




本篇介绍CockroachDB底层存储引擎RocksDB数据读取的相关细节。通过LSM存储模型的层级结构及基于文件组织形式来介绍读取数据方法,最后介绍RocksDB支持的快照功能及使用。
TIPS:
以下内容基于CockroachDB v2.0.3版本,集成的RocksDB版本为v5.13.4。
LSM 回顾

根据LSM存储模型,RocksDB首先会写WAL日志,然后将数据插入到Active状态的MemTable当中。Active状态的MemTable的数据量达到一定阈值以后转化为Immutable
MemTable,随着后台FlushJob异步持久化成不可修改的多个SSTable文件。为了更好的读性能,后台也会适时地开启Compaction任务,合并多个Key值范围重叠、彼此之间可能无序的SSTable文件成新的整体有序的SSTable文件,同时回收冗余的多版本数据,减少文件数量。
如下图,默认情况下RocksDB将硬盘上的SSTable文件组织成多个Level。除了L0层SSTable文件彼此之间不保证有序,L1到Ln到每层SSTable彼此之间互不重叠,每层都形成一个有序的KV序列。
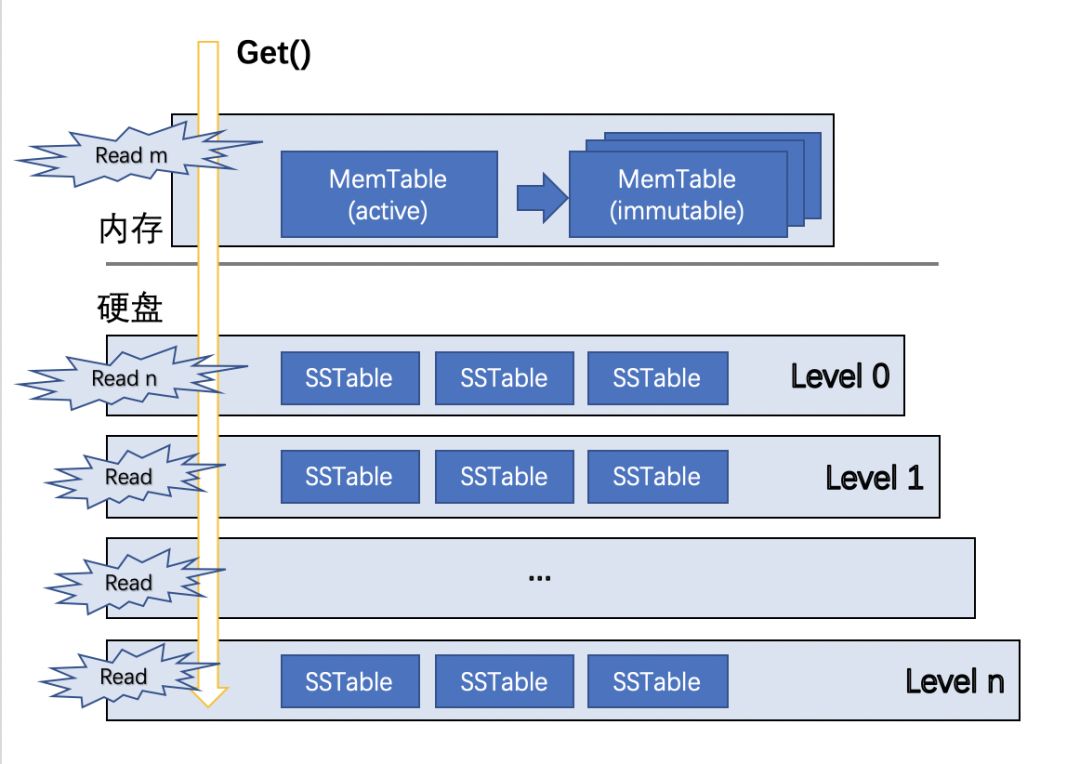
数据查询在这样的分层结构中自上而下进行,可能需要聚合多个版本的数据,返回查询结果。
读取数据方式
| Get方法实现
对于RocksDB来说,读操作基本都是快照读,但不生成快照对象,只是在调用读接口的时候获取指定快照的序列号(Seqnumber)或是当前DB实例最新序列号,来决定读操作对数据可见范围。
Get方法实现的大体逻辑如下:
获取序列号构造LookUpKey,作为内部查询的Key值。
调用Active状态的MemTable的Get方法,查看是否存在指定Key值。
调用所有Immutable状态的MemTable的Get方法,查看是否存在指定Key值。
获取记录硬盘SSTable文件层级结构的最新Version对象,调用其Get方法。尝试从L0层一直遍历到最底层Ln层,直到在某一层查找到与指定Key值相匹配的键值对数据。通过比较SSTable元数据(该SSTable文件的Key值范围),确定每一层文件中跟指定Key值范围重叠的所有SSTable文件,并逐一查询。
对于需要查询的每一个SSTable文件,RocksDB通过指定的文件元信息,调用TableCache的Get方法,从缓存中获取或是从设备中读取文件并生成TableReader对象,再调用该TableReader对象的Get方法查询数据。
TableReader对象的Get方法,实现了从持久化的SSTable文件中查找指定Key值对应键值对的逻辑。如下图,对于BlockBasedTable类型的文件,其TableReader对象的Get方法,会先尝试获取Filter块生成BloomFilter,通过BloomFilter查看指定Key值是否一定不存在。若可能存在,则读取索引块数据。通过索引找到Key值所在的具体数据块,遍历数据块的内容查看Key值是否存在。
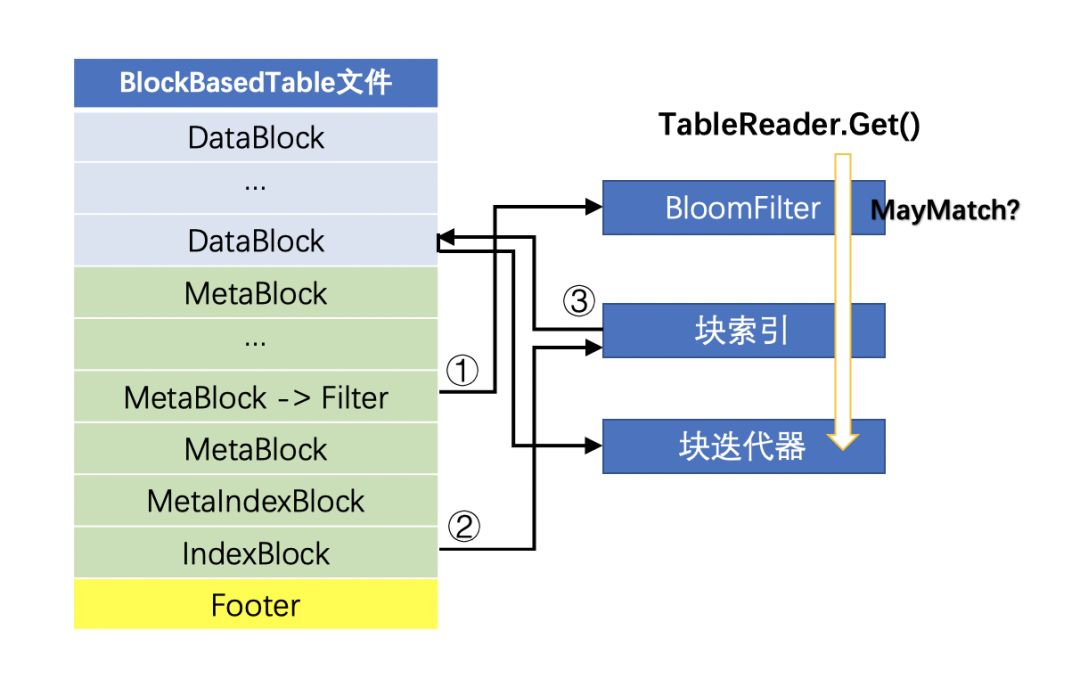
可以看出通过Get方法获取指定Key值对应的Value值,意味着自上而下多个数据结构的查询。特别是对硬盘SSTable文件的查询,如果索引块、Filter块等数据没有得到很好的缓存,或是需要查询文件数量太多,往往意味着多次硬盘IO,数据读取性能下降。这就需要针对性地进行性能调优。
| 迭代器遍历
除了通过Get方法查询单个键值对数据以外,还可以通过迭代器进行连续数据的遍历。在存储引擎(一)已经讲到,RocksDB针对很多物理上或逻辑上的数据结构,实现了对应的迭代器接口,自上而下层层嵌套,最上层可以通过DB实例的NewIterator方法创建迭代器遍历整个DB的数据。
默认情况下,迭代器自上而下依次为:
ArenaWrappedDBIter:使用Arena连续内存优化。
DBIter:DB迭代器,可以过滤多版本数据。
MergingIterator:组合迭代器。
MemTableIterator:不同类型的MemTable对应的迭代器。
LevelIterator:硬盘上L1到Ln层每层都对应一个迭代器。
BlockBasedTableIterator:硬盘上BlockBasedTable类型的SSTable文件所对应的迭代器,RocksDB默认使用BlockBaseTable类型的SSTable,一般为单层块索引。
BlockIter:不同类型的块所对应的迭代器,主要包括索引块和数据块。
迭代器设计使RocksDB从结构上看更加复杂,但简化了遍历的方式,对外部屏蔽RocksDB内部多种数据结构的复杂逻辑,提供统一的遍历接口,为后续特性拓展提供了便利。
快 照
| 新建快照
只需要获取当前序列号构造快照对象,插入到快照列表。
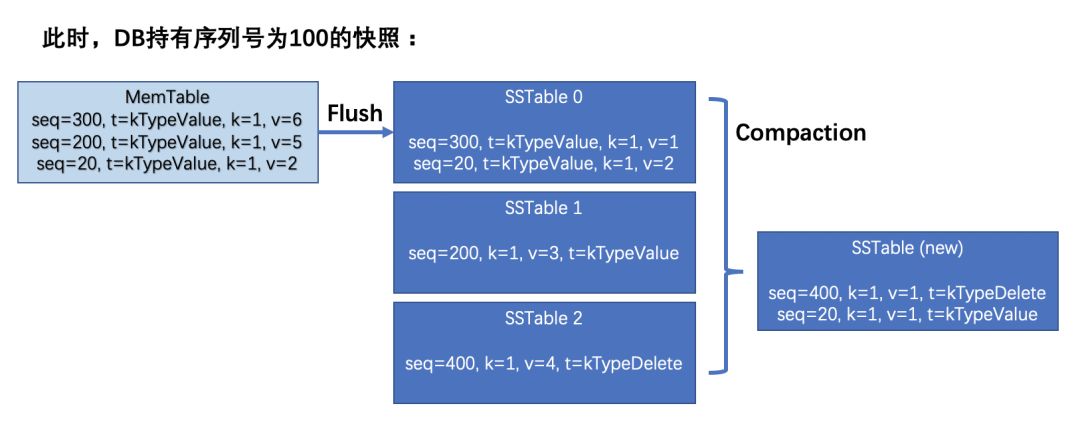
在生成CompactionJob对象的时候,会获取DB当前所有的快照。这些快照能够避免小于快照最小序列号的数据被新数据覆盖或被删除,保证快照数据的有效性,同时也带来老数据的空间得不到及时释放的问题。如下图,SSTable 0到2组成的Compaction因为快照(序列号为100)的缘故,保留了序列号为20的数据版本。
| 释放快照
RocksDB会删除快照列表中的快照对象,然后尝试标记LSM文件结构中最底层的某些SSTable文件为Compaction的目标文件,并触发后台Compaction任务。最底层SSTable文件是否标记为Compaction的目标文件,其判断的标准为该文件存在数据删除标记(一般来说数据删除标记在快照不存在的情况下不会出现在最底层SSTable文件),且最大序列号小于快照的序列号。这是为了避免最底层待删除的大量冷数据因为快照锁住的原因,占用的空间一直得不到回收。
总的来说,RocksDB通过LSM存储模型存储多版本数据,可以方便地实现快照功能,读取特定版本的数据。但是快照功能的使用可能会给Flush和Compaction带来较大的负担,因此尽量避免数据写入高峰的时候长时间持有快照。
CockroachDB
CockroachDB跟RocksDB数据读取相关的接口为engine.go的Reader接口,包括了迭代器创建和Get方法。
对于RocksDB的Get方法,CockroachDB只有在少数情况下直接使用,更多地是被MVCC层MVCCGet方法替代。CockroachDB实现了基于HLC时间戳的MVCC层,并将部分MVCC查询逻辑移植到了C++层,以获得更加高效的性能。CockroachDB MVCC相关的更多内容,可以阅读参考资料[3][4]。
对于RocksDB迭代器,CockroachDB在使用上必须指定查询范围的上限或是前缀,有利于提高迭代器Seek的效率,防止迭代器查询过多的数据。例如,CockroachDB在清理事务Intents的时候,对于使用了时间戳过滤的迭代器会指定查询范围的上限值,避免Seek操作为找到第一个大于或等于指定Key值的键值对,从前往后过滤掉很多SSTable文件而造成的性能问题。
总 结
作为CockroachDB底层存储引擎的RocksDB是基于LSM存储模型进行设计实现,读取数据时的Get方法所对应的随机查询性能与缓存命中率、读放大的控制有关;迭代器遍历所对应的范围查询则与空间放大有关。两者均受限于硬件资源的上限。开发者可以根据实际的硬件条件和业务数据特征对RocksDB进行参数调整,以获得更好性能。CockroachDB也可以通过--store Flag调整RocksDB实例的参数。
参考资料:
[1] https://github.com/cockroachdb/cockroach
[2] https://github.com/facebook/rocksdb
[3] https://mp.weixin.qq.com/s/ho2McS6yNohEJSqChXmckA
[4] https://mp.weixin.qq.com/s/39hPkoFZonWajhFWE41tVA
关于我们:我们是百度 DBA 团队,团队有两位 CockroachDB PMC Member 及一位 Contributor, 目前正积极推动 NewSQL 在百度内部以及外部的发展。除了NewSQL, 我们在MySQL, PostgreSQL, GreenPlum 有多年的内核开发经验及实践经验,对数据库和大数据领域有疑问或者需求欢迎联系我们,同时欢迎有志青年加入我们!
关注我们

