




在上一篇存储引擎介绍(一)中,我们了解到分布式 NewSQL 数据库 CockroachDB(简称 CRDB )通过 CGO 集成了 RocksDB 存储引擎,面向 CRDB 顶层的相关接口和结构体均在 engine.go 和 rocksdb.go 里声明和定义。本文就将从 LSM 结构设计的角度介绍 RocksDB 以及 CRDB 中跟 LSM 相关的操作。
TIPS:
以下内容基于 CockroachDB v2.0.3版本,集成的 RocksDB 版本为 v5.13.4。
LSM Overview

LSM-Tree,全称为 log-structured merge-tree,是为了满足日益增长的数据量所带来的高效写性能的需求而提出的设计。考虑到磁盘随机写和顺序写上千倍的性能差距,传统的Btree 结构设计采取的分散的 update-in-place 策略在数据量庞大、写缓存作用有限的情况下,存在大批量的随机写操作,使得写性能完全满足不了新数据的业务需求。为了提高写速率,LSM-Tree 采取的简单高效的日志结构的设计,将所有写操作的结果先缓存在内存并按次序分批写入硬盘,在底层管理多个版本的数据内容。理所当然地,不管是在点查还是范围查询的场景下,简单的日志结构会使得读的性能不高。因此为了提高读的性能,适当地保持系统内一定的有序性,引入排序开销是有必要的,即采取 LSM 里的 Merge 操作。此外在日志的基础上也可以添加额外的索引结构,例如 Bloomfilter 或者块索引设计。缓存友好的索引结构能够有效降低 IO 次数,快速定位到查询的数据具体的位置。
在 LSM 结构设计当中,数据按写入顺序拆分成多个批次的数据集合,包括了内存中的Memtable 和硬盘上的 SSTable。具体地,数据插入到 Memtable 当中,在 MemTable 大小超过一定阈值后进行 Flush 操作,变成不可修改的、内部有序的 SSTable。SSTable 在后台根据一定的层次结构进行组织。如下图是一个典型的多个 Level 的层次设计,Level-0 对应多个 Memtable,Level-1 对应 Flush 到硬盘上的多个相互之间无序的 SSTable,Level-2 对应一个有序的大 SSTable。
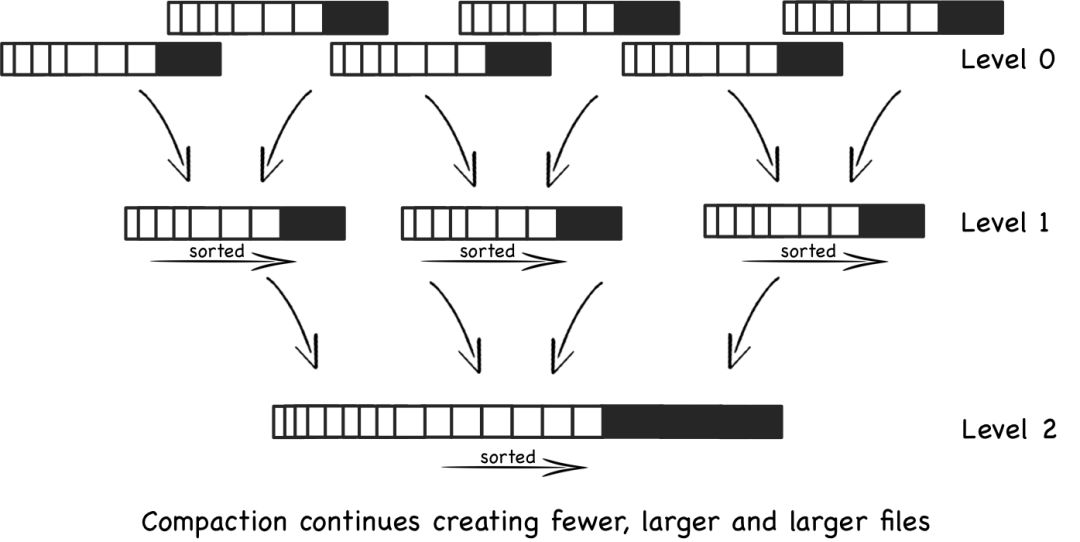
图片来自参考资料[1]
在适当的条件下后台会触发 Merge 操作,合并多个旧 SSTable 成新的 SSTable。合并的目的是为了减少文件数量,提高读的性能,此外也能够进行垃圾回收,减少多版本数据占用的空间大小。值得注意的是,后台 Merge 可能是一个特别影响前台读、写性能的操作。若系统对读要求越高,即对有序性要求越严格,往往需要更加积极的 Merge 操作,也往往会导致更剧烈的写放大,对系统整体而言累积下来的负担是更大的。
在LSM结构设计中所有的写操作都将是顺序写,换来的代价:
读放大:查询一个 Key 值所对应的 Value 值,可能需要遍历多个 SSTable 文件,对应了复数次随机 IO。
空间放大:多版本数据在合并之前会占用更多的存储空间。
写放大:在系统稳定后硬盘写数据的累积值 数据第一次写入硬盘的大小,该比值在LevelDB 或 RocksDB 中可达两位数。
总结来说,LSM结构设计能够提供非常好的写性能,在读方面需要结合业务特性,通过合理的层次结构设计以及索引结构控制负面影响,能够使得读性能达到业务能够接受的范畴。
目前随着固态硬盘的普及,不同于传统Btree结构在大量随机写情况下可能导致FTL层繁重的垃圾回收负载,LSM 的日志结构设计对于固态硬盘天然的友好性以及较为简单的设计模式,使其受到了很多存储引擎开发者的青睐。然而后台排序导致的写放大对于寿命有限的固态盘来说,是 LSM 中备受关注的痛点,近年来也有不少关于 LSM 在 SSD 上深度优化的相关研究。
LSM in RocksDB
RocksDB 是 Facebook 公司基于 LevelDB 开发的一款使用日志结构的开源嵌入式数据库引擎。在 LevelDB 基础上,RocksDB 在硬件上针对多核 CPU 和 SSD 设备在底层做了优化,在软件上在 Single-Writer 的锁处理、LSM 组织结构、DB锁的处理等方面进行了一系列改进,同时提供了更加丰富的功能特性,例如数据压缩、多线程 Compaction、前缀BloomFilter、列簇等。
RocksDB 默认使用了 kCompactionStyleLevel 类型的 Compaction 形式,有利于提高 Compaction 的并行度。文件组织形式如下图,在硬盘上管理 L0 到 Ln 层的 SSTable 文件。除开 L0 层,其他层的每一层,层内所有 SSTable 文件相互之间 Key 值范围是不重叠的,整体在逻辑上可以形成一个有序的 KV序列。在这种层次结构设计中,Memtable 会首先 Flush 到 L0 层成为不可修改的 SSTable 文件,当 L0 层文件数量超过了某个阈值将会触发 L0 到 L1 层的 Compaction,同理 Ln 层(n>0)的文件内容足够多的时候也将 Compaction 到 Ln+1 层,数据不断下沉直到最后一层。
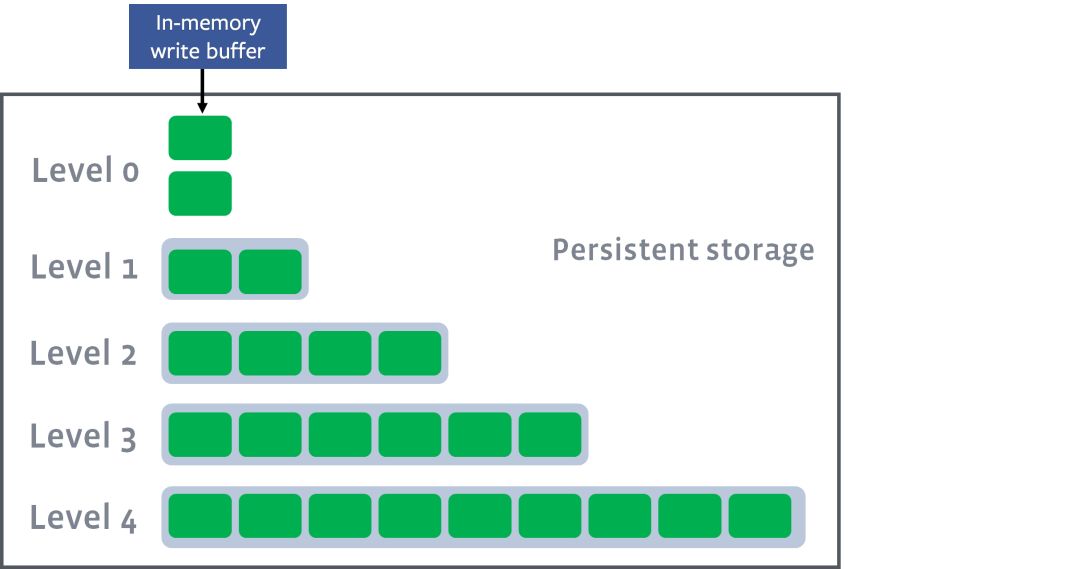
图片来自参考资料[5]
LSM构成元素
具体到 RocksDB 中的 LSM,有3个比较重要的构成元素:
版本管理
Version:对应了 RocksDB 在某个时刻点下组成层次结构的一组 SSTable 文件的所有元信息。Version 之间组成链表,通过 VersionEdit 记录相邻节点之间文件变动的情况。
VersionSet:维护所有列簇的 Version 链表,持久化到
.mainfest
文件。此外还提供了 LevelIterator 创建、Compaction 触发相关的接口。SuperVersion:由当前 Memtable、immutable Memtable 列表和 Version 构成,描述一个列簇在某个时刻点下的所有版本信息。
Memtable
RocksDB 存在一个 Active 状态的 Memtable 和多个 Immutable 状态 Memtable,默认的数据结构类型为 Skiplist 类型。Skiplist 能够提供对数级的插入/删除/查询性能,在并发上使用 CAS 实现了无锁操作,适合高并发的混合负载,性能表现优异。
SSTable
全称为 Sorted-String-Table,RocksDB 默认使用 BlockBasedTable 类型的 SSTable,对应由一系列存储块构成的物理文件。如下图,存储块根据数据内容可以分为数据块、BloomFilter 数据块、Table 属性块、范围删除块、索引块、元索引块等,额外的 Footer 结构是固定模式的、能够帮助解析文件结构的元信息。
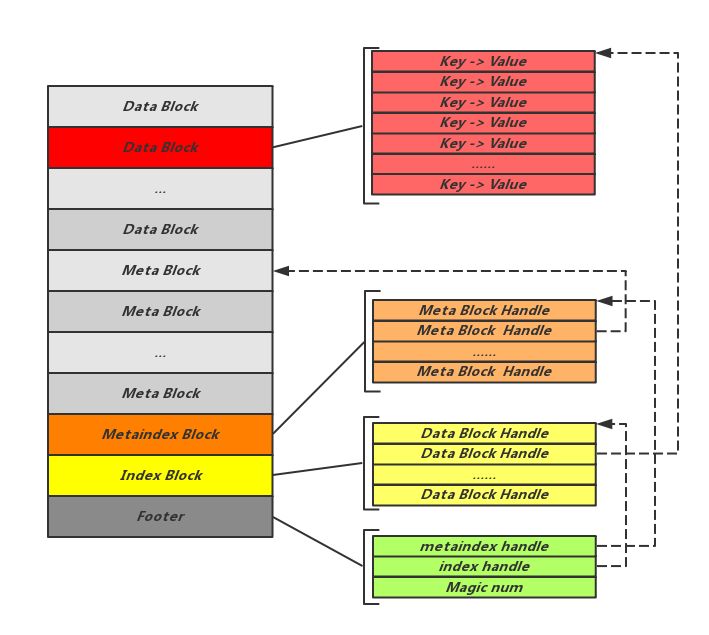
图片来自参考资料[6]
行为
除了人工触发的 Compaction(对应 Merge 操作)和 Flush 操作,RocksDB 会适时地在 Env 对象的线程池中注册后台 Compaction 或 Flush 任务,管理 LSM 层级结构。
Compaction 任务
后台 Compaction 任务触发时机包括了硬盘 SSTable 文件变动、数据库开启、配置修改、快照释放等情况。
默认配置下,一个简单的 Compaction 任务涉及到如下流程:
构造 Compaction 对象:在默认配置下,RocksDB 获取当前时刻的 Version 信息,计算每层 Level 的分数并倒序排序,按排序结果选择一个 Level(记为 Ln )中优先级最高的一个 SSTable 文件作为 Compaction 的种子文件;再根据种子文件的 Key 值范围获取其他“范围重叠”的 Ln 和 Ln+1 层的相关 SSTable 文件,组成一次 Compaction 的所有输入文件,在构造 Compaction 的同时锁住输入文件避免文件变动。
构造 CompactionJob 对象:封装 Compaction 对象、Env 对象、Version 对象、输出目录等内容信息。
CompactionJob.Prepare():视条件可能创建多个 SubCompaction,尽可能地切分输入文件的 Key 值范围到每个 SubCompaction。SubCompaction 设计用于提高L0 到 L1 层大 Compaction 的并行度,加速 Compaction 进行。
CompactionJob.Run():一个 SubCompaction 开启一个线程,并行执行 Compaction 任务。每个线程将根据输入文件和其他配置信息创建 CompactionIterator 对象。该迭代器合并多版本数据,输出有序的结果,存储到 Ln+1 层的新文件。
CompactionJob.Install():更新并持久化 Version 信息,同时收集 Compaction 相关的日志信息。
更新 SuperVersion 并尝试注册新的 Compaction 或 Flush 后台任务。
解锁文件,并尝试清理旧文件。
实际上 RocksDB 中 Compaction 设计涉及到了很多细节内容,例如无 Ln+1层输入文件的Compaction 在条件允许的情况下会转换为 Move 操作而不需要读取文件内容;针对 L0 到 L1 的 Compaction 不足以及时消化 L0 层 SSTable 文件的情况,RocksDB 会发起 IntraL0Compaction 来减少 L0 层文件数量,减轻 L0 层读放大。
感兴趣的同学可以查阅 Github Wiki 相关内容。相关 LSM 调优参数介绍可以查看 Wiki 以及c-deps/rocksdb/include/rocksdb/option.h
文件的注释内容。
Flush任务
后台 Flush 任务触发时机为 active 状态的 Memtable 超过阈值大小后切换为 Immutable 状态的时候。
默认配置下,一个简单的 Flush 任务涉及到如下流程:
构造FlushJob对象,并获取需要Flush到硬盘的、Immutable状态的 Memtable。
FlushJob.Run():将 Immutable Memtable 输出为L0层文件,更新并持久化 Version 信息。
更新 SuperVersion 并尝试注册新的 Compaction 或 Flush 后台任务:在析构旧 SuperVersion时清理引用计数为0的 Immutable Memtable。
CRDB with LSM
CRDB 底层集成了 RocksDB 作为后端存储引擎,跟 RocksDB LSM 相关的接口包括了RocksDB 结构体中实现的 Compact()、CompactRange()和Flush(),其中Compact()和Flush() 为未使用的保留接口。CompactRange 方法根据指定的 begin 和 end,直接调用RocksDB 中定义的 CompactRange 方法,在底层属于手动触发的 Compaction 操作。
ClearRange方法
具体地,CRDB 在 Range Rebalance、表删除、表清空等场景下调用 ClearRange 操作,向底层 RocksDB 存储引擎插入范围删除的记录,随后将该 Range 的 Key 值范围加入到当前Store维护的 SuggestedCompactions 列表当中。当列表内容足够多或定时器触发了任务的时候,CRDB 根据 SSTable 文件的 Key 值范围尝试合并列表中“相邻”区间,再为 SuggestedCompactions 列表中每一个足够大的SuggestedCompaction(默认情况下阈值为256MiB数据大小)调用 CompactRange 操作,以便及时回收 Store 空间。
在 RocksDB 底层,CompactRange方法可能触发跟指定 Key 值范围相关的 Memtable 的强制 Flush 操作,然后获取该 Key 值区间内相关的所有 SSTable 文件作为输入文件,创建Compaction 对象。随后 RocksDB 在 Env 对象的线程池中注册带指定 Compaction 对象的后台 Compaction 任务,异步执行与普通的后台 Compaction 任务类似的流程。
TIPS:
CRDB 集成的 RocksDB,其默认的参数配置大部分在代码中明确定义,对应源码目录c-deps/libroach/options.cc
文件。如果需要更多关于 LSM 的参数调优,可以通过cockroach $subcmd $otherFlags --store="$otherAttrs,rocksdb=key1=value1;key2=value2"
指定,需要开发人员具备一定的背景知识。
指标监控
在 CRDB 的 Admin 界面中存在跟 RocksDB LSM 管理行为相关的指标监控,用户可以监控这些指标数值检测 CRDB 中指定节点或整个集群节点的 LSM 性能表现。
具体地,用户可以 Storage 仪表盘中查看读放大、SSTable 文件数量等监控信息(详见参考资料[9]),也可以在 Custom Chart 页中定制图表(详见参考资料[10]),指定一组监控指标,包括但不限于:
rocksdb.compactionscompactor.compactingnanoscompactor.compactions.failurecompactor.compactions.successcompactor.suggestionbytes.compactedcompactor.suggestionbytes.queuedcompactor.suggestionbytes.skipped
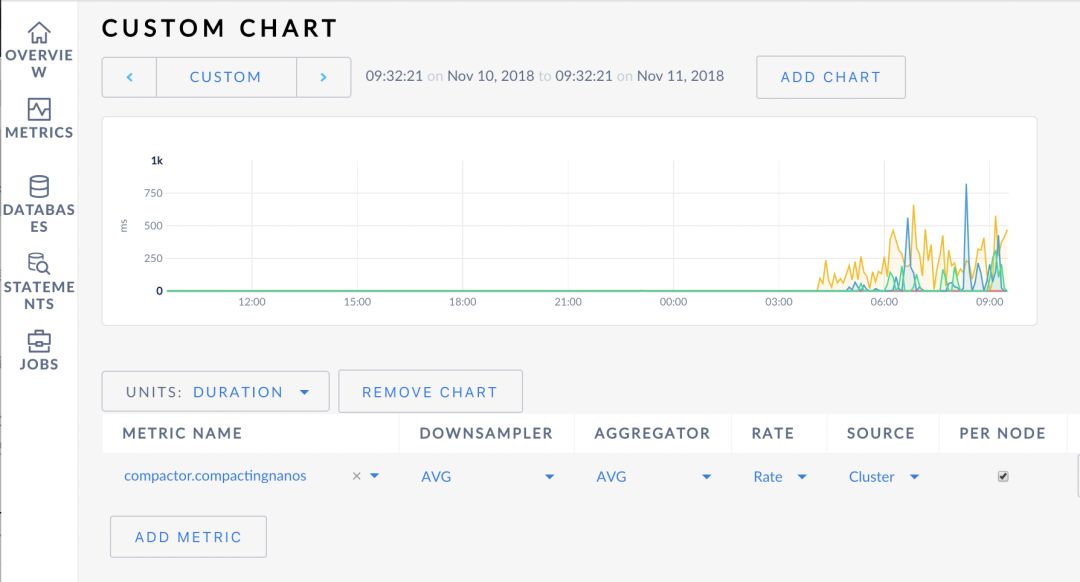
监控示例图:反映集群各个节点在每个采样周期内RangeCompaction的耗时情况
结语
在本文中,我们在第一章介绍了 LSM-tree 的基本概念以及其与生俱来的优缺点。在第二章讲解了 RocksDB 中具体到 LSM 设计的构成元素与管理行为。第三章则讲解了 CRDB 中跟LSM 相关的操作以及触发操作的时机。
后续存储引擎相关的文章将从增(改)、删、查、文件操作四个方面进一步地介绍 CRDB 中的 RocksDB。
参考资料:
[1] https://en.wikipedia.org/wiki/Log-structured_merge-tree
[2] http://www.benstopford.com/2015/02/14/log-structured-merge-trees/
[3] http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.44.2782&rep=rep1&type=pdf
[4] https://github.com/facebook/rocksdb
[5] https://github.com/facebook/rocksdb/wiki/Leveled-Compaction
[6] http://catkang.github.io/2017/01/17/leveldb-data.html
[7] https://github.com/cockroachdb/cockroach
[8] https://github.com/cockroachdb/cockroach/pull/20607
[9] 英文文档P1:https://www.cockroachlabs.com/docs/stable/admin-ui-storage-dashboard.html
[10] 英文文档P2:https://www.cockroachlabs.com/docs/stable/admin-ui-custom-chart-debug-page.html#available-metrics
[11] 中文文档:http://doc.cockroachchina.baidu.com/
关于我们:我们是百度DBA团队,团队有两位CockroachDB PMC Member及一位Contributor, 目前正积极推动NewSQL在百度内部以及外部的发展。除了NewSQL, 我们在MySQL, PostgreSQL, GreenPlum有多年的内核开发经验及实践经验,对数据库和大数据领域有疑问或者需求欢迎联系我们,同时欢迎有志青年加入我们!
关注我们

