




2019年5月8日–10日,第十届中国数据库技术大会DTCC在北京举行,百度NewSQL数据库架构师严龙受邀在DTCC大会上进行了主题为《CockroachDB 2.x特性详解》的技术分享,介绍了CockroachDB自2018年4月发布2.0版本到目前的2.1.6版本期间引入的一些新特性,以及在百度内部进行的相关实践。

如下是分享的内容,主要包括四个部分:CockroachDB简介、CockroachDB 2.x关键特性、CockroachDB 2.x在百度的实践、CockroachDB Roadmap。
CockroachDB简介

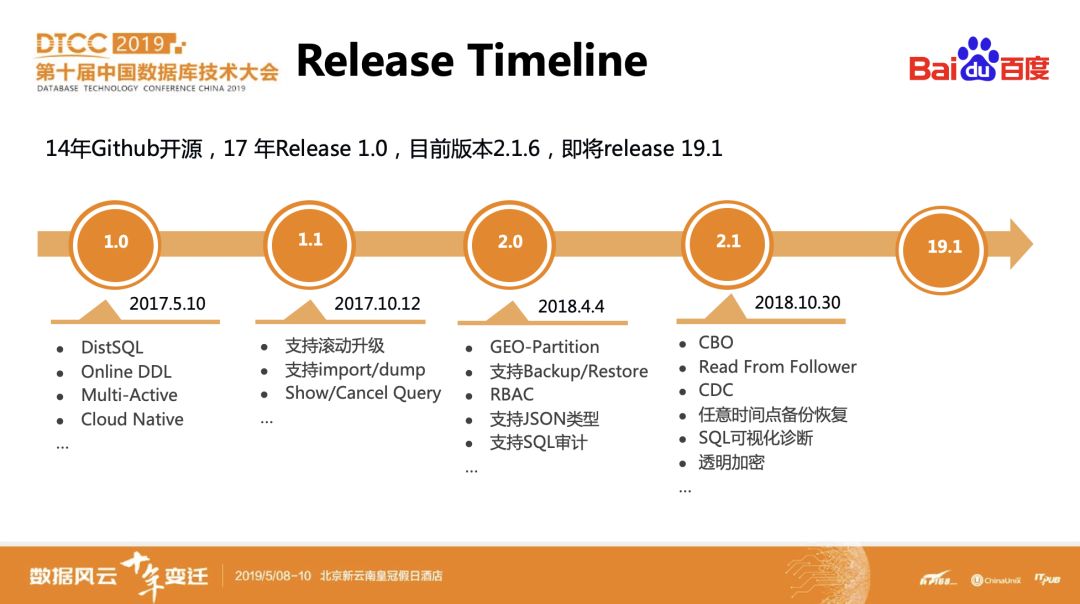
CockroachDB是2014年在Github上开源的NewSQL开源数据库项目,是目前开源界最受关注的布式数据库之一。
CockroachDB在17年5月release了1.0版本,18年4月release了2.0版本,目前已经进入到2.1.6版本。2.1版本在性能方面进行了进一步优化,同时引入了几个重要的特性,如CBO优化器、Read From Follower、CDC、任意时间点恢复等。
值得一提的是,CockroachDB将变更后续发布的新版本的版本号命名方式,版本号将改为“年份+release序号“,例如即将发布的2019年的第一个版本的版本号为”19.1”。
CockroachDB 2.x关键特性
CockroachDB在2.0~2.1版本中新增了几个比较重要的特性:Cost-Based Optimizer、Read From Follower和CDC。
1、Cost-Based Optimizer
优化器是影响数据库性能的核心因素之一,CockroachDB在1.0版本使用的优化器是RBO(Rule-Based Optimizer)。RBO优化器会根据一些通用的优化规则来重写执行计划,这种静态的优化方式无法在时间和效率方面对执行计划进行评估,在某些情况下优化效果并不理想;另一方面,随着SQL引擎的不断完善增强,优化规则的维护变得越来越复杂。为了进一步提升在性能方面的表现,CockroachDB在2.1版本引入了CBO优化器。
CockroachDB的CBO实现参考了现有的成熟的CBO方案,整体优化过程主要参考的Volcano模型。从下图可以看到CBO基本的优化思路,SQL引擎在对SQL语句进行语法解析和语义分析后,通过3个阶段来生成和优化执行计划:Prep阶段、Rewrite阶段和Search阶段。

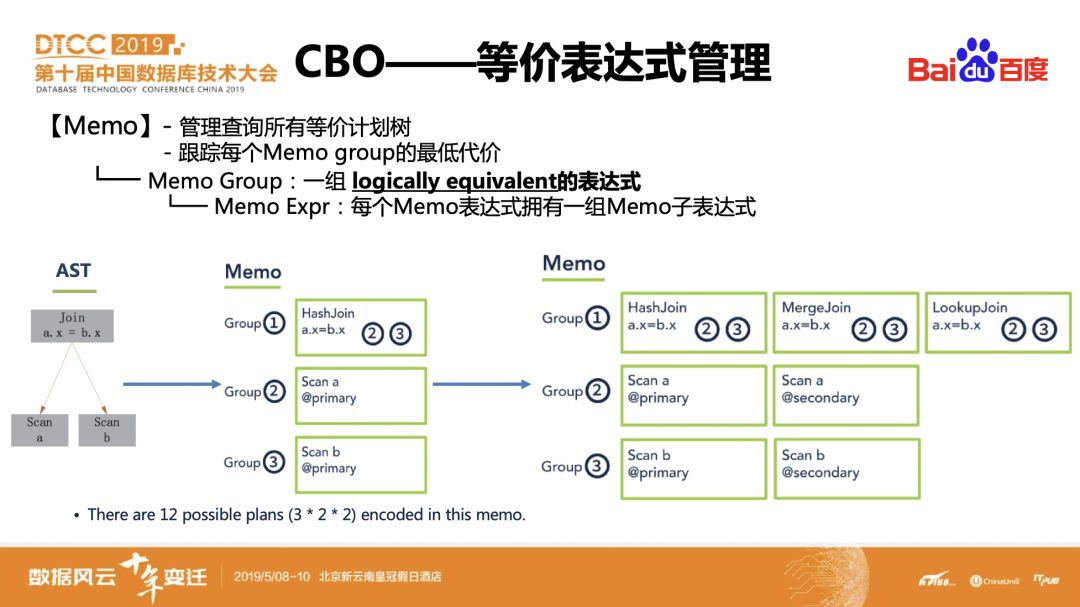
在CBO执行查询优化的过程中,会对执行计划树进行多次等价替换,生成多种等价表达式,越是复杂的查询,产生的等价计划数量越多,这些等价计划的管理也会变得很复杂,所以CockroachDB设计了一种叫做 Memo 的结构来管理和检索这些等价执行计划。
Memo整体的思路是将表达式进行等价替换时产生的等价表达式都集中到同一个Memo group中,Memo group中的表达式通过GroupID索引自己的下一层表达式,每个group同时维护一个代价最低的表达式。通过Memo的方式来管理等价执行计划,不需要单独维护每一棵可能的执行计划树,节省了存储空间。
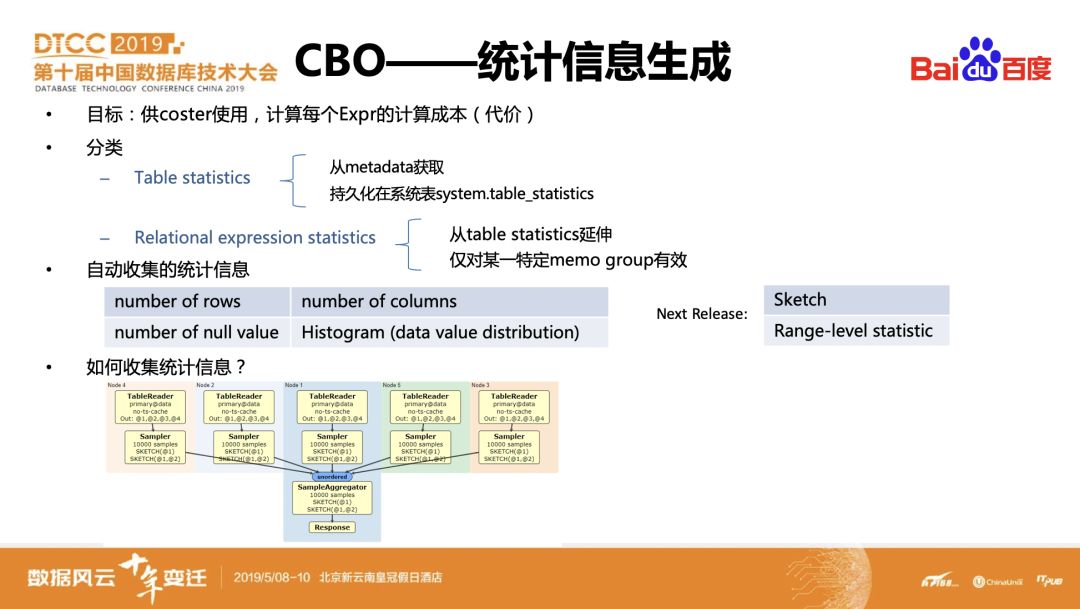
CockroachDB在统计信息方面主要参考了Postgres的实现。目前统计信息分成两类:Table statistics和Relational expression statistics。Table statistics主要是常见的row count、表宽度、空值统计和直方图,而Relational expression statistics主要是基于表级的统计信息叠加操作符的逻辑属性做进一步的推导,例如scan表达式可根据表的统计信息进一步估算可能的输出行数。在19.1版本将会引入distinct和range级别的统计信息。
总体来看,CockroachDB的CBO优化器支持了绝大部分SQL语句的优化,在性能方面有显著提升,在即将发布的19.1版本也会进一步对CBO进行完善。
2、Read From Follower
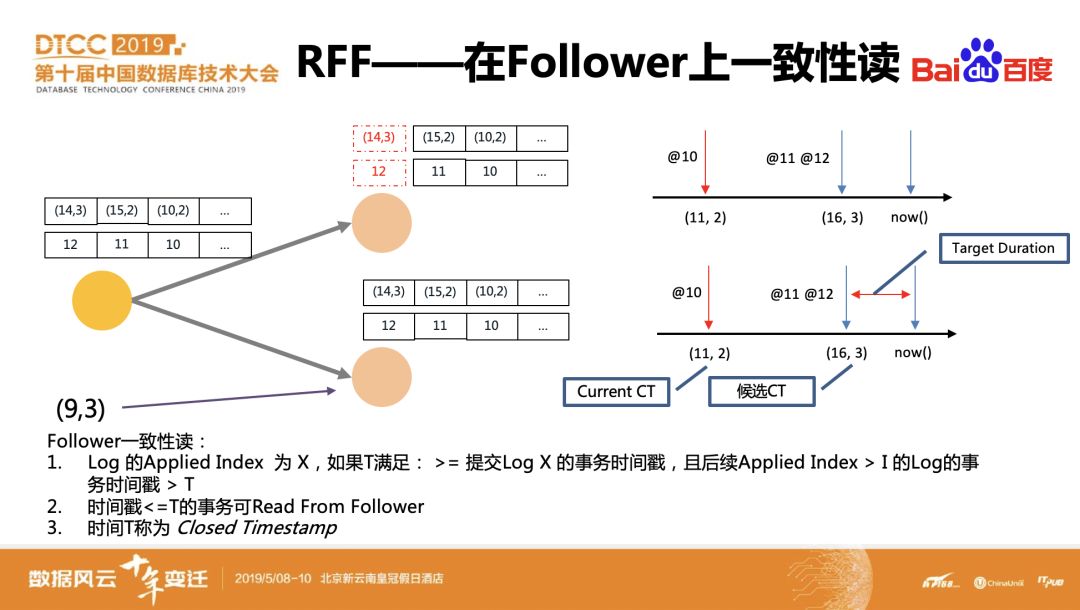
CockroachDB底层数据默认是3副本,只有Leader/Lease holder可以读写数据,这样所有的读写压力都集中在一个副本上。是否可以参考读写分离结构,让follower也提供部分读功能,来分摊一部分压力?通过分析发现,像Long run的查询、历史读、以及只读表在一定条件下是可以由follower来提供服务的。
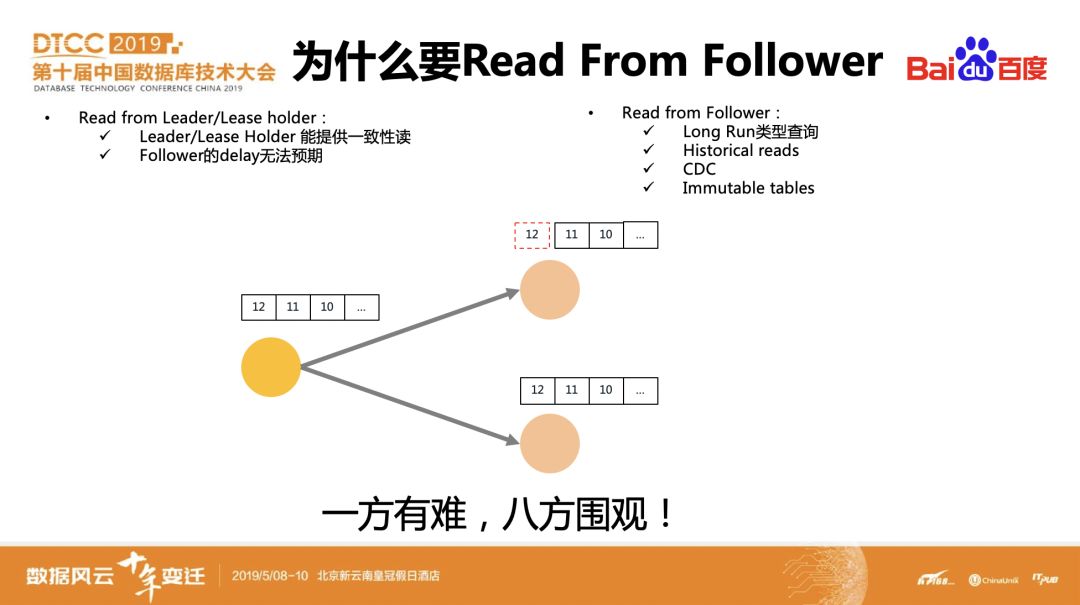
在follower上读数据时如何保证一致性读?我们给每条raft log加一个事务时间T,当一条raft log已经被所有follower apply了,如果能保证后续提交raft log的事务的时间戳是在T之后的,那么它从任意一个follower上读取早于T的数据都是安全的。该时间T在CockroachDB中使用Close timestamp来标识,如果后续事务读取数据的时间戳小于Close timestamp的话,就可以read from follower。
那么Close timestamp是如何确定的?系统会设置一个Target duration,然后使用当前时间-Target duration作为备选Close timestamp,如果此时没有小于该时间的raft log在等待apply,则leader会尝试把Close timestamp调整到该时间,若后续发现还有比Close timestamp更早的raft log提交过来,leader会让该事务restart,从而保证满足上述的约束。
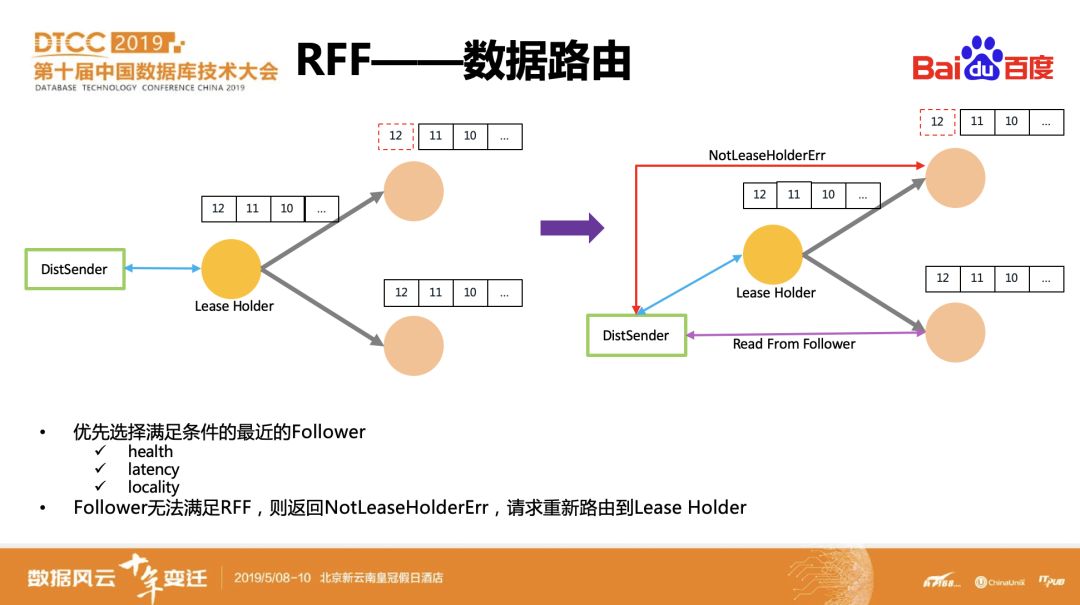
在副本之间的同步改造完之后,请求的路由也跟着会发生一些变化,以前读请求统一发送到lease holder上,现在会优先选择最优的follower,如果该follower无法满足一致性读,则给上层DistSender返回一个NotLeaseholder的错误,并告知其lease holder的位置,由DistSender把请求重新转发到leaseholder上。
3、Change Data Capture
虽然CockroachDB支持海量存储和高性能查询任务,但业务有时候也需要与其他系统共同协作,例如在集群间做数据同步,可用于灾备、模拟沙盒环境等,或者将CockroachDB中的数据镜像传输到分析引擎或大数据管道中,进行数据分析、数据挖掘。 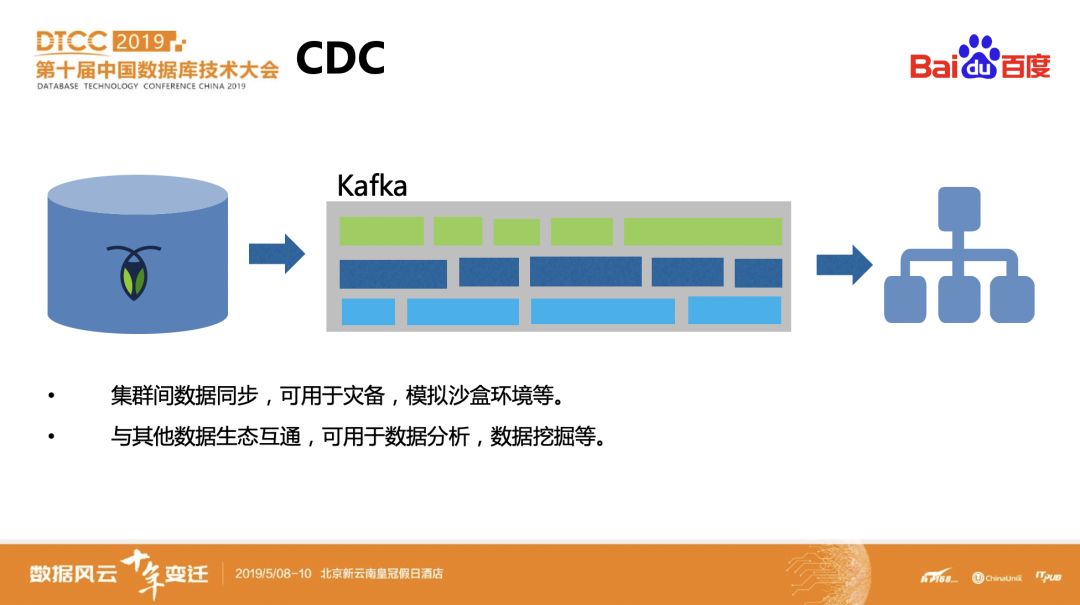
CockroachDB 2.x在百度的实践
在实践方面介绍了百度在CockroachDB
2.x版本上的冷热数据分离方案。如果使用SSD来存储PB级别数据,需要高昂的硬件成本,但若使用SATA
HDD盘来存储,在性能方面又有较大的下降,难以满足业务需求。结合具体业务的数据和使用特征,我们设计了使用SSD和SATA
HDD混合部署方案,利用CockroachDB的GEO-Partition特性,对用户数据基于时间维度做水平分区,三个月以内的数据放在SSD区域,三个月以前的归档到SATA
HDD区域。GEO-Partition支持对用户透明的数据水平分区,可以单独对每一个分区设置独立的复制策略,保证热数据只在
SSD区域,冷数据只在HDD区域,而且支持在线调整分区。
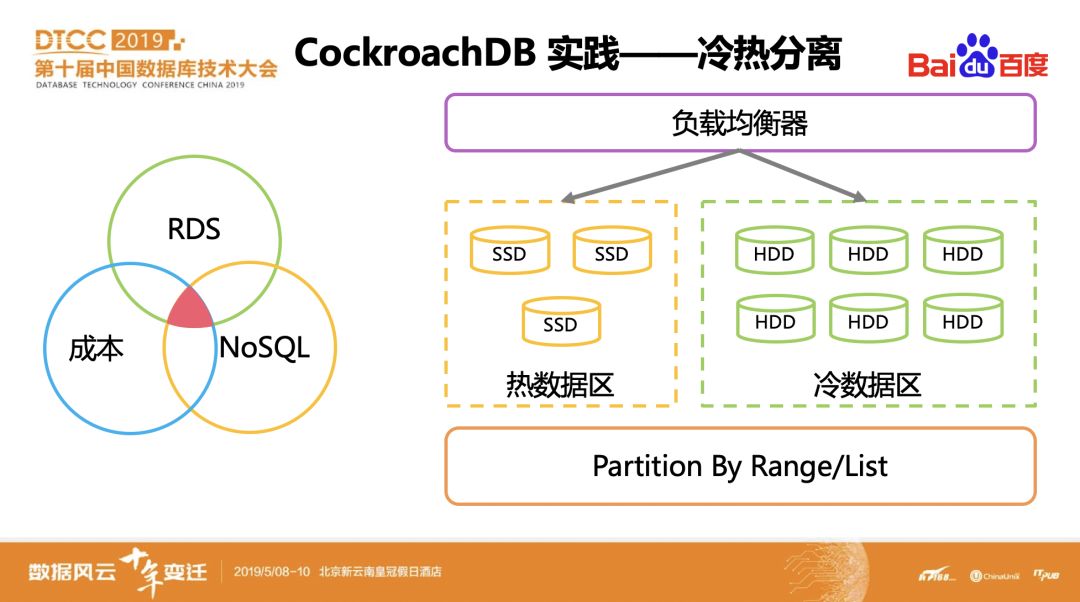
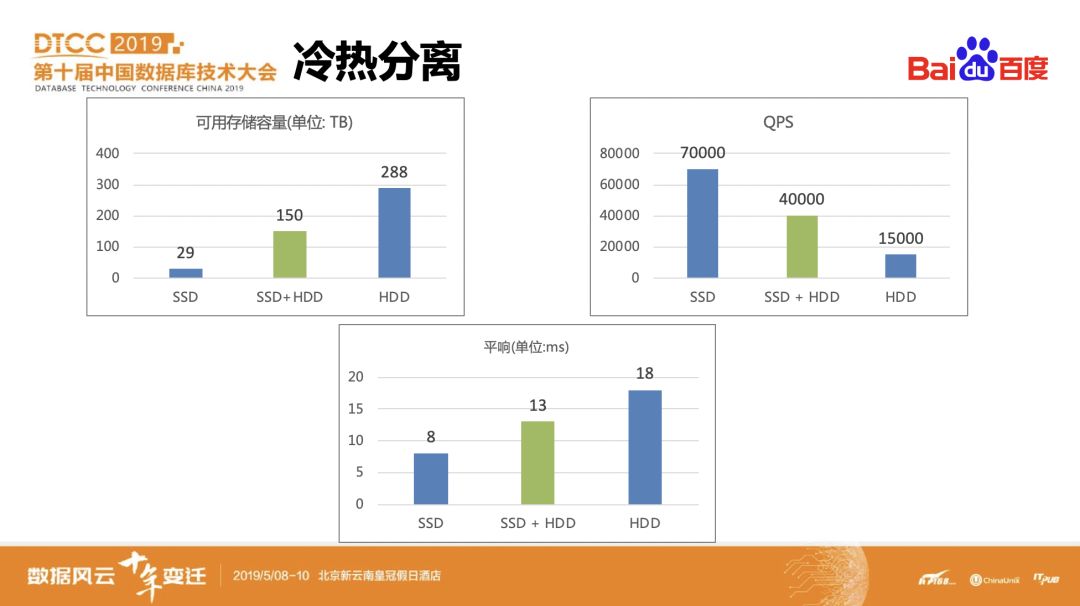
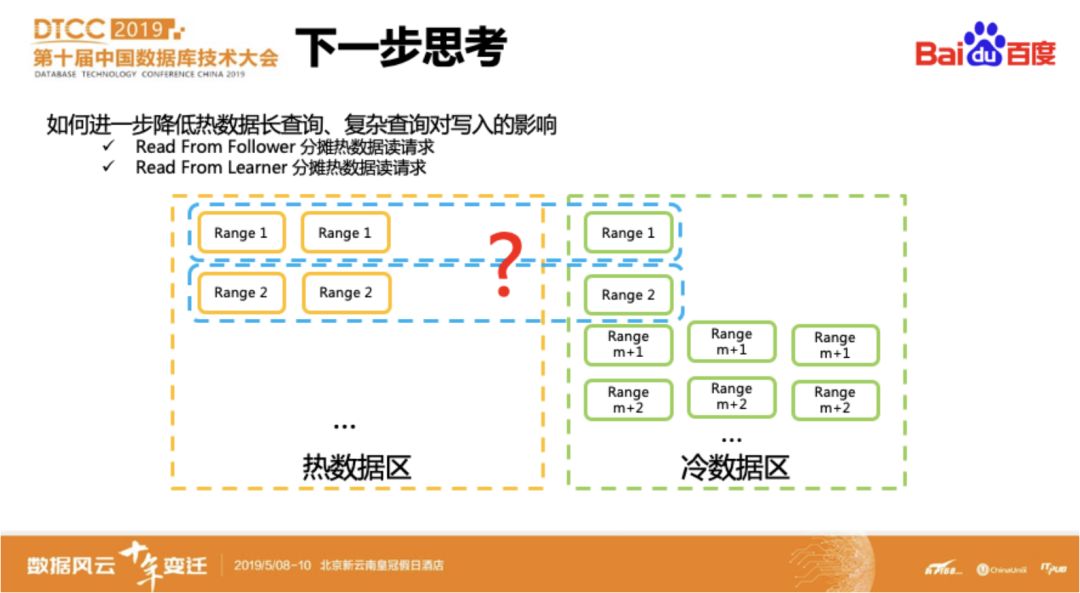
该混合部署方案结合GEO-Partition特性和冷热分离思想,兼顾了成本和性能,满足业务的使用需求。针对该方案的进一步优化思考,主要是解决如何降低热数据上的Long run查询、复杂查询对写入的影响,目前考虑使用Read From Follower/Read From Learner的方式来分摊lease holder的压力,从而提升系统整体的读写性能。
CockroachDB Roadmap
最后介绍了CockroachDB的Roadmap,在CBO优化器优化、内核、在线事务变更和安全方面都有较大的增强。 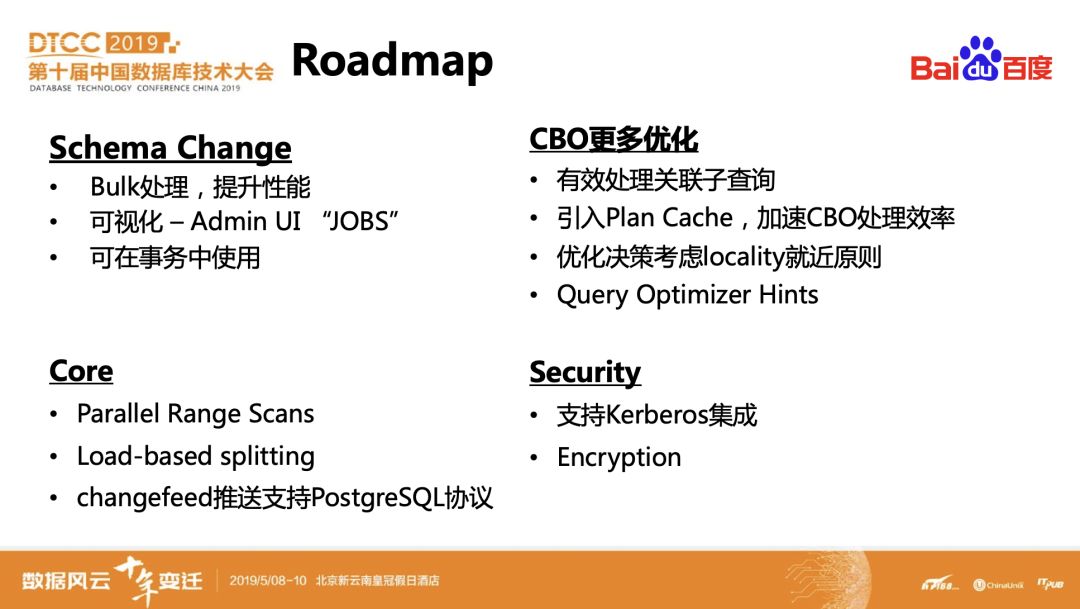
关于我们:我们是百度 DBA 团队,团队有多位 CockroachDB PMC Member 及 Contributor, 目前正积极推动 NewSQL 在百度内部以及外部的发展。除了NewSQL, 我们在MySQL, PostgreSQL, GreenPlum 有多年的内核开发经验及实践经验,对数据库和大数据领域有疑问或者需求欢迎联系我们,同时欢迎有志青年加入我们!
关注我们

