




基本语法介绍

CockroachDB是一个分布式关系型数据库,除了兼容PostgreSQL语法规则之外,还有自己的语法规则。本篇文章小编将重点介绍CockroachDB中语法的重要组成部分:关键字、标识符、常量、操作符、函数。
关键字
SQL的词汇表由关键字组成,且关键字在语句中有特定的含义。CockroachDB支持的SQL关键字分为以下四类:
保留关键字(具体可参考:http://suo.im/121m7S )
类型函数名称关键字
列名称关键字
未保留关键字
保留关键字具有固定的含义,通常不允许作为标识符。其他类型的关键字都被视为是非保留的;它们在特定的环境中有特定的含义,可以用作其他环境中的标识符。
标识符
在SQL语法中,所有标识符都必须遵循以下规则:
以Unicode字母或下划线(_)开头。后续字符可以是字母、下划线、数字或美元符号($)
除非关键字被元素的语法接受,否则不等于任何SQL关键字。(例如name 为列名称的关键字,又是一个未保留的关键字)
若不想受上述规则限制,只需要用双引号“ ”来包裹标识符。
常量
SQL常量表示一个不会更改的简单值。
CockroachDB中有五类常量:
字符串常量:定义的字符串值,实际数据类型需要从上下文中推断出来,例如:”hello”
数字常量:定义数字值,实际数据类型需要从上下文中推断出来,例如:-12.3
字节数组常量:使用BYTES类型定义字节数组,例如:b’hello’
解释常量:用明确的类型定义任意值,例如: INTERVAL ‘3 days’
命名常量:命名常量具有预定义类型的预定义值,例如 TRUE 或NULL
操作符
操作符和具体用途参考如下表格:
操作符 | 描述 |
-(一元) | 负数 |
+(一元) | 正数 |
~(一元) | 64位进制补码 |
NOT(一元) | 布尔/逻辑否定 |
+ | 加 |
- | 减 |
* | 乘 |
/ | 除 |
// | 整数除法 |
% | 取模 |
& | 位与 |
` | ` |
^,# | 位异或 |
<< | 二进制左位移 |
>> | 二进制右位移 |
~ , !~ , ~* , !~* | 使用正则表达式匹配 |
< , > , <= , >= , <> , != , IS | 比较符 |
LIKE , ILIKE , SIMILAR TO | 字符串模式匹配 |
IN | 值在一个范围内 |
函数
CockroachDB存在着非常丰富的函数,有以下类型:
数组函数
比较函数
日期与时间函数
ID生成函数
数学与数值函数
字符串和字节函数
系统信息函数
兼容性函数
聚合函数
函数数量过多,这里只做一些简单的函数列举:
函数 -> 返回 | 描述 |
greatest(anyelement...) → anyelement | 返回具有最大值的元素 |
least(anyelement...) → anyelement | 返回具有最小值的元素 |
age(begin: timestamptz, end: timestamptz) → interval | 返回begin和end之间的时间间隔 |
age(val: timestamptz) → interval | 返回val时间到当前时间的间隔 |
clock_timestamp() → timestamp | 返回当前的时钟时间 |
current_date() → date | 返回当前日期 |
current_timestamp() → timestamp | 返回当前事务的时间戳 |
abs(val: decimal/float/int…) → decimal/….. | 返回val的绝对值 |
avg(arg: float/int/…) → float/int/… | 返回arg的平均值 |
concat_agg(arg: string/bytes) →string/bytes | 连接所有选中的值 |
count_rows() → int | 返回行数 |
sum(arg: int/…) → int/… | 返回所选值的总和 |
current_database() → string | 返回当前数据库 |
current_database() → string | 返回当前用户 |
version() → string | 返回该节点的CockroachDB版本 |
基本SQL语句
通过上面的介绍,我们已经大致了解了一些语法规则。下面我们由深到浅的梳理一下CockroachDB中的一些基本语句,这些语句基本包含了所有的日常操作。基本SQL语句的主要面对对象是零基础的用户,大家在看完以下语句介绍之后能够自主上手操作数据库。
创建一个数据库
CockroachDB附带一个默认system数据库,其中包含CockroachDB元数据并且是只读的。要创建一个新的数据库,请使用CREATE DATABASES后跟数据库名称:

数据库名称必须遵循一些规则。为避免数据库已存在的错误,可以使用IF NOT EXITSTS:

当不再需要这个数据库时,请使用DROP DATABASE后跟数据库名称来删除数据库及其所有对象:

显示数据库
要查看所有数据库,请使用SHOW DATABASES语句:

设置默认数据库
要设置默认数据库,请使用SET语句:

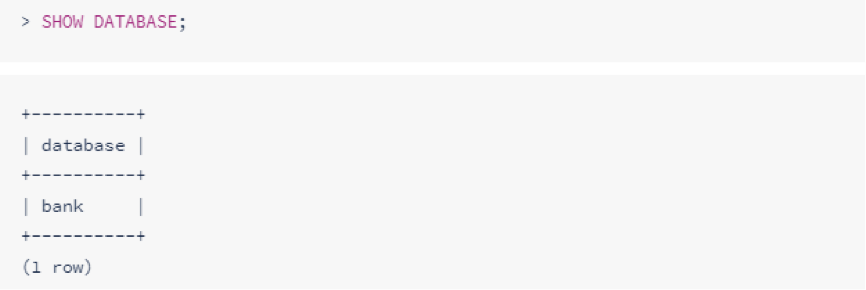
使用默认数据库时,不需要在语句中明确声明数据库。若要查看当前默认数据库是哪个数据库,需要使用SHOW DATABASE语句:
创建一个表
要创建一个表,使用CREATE TABLE后跟表名称,列名称以及每列的数据类型和约束(如果有):

表和列名称必须遵守一些规则。另外,当你没有明确定义主键时,CockroachDB会自动添加一个隐藏的rowid列作为主键。
如果表已经存在,为了避免错误,可以使用IF NOT EXISTS语句:

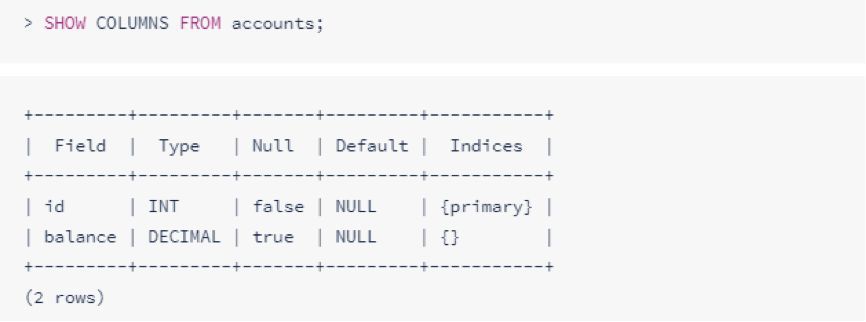
要显示表格中的所有列,请使用SHOW COLUMNS FROM后跟表格名称:
当不再需要表格时,使用DROP TABLE后跟表名称来删除表及其所有数据:

显示表格
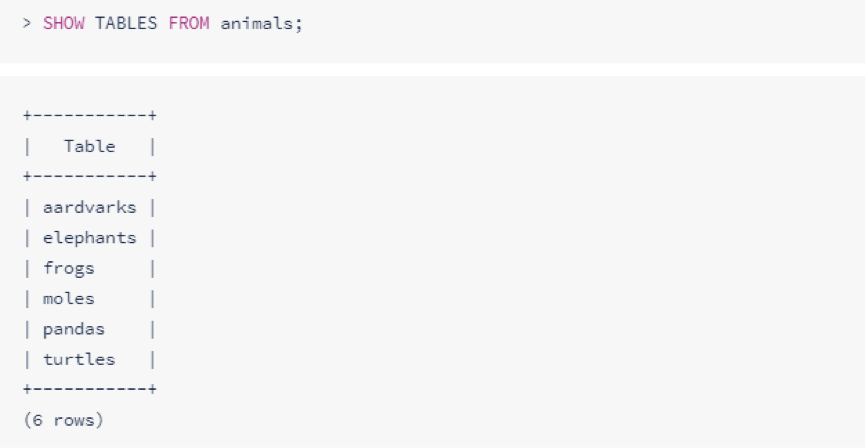
要查看已进入数据库中的所有表,请使用SHOW TABLES语句:

要查看未进入数据库中的所有表,请使用SHOW TABLES后跟数据库名称:
将行插入表格中
要将一行数据插入表中,请使用INSERT INTO后跟表名称,然后按照列顺序列出插入值:

如果要以不同顺序传递列值,请明确列出表的列名并按相应的顺序提供值:

要向表格中插入多行,请使用逗号分隔的括号列表,每个括号包含一行的值:

创建一个索引
索引有助于查找数据,数据查找时而无需查看表格的每一行。创建表时会自动为主键列和唯一约束列创建索引。要为非唯一列创建索引,请使用CREATE INDEX后跟索引名称和ON标识要创建索引的表和列。对于每一列索引,可以选择是按升序ASC或者降序DES进行排序。

也可以在创建表格时创建索引,只需要包含关键字INDEX,后跟可选的索引名称和要创建索引的列:

在表格上显示索引
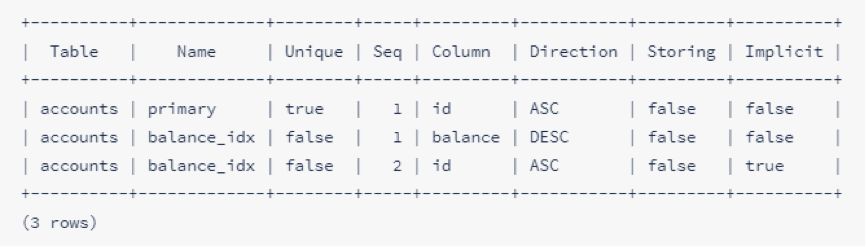
要在表格中显示索引,请使用SHOW INDEX FROM后跟表名称:

查询表格
要查询表格,请使用SELECT后跟要返回的列(多列使用逗号分隔)FROM检索数据的表:
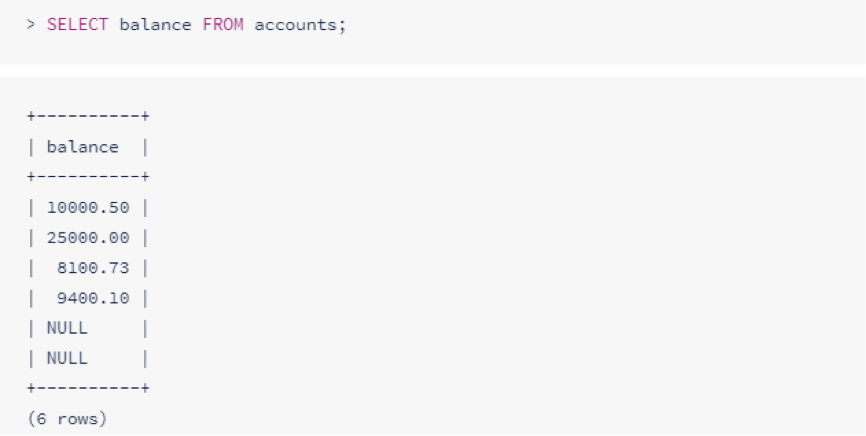
要检索所有列,请使用通配符(*):
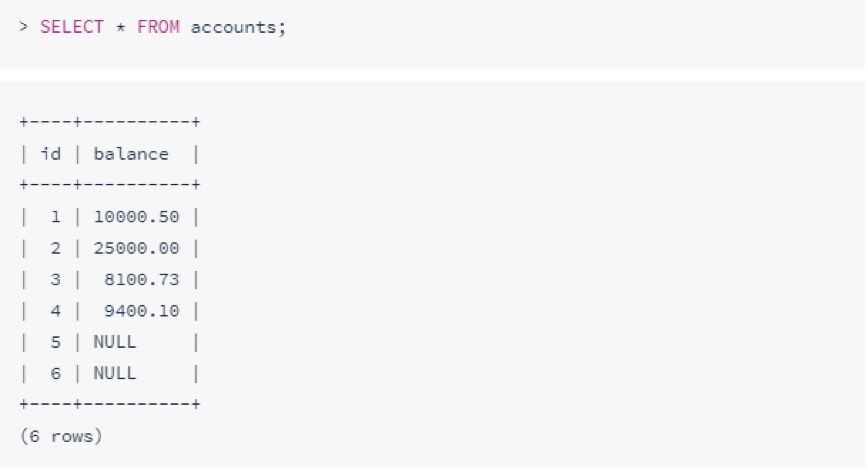
要过滤结果,请添加一个WHERE用于标识要过滤的列和值的字句:
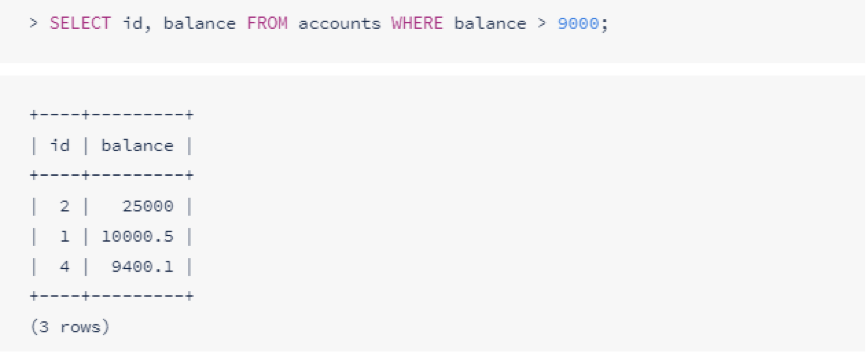
如果要对结果进行排序,请添加一个ORDER BY标识要排序的列。对于每一列,您可以选择按升序(ASC)或者降序(DESC)进行排序。
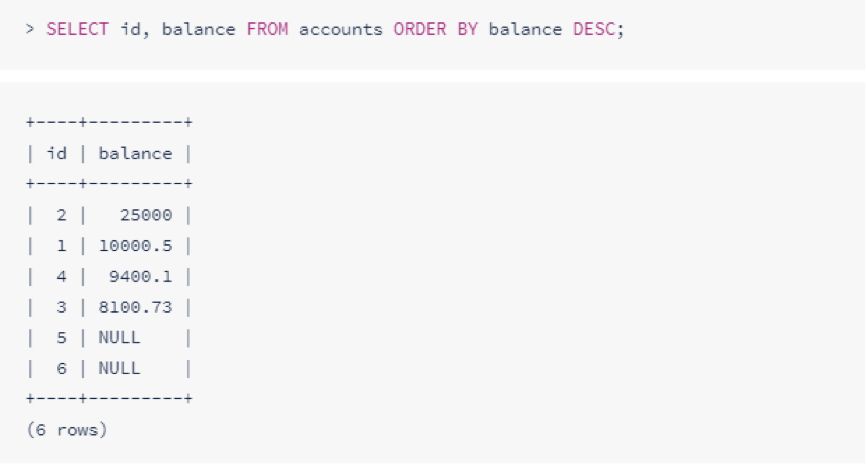
更新表中的行
要更新表中行的值,请使用UPDATE后跟表名,SET标识要更新的列字句及其更新值,以及可以用WHERE标识要更新的部分:
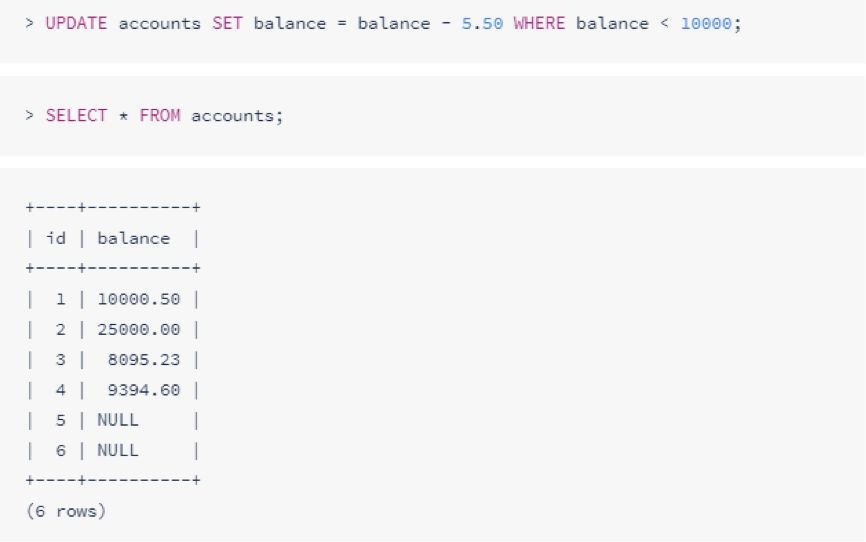
若没有使用WHERE,则每一行都会更新。
删除表中的行
要从表中删除行,请使用DELETE FROM后跟表名和WHERE标识要删除的行:
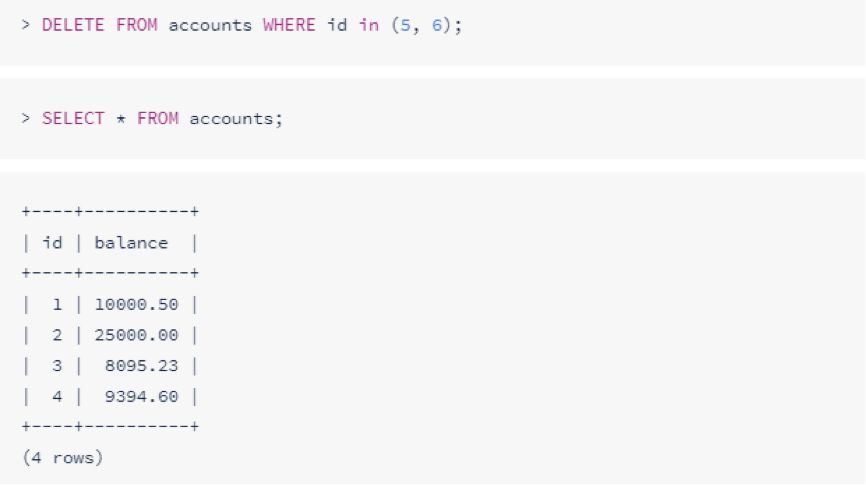
和UPDATE一样,没有WHERE标识将删除所有行。
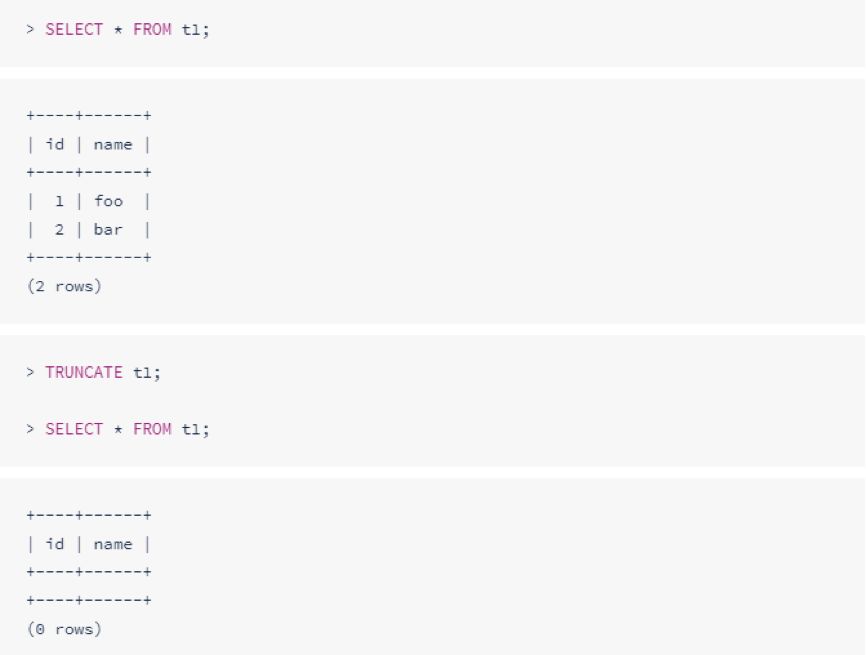
清空一个表
与DELETE不同的是,DELETE是一行一行的删除数据,TRUNCATE是直接清空一个表(在没有外键约束的情况下):
插入更新
插入更新不违反唯一键索引的行,和插入语句相似:
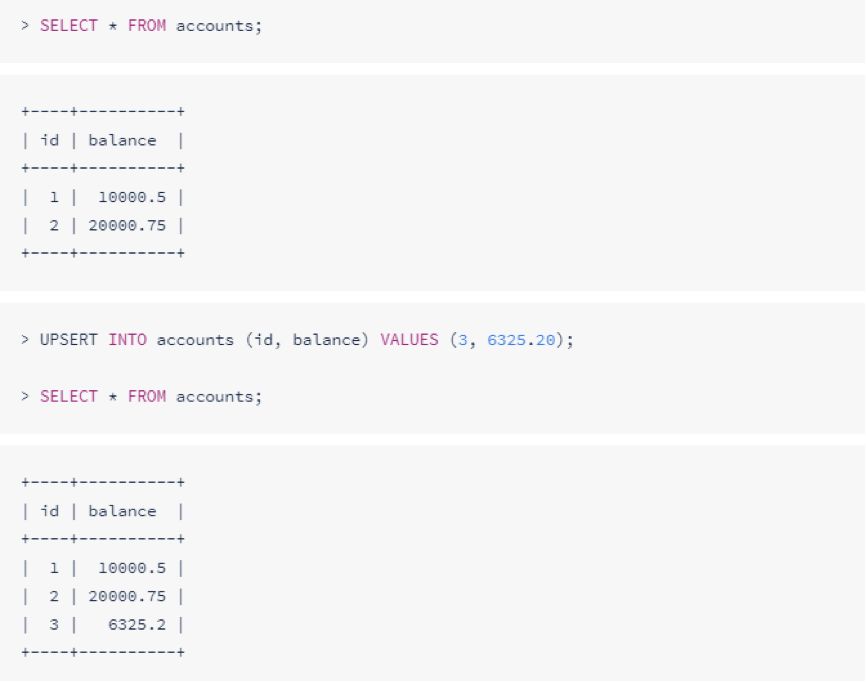
在插入的值存在但不被唯一性约束时,也能更新值:
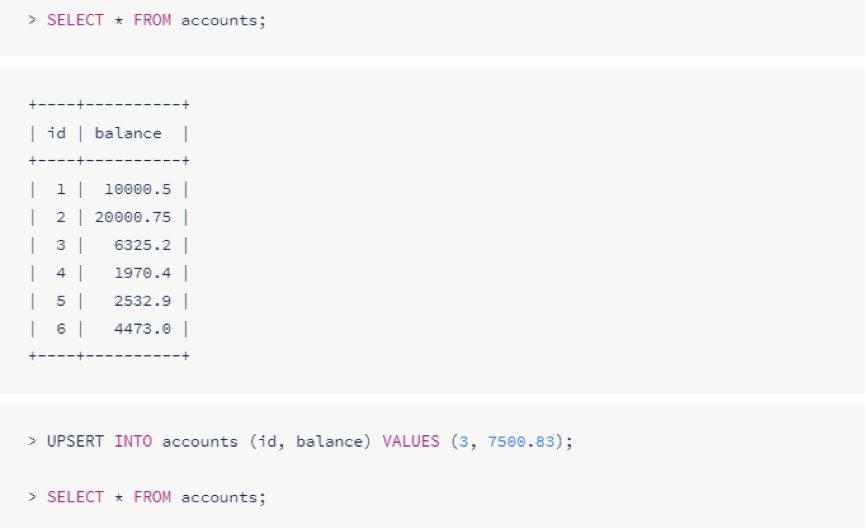

插入的值与唯一约束冲突时,将插入不成功。下面的例子中b的值具有唯一约束:

修改数据库/表/索引
修改数据库:
子命令 | 说明 | 例子 |
RENAME | 更改数据库名称 | ALTER DATABASE <旧库名> RENAME TO <新库名> |
修改数据表:
子命令 | 说明 | 例子 |
ADD COLUMN | 添加表的列 | ALTER TABLE <新列名> ADD COUMN <列声明语句> |
ADD CONSTRAINT | 添加约束到列 | ALTER TABLE <表名> ADD CONSTRAINT <索引名> <索引> |
ALTER COLUMN | 更改或删除列的约束 | ALTER TABLE <表名> ALTER COLUMN <列名> SET DEFAULT TRUE |
DROP COLUMN | 删除表的列 | ALTER TABLE <表名> DROP COLUMN <列名> |
DROP CONSTRAINT | 删除列的约束 | ALTER TABLE <表名> DROP CONSTRAINT <索引名> |
RENAME COLUMN | 更改列的名称 | ALTER TABLE <表名> RENAME COLUMN <列名> TO <新列名> |
RENAME TABLE | 更改表名称 | ALTER TABLE <表名> RENAME TO <新表名> |
查询计划
EXPLAIN语句用来查看一个语句的查询计划,可以用来分析语句所使用的索引和键:

上面的例子是默认的粒度。还可以更加细化查询的粒度,具体使用方法为:
EXPLAIN(Option…)(DELETE/ INSERT/SELECT/UPDATE statements)
Option具体有:
EXPRS—— 包含SQL表达式
METADATA—— 包含每个层次使用哪些列的详细信息及如何排序列
QUALIFY —— QUALIFY必须与EXPRS一起使用,它会用符号具体显示出是哪个表哪个列
VERBOSE—— 包含以上所有的选项,最详细的查询计划
TYPE——显示出查询计划中值的类型
SHOW TRACE
SHOW TRACE语句返回CockroachDB如何执行语句的详细信息及时间信息。可以用来查看为什么语句没有按预期执行。
用法:
SHOW TRACE FOR <statements> :执行一个可解释的语句并返回执行这个语句的所有历程
SHOW TRACE FOR SESSION:返回会话期间记录的所有已执行语句的历程信息
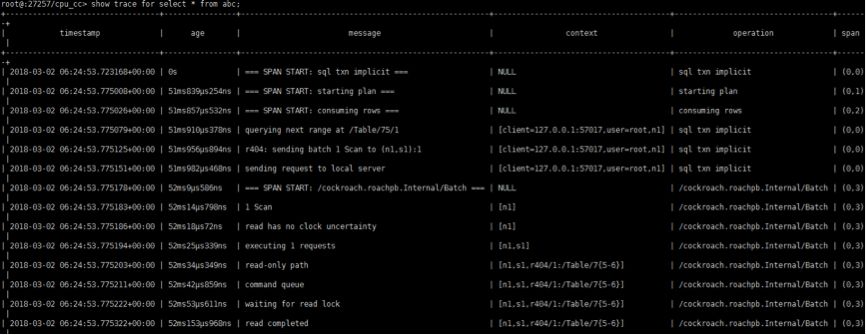
以上所有的语句都需要注意是否有权限执行,如果权限不足将会报错。
本篇文章介绍了语法规则的组成部分及基本的SQL语句,内容比较基础。建议读者结合公众号之前的一些文章,自主动手实践操作一下,这样能更快的了解与熟悉CockroachDB数据库。
关于我们:我们是百度DBA团队,团队有两位CockroachDB PMC Member及一位Contributor, 目前正积极推动NewSQL在百度内部以及外部的发展。除了NewSQL, 我们在MySQL, PostgreSQL, GreenPlum有多年的内核开发经验及实践经验,对数据库和大数据领域有疑问或者需求欢迎联系我们,同时欢迎有志青年加入我们!
关注我们

