




前 言

CockroachDB是著名的开源NewSQL数据库,对外提供了标准SQL接口。本文将先从全局视角出发,介绍一个SQL语句从用户发送请求到服务端进行解析和处理的过程,包括在系统各层(网络协议、执行计划、语法树、相关转换)上的关键内容和相关代码路径。对于部分模块的细节和原理,后续将会有更多专题文章进行深入介绍。
(注:本文示例代码是CockroachDB v1.0,其中部分代码在v2.0有所优化,但其实现思路类似。)
概 述
用户通过客户端连接CockroachDB数据库,发送SQL执行命令,该请求在CockroachDB内部的实现过程如图:
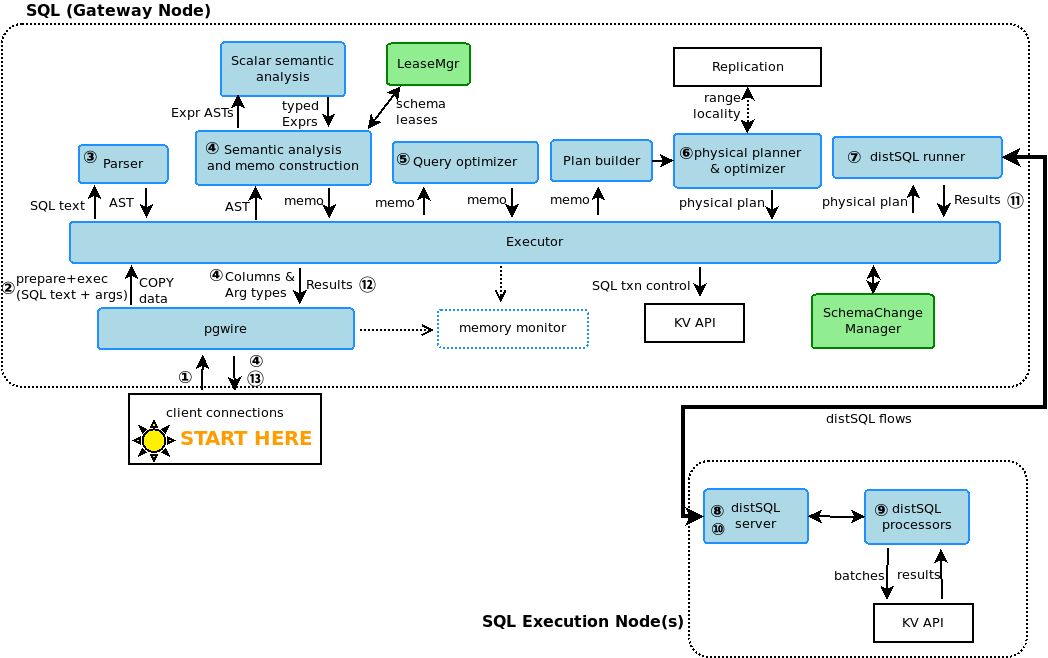
pgwire:客户端和CockroachDB的SQL执行器之间使用Postgres Wire协议通信,该模块负责接收用户的查询,并将结果返回给用户;
SQL Executor:SQL执行器负责SQL语句的转换和执行,实际查询过程是在session对象的上下文中完成的,它维护了执行过程的相关信息;
语句解析:解析用户请求中的String类型的SQL语句,生成一颗抽象语法树(AST);
构建执行计划:解析和转换AST树,构建执行计划,并进行优化;
构建分布式物理执行计划:物理计划决定在哪些节点上执行哪些计算,并将执行完的结果通过pgwire返回给用户。
Postgres Wire协议
CockroachDB使用Postgres协议来兼容现有的客户端驱动和应用程序。用户通过Postgres wire协议将query发送到CockorachDB服务器。
客户端的连接使用pgwire.v3Conn结构体来表示(它封装了net.Conn接口),v3Conn.Serve()负责维护用户的连接,读取query,将query发送给SQL执行器,然后收集结果并返回给用户。
Postgres Wire协议是面向消息的:在连接的生命周期内,我们读取一条消息,并将其传递给SQL执行器来批量执行消息中的语句,在执行完成并产生结果后,就会将结果序列化后发回给客户端。
该协议的功能在代码pgwire包中。
SQL Executor
sql.Executor负责统一协调SQL层各个组件来完成SQL语句转换、执行,并将结果返回pgwire.v3Conn。它还维护了SQL事务状态相关信息、处理部分事务的自动重试。
执行器入口是Executor.execRequest(),它接收一批String格式的SQL语句,并逐个执行,更新相关状态并返回结果。
实际查询过程是在sql.Session对象的上下文中完成的,它记录了连接状态相关的信息(例如当前选择的数据库、设置的各种变量、事务状态等)以及该连接在查询过程中的内存使用量信息。
Executor通过planner完成计划和查询相关工作。
语句解析
Executor做的第一件事情就是调用解析器Parser,把SQL语句从String类型解析成AST(抽象语法树,Abstract Syntax Trees)。解析生成的AST通常有两种类型:Statements和Expressions。AST后续会被planner转化为执行计划。
CockroachDB的Parser是通过解析文件sql.y生成的一个LALR解析器,相关的实现在sql/parser 包下面。
语句执行
Executor.execRequest()会按顺序遍历Statements列表,并一次执行一个事务相关的语句(通过BEGIN和COMMIT/ROLLBACK提交的一组语句,或者单个语句)。它通过调用runTxnAttempt函数来执行语句,在执行完一批语句后,如果session中的事务状态仍未结束,则将会继续执行后续的语句,直到遇到COMMIT/ROLLBACK才返回结果。
这里有一点需要说明:SQL执行器的代码接口是面向流的(处理在一个SQL事务范围内的SQL语句), KV层接口是面向请求的,事务需要显式附加到每个请求上。KV层最重要的接口之一是Txn.Exec(),Txn代表一个事务,它包含KV客户端接口(此处提到的客户端和服务端是指CockroachDB内部实现相关的内容,并非实际用户和CockroachDB服务)。
Txn.Exec接口接收一个回调函数和一些options,基于这些options来执行回调函数和提交事务。如果options允许,在某些情况下它可能会通过多次执行回调函数来处理事务重试(通常是竞争数据引起的),不过这类重试并不适合让KV客户端自动执行,因为事务重试处理存在一定复杂性。
单个SQL语句(隐式事务)的重试是安全的,然而当一个事务存在多个SQL语句,并通过多个client请求传递给多个Txn.Exec时,由于它们执行的是不同语句,所以不能只重试其中的一个,我们必须重试事务中的所有语句,另一方面,通常这些语句会依赖客户端的逻辑(例如SELECT出不同结果可能会决定后续不同的语句),因此不能简单逐句重试。这种情况通常会给客户端返回一个“可重试“错误。Executor.execRequest()中捕获和处理了这些问题,它包含设置不同options的逻辑和传递合适的回调函数给Txn.Exec()。
构建执行计划
在CockroachDB中,执行计划是一个由planNode节点组成的树(类似AST),它包含语义信息和runtime状态。
Executor.execStmt通过调用Planner.makePlan来生成执行计划。Planner.makePlan接收一个解析过的语句,然后在执行完完语义分析和各种转换后,返回planNode树的根节点。这个节点是可执行的,它拥有Start()和Next()方法,每个节点都会消费掉其子节点产生的数据(例如JoinNode将消费掉它的left、right子节点的数据)。
在生成执行计划过程中,planner会从AST根节点开始查找它的Statement类型,对于每种类型都有一个特定的方法用来创建执行计划。例如一个Select语句通常是由多个部分组成的,其中scanNode是用来读取表数据的,WHERE中的条件会被转换为表示式并分配给filterNode,ORDER BY条件会被转化为sortNode等,最终会产生一个selectTopNode,它其实是一颗由多种planNode组成的树。
最后,执行计划会进行一定程度的简化和优化,例如删除一些no-op(无操作)的中间节点、移除selectTopNode封装等。
举个例子:

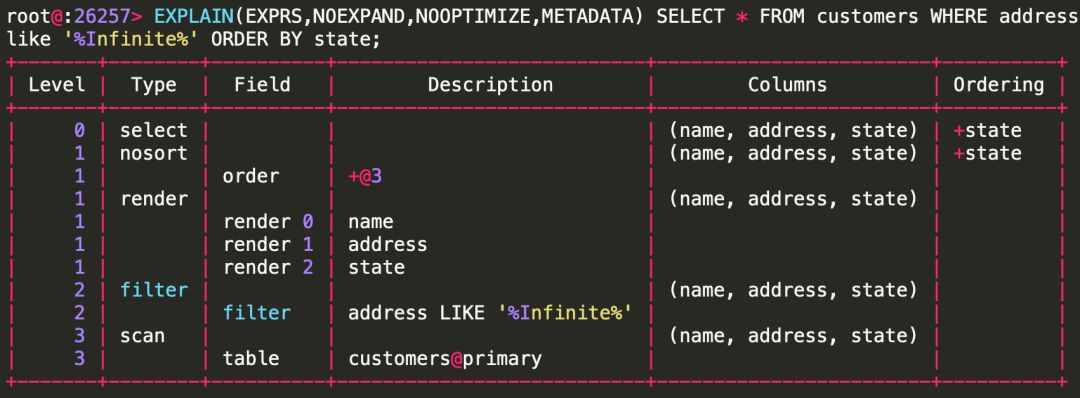
通过上图的plan可以看到,数据由scanNode产生(图中的scan),在filterNode做过滤(图中的filter),然后在sortNode做排序(对应图中的nosort,因为我们使用NOOPTIMIZE字段禁止了排序分析,所以sortNode目前还不知道是否需要进行排序),然后封装成selectTopNode(图中的select)。
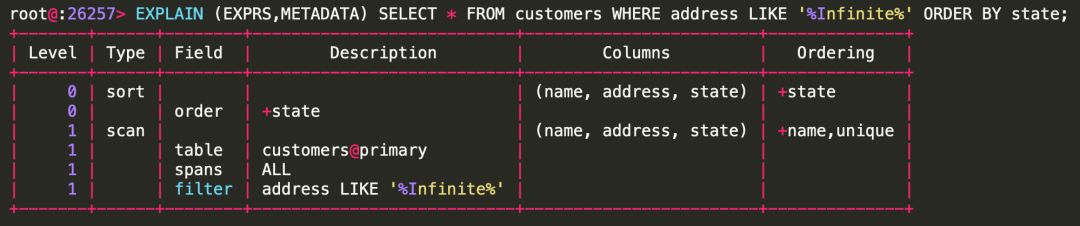
如果不使用NOOPTIMIZE,EXPLAIN的输出如下,可以看到对比初始的plan进行了一定的优化和简化。
Expression
expression是语句的一部分,一般出现在 WHERE、LIMIT、ORDER BY 等子句中。每个planNode节点都负责调用 planner.analyzeExpr 来对expression进行处理,它会执行以下内容:
resolving names(名称解析)。例如在 “select 3 * colA from MyTable” 中的 colA 需要被替换为底层数据源(通常是 scanNode)产生的行中的索引。
normalization(常规转化)。例如”a=1+1” 转为”a=2”,”a not between b and c” 转为” (a < b) or ( a > c )”。
type checking(类型检查),主要包括:
constant folding(常量折叠),例如1+2 转化为3。我们使用和Go编译器相同的库执行算术计算,并将所有常量分为两类:数字类 NumVal 或字符类 StrVal。 这些常量的表示足够智能,可以找出可以值的对应的类型集(例如 5 可以表示为 int, decimal 或者 float, 但是 5.4 只能表示为 decimal 或者 float ) ,这在后续将会很有用。
type inference and propagation(类型推断和传播)。此阶段将结果类型分配给表达式,在这个过程中会推断所有子表达式的类型。
使用执行计划节点sql.subquery来替换子查询的语法节点。
关于子查询:在sql语句 “select from Employees where DepartmentID in (select DepartmentID from Departments where NumEmployees > 100)” 中,在 Departments 表上进行的查询是一个子查询。子查询会被 subqueryVisitor 识别并替换成可执行的节点,然后 subqueryPlanVisitor 会执行该节点,并使用返回的结果进行替代。这个过程通常在最顶层的节点开始执行时(例如 renderNode.Start())完成。
PlanNodes
执行计划节点负责执行查询中的一部分,每个节点都会消费其子节点产生的数据,执行相关操作,然后再把数据传给更高层的节点。
节点构建完成后,会通过 Start 方法进行初始化,然后通过多次调用 Next 来不断产生下一行数据。
我们使用上文提到的 customers 表,进行一个SELECT查询,然后看看其中的一些planNode: 
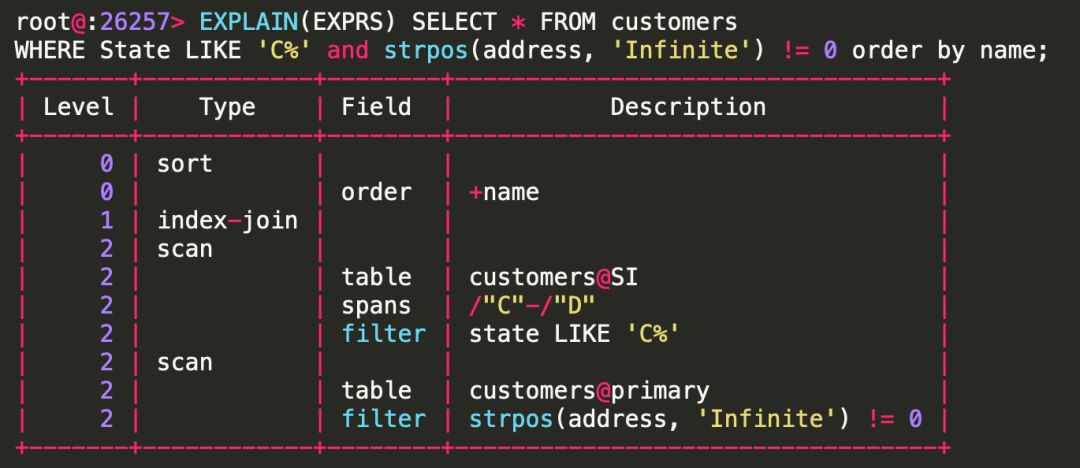
该语句生成的执行计划,从高到低分别为: 
首先需要解释一下这个 indexJoinNode 是怎么来的,因为在这个SELECT语句的语法结构中并没有指明使用 SI 索引。实际上,这里还有一个我们之前没有提到的步骤:”plan expansion”(计划扩展),它会进行相关索引选择(关于目前是如何进行索引选择,可以参考此博客:https://www.cockroachlabs.com/blog/index-selection-cockroachdb-2/)。在这个例子中,SI 索引可以利用条件 “State LIKE ‘C%’” 来更高效得获取我们想要得数据。
我们来看看 planNode 是如何运行的:
sortNode 对应 ORDER BY 子句,它对其子节点产生的rows进行排序。有时候排序依据不是一个简单的列,例如ORDER BY a+b,则需要在子节点计算好每一行 a+b 的值。通常 renderNode 会对该表达式进行计算,然后把结果发给 sortNode。实际的排序是在 sortNode.Next() 中进行的。第一次调用时,它会消费其子节点产生的所有数据并累积到 n.sortStrategy(一个隐藏了多种排序算法的接口)中,当消费到最后一行数据时,会调用 n.sortStrategy.Finish(),此时排序算法已经完成排序。接下来调用 sortnode.next() 只是迭代排序算法的结果。
indexJoinNode 实现了索引的结果和表的行的连接。它一般在当一个查询可以使用索引时使用。它可能不包含查询所需的所有列,那些它不包含的列需要通过主键来获取。indexJoinNode 节点在两个scan节点的上面,其中一个scan扫描索引,另一个scan通过Primary Key进行点查。在这个例子中,我们可以看到 SI 索引用于获取符合 state 过滤条件的行,但是因为它没有包含 address 列,所以还是需要使用主键来获取。因为每个索引KV对都包含主键信息,我们可以使用该信息对PK进行点查。indexJoinNode.Next 从索引读取下一行,并为每一行添加PK读取需要的spans信息。
scanNode 通常是 renderNode 和 filterNode 的数据源,它负责扫描一张表的Key/Value对并构成行。这里已经越来越接近实际数据–分布式KV层了。scanNOde 会执行过滤表达式,类似 filterNode,因为CockroachDB尝试尽可能得把 WHERE 子句的某些部分下推,从而提高效率。例如像下列查询:

它将会产生两个 scanNode,一个负责 Customers 表,另一个负责 Orders 表,它们都能处理各自节点涉及的表的过滤条件,然后由更高层的join节点来处理同时需要两张表数据才能处理的过滤条件。
继续往下看看 scanNode 在实际读取数据时使用到的数据结构:
rowFetcher 负责遍历KV对,确定SQL表或索引行的结束位置(一行数据可能被编码成多个KV对)、KV解码、处理主键索引和其他索引之间的差异等。rowFetcher 还负责把从磁盘上读取的字节数组解码成我们我们可以进行处理的数据。rowfetcher 将调用kvbatchfetcher 来从数据库中读取KV对。
kvBatchFetcher 从KV数据库读取数据,它对SQL层的东西一无所知,例如表、行和列。在创建一个 kvBatchFetcher 时,会指定它需要读取的key的范围(key spans),例如可能是一个span,用来读取一整张表,也可能是几个spans,用来读取主键或者索引的一部分数据。kvBatchFetcher 使用KV层的client接口“client.Batch“—它是SQL层和KV层的接口,并创建相关的Batches请求,把请求发送到KV层进行处理,读取结果并把它们返回给planNode一层。
构建分布式物理执行计划
通过逻辑计划构建的分布式物理执行计划将决定在哪些节点上执行哪些计算,最后将结果通过pgwire返回给用户。
集群中每个节点会负责整个物理计划(DAG图)的其中一部分,我们把它的每一部分都成为流。流由其中的physical plan节点序列、它们之间的连接(input synchronizers, output routers)、计划中顶部节点的输入流标识符和底部节点的输出流(可能是多个)来描述。一个节点可能负责多个异构流。
节点实现了ScheduleFlows RPC,它接受一组流、设置输入输出mailboxes、创建本地处理器并开始执行。为了允许生产者和消费者在不同时间启动,ScheduleFlows会为所有输入和输出流创建命名邮箱Mailboxes。 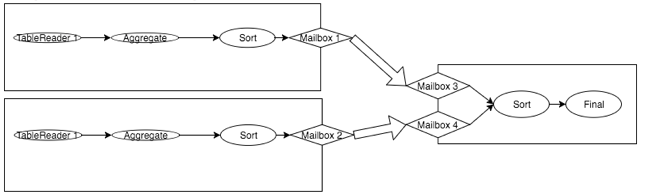
分布式物理计划部分相关代码在:pkg/sql/distsql{plan,run}
总 结
本文介绍了一个SQL语句从用户发送请求到服务端进行解析和处理的过程:用户通过pgwire协议与服务端通信,发送SQL请求,SQL请求在CockroachDB内部经过语法解析、构建逻辑计划、优化执行计划、生成分布式物理执行计划,执行计划并将结果返回给用户。
出于文章篇幅考虑,此处并未对细节展开分析,我们后续会有更多专题文章来对SQL引擎相关原理进行深入介绍。
参考文档:
https://github.com/cockroachdb/cockroach/blob/master/docs/tech-notes/life_of_a_query.md
https://github.com/cockroachdb/cockroach/blob/master/docs/tech-notes/sql.md
https://github.com/cockroachdb/cockroach/blob/master/docs/RFCS/20160421_distributed_sql.md
关于我们:我们是百度 DBA 团队,团队有两位 CockroachDB PMC Member 及一位 Contributor, 目前正积极推动 NewSQL 在百度内部以及外部的发展。除了NewSQL, 我们在MySQL, PostgreSQL, GreenPlum 有多年的内核开发经验及实践经验,对数据库和大数据领域有疑问或者需求欢迎联系我们,同时欢迎有志青年加入我们!
关注我们

