




RocksDB是Facebook公司基于LevelDB开发的一款使用日志结构的开源嵌入式数据库引擎,以读写放大和空间放大为代价换取高效的写性能,主要适合写多读少的应用场景。在LevelDB基础上,RocksDB在硬件上针对多核CPU和SSD设备在底层做了优化,在软件上在Single-Writer的锁处理、LSM组织结构、DB锁的处理等方面进行了一系列改进,同时提供了更加丰富的功能特性,例如数据压缩、多线程Compaction、前缀BloomFilter、列簇等。
RocksDB作为一款流行的嵌入式存储引擎,其本身和相关联的产品被国内外各大互联网公司广泛应用于生产系统当中,包括百度、阿里、腾讯、头条、Yahoo和Linkedin等公司。同时,不少主流的数据库也将RocksDB改造成可选的存储引擎,例如MyRocks in MySQL、Cassandra on Rocks、MongoRocks等。
CockroachDB(简称CRDB)是一款开源、可伸缩、跨地域复制且兼容事务的 ACID 特性的分布式数据库,能够承载PB级别的数据量,其底层集成了RocksDB作为后端存储引擎。在每个Cockroach进程的每个Store上运行着一个DB实例,在SQL-KV转换模型的基础上统一管理数据库数据。
本文以迭代器作为切入点,将从CRDB如何集成RocksDB、RocksDB内部迭代器的作用和实现以及CRDB如何封装并使用RocksDB迭代器三个方面介绍CRDB当中的RocksDB迭代器使用方式 。
TIPS:
以下内容基于CockroachDB v2.0.3版本,集成的RocksDB版本为v5.13.4。
RocksDB in CRDB

CRDB使用Go语言编写程序,内部集成的RocksDB采用了C++版本,两者通过CGO框架进行混合编程。
封装RocksDB底层操作的接口主要在engine.go当中声明,相关的结构体则集中在rocksdb.go声明与实现。结构体实现了engine.go当中对应的接口,结构体内部通过CGO调用libroach.h定义的C函数接口和数据结构。CRDB的MVCC多版本控制、备份恢复、Range操作等其他模块则根据实际功能需求通过rocksdb.go向上提供的函数与底层RocksDB进行数据交互,或进行二次封装向上提供给其他模块使用。
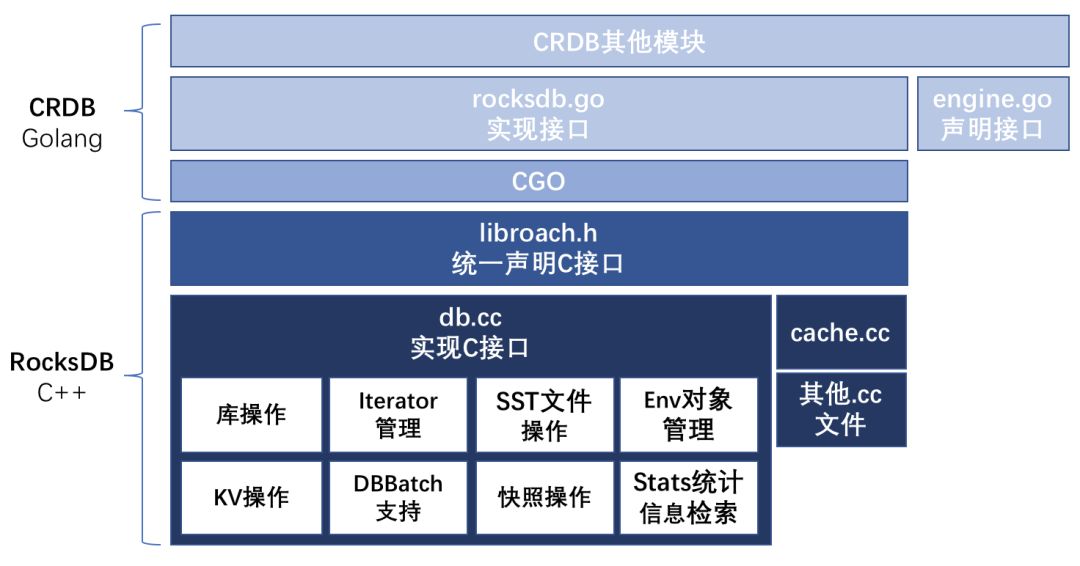
如上图,libroach.h中定义的C函数接口绝大部分在db.cc文件当中实现,按功能模块可划分成库操作、KV操作、DBBatch支持、Iterator管理、快照操作、SST文件操作、Env对象管理和Stats统计信息检索等。
下面我们将重点介绍RocksDB当中迭代器的设计和作用。
Iterators in RocksDB
本章描述的Iterators为RocksDB的迭代器,它允许用户以一种有条理的方式顺序或是倒序访问数据库,用户创建的迭代器为ArenaWrappedIterator,内部封装了Iterator的子类DBIter的对象。
DBIter类的成员变量iter_是由一系列继承自InternalIterator类的、嵌套的内部迭代器构成的组合迭代器。通过Github提交日志可知,InternalIterator类是开发者出于后续优化的考虑从Iterator类剥离,大部分函数接口拷贝自Iterator类,两者均为Cleanable类的子类。其中一个不同点在于InternalIterator使用的Key值是在Iterator传递的Key值基础上附加了sequenceNumber和type属性,方便数据库内部对数据进行多版本管理。
Iterator主要接口
迭代器正向遍历主要使用Seek()、Valid()、Key()、Value()、Next()接口。
Seek()函数查找大于或等于指定key值的第一个键值对的位置;
Valid()判断该位置是否存在有效的键值对;
Key()和Value()获取该位置的键与值;
Next()用于将迭代器当前位置向后移动一个单位。
主要内部迭代器
CRDB底层数据存储结构和数据处理逻辑多样,为此实现了多层内部迭代器用于不同场景。统一的内部迭代器接口(InternalIterator接口)能够为不同的遍历需求提供统一的访问方式,屏蔽迭代器内部复杂多样的实现细节。本小节将讲解主要的内部迭代器及其层次结构。
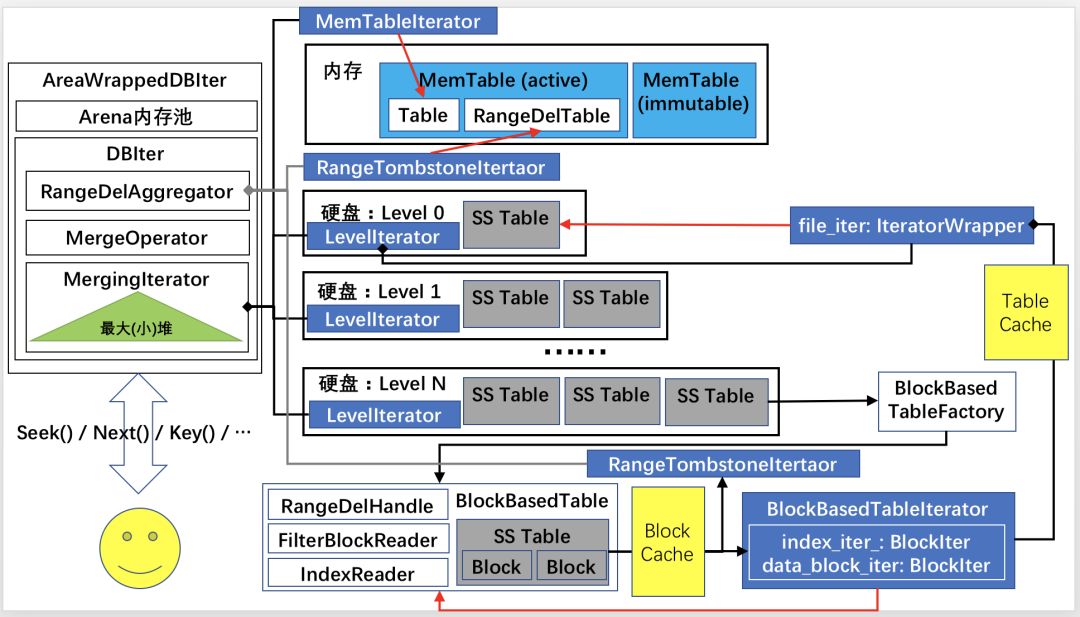
如上图,用户在RocksDB创建了AreaWrappedDBIter迭代器,执行Seek()、Next()、Key()等方法处理键值对数据。以下将由外到里展示内部迭代器的层次结构:
AreaWrappedDBIter:主要封装DBIter的访问接口,以及在创建迭代器过程当中用于内存申请的Arena内存池。
DBIter:默认情况下封装MergingIterator对象,同时在内部迭代器的基础上进行多版本键值对的Merge、范围删除等功能特性的逻辑。
MergingIterator:根据迭代器遍历的方向(kForward kReverse)管理由子迭代器构成的最小堆或是最大堆,实现子迭代器对应的有序序列的数据的归并操作。其子迭代器主要包括MemTableIterator和LevelIterator。MemTableIterator用于遍历内存中active或immutable状态的MemTable,LevelIterator用于遍历在硬盘上SSTable分层结构中每一层对应的逻辑上的有序序列。
MemTableIterator:封装MemTable插入的键值对的遍历逻辑,根据MemTable的类型(skiplist、hashskiplist或是vector等)其数据处理逻辑不一样。
LevelIterator:对应硬盘SSTable分层结构中的一层,每一层可以有若干个键值范围前后有序的SSTable文件。LevelIterator拥有一个IteratorWrapper对象,指向需要查看的SSTable文件的Table迭代器。在遍历的过程中,LevelIterator根据SSTable文件所包含的键的值范围,确定查找键所在的某个SSTable文件,通过TableFactory创建该SSTable文件对象TableReader。该对象能够缓存在TableCache当中,在需要遍历SSTable的时候生成对应的TableIterator。
在默认的情况下,RocksDB底层使用BlockBasedTable类型的SSTable文件组织形式,此时TableReader具体为BlockBasedTable,对应TableIterator为BlockBasedTableIterator。BlockBasedTable类型的SSTable文件的文件对象,管理由一系列存储块(即图中的Block)构成的物理文件。存储块根据数据内容可以分为数据块、BloomFilter数据块、Table属性块、范围删除块、索引块等,均使用BlockIter进行查找。根据数据内容的不同,BlockBasedTable拥有若干类型的Reader对象,实现不同数据内容更多丰富的处理逻辑。例如,在BlockBasedTable初始化时,默认使用的BinarySearchIndexReader会读取索引块,初始化index_iter_对象。该对象能够帮助定位指定键对应的数据在哪个数据块,并基于该数据块初始化data_block_iter对象。
BlockBasedTableIterator:由BlockBasedTable创建的Table迭代器,可以通过索引迭代器index_iter_定位指定键所在的数据块,并使用该数据块初始化BlockIter。
BlockIter:该迭代器将以固定的模式反序列化二进制数据,以前缀查找、二分查找或是顺序查找的方式进行从数据区内查找出指定的键值对。具体地,Block底层在块末存储int32类型的RestartPoint数组,通过该定长数组,可以查找出数据区指定的键值对的具体偏移量,读取该偏移量下不定长的二进制数据,反序列化成可比较的键与值。
特别地,SSTable文件当中范围删除块和MemTable当中的RangeDelTable结构,存储的是范围删除(RangeDelete)的元数据,必要时将基于这些数据创建RangeTombstoneIterator对象。DBIter会遍历并集中管理RangeTombstoneIterator的元数据,并在DBIter的内部对外过滤掉被删除的键值对。
Seek方法
默认情况下AreaWrappedDBIter的Seek处理流程如下图所示。
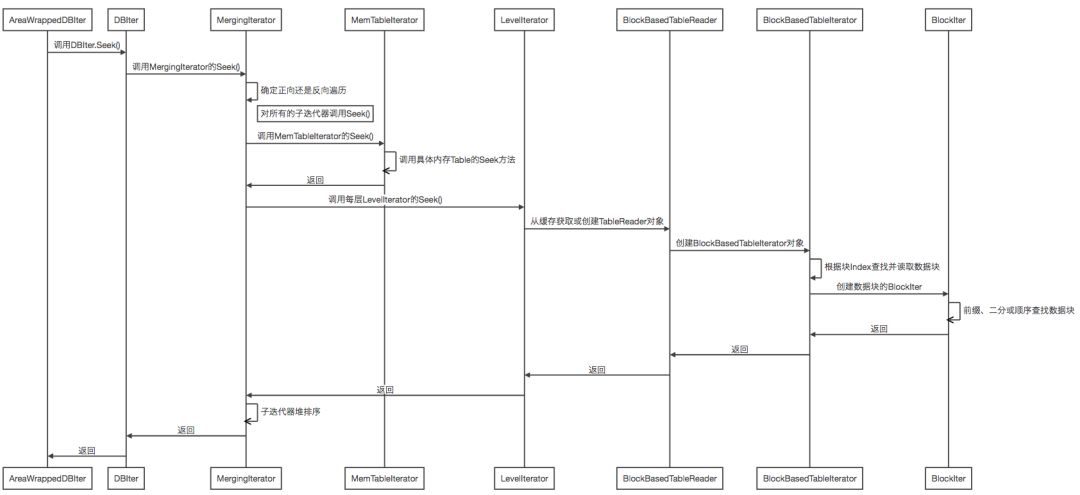
如图:
ArenaWrapperDBIter调用DBIter的Seek方法;
DBIter默认情况下封装MergingIterator,在Key值的基础上附加sequenceNumber和type属性,转换成内部Key,再通过内部Key调用MergingIterator的Seek方法;
MergingIterator首先会判断遍历的方向,正向遍历(默认)的时候创建最小堆,在反向遍历的时候创建最大堆,堆的元素为所有的子迭代器(包括MemTableIterator和LevelIterator)。为方便后续的遍历过程,对于每个子迭代器都会进行Seek操作,以便通过堆排序合并子迭代器有序的输出结果。
MemTableIterator执行的Seek方法根据MemTable的数据结构类型的不同而不同,默认情况下为SkipListRep类型,对跳表自顶向下搜索。
LevelIterator在执行Seek方法时,根据该层的元数据中每个文件的Key值范围,查找出指定键的对应SSTable文件,从TableCache中获取或重新创建该SSTable的TableReader对象并创建相应的Table迭代器,并调用迭代器的Seek方法。默认情况下该Table迭代器为BlockBasedTableIterator。
BlockBasedTableIterator,在执行Seek方法时首先查找索引迭代器index_iter_,确定指定键在哪个数据块。再从BlockCache中获取或重新创建该数据块的BlockIter对象,调用数据块的BlockIter的Seek方法。
数据块的BlockIter在执行Seek方法时,根据RestartPoint数组查找到数据区中指定的键值对的具体偏移量,记录为起始偏移量,反序列化出有效的出键值对并缓存在内部属性key_和value_中。
Iterators in CRDB
本章描述的Iterators为CRDB的迭代器。上文已经提到,engine.go声明了CRDB与底层RocksDB进行数据交互的接口,其中就包括迭代器接口。
迭代器接口与相关结构体
此处简单介绍engine.go和rocksdb.go当中基本的接口和结构体。
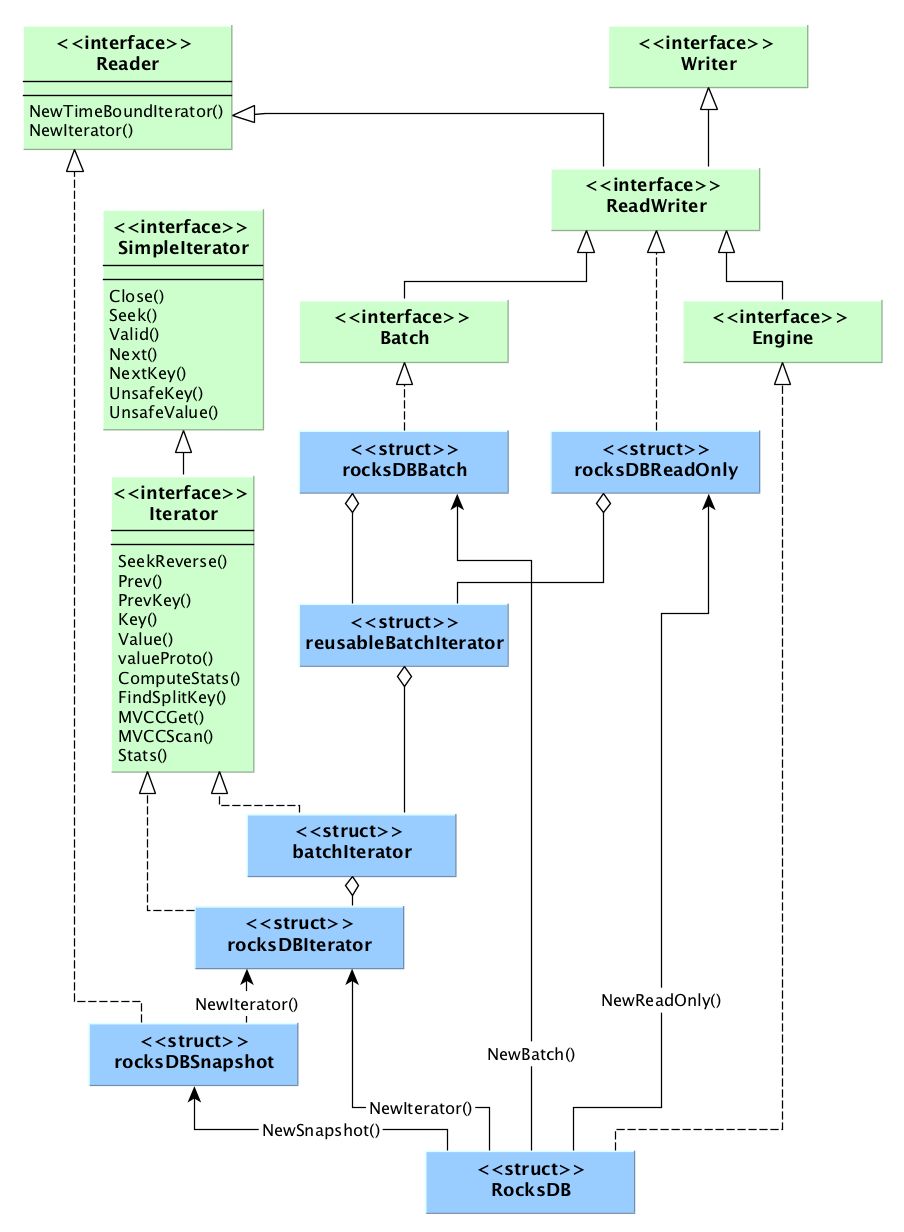
在上面类图当中,绿色为engine.go声明的接口:
Reader,涉及RocksDB读数据的相关方法,例如Get、创建迭代器和Scan等。
Writer,涉及RocksDB修改数据的相关方法,例如Put、Clear和Merge等。
ReadWriter,嵌套组合了Reader和Writer接口。
Batch,嵌套了ReadWriter接口,涉及批量处理写操作的相关方法。
Engine,嵌套了ReadWriter接口,涉及DB操作的大部分方法,例如手动触发memtableFlush、手动触发Compaction、创建其他结构体、文件操作、获取RocksDB统计信息等。
蓝色为rocksdb.go定义的结构体:
RocksDB,实现Engine接口,调用C接口实现CRDB操作底层RocksDB的主要逻辑。
rocksDBReadOnly,RocksDB的NewReadOnly方法创建出的只读DB对象,屏蔽了相关的写操作。
rocksDBSnapshot,提供底层RocksDB创建的快照的读操作和删除操作。
rocksDBBatch,用于缓存写操作,最终提交,批量执行。
RocksDBSstFileReader和RocksDBSstFileWriter,用于RocksDB对文件直接操作,例如创建SST文件并ingest到RocksDB SST文件层级结构当中。
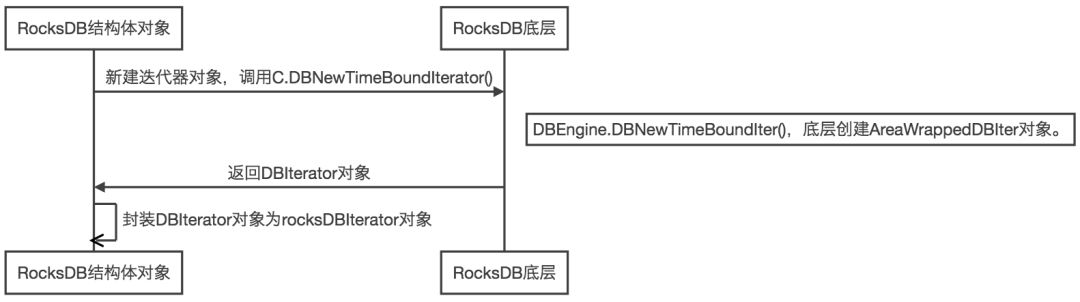
由上可知,继承了Reader接口的结构体,能够实现NewIterator或NewTimeBoundIterator接口,调用底层RocksDB方法创建普通迭代器Iterator和带有时间戳范围作为过滤条件的TimeBoundIterator。
MORE:
TimeBoundIterator底层是在普通迭代器的基础上,附加了TableFilter和用户自定义Table属性收集器。MemTable持久化成SSTable时统计所有键值对的时间戳,记录在Table属性中并持久化到Table属性块。在LevelIterator创建SSTable对应TableIterator前,TableReader通过Table属性记录的时间戳范围,过滤掉时间戳范围不重叠的SSTable。
迭代器创建时序图
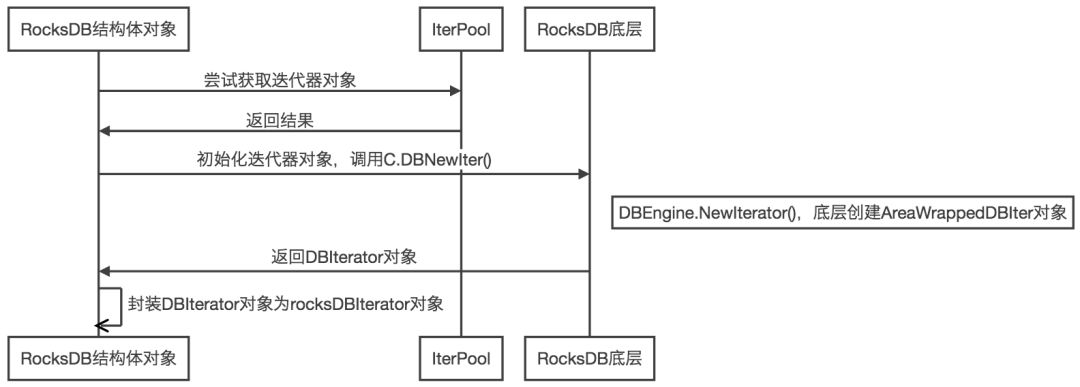
以RocksDB结构体对象创建rocksDBIterator为例:
普通迭代器,由newRocksDBIterator方法创建。
带时间戳过滤的迭代器,由NewTimeBoundIterator方法创建。
结 语
本文介绍CRDB底层如何集成RocksDB,如何封装RocksDB的迭代器向上提供底层数据交互功能,并着重介绍了基于RocksDB迭代器为处理逻辑多样数据而实现的不同内部迭代器,实现不同层次上的数据不同的遍历方式,应对复杂多样的内部场景。它们构成一定的层级结构,为RocksDB的可读、代码运维和结构拓展提供了便捷。
参考资料:
https://github.com/cockroachdb/cockroach
https://github.com/facebook/rocksdb
http://catkang.github.io/2017/02/12/leveldb-iterator.html
http://kernelmaker.github.io/Rocksdb_Iterator
关于我们:我们是百度DBA团队,团队有两位CockroachDB PMC Member及一位Contributor, 目前正积极推动NewSQL在百度内部以及外部的发展。除了NewSQL, 我们在MySQL, PostgreSQL, GreenPlum有多年的内核开发经验及实践经验,对数据库和大数据领域有疑问或者需求欢迎联系我们,同时欢迎有志青年加入我们!
关注我们

