ibits.test on key columns and columns(addr) with distribution on key columns and sampled detailed indexes all
使用SAMPLED DETAILED子句通过抽样计算详细的索引统计信息,这样就可以减少为获得详细索引统计信息而执行的后台计算量,使用了SAMPLED DETAILED子句可以减少收集统计信息所需要的时间,并在大多数情况下产生足够的精度。
采用表抽样和索引抽样
1.1.5、runstats用法
假如有如下表:
create table db2ibits.test(id int not null,name varchar(10));
create index test_i1 on test(id) allow reverse scans;
create index test_i2 on test(name) cluster allow reverse scans;
alter table test add primary key(id);
insert into test values(1,'aa'),(2,'bb');
使用runstats对如上表收集统计信息,常用的使用方法如下:
1)、为表和索引收集统计信息,包括数据分布
runstats on table db2ibits.test on all columns with distribution and detailed indexes all
2)、收集部分索引统计信息(如果表上没有统计信息,会同时对表做统计)
runstats on table db2ibits.test for indexes test_i1,test_i2
3)、收集所有索引统计信息(如果表上没有统计信息,会同时对表做统计)
runstats on table db2ibits.test for indexes all
4)、使用贝努利算法抽样统计
db2 "runstats on table db2ibits.test and sampled detailed indexes all tablesample bernoulli(10) INDEXSAMPLE bernoulli(10)"
1.1.6、runstats事项补充
1)、当运行Runstats时,如果出现表和索引统计信息不一致,将会导致Runstats报警而影响优化器路径选择。出现该种情况时,需要同时收集表和索引统计信息。
db2 "runstats on table db2ibits.test"
SQL2314W Some statistics are in an inconsistent state. The newly collected
"TABLE" statistics are inconsistent with the existing "INDEX" statistics.
SQLSTATE=01650
db2 "runstats on table db2ibits.test and indexes all"
DB20000I The RUNSTATS command completed successfully.
2)、Runstats统计结果存在系统表中,如SYSSTAT.TABLES保存了表的统计信息,SYSSTAT.INDEXES保存了索引统计信息,可以查看这些统计信息。
3)、索引详细统计信息
indexes all:收集CLUSTERRATIO的信息,CLUSTERFACTOR和PAGE_FETCH_PAIRS是空的。
detailed indexes all:收集CLUSTERFACTOR和PAGE_FETCH_PAIRS 这两列的信息,CLUSTERRATIO是空的。
计算索引的集群度,如果集群的很好就可能采用这个索引进行索引扫描。如果集群度不好,则可能直接走表扫描。
4)、包含频率和分位数统计信息的RUNSTATS
频率统计信息的默认值由num_freqvalues数据库配置参数控制,提供了重复最多的列和数据值的信息。默认值是10,建议这个值设置在10到100之间。
分位数统计信息的默认值由num_quantiles数据库配置参数控制,该值提供了数据值对于其他值而言是如何分布的有关信息。指定应将列数据值分成的组数,默认值是20,建议该值设置在20到50之间。
对于这些分布统计信息,只考虑对拥有选择谓词的最重要的查询而言最为重要的列。
当出现下列任何一种条件时,RUNSTATS将不收集分布统计信息:
当将num_freqvalues配置参数设置为0,以及将num_quantiles数据库配置参数设置为0或1时
当每个数据都是唯一的时候
当该列是LONG、LOB、或结构化列时
如果列中只有一个非空值
下面例子说明了用法:
收集表上的数据库统计信息,包含列deptno和deptname上的分布统计信息。单独为deptname列设置分布统计信息的范围,而deptno列使用公共的默认值。并且还为两个索引IDX1和IDX2收集数据库库统计信息
runstats on table db2admin.department with distribution on columns (deptno,deptname num_freqvalues 50 num_quantiles 100) default num_freqvalues 5 num_quantiles 10 and indexes db2admin.IDX1,db2admin.IDX2
对于deptname列,num_freqvalues是50,num_quantiles是100.
对于deptno列,num_freqvalues是5,num_quantiles是10.
5)、包含列组统计信息的RUNSTATS
列组(Column Group)
基数(cardinality)
runstats on table db2admin.department on columns((deptno,deptname),deptname,mrgno,(admrdept,loation))
本例中,总共有两个列组:(deptno,deptname)和(admrdept,location)。
6)、包含like statistics的runstats
当在runstats中指定like statistics子句时,将收集附加的列统计信息。这些统计信息存储在sysibm.syscolumns表里的sub_count和sub_delim_length列中。它们仅针对字符串列进行收集,查询优化器用它们来提高“column like ‘%abc’和”“column like ‘%abc%’”类型谓词的选择性估计。
下列例子说明了如何使用RUNSTATS收集包含LIKE统计信息的数据库统计信息
RUNSTATS ON TABLE db2admin.department on all columns and columns(deptname like statistics)
7)、包含统计信息配置文件的RUNSTATS
统计信息配置文件是指一组选项,它预先定义了特定表上将要收集的统计信息。
当将命令“set profile”添加到RUNSTATS命令时,将在表描述符和系统目录中注册或存储统计信息配置文件。若要更新,则使用”UPDATE PROFILE”。DB2中没有删除配置文件的选项。
参考下列例子:
只注册一个统计信息配置文件,不收集数据库统计信息
runstats on table db2ibits.department and indexes all set profile only
runstats中的子句set profile only不收集统计信息
根据前面已注册的统计信息配置文件来查询RUNSTATS选项
select statistics_profile from sysibm.systables where name='DEPARTMENT' AND CREATOR='DB2IBITS'
查询结果为:RUNSTATS ON TABLE "DB2IBITS"."DEPARTMENT" ON ALL COLUMNS AND INDEXES ALL
使用前面已注册的统计信息配置文件收集数据库统计信息
RUNSTATS ON TABLE db2ibits.department use profile
8)、调整RUNSTATS,以便最大程度地减少它对系统资源的需求。
调整选项将根据当前的数据库活动级别,来限制RUNSTATS命令所占有的资源数量。DB2中,在调整时,UTIL_IMPACT_LIM与UTIL_IMPACT_PRIORITY参数的配合使用确定了RUNSTATS命令的行为。UTIL_IMPACT_PRIORITY关键字被用于RUNSTATS命令的子句中,而UTIL_IMPACT_LIM则是一个实例配置参数。
UTIL_IMPACT_LIM参数是指允许所有运行的实用程序对于实例的工作负载产生影响的百分比。如果UTIL_IMPACT_LIM是100(默认值),则不用调整诸如RUNSTATS之类的运行程序所消耗的资源。例如,如果将UTIL_IMPACT_LIM设置为10,那么正在运行的RUNSTATS命令就被限定消耗10%以下的工作负载。UTIL_IMPACT_PRIORITY关键字可充当一个开关,它指定RUNSTATS命令是否使用这种调整策略。
例:runstats on table db2ibits.test on key columns and columns(addr) and sampled detailed indexes all UTIL_IMPACT_PRIORITY 10
其中,10是调整RUNSTATS的优先权,值越高,优先权越高,最高为100。
当UTIL_IMPACT_LIM不是100,而且用UTIL_IMPACT_PRIORITY调用RUNSTATS时,将会对该值进行调整。如果没有为UTIL_IMPACT_PRIORITY指定优先权,且UTIL_IMPACT_LIM不是100,那么RUNSTATS将使用默认的优先权50,并将据此进行调整。如果在RUNSTATS命令中省略了UTIL_IMPACT_PRIORITY关键字,那么不会对正在运行的RUNSTATS命令做资源调整。如果指定了优先权,但是将UTIL_IMPACT_LIMIT设置为100,那么也不会对正在运行的RUNSTATS命令做资源调整。将UTIL_IMPACT_PRIORITY设置为0,也不会对正在运行的RUNSTATS命令做调整。
当定义了RUNSTATS调整(Throttling),并且该调整可操作时,RUNSTATS命令通常会花费更长时间,但是对系统产生的影响会相对少一些。
SET UTIL_IMPACT_PRIORITY 1 TO 20
执行这个命令之后,runstats操作和同时执行的其他节流实用程序的累积影响会低于为配置参数util_impact_lim指定的百分比值;值20定义runstats操作相对于其他节流实用程序的节流重要性。
可使用LIST UTILITIES SHOW DETAIL查看UtilityID,表示正在运行的实用程序的ID。
9)、收集统计信息的其他方法
在表的LOAD REPLACE期间以及索引的创建期间,也可以进行数据库统计信息的收集。
在执行LOAD之前,就必须创建统计信息配置文件,例如:
runstats on table db2ibits.department and indexes all set profile only
LOAD FROM inputfile.del of del replace into db2ibits.department statistics use profile。
如果只是简单的用statistics yes,那么在收集信息发生在装载阶段,并且很容易出现统计信息不准,而索引信息在任何阶段都是不会收集的。
在执行索引创建操作时,也能收集索引的统计信息。这将避免为了收集统计信息而进行的另一次索引扫描。
例如:收集扩展的索引数据库统计信息,指定使用抽样。
create index db2admin.inx3 on db2admin.department(deptname) collect sampled detailed statistics
10)、昵称统计信息收集
db2 "call sysproc.nnstat('HIS','BDPOUSER','CAP_BTP_HIS',NULL,NULL,0,'/tmp/1.txt',?)"
参数分别为:SERVER、SCHEMA、NICKNAME、COLNAMES、INDEXNAMES、METHOD、LOG_FILE_PATH、OUT_TRACE
其中/tmp/1.txt是日志信息
如果要收集HIS下的所有昵称信息,命令为:
db2 "call sysproc.nnstat('HIS','','',NULL,NULL,0,'/tmp/1.txt',?)"。
如果源表表结构发生了变化,或者新增加了索引等,就最好进行一次runstats,然后重建昵称,这样才能把表结构信息和索引信息及统计信息反映在联邦表。
如果是根据视图创建昵称表,昵称的统计信息可能稍有不同(能不能收集到统计信息),但为了保险起见,建议还是先收集源表的统计信息,再创建昵称。
常规的昵称表收集统计信息的顺序为:先执行源表的runstats,再执行sysproc.nnstat把源表的统计信息同步过来。
例如:收集HIS下的所有昵称信息:
db2 "call sysproc.nnstat('HIS','','',NULL,NULL,0,'/tmp/1.txt',?)"。
参数分别为:SERVER、SCHEMA、NICKNAME、COLNAMES、INDEXNAMES、METHOD、LOG_FILE_PATH、OUT_TRACE
其中/tmp/1.txt是日志信息
如果要重建昵称,登录的时候最好把用户和密码带上,例如:
db2 connect to bdpo user bdpouser using bdpouser
1.2、 reorg
1.2.1、离线reorg
最多可包含4个阶段:
Scan-sort:根据reorg指定的索引对表数据进行扫描、排序
Build:根据第一阶段的结果进行表数据构建
Replace(copy):用新数据替换原有数据
Index rebuild:基于新数据,重建索引
使用reorg table test index test_i1将经历如上4个阶段
使用reorg table test将经历Build、Replace、Index rebuild3个阶段。
对于离线reorg,可以根据index index-name选项指定根据哪个索引进行表重组,DB2会按该索引的顺序重新组织表数据的物理存储。如果没有指定索引,表数据重组时不关心顺序。如果该表定义了聚集索引,如果reorg没有指定索引,默认也会按聚集索引顺序重组表,如果指定了索引,就会按该索引的顺序重组表。当离线表重组结束后,会重建表上的所有索引。
离线reorg,默认是allow read access,支持allow no access,在index rebuild阶段对表加Z锁,其他事务不能读写该表,在index rebuild阶段之前,其他事务可以使用索引读该表。表扫描、索引重建
表扫描,消耗IO;索引重建,消耗IO,消耗CPU排序。索引越多,reorg越慢。
离线reorg用法:
1)、重组表test
reorg table test
2)、在临时表空间里进行重组
reorg table test use tempspace1
3)、按索引重组表,在临时表空间里进行重组
reorg table test index test_i1 use tempspace1
4)、分区表,不支持在线reorg,对某个分区进行reorg
reorg table db2ohqbb.interest_cfm_his allow read access on data partition PART3,已经重建了索引,可以不用对索引进行reorg
5)、分区表,对某个分区索引进行reorg
reorg indexes all for table db2ohqbb.interest_cfm_his allow write access on data partition PART3
1.2.2、在线reorg
DB2 V8后支持在线REORG,与离线reorg相比,在线reorg对资源的占用很少,对应用的影响也很小,可以保证在重组过程中,其他应用对数据的不间断访问。在线表重组并不会创建数据副本,而是在原空间中进行,表数据的重组是分批次的,每批次只处理一部分数据,因此速度比离线reorg要慢很多。
在线reorg可随时启动和终止,为了保证可恢复性,在线reorg会记录大量的日志,需要的日志空间依赖于要移动的行数、表上索引的个数和索引键大小,因此可能是表大小的几倍。
在线reorg默认allow write access,支持allow read access。
在在线表重组操作期间,将按顺序重组表的各个部分。不会将数据复制到临时表空间;而是,在现有表对象中移动行以重新建立集群、回收可用空间并消除溢出行。
在线表重组操作分为 4 个主要阶段:
1)、选择n页
在此阶段,数据库管理器将选择由n页组成的范围,其中n是至少包含 32 个要进行重组处理的顺序页的扩展数据块(每个块默认包含32个数据页)的大小。
2)、腾出范围
REORG 实用程序将此范围内的所有行移至表中的可用页。每个被移动的行都保留一条重组表指针(RP)记录,该记录包含该行的新位置的记录标识 (RID)。将行作为包含数据的重组表溢出(RO)记录被放入到表的可用页。此实用程序移动一组行完成后,它将等待所有访问该表中数据的应用程序完成。这些“旧扫描者”在访问表数据时,将使用旧 RID。在等待阶段开始的任何表访问(“新扫描者”)都将使用新 RID 来访问数据。在所有旧扫描者都完成后,REORG 实用程序将清除已移动的行、删除 RP 记录并将 RO 记录转换为常规记录。
3)、填充范围
腾出特定范围内的所有行之后,将采用已重组的格式、根据先前使用的任何索引进行排序后的顺序并遵循先前定义的任何预取限制写回这些行。重写该范围内的所有页之后,将选择该表中的后续n个顺序页并重复以上过程。
4)、截断表
缺省情况下,重组表中的所有页后,缺省情况下将截断表以回收空间。如果指定了 NOTRUNCATE 选项,那么不会截断已重组的表。
在线reorg用法:
1)、执行在线reorg
db2 "reorg table db2ibits.test inplace allow write access"
2)、手动停止reorg的执行
db2 "reorg table db2ibits.test inplace pause"
3)、激活在线reorg,reorg完不回收表空间
db2 "reorg table db2ibits.test inplace resume notruncate table"
在线reorg是在后台异步执行的,因此即使我们看到命令成功返回,实际上仍然在后台执行,如果要重组的表很多,通常的做法是写成脚本,控制多个表的在线reorg执行顺序:每个在线reorg执行时,都有一个对应的db2reorg应用程序,通过db2 list applications show detail|grep –I db2reorg判断,如果有reorg正在执行,则等待该reorg执行完毕,否则执行脚本里的下一个表重组。脚本类似于:
db2 connect to bitsdb
db2 "reorg table db2obits.wf_task inplace"
inum=`db2 list applications|grep -i db2reorg|wc -l`
echo inum
if [ inum -eq 1 ]; then
echo "wait"
else
echo "execute next"
db2 "reorg table db2obits.lc_master inplace"
fi
1.2.3、Reorg索引
当离线重组结束后,会重建表上的所有索引。在线表重组仅仅维护索引,而不会重建索引(聚集索引除外),当在线重组结束后,最好进行索引单独重组,命令为:
db2 "reorg indexes all for table db2ibits.test"
索引重组默认为allow read access rebuild,建议用allow write access cleanup all reclaim extents,能达到类似的效果。
加锁情况(默认allow read access):
1)、对表加U锁,重新构建索引
db2 "reorg indexes all for table db2obits.wf_task rebuild"
2)、对表加U锁,回收所有逻辑删除的索引空间,增多free pages;并回收扩展块,可供其他索引对象使用。
db2 "reorg indexes all for table db2obits.wf_task cleanup all reclaim extents"
3)、对表加U锁,回收所有RID都被标记为已删除的页中的空间,增多free pages;并回收扩展块,可供其他索引对象使用。
db2 "reorg indexes all for table db2obits.wf_task cleanup pages reclaim extents"
NUMRIDS_DELETED:并非所有RID都标记为删除的叶子页,逻辑上已删除的RID总数存储在NUMRIDS_DELETED中。
NUM_EMPTY_LEAFS:每个RID都被标记为已删除的叶子页的数目。
使用带CLEANUP ALL选项的REORG INDEXES可以回收所有逻辑删除的索引空间;使用带CLEANUP PAGES选项的REORG INDEXES只可以回收所有RID都被标记为已删除的页中的空间。
例子:
reorg table CUST INPLACE allow write access; (后台异步执行)
reorg indexes all for table CUST allow write access cleanup all reclaim extents;(可对表进行读写,并回收所有逻辑删除的索引空间)
(默认是reorg indexes all for table CUST allow read access rebuild;即重建索引,但表只能读,不能写)
这两个索引重组的方式结果等价,但前者能对表进行读写,后者不能对表写,相当于离线reorg索引。
1.2.4、reorg监控
1)、表快照
db2 get snapshot for tables on sample
2)、db2pd
db2pd -d sample –reorg
3)、历史文件
db2 list history reorg all for sample
4)、sysibmadm.snaptab_reorg
SELECT
substr(tabname,1,15) as tab_name,
substr(tabschema,1,15) as tab_schema,
reorg_phase,
substr(reorg_type,1,20) as reorg_type,
reorg_status,
reorg_completion,
dbpartitionnum
FROM
sysibmadm.snaptab_reorg
ORDER BY
dbpartitionnum
1.3、 rebind
rebind工具会根据当前的统计信息为package里的SQL语句重新生成新的访问计划,对性能有比较好的提升。
rebind一般用于存储过程,每个存储过程对应一个package。
可以通过db2 list packages for all(或schema xx),列出相应的package名。
db2 rebind package P6045027
rebind命令只能针对每个package,如果需要对所有package重新绑定,可以考虑用db2rbind命令:
db2rbind sample -l db2rbind.log all
1.4、 数据库大小
V9开始,提供了SYSSPROC.GET_DBSIZE_INFO存储过程来计算当前数据库大小和最大容量大小:
db2 "call GET_DBSIZE_INFO(?,?,?,0)"
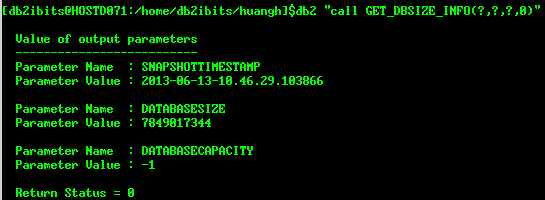
前三个参数为输出参数,第4个参数为输入参数,表示在该时间后进行数据库大小和容量大小的刷新,单位为分钟,默认值为30分钟,如果为0,则会马上进行刷新。如果需要统计每天数据大小的增长情况,可考虑将此窗口设为24小时,即24*60=1440分钟。
DATABASESIZE:返回数据库大小(单位为bytes),大小的计算如下:dbsize=sum(used_pages*page_size)每个表空间(SMS和DMS)的已使用页数乘以页大小。
1.5、 表空间大小
在V9.1,提供了sysibmadm.tbsp_utilization,如下:
select tbsp_name,tbsp_used_size_kb, tbsp_utilization_percent from sysibmadm.tbsp_utilization where tbsp_name in ('COMP_LOB_DMS_8K','COMP_DATA_DMS_8K','COMP_INDEX_DMS_8K')
SMS的表空间因为每个对象占用一个文件,所以只有通过计算容器中文件的总大小。
1.6、 表大小
查看表大小:
方法一:
通过db2pd –d bitsdb –tcbstats,可以查看表大小、LOB大小、XML大小,不能查看索引大小。
方法二:
db2 "reorgchk update statistics on table db2obits.accounting_detail_sub"
只能通过NPAGES查看表大小,不能查看索引大小、LOB大小。
方法三:
select tabname,npages from syscat.tables where tabname not like 'SYS%'
如果没有捕捉到某个表的统计信息,那么npages上的值就是-1
方法四:
查看某个表/索引/大字段/长字段占用空间的大小
如下是查找组件表大字段最大的表,按照大字段大小从高到低排序(思路:先从syscat.columns找出含有大字段的表;然后从syscat.tables中查找放在表空间COMP_LOB_DMS_8K的表,最后从管理视图sysibmadm.ADMINTABINFO中查找表/索引/大字段/长字段占用空间的大小),以KB为计量单位。因为管理视图是DB2 9引入的,所以此种方式只适合DB2 9,对DB2 8采用表函数Admin_get_tab_info:
SELECT TABNAME,DATA_OBJECT_P_SIZE,LOB_OBJECT_P_SIZE,INDEX_OBJECT_P_SIZE,LONG_OBJECT_P_SIZE,XML_OBJECT_P_SIZE FROM SYSIBMADM.ADMINTABINFO WHERE TABNAME IN (select TABNAME from SYSCAT.TABLES WHERE TBSPACE='COMP_DATA_DMS_8K' AND TABNAME IN (SELECT TABNAME FROM SYSCAT.COLUMNS WHERE TYPENAME LIKE '%LOB%' AND TABSCHEMA='DB2OBITS')) ORDER BY LOB_OBJECT_P_SIZE DESC
下面是具体例子:
--获取组件表大对象大小排前10的表
SELECT TABNAME,DATA_OBJECT_P_SIZE,LOB_OBJECT_P_SIZE,INDEX_OBJECT_P_SIZE,LONG_OBJECT_P_SIZE,XML_OBJECT_P_SIZE FROM SYSIBMADM.ADMINTABINFO WHERE TABNAME IN (select TABNAME from SYSCAT.TABLES WHERE TBSPACE='COMP_DATA_DMS_8K' AND TABNAME IN (SELECT TABNAME FROM SYSCAT.COLUMNS WHERE TYPENAME LIKE '%LOB%' AND TABSCHEMA='DB2OBITS')) ORDER BY LOB_OBJECT_P_SIZE DESC fetch first 10 rows only
--查看组件表数据总大小、大对象总大小、索引总大小
SELECT sum(DATA_OBJECT_P_SIZE),sum(LOB_OBJECT_P_SIZE),sum(INDEX_OBJECT_P_SIZE),sum(LONG_OBJECT_P_SIZE),sum(XML_OBJECT_P_SIZE) FROM SYSIBMADM.ADMINTABINFO WHERE TABNAME IN (select TABNAME from SYSCAT.TABLES WHERE TBSPACE='COMP_DATA_DMS_8K' AND TABNAME IN (SELECT TABNAME FROM SYSCAT.COLUMNS WHERE TYPENAME LIKE '%LOB%' AND TABSCHEMA='DB2OBITS'))
方法五:DB2 V8提供的表函数,与方法四效果一致
select t.* from table(SNAP_GET_TAB('BOCOMPL',-1)) t
(这个是V9的:select t.* from table(Admin_get_tab_info('BITSDB',-1)) t)
总结:方法四最好用
2数据库备份
2.1、备份
参考附件《DB2数据库备份与恢复策略》
2.2、恢复
参考附件《DB2数据库备份与恢复策略》
附件共享链接详见末尾
3数据迁移
3.1、数据迁移概述
数据迁移是DBA 重要的工作内容之一。广义的数据迁移,既包括平台间数据库迁移,也包括同一数据库不同表间的数据迁移,还包括数据表与文件之间的数据导入/导出。针对不同的场景,DBA 要在众多的方案中选择最优的解决方案:
同构平台间的数据迁移,如从生产库系统到测试库,最简单的迁移方法是通过对生产库做备份,然后在测试机上进行数据库恢复。
异构平台间的数据迁移,如从HP到AIX的数据迁移,这种场景不能采用数据库备份恢复,只能先用db2look 导出表结构,并将表数据导出来,然后用导入到目标库。
灾难或故障情况下的数据挽回,DB2 提供了db2dart 工具,可以在实例都无法启动的情况下将数据导出。该工具一般用于没有进行数据库备份,但发生了日志故障或其他操作故障,而没有其他机制挽回数据的场景。
本节主要介绍表与文件间的数据导入/导出、表间数据迁移。
在日常工作中,经常有数据的导入/导出需求,比如将某些表的数据保存成报表形式,或将文件数据加载到数据库等。为此,DB2 提供了很多工具供大家选择,如export、import、load、db2look、db2move 和db2dart。图3.1 直观地展现了这几个工具的使用,最上面虚线框部分是工具支持的导入/导出文件格式,中间虚线框是DB2 提供的导入/导出工具,最下面是DB2 数据表。
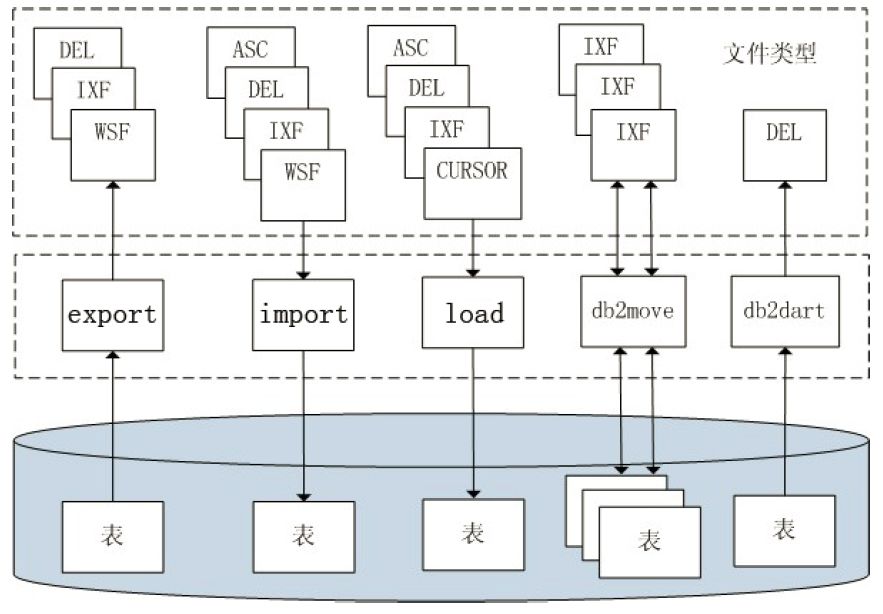
3.2、文件格式
首先我们介绍DB2 支持的文件格式:DEL、ASC、PC/IXF 和WSF 格式,其中DEL 和ASC格式是文本格式,PC/IXF 格式是IBM 特有的二进制格式,WSF 格式主要用于和Lotus 1-2-3 进行数据导入/导出,新版本中将不再支持。
3.2.1、DEL格式
定界ASCII 格式(DEL)是DB2 用于数据交换的最常用格式。这种格式包含ASCII 数据,使用字符分隔符分隔列值,分隔符用来标识数据元素的起始和结束,最主要的分隔符有
以下几种。
字符分隔符:界定字符字段的起始。在默认情况下,用双引号(“”)作为字符分隔符。
列分隔符:界定列的结束。默认用逗号(,)作为列分隔符。
行分隔符:用来标识一行或一个记录的结束。默认用换行符作为分隔符。
以下是DEL 格式的例子:
330,"Burke",66,"Clerk",1,+49988.00,+00055.50
340,"Edwards",84,"Sales",7,+67844.00,+01285.00
3.2.2、ASC格式
定长ASCII(ASC)格式,顾名思义,这种文件类型包含定长ASCII 数据,每个数据长度与列定义相同,不足的用空格补齐,行与行之间通过换行符分隔,例子如下:
330 Burke 66 Clerk1 +49988.00 +00055.50
340 Edwards 84 Sales7 +67844.00 +01285.00
3.2.3、PC/IXF
PC/IXF(IXF)是IBM特定的二进制格式,适用于在异构平台间进行数据迁移,IXF的优点是数据占用空间小,而且包含表结构的定义,可以通过IXF文件重建表。
3.2.4、Cursor
游标(Cursor)是非常重要的一个概念,它提供了一种对从表中检索出的数据进行操作的灵活手段。可以把游标想象为一个指针,刚开始指向结果集中的第一条数据,当第一条数据读
取完成后,游标会自动跳转到下一条数据。
如果在两张表之间进行数据迁移,最容易想到的方法是先将数据从一张表导出来,存到一个文件中,然后将这个文件的数据导入到另外一张表。而采用游标,数据不需落地,效率比较
高,因此比较适于表间数据迁移。只有LOAD 支持游标,其余几种工具不支持。
下面是使用Cursor 进行表间迁移的例子:
DECLARE mycursor CURSOR FOR SELECT col1, col2, col3 FROM tab1;
LOAD FROM mycursor OF CURSOR INSERT INTO newtab;
3.3、export
export用于将表里的数据导出到文件中,
export例子:
db2 "export to ./test.del of del modified by lobsinfile coldel0x0f codepage=1208 implicitlyhiddeninclude select * from test"
3.4、import
Import用来将文件里的数据导入到表中,<Action> INTO table-name用来指定导入数据的几种方式,目前支持insert、insert_update、replace。
执行import时,最好指定commitcount,避免事务日志满和锁升级,默认情况下,DB2会自动使用automatic选项。
在默认情况下,import 会在目标表加X 锁,不允许其他应用访问(allow no access)。如果import 允许其他应用读和写,可指定allow write access 选项,这时import 会在目标表上加IX 锁,但该选项只能用于insert 或insert_update 操作。
Import例子:
db2 "import from ./test.del of del modified by lobsinfile coldel0x0f codepage=1208 implicitlyhiddeninclude delprioritychar commitcount 10000 insert_update into test"
3.5、load
LOAD分四个阶段
装载阶段(load)
装载阶段将源文件解析成数据物理存储的格式,直接装入到页中。在装入过程中,会收集索引键(如果对一个表定义了多个索引,那么因为装入操作会将所有键保存在内存中,所以内存消耗将按比例地增加,消耗内存为UTIL_HEAP_SZ),如果指定了statistics yes,那么在该阶段也会收集表统计信息(需要指定statistics yes,默认为statistics no。statistics yes只对load replace有效,不支持load insert。即使指定了statistics yes也只收集表统计信息而不收集索引统计信息。如果第三阶段删除了许多重复值记录,表统计信息也会严重不准,比如load了20条记录,但因为主键冲突在第三阶段删除了18条记录,因为表统计信息是在装载阶段收集的,所以表统计信息仍显示为20条记录。虽然不能收集索引统计信息,但即使发生了索引重建,之前索引统计信息并不会被删除,索引统计信息在LOAD整个过程中不发生任何变化。因此建议,LOAD后应该对表和索引都收集统计信息,否则,会有较大程度的统计信息不准),并记录一致点。当数据不符合表定义时,这些数据就被当做无效数据,无效数据是不会装载到表中的,但可以放在转储文件(dump file)中,可以使用modified by dumpfile修饰符来指定转储文件名和路径。
构建索引阶段(build)
如果加载的表上有索引的话,构建阶段基于装载阶段收集到的键创建索引。如果使用了allow read access use tablespace选项(只支持indexing mode rebuild),索引将创建在系统临时表空间中,在索引复制阶段会将索引从系统临时表空间中复制到索引表空间中。优点是在系统临时表空间中构建新索引以避免用完原始表空间中的空间。
删除重复值阶段(delete)
如果表上有主键或唯一性索引,此阶段将删除违反唯一键的行。此阶段只检查违背了唯一性约束的行,而不会检查check约束和参考完整性约束。可以创建一个异常表(exception table)来存储被删除的行,这样在LOAD结束后可以查看异常表,并决定如何处理它们。如果没有指定异常表,那么重复行将被删除。
索引复制阶段(index copy)
如果load指定了allow read access use tablespace选项,那么此阶段会将索引数据从系统临时表空间中复制到索引表空间中。
3.5.1、Load并发性
Load操作对业务的影响
1)、默认使用allow no access
2)、也可使用allow read access,在load的时候,允许其他应用访问load之前的原有数据。
3)、load replace不支持allow read access
3.5.2、Load的copy选项
循环日志:LOAD操作默认NONRECOVERABLE。
归档日志:LOAD操作默认COPY NO,LOAD完后该表所在表空间是backup pending。
不管归档日志还是循环日志,当LOAD的时候,建议用 NONRECOVERABLE 选项将装入事务标记为不可恢复,优点是表空间不会处于backup pending。缺点是以后不可能通过前滚操作恢复该事务。建议在LOAD后,对表空间或者数据库进行备份,方便对表进行误操作的时候能够从备份中恢复该表。
Copy yes to path选项会在load结束时,对表所属的表空间做一次备份,load结束后,表所在的表空间不会处于backup pending状态,而为正常状态,但由于要备份,所需时间要长些。在前滚恢复阶段,DB2会使用这个备份文件恢复load过程中加载的数据。
3.5.3、Load表状态
表状态 | 出现原因 | 解决方法 |
Set integrity pending | Check约束等待检查 | 执行set integrity for tabname immediate checked |
Load in progress | 正在数据加载过程中 | |
Load pending | 数据提交前出现了故障,如表空间没有足够的空间等 | Load terminate、load restart解除挂起状态 |
unavailable | 使用了nonrecoverable,之后表从backup中恢复并前滚 |
3.5.4、如何提高load性能
1)、调整 sortheap 数据库配置参数,用于对索引键进行排序。
2)、indexing mode INCREMENTAL的方式构建索引
3)、indexing mode rebuild use TEMPSPACE1的方式构建索引
4)、 indexing mode DEFERRED,延迟创建索引
5)、删除唯一性索引之外的其他索引,load完数据之后再用create index命令重建这些索引,因为CREATE INDEX语句可以使用多个线程来对键进行排序。实际构建索引时并不是并行执行的
3.5.5、LOAD使用范例
1)、使用异常表
db2 "create table t1(empno int not null primary key,name char(10),seqno int not null)"
db2 "create table t1_exp like t1"
db2 "alter table t1_exp add column ts timestamp add column msg clob(32k)"
db2 "export to ./t1.del of del select * from t1"
db2 "load from t1.del of del modified by dumpfile=/home/db2ibits/huangh/t1.dmp messages t1.msg insert into t1 for exception t1_exp"
有主键冲突的会被删除,只检查违背了唯一性约束的行,而不会检查check约束和参考完整性约束,插入到t1_exp中
违背表定义会被拒绝,转储到文件t1.dmp中
2)、在客户端load数据
如果要加载的数据在客户端,可通过Load client from 语句加载数据。
db2 connect to bitscn user db2ibits using db2ibits
db2 "load client from home/bitsadm/bits_batch/batchdata/test.del of del insert into db2obits.test nonrecoverable"
3)、load各个阶段耗时可通过db2diag.log查看
db2 "load from SWIFT_INPUT_MSG.del of del modified by lobsinfile implicitlyhiddeninclude coldel0x0f dumpfile=/home/db2obits/huangh/swift/SWIFT_INPUT_MSG.dmp messages SWIFT_INPUT_MSG.msg insert into SWIFT_INPUT_MSG for exception SWIFT_INPUT_MSG_EXP NONRECOVERABLE ALLOW READ ACCESS USE TEMPSPACE8K"
在db2diag.log中看到的LOAD执行过程如下:
Starting LOAD operation (S) (1) (I) [DB2OBITS.SWIFT_INPUT_MSG].
Starting LOAD phase at 11/20/2014 15:42:07.572625. Table DB2OBITS.SWIFT_INPUT_MSG
Completed LOAD phase at 11/20/2014 15:47:47.780264.
Starting BUILD phase at 11/20/2014 15:47:47.791569.
Completed BUILD phase at 11/20/2014 15:47:53.437142.
Starting DELETE phase at 11/20/2014 15:47:55.481011.
Completed DELETE phase at 11/20/2014 15:47:55.495988.
Starting INDEX COPY phase at 11/20/2014 15:47:56.118805.
Completed INDEX COPY phase at 11/20/2014 15:47:56.549401.
Completed LOAD operation.
4)、通过JDBC执行LOAD
conn = DBFactory.getConnection(Constants.DB_HW_SIT);
Statement stmm = conn.createStatement();
// t2.del必须已经位于AIX服务器的/home/db2obits/路径下
String sSQL ="call sysproc.admin_cmd('load from home/db2obits/t2.del of del replace into t2 nonrecoverable')";
stmm.execute(sSQL);
5)、通过在服务器上创建新的进程来执行LOAD
List<String> commandList = new ArrayList<String>();
commandList.add("/home/db2obits/loadTest.sh");
ProcessBuilder pb = new ProcessBuilder(commandList);
pb.command(commandList);
Process process = pb.start();
int exitStatus = process.waitFor();
// exitStatus返回非0数字表示执行出现异常
System.out.println(exitStatus);
然后封装一个sh执行该JAVA程序
/home/db2obits/jre/bin/java -Dlogback.configurationFile=./bin/logback_bits.xml -Dfile.encoding=GBK -Duser.language=Zh -Djava.ext.dirs=./lib -cp ./bin db.LoadTest
6)、游标load
db2 "declare c1 cursor database sacvsdb user acvsuser using acvsuser for select * from acvsuser.ACVS_EV_REPORT_B where EVAL_DATE <='2015-12-31'"
db2 "load from c1 of cursor insert into acvsuser.ACVS_EV_REPORT_B for exception acvsuser.ACVS_EV_REPORT_B_EXP_INCREMENT nonrecoverable"
3.5.6、Load事项补充
1)、可在 LOAD 命令中指定四种建立索引方式
1.REBUILD。将重建所有索引。
2.INCREMENTAL。以增量方式维护索引。
3.AUTOSELECT。装入实用程序自动决定是使用 REBUILD 还是 INCREMENTAL 方式。AUTOSELECT 是缺省值。如果正在执行 LOAD REPLACE 操作,那么将使用 REBUILD 索引建立方式。否则,根据表中的现有数据量与新近装入的数据量的比率来选择建立索引方式。如果比率非常大,那么选择 INCREMENTAL 建立索引方式。否则,选择 REBUILD 建立索引方式。
4.DEFERRED。如果指定此方式,那么装入实用程序不会尝试创建索引。索引将标记为需要刷新(无效),并且可能会在第一次访问索引时强制重建。在下列任何一种情况下,不允许使用 DEFERRED 选项:
指定了 ALLOW READ ACCESS 选项(它不会维护索引并且索引扫描程序需要有效索引)
针对表定义了任何唯一索引
正在装入 XML 数据(XML 路径索引是唯一的,并且缺省情况下,只要在表中添加 XML 列,就会创建该索引)
2)、LOAD构建阶段,新索引将在原始索引所在的表空间或系统临时表空间中构建影子索引
缺省情况下(ALLOW NO ACCESS),将在原始索引所在的表空间中构建影子索引,因为原始索引和新索引都同时保留下来,所以必须有足够的表空间才能同时容纳两个索引。如果装入操作中止,那么将释放用于构建新索引的其他空间。如果装入操作落实,那么将释放用于原始索引的空间,并且新索引成为当前索引。在原始索引所在的表空间中构建新索引时,几乎会同时替换原始索引。
在使用 INDEXING MODE REBUILD(或AUTOSELECT) 和 ALLOW READ ACCESS 选项时,USE tablespace-name 选项允许在系统临时表空间中重建索引。系统临时表空间的页大小必须与原始索引表空间的页大小相匹配。如果指定了 INDEXING MODE INCREMENTAL,那么会忽略 USE tablespace-name 选项。在装入操作的构建阶段,将在系统临时表空间中构建索引。在索引复制阶段,将索引从系统临时表空间复制至原始表空间。索引复制阶段在构建和删除阶段之后进行。在索引复制阶段开始之前,表以独占方式锁定。即,在整个索引复制阶段它不能用于读访问。因为索引复制阶段是物理复制,所以该表可能有很长一段时间不可用。
3)、延迟创建索引
通常,通过指定 REBUILD 或 INCREMENTAL 方式允许在装入操作期间创建索引比延迟创建索引的效率要高。
在某些情况下,延迟创建索引并调用 CREATE INDEX 语句可以提高性能。在索引重建期间进行排序将使用多达 sortheap 页。如果需要更多空间,那么会使用 TEMP 缓冲池并(最终)溢出至磁盘。如果装入溢出,并因此而导致性能下降,那么可能最好是将 LOAD 与 INDEXING MODE DEFERRED 配合运行,然后再重新创建索引。CREATE INDEX 一次将创建一个索引,在多次扫描表来搜索键的同时还降低了内存使用量。
使用 CREATE INDEX 语句而不同时使用装入操作来构建索引的另一个优点是,CREATE INDEX 语句可以使用多个进程或线程来对键进行排序。实际构建索引时并不是并行执行的。
3.6、常见导入导出问题
1)、要加载的数据是Excel 格式怎么办
处理Excel数据,可将其另存为“CSV(逗号分隔)”格式,然后导入
2)、如何导入identity 数据
针对不同的需求,DB2 提供了两组修饰符
来解决。一组为identity 修饰符,包含identityoverride,identityignore 和identitymissing 3 个,用于当表字段有generated always as identity 或generated by default as identity 自增列时数据加载处理方法;另外一组为generated 修饰符,包含generatedoverride、generatedignore 和generatedmissing3 个,用于当表字段有generated always as <expression>时数据加载处理方法。
注意:identityoverride 修饰符只适用于generated always,不支持generated by default。identityoverride 不能在import 命令中使用,只在load 中支持。
db2 "create table t6 (custno smallint not null generated always as identity (start with 500, increment by 1), custname varchar(16)) "
db2 "create table t10 (name varchar(16) not null, salary decimal(9,2), bonus decimal(9,2) generated always as (salary/10) )"
3)、乱码问题的解决
数据库为UTF-8编码
a) select的时候,只与会话选项的外观有联系,两者一致即可正常显示。
b) 如果想在SecureCRT等环境输入中文并执行类似的SQL语句:db2 “insert into test values(1,‘测试’)”。则必须在当前会话设置LANG=ZH_CN.UTF-8,会话选项的外观的字符编码为UTF-8。
c) 如果上传UTF-8无BOM格式的文件,则不管LANG和会话选项是何种编码,都能通过db2 -tvf test.sql成功地执行,不会出现乱码。
d) import的时候假定文件编码与注册表变量DB2CODEPAGE一致
e) load、export的时候假定文件编码与数据库codepage一致
f) 如果import、load使用默认的方式导入,文件编码与假定的不一致,那么就会出现乱码。解决方式为通过modified by codepage=xxxx,显示地将数据文件编码告诉import、load程序。确保DB2能正确地执行编码页转换。
4)、要导出/加载的数据不是逗号/双引号分隔怎么办
在默认情况下,对于DEL 格式,每行数据字段之间用逗号分隔,字符串数据用双引号分隔。
如果提供的数据不是这种格式,如字段间用分号“;”分隔,字符串用单引号“''”分隔,那么可用modified by 修饰符来指定,coldelx 用来指定字段间分隔符,chardelx 用来指定字符串分隔符,
代码如下:
db2inst1@dpf1:~> cat t1.del
10;'wang qi';1
20;'zhang san';2
db2inst1@dpf1:~> db2 "import from t1.del of del modified by coldel; chardel'' insert into t1"
注意:对于分隔符,有以下限制:
用户要确保数据中不能包含分隔符,如果存在,会出现各种异常。
分隔符不能是换行符、回车符、0x00 或空格。
在 DBCS 环境下(如中文系统),不能用“|”符号作为分隔符。
如果 DEL 文件通过某个特殊字符分隔,而import、load、export 命令中通过键盘无法
敲入时,可转换为十六进制表示,如0x7c 代表“|”。
对于 decimal 值,默认的导出格式是在前面有+号,如果位数不够定义的长度,则用0 补齐,
有些情况下,客户不希望保留+号,或者去掉前面的0,DB2 提供了两个修饰符选项,一个是decplusblank(del plus blank,即+换成空格),另一个是striplzeros(strip zero,去掉空格)。
对日期格式的支持也比较灵活,如客户指定了导出的时间格式,那么可以通过modified bytimestampformat 来指定。
如果客户要求导出的时间按照“年/月/日时:分:秒.毫秒”的格式,可在export 命令中指定(注意:YYYY 前面的“\”用于对“"”转义),类似:
modified by timestampformat=\"YYYY/MM/DD HH:MM:SS.UUUUUU\"
5)、要加载的数据有换行符怎么办
DB2 默认import/load 优先级策略为:行分隔符(record delimiter)、字符分隔符(character
delimiter)和列分隔符(column delimiter),行分隔符优先级最高。所以如果原始文件有换行的
话,load 就认为是新的记录,这时可用delprioritychar 修饰符改变默认的优先级别,确保""之间
的数据不管有没有换行符都被认为是同一条记录。
注意:用IXF 不会出现此问题。
3.7、db2look
在数据迁移前,需要在目标端建立数据对象定义。db2look能产生表、视图、索引、函数、Trigger、存储过程等对象定义语句,可通过db2look –h 查看帮助。
以下是db2look 常用的选项,-d 表示数据库名,-e 抽取数据库对象定义,-l 抽取表空间定义, -t 表示抽取的表名(注意:数据库默认创建的bufferpool、表空间和节点组不会抽取),代码如下:
db2look -d db_name -e -l -o db2look.ddl -- 抽取所有用户对象定义,包括表空间等
db2look -d -t t1 t2 -e -o db2look_tables.out -- 抽取某个或某些表定义信息, t1、t2 为表名
3.8、db2move
db2move 程序用来在两个数据库间数据迁移,特别适合于不同平台、表数量比较多的情况。
此程序是对export、import、load 命令的封装,根据系统表获得用户表,将数据导出为PC/IXF格式,同时会产生一个db2move.lst 文件,记录导出表和数据文件名字。然后将这些文件传送到目标系统中,通过load 或import 进行导入。
db2move 命令的语法如下:
db2move--dbname--action
Action 可以是export、import 和load 中的一种,db2move 执行时会自动进行数据库连接。
例如:
db2move sample export
db2move sample load
3.9、db2dart
由于事务日志被破坏,或磁盘故障导致数据库无法连接,而又没有数据库备份情况下,db2dart 可能是您的最后一根救命稻草了。
通过db2dart ddel 选项导出表数据,该选项需要用户提供表ID 或表名、表空间ID、起始页和页数。表ID 和表空间ID 可以通过syscat.tables 系统表查询,起始页可以
从0 开始,页数可以设为999999999。默认的输出目录是<inst_home>/sqllib/db2dump/DART0000,可以通过/rpt 来指定。默认的导出数据名是TS<tbspace_id>T<table_id>.DEL
db2dart sample ddel
Table object data formatting start.
Please enter
Table ID or name, tablespace ID, first page, num of pages:
4,8,0,999999999
强烈建议执行db2dart 的时候deactivate 数据库,否则可能会出现不一致
既然数据库都无法连接了,还怎么查询tableid 和tablespaceid 呢?要解决这个问题还得靠db2dart,不过这次使用/db 选项。
db2dart sample db rpt home/db2inst1/dart rptn chekdb_dart.out
db2dart db 选项会检查数据库的完整性,对库中的每张表进行检查,输出报告中会打印表名、表ID 和表空间ID。以下是一个结果片段,结果显示了表名DBA.SNAP_LOCKWAIT,以及表ID=29 和表空间ID=3:
Table inspection start: DBA.SNAP_LOCKWAIT
Data inspection phase start. Data obj: 29 In pool: 3
Data inspection phase end.
db2dart 不会抽取大对象数据,如果表中含有CLOB/BLOB 字段,并且是最后一个字段,且字段类型允许为空,那么db2dart 导出的数据是可以插入的,但CLOB/BLOB 值为NULL 值。如果不是最后一个字段,load 加载时就会出错,这时需要对db2dart 导出的DEL 格式数据进行处理,用NULL 或空格等补齐大对象所在的字段。
除非在没有别的办法的情况下,否则不建议用db2dart,因为:
如果缓冲池有数据没有写到磁盘,用db2dart 导出的数据可能是不完整、不准确的。
db2dart 抽取速度会比较慢,特别是表很多、数据量很大的情况下,需要的时间很长。
db2dart 会忽略大对象数据的抽取。
必须有表、索引、存储过程、函数等的定义,否则无法重建结构。
注意:只有当系统表(catalog tables)有效时,才能用db2dart;当系统表数据被破坏的情况下,除了使用restore 没有别的方法。这也从另外一个侧面说明了做好备份的重要性。
4约束检查
4.1、约束类型
非空约束:定义了非空约束的字段不能插入NULL值
唯一约束:字段不允许出现重复值,也不能出现空值
主键约束:要求同时满足非空和唯一的条件
外键约束:用于实现引用完整性约束。引用约束只能引用主键或唯一键。外键的值只能是它所引用的主键或惟一键中定义的值(或空值,外键可以为空),注意,外键并不是索引,创建了外键不会自动创建索引,一般建议在外键上创建索引。从表中对应的字段数据类型必须与主表中的相同,但字段名称并不要求相同。
检查约束:比如字段col1>10。
缺省值约束:用于指定某个字段的默认值,当插入数据的时候没有给出值,将使用这个默认值进行填充,它是一个列级别约束,语法为:字段名称 数据类型 DEFAULT <默认值>
注意:创建唯一约束和主键约束的时候都会创建索引,索引名为约束名,如果没有申明约束名,将会自动生成索引名,类似于SQL121217162213560。主键的索引或惟一键约束产生的索引不能被显示删除,如果要删除主索引或惟一约束索引,需要使用ALTER TABLE语句。使用DROP PRIMATY KEY选项删除主索引,使用DROP UNIQUE(约束名)选项删除惟一键索引。
如果既有主键,又想在该主键上创建一个include索引,就最好把主键产生的索引删除,方法如下:
CREATE UNIQUE INDEX "DB2OBITS"."IDX1602230744540"
ON "DB2OBITS"."LA_OTHER_EVENT" ("EVENT_NO" ASC) INCLUDE
("LA_REVOKE_CLS_OPTION") ALLOW REVERSE SCANS COLLECT SAMPLED DETAILED STATISTICS;
COMMIT WORK ;
alter table db2obits.LA_OTHER_EVENT drop primary key;
alter table db2obits.LA_OTHER_EVENT add primary key(event_no);
主键、唯一约束、唯一索引的区别
主键一个表只能创建一个
惟一约束一个表可以拥有多个
惟一索引,加上not null就是惟一约束
比如如下表
db2 "create table test(id int)"
db2 "create unique index test_I1 on test(id asc)"
手动创建唯一索引,不要求该列NOT NULL
DB2OBITS TEST_I1 DB2OBITS U DB2OBITS TEST +ID U REG 2012-11-15 11:08:47.549048 DB2OBITS
db2 "create table test(id int unique)"
这样会报错,因为unique,要求该列NOT NULL
db2 "create table test(id int not null unique)"
这样创建成功,同时系统创建了一个唯一索引
SYSIBM SQL121115110203680 DB2OBITS U DB2OBITS TEST +ID U REG 2012-11-15 11:02:03.667448 DB2OBITS
4.2、set integrity
Load的时候,在删除阶段,会删除违反唯一性约束的行,对于表中包含了违背参照完整性约束和检查约束的数据,load程序不会检查,而是将表置于set integrity pending状态,当访问时,会提示以下错误:
SQL0668N Operation not allowed for reason code "1" on table "<table-name>".SQLSTATE=57016
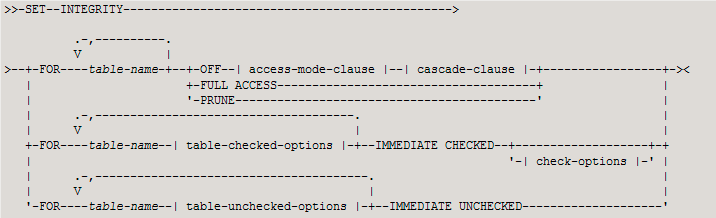
为解除这种状态,需要通过set integrity 命令检查数据完整性,该命令语法如下:
以下介绍几个重要选项的用法。
OFF:将检查关闭,同时将表处于set integrity pending 状态。
IMMEDIATE CHECKED:对表立即做完整性检查,并将状态从set integrity pending 状态中脱离出来。当将主表从set integrity pending 状态中脱离时,它的依赖表可能会处于此状态,可通过返回的警告信息观察(SQLSTATE 01586)。
IMMEDIATE UNCHECKED:不对表做检查,但将表从set integrity pending 状态中脱离出来。当表数据很大时,做完整性检查需要花费很长时间,因此如果能够确保加载的数据都是正确的,采用此选项将会大大降低执行时间。
对于处在set integrity pending 状态下的表,如果包含异常数据,则必须创建异常表,才能使表脱离此状态,例如:
db2 "create table t2_exp like t2"
db2 "set integrity for db2inst1.t2 immediate checked for exception in t2 use t2_exp"
set integrity 的其他用法
1)、将T1表置于set integrity pending状态、不允许访问状态,同时将它的依赖表置于set integrity pending 状态,代码如下:
SET INTEGRITY FOR T1 OFF NO ACCESS CASCADE IMMEDIATE
2)、不对manager表的外键约束和employee的检查约束做检查,并将该表脱离set integrity pending 状态,代码如下:
SET INTEGRITY FOR MANAGER FOREIGN KEY, EMPLOYEE CHECK IMMEDIATE UNCHECKED
5疑惑解答与案例演示
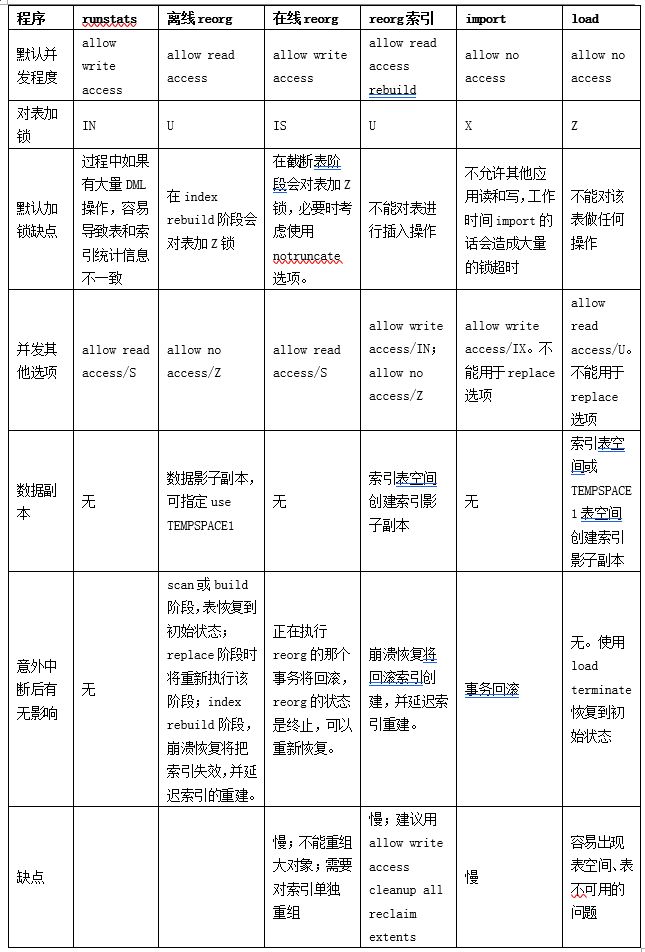
5.1、runstats、reorg、load的并发性
5.2、load与import的优化例子
#使用allow read access选项,对表加U锁,允许读之前已经存在的数据,不允许对表做UPDATE和DELETE。默认是allow no access选项,对表加Z锁,不能读写该表。
#调整sortheap数据库配置参数,用于对索引键进行排序,建议200M,比如51200个页面。
#调整UTIL_HEAP_SZ参数,建议为400M,比如102400个页面。
db2 "load from ./bp_transition.del of del modified by lobsinfile implicitlyhiddeninclude coldel0x0f delprioritychar savecount 10000 rowcount 10000 insert into db2obits.bp_transition nonrecoverable allow read access"
#使用allow write access选项,对表加IX锁,允许读写该表。默认是allow no access选项,对表加X锁,不能读写该表
db2 "import from ./bp_transition.del of del modified by lobsinfile implicitlyhiddeninclude coldel0x0f delprioritychar allow write access commitcount 10000 insert into db2obits.bp_transition"
文章word版共享链接:
https://pan.baidu.com/s/1bprZhev
供稿 | 黄海 编辑 | lin

