




参考书籍:Redis开发与运维[1]
集群
数据分布
Redis数据分布
Redis Cluser采用虚拟槽分区,所有的键根据哈希函数映射到0~16383整数槽内,计算公式:slot=CRC16(key)&16383
Redis虚拟槽分区的特点:
•解耦数据和节点之间的关系,简化了节点扩容和收缩难度。•节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据。•支持节点、槽、键之间的映射查询,用于数据路由、在线伸缩等场景
Redis分布式集群功能限制
1.key批量操作支持有限。如mset、mget,目前只支持具有相同slot值的key执行批量操作。对于映射为不同slot值的key由于执行mget、mget等操作可 能存在于多个节点上因此不被支持。2.key事务操作支持有限。同理只支持多key在同一节点上的事务操作,当多个key分布在不同的节点上时无法使用事务功能。3.key作为数据分区的最小粒度,因此不能将一个大的键值对象如hash、list等映射到不同的节点。4.不支持多数据库空间。单机下的Redis可以支持16个数据库,集群模式下只能使用一个数据库空间,即db0。5.复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构
节点通信
Redis集群采用P2P的Gossip(流言)协议, Gossip协议工作原理就是节点彼此不断通信交换信息,一段时间后所有的节 点都会知道集群完整的信息,这种方式类似流言传播。
Gossip消息
常用的Goosip消息分为:ping消息、pong消息、meet消息、fail消息等
•meet消息:用于通知新节点加入•ping消息:每个节点向其他多个节点发送ping消息,消息中含有节点自身及其他部分节点的状态数据。•pong消息:接收到meet、ping消息时作为返回数据,封装自身状态信息。也可以广播pong消息用于通知其他节点更新当前节点状态。•fail消息:当节点判定其他节点下线时,会向集群内广播fail消息,其他节点收到消息后将标记节点设置为下线状态。
搭建集群
需要redis版本在5.0以上,对应官方文档[2]
编写配置文件
创建配置文件目录cluster-test
及数据文件目录
mkdir -p home/dev/data/redis/data/cluster-test
mkdir -p home/dev/data/redis/conf/cluster-test
编写配置文件
### home/dev/data/redis/conf/cluster-test/redis-6379.conf 同理编写6380-6386的配置
#节点端口
port 6379
## 开启集群模式
cluster-enabled yes
## 节点超时时间,单位毫秒
cluster-node-timeout 15000
## 集群内部配置文件
cluster-config-file "nodes-6379.conf"
## 指定本地数据库文件名,默认值为dump.rdb
dbfilename dump-6379.rdb
## dump 文件保存目录
dir home/dev/data/redis/data/cluster-test
启动redis
redis-server redis-6379.conf &
redis-server redis-6380.conf &
redis-server redis-6381.conf &
redis-server redis-6382.conf &
redis-server redis-6383.conf &
redis-server redis-6384.conf &
•这里可以使用redis官方提供的脚本进行基础集群的搭建。具体查看目录redis-x.x.x/utils/create-cluster
。其中包含README说明及create-cluster脚本
启动集群
redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 --cluster-replicas 1
•--cluster-replicas:1:代表集群中的主节点有几个从节点
执行过程如下:
[dev@localhost create-cluster]$ redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:6383 to 127.0.0.1:6379
Adding replica 127.0.0.1:6384 to 127.0.0.1:6380
Adding replica 127.0.0.1:6382 to 127.0.0.1:6381
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: e8e05250b518f5e774ce12f9cd8ff0c285c96bd5 127.0.0.1:6379
slots:[0-5460] (5461 slots) master
M: e34482fb5455d94959f5b46b41fc17cf72646a4c 127.0.0.1:6380
slots:[5461-10922] (5462 slots) master
M: fcceb74f27471d80e991b33e23817200b47866ff 127.0.0.1:6381
slots:[10923-16383] (5461 slots) master
S: 3eee4e2dc41e924d313b6fef575fab40055b69d9 127.0.0.1:6382
replicates e8e05250b518f5e774ce12f9cd8ff0c285c96bd5
S: 208df20aedbbf1687ac66386fc064771793504e6 127.0.0.1:6383
replicates e34482fb5455d94959f5b46b41fc17cf72646a4c
S: 6964ab0161d106093024f643bbe03bf9daf57760 127.0.0.1:6384
replicates fcceb74f27471d80e991b33e23817200b47866ff
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
>>> Performing Cluster Check (using node 127.0.0.1:6379)
M: e8e05250b518f5e774ce12f9cd8ff0c285c96bd5 127.0.0.1:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: fcceb74f27471d80e991b33e23817200b47866ff 127.0.0.1:6381
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 208df20aedbbf1687ac66386fc064771793504e6 127.0.0.1:6383
slots: (0 slots) slave
replicates e34482fb5455d94959f5b46b41fc17cf72646a4c
S: 6964ab0161d106093024f643bbe03bf9daf57760 127.0.0.1:6384
slots: (0 slots) slave
replicates fcceb74f27471d80e991b33e23817200b47866ff
M: e34482fb5455d94959f5b46b41fc17cf72646a4c 127.0.0.1:6380
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 3eee4e2dc41e924d313b6fef575fab40055b69d9 127.0.0.1:6382
slots: (0 slots) slave
replicates e8e05250b518f5e774ce12f9cd8ff0c285c96bd5
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
查看集群状态
•查看集群状态
[dev@localhost create-cluster]$ redis-cli cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:281
cluster_stats_messages_pong_sent:281
cluster_stats_messages_sent:562
cluster_stats_messages_ping_received:276
cluster_stats_messages_pong_received:281
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:562
•查看集群节点信息
[dev@localhost create-cluster]$ redis-cli cluster nodes
fcceb74f27471d80e991b33e23817200b47866ff 127.0.0.1:6381@16381 master - 0 1622448169000 3 connected 10923-16383
208df20aedbbf1687ac66386fc064771793504e6 127.0.0.1:6383@16383 slave e34482fb5455d94959f5b46b41fc17cf72646a4c 0 1622448169000 2 connected
6964ab0161d106093024f643bbe03bf9daf57760 127.0.0.1:6384@16384 slave fcceb74f27471d80e991b33e23817200b47866ff 0 1622448170329 3 connected
e34482fb5455d94959f5b46b41fc17cf72646a4c 127.0.0.1:6380@16380 master - 0 1622448170000 2 connected 5461-10922
e8e05250b518f5e774ce12f9cd8ff0c285c96bd5 127.0.0.1:6379@16379 myself,master - 0 1622448169000 1 connected 0-5460
3eee4e2dc41e924d313b6fef575fab40055b69d9 127.0.0.1:6382@16382 slave e8e05250b518f5e774ce12f9cd8ff0c285c96bd5 0 1622448171335 1 connected
集群扩容
启动备用节点:
redis-server redis-6385.conf &
redis-server redis-6386.conf &
查看redis
[dev@localhost cluster-test]$ ps -ef | grep redis
dev 3934 3552 0 07:56 pts/1 00:00:01 redis-server *:6379 [cluster]
dev 3935 3552 0 07:56 pts/1 00:00:01 redis-server *:6380 [cluster]
dev 3936 3552 0 07:56 pts/1 00:00:01 redis-server *:6381 [cluster]
dev 3937 3552 0 07:56 pts/1 00:00:01 redis-server *:6382 [cluster]
dev 3938 3552 0 07:56 pts/1 00:00:01 redis-server *:6383 [cluster]
dev 3959 3552 0 07:56 pts/1 00:00:01 redis-server *:6384 [cluster]
dev 3989 3552 0 08:21 pts/1 00:00:00 redis-server *:6385 [cluster]
dev 3994 3552 0 08:21 pts/1 00:00:00 redis-server *:6386 [cluster]
dev 4001 3552 0 08:21 pts/1 00:00:00 grep --color=auto redis
添加master节点
redis-cli --cluster add-node <host_new>:<port_new> <host>:<port>
•**<host_new>:<port_new>**:新加入集群节点
•**<host>:<port>**:集群内任意节点
[dev@localhost cluster-test]$ redis-cli --cluster add-node 127.0.0.1:6385 127.0.0.1:6379
>>> Adding node 127.0.0.1:6385 to cluster 127.0.0.1:6379
>>> Performing Cluster Check (using node 127.0.0.1:6379)
M: e8e05250b518f5e774ce12f9cd8ff0c285c96bd5 127.0.0.1:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: fcceb74f27471d80e991b33e23817200b47866ff 127.0.0.1:6381
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 208df20aedbbf1687ac66386fc064771793504e6 127.0.0.1:6383
slots: (0 slots) slave
replicates e34482fb5455d94959f5b46b41fc17cf72646a4c
S: 6964ab0161d106093024f643bbe03bf9daf57760 127.0.0.1:6384
slots: (0 slots) slave
replicates fcceb74f27471d80e991b33e23817200b47866ff
M: e34482fb5455d94959f5b46b41fc17cf72646a4c 127.0.0.1:6380
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 3eee4e2dc41e924d313b6fef575fab40055b69d9 127.0.0.1:6382
slots: (0 slots) slave
replicates e8e05250b518f5e774ce12f9cd8ff0c285c96bd5
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 127.0.0.1:6385 to make it join the cluster.
[OK] New node added correctly.
分配槽
redis-cli --cluster reshard <host>:<port> --cluster-from <node-id> --cluster-to <node-id> --cluster-slots <number of slots> --cluster-yes
•**<host>:<port>**:集群内任意节点•--cluster-from
:从集群中哪些节点转移槽,多个几点用,
分割•--cluster-to
:转移槽到集群中的那个节点•--cluster-slots
:分配的槽的数量•--cluster-yes
:自动确认,不加此参数,需要手动输入yes确认槽迁移计划•<node-id>: 节点对应的集群ID,以集群模式启动时会写入到nodes-{port}.conf
配置中。也可以通过redis-cli cluster nodes
查看
[dev@localhost create-cluster]$ redis-cli cluster nodes
b48e9109610b9952cde3f032f77563e441a3d75d 127.0.0.1:6385@16385 master - 0 1622449778389 0 connected
fcceb74f27471d80e991b33e23817200b47866ff 127.0.0.1:6381@16381 master - 0 1622449776378 3 connected 10923-16383
208df20aedbbf1687ac66386fc064771793504e6 127.0.0.1:6383@16383 slave e34482fb5455d94959f5b46b41fc17cf72646a4c 0 1622449774000 2 connected
6964ab0161d106093024f643bbe03bf9daf57760 127.0.0.1:6384@16384 slave fcceb74f27471d80e991b33e23817200b47866ff 0 1622449776000 3 connected
e34482fb5455d94959f5b46b41fc17cf72646a4c 127.0.0.1:6380@16380 master - 0 1622449777384 2 connected 5461-10922
e8e05250b518f5e774ce12f9cd8ff0c285c96bd5 127.0.0.1:6379@16379 myself,master - 0 1622449775000 1 connected 0-5460
3eee4e2dc41e924d313b6fef575fab40055b69d9 127.0.0.1:6382@16382 slave e8e05250b518f5e774ce12f9cd8ff0c285c96bd5 0 1622449777000 1 connected
将6379,6380,6381的词槽分别分给6385节点1024个词槽
redis-cli --cluster reshard 127.0.0.1:6379 --cluster-from e8e05250b518f5e774ce12f9cd8ff0c285c96bd5,e34482fb5455d94959f5b46b41fc17cf72646a4c,fcceb74f27471d80e991b33e23817200b47866ff --cluster-to b48e9109610b9952cde3f032f77563e441a3d75d --cluster-slots 1024 --cluster-yes
迁移后的集群节点信息:
[dev@localhost create-cluster]$ redis-cli cluster nodes
b48e9109610b9952cde3f032f77563e441a3d75d 127.0.0.1:6385@16385 master - 0 1622450708439 7 connected 0-340 5461-5802 10923-11263
fcceb74f27471d80e991b33e23817200b47866ff 127.0.0.1:6381@16381 master - 0 1622450708000 3 connected 11264-16383
208df20aedbbf1687ac66386fc064771793504e6 127.0.0.1:6383@16383 slave e34482fb5455d94959f5b46b41fc17cf72646a4c 0 1622450706000 2 connected
6964ab0161d106093024f643bbe03bf9daf57760 127.0.0.1:6384@16384 slave fcceb74f27471d80e991b33e23817200b47866ff 0 1622450707433 3 connected
e34482fb5455d94959f5b46b41fc17cf72646a4c 127.0.0.1:6380@16380 master - 0 1622450706427 2 connected 5803-10922
e8e05250b518f5e774ce12f9cd8ff0c285c96bd5 127.0.0.1:6379@16379 myself,master - 0 1622450705000 1 connected 341-5460
3eee4e2dc41e924d313b6fef575fab40055b69d9 127.0.0.1:6382@16382 slave e8e05250b518f5e774ce12f9cd8ff0c285c96bd5 0 1622450709445 1 connected
添加从节点
redis-cli --cluster add-node <host_new>:<port_new> <host>:<port> --cluster-slave \
--cluster-master-id <node-id>
•--cluster-slave
:添加从节点•--cluster-master-id <node-id>
:从节点的主节点id
[dev@localhost create-cluster]$ redis-cli --cluster add-node 127.0.0.1:6386 127.0.0.1:6385 --cluster-slave --cluster-master-id b48e9109610b9952cde3f032f77563e441a3d75d
>>> Adding node 127.0.0.1:6386 to cluster 127.0.0.1:6385
>>> Performing Cluster Check (using node 127.0.0.1:6385)
M: b48e9109610b9952cde3f032f77563e441a3d75d 127.0.0.1:6385
slots:[0-340],[5461-5802],[10923-11263] (1024 slots) master
S: 208df20aedbbf1687ac66386fc064771793504e6 127.0.0.1:6383
slots: (0 slots) slave
replicates e34482fb5455d94959f5b46b41fc17cf72646a4c
M: e34482fb5455d94959f5b46b41fc17cf72646a4c 127.0.0.1:6380
slots:[5803-10922] (5120 slots) master
1 additional replica(s)
M: e8e05250b518f5e774ce12f9cd8ff0c285c96bd5 127.0.0.1:6379
slots:[341-5460] (5120 slots) master
1 additional replica(s)
M: fcceb74f27471d80e991b33e23817200b47866ff 127.0.0.1:6381
slots:[11264-16383] (5120 slots) master
1 additional replica(s)
S: 6964ab0161d106093024f643bbe03bf9daf57760 127.0.0.1:6384
slots: (0 slots) slave
replicates fcceb74f27471d80e991b33e23817200b47866ff
S: 3eee4e2dc41e924d313b6fef575fab40055b69d9 127.0.0.1:6382
slots: (0 slots) slave
replicates e8e05250b518f5e774ce12f9cd8ff0c285c96bd5
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 127.0.0.1:6386 to make it join the cluster.
Waiting for the cluster to join
>>> Configure node as replica of 127.0.0.1:6385.
[OK] New node added correctly.
•查看集群状态
[dev@localhost create-cluster]$ redis-cli cluster nodes
703596043233487cc79ef364d56a13907ccf7cb6 127.0.0.1:6386@16386 slave b48e9109610b9952cde3f032f77563e441a3d75d 0 1622451294000 7 connected
b48e9109610b9952cde3f032f77563e441a3d75d 127.0.0.1:6385@16385 master - 0 1622451294000 7 connected 0-340 5461-5802 10923-11263
fcceb74f27471d80e991b33e23817200b47866ff 127.0.0.1:6381@16381 master - 0 1622451293000 3 connected 11264-16383
208df20aedbbf1687ac66386fc064771793504e6 127.0.0.1:6383@16383 slave e34482fb5455d94959f5b46b41fc17cf72646a4c 0 1622451291000 2 connected
6964ab0161d106093024f643bbe03bf9daf57760 127.0.0.1:6384@16384 slave fcceb74f27471d80e991b33e23817200b47866ff 0 1622451295061 3 connected
e34482fb5455d94959f5b46b41fc17cf72646a4c 127.0.0.1:6380@16380 master - 0 1622451296066 2 connected 5803-10922
e8e05250b518f5e774ce12f9cd8ff0c285c96bd5 127.0.0.1:6379@16379 myself,master - 0 1622451293000 1 connected 341-5460
3eee4e2dc41e924d313b6fef575fab40055b69d9 127.0.0.1:6382@16382 slave e8e05250b518f5e774ce12f9cd8ff0c285c96bd5 0 1622451294055 1 connected
集群收缩
下线节点 127.0.0.1:6385、127.0.0.1:6386
删除master对应的从节点
•查看从节点
[dev@localhost create-cluster]$ redis-cli cluster nodes | grep :6386
703596043233487cc79ef364d56a13907ccf7cb6 127.0.0.1:6386@16386 slave b48e9109610b9952cde3f032f77563e441a3d75d 0 1622451429000 7 connected
•从集群中删除从节点
redis-cli --cluster del-node 127.0.0.1:6379 703596043233487cc79ef364d56a13907ccf7cb6
•后续使用redis-cli -h 127.0.0.1 -p 6379 cluster nodes
查看集群节点状态,6386节点应该已经被移除。
清空槽
redis-cli --cluster reshard 127.0.0.1:6379 --cluster-from b48e9109610b9952cde3f032f77563e441a3d75d --cluster-to e8e05250b518f5e774ce12f9cd8ff0c285c96bd5 --cluster-slots 341 --cluster-yes
redis-cli --cluster reshard 127.0.0.1:6379 --cluster-from b48e9109610b9952cde3f032f77563e441a3d75d --cluster-to e34482fb5455d94959f5b46b41fc17cf72646a4c --cluster-slots 341 --cluster-yes
redis-cli --cluster reshard 127.0.0.1:6379 --cluster-from b48e9109610b9952cde3f032f77563e441a3d75d --cluster-to fcceb74f27471d80e991b33e23817200b47866ff --cluster-slots 342 --cluster-yes
•由于目标节点只能写一个,因此需要执行三次。
•查看当前集群槽分配状态
[dev@localhost create-cluster]$ redis-cli cluster slots
1) 1) (integer) 0 ## 槽起始位置
2) (integer) 5460 ## 槽结束位置
3) 1) "127.0.0.1" ## master:host
2) (integer) 6379 ## master:port
3) "e8e05250b518f5e774ce12f9cd8ff0c285c96bd5" ## master-node-id
4) 1) "127.0.0.1" ## slave:host
2) (integer) 6382 ## slave:port
3) "3eee4e2dc41e924d313b6fef575fab40055b69d9" ## slave-node-id
2) 1) (integer) 5461
2) (integer) 5801
3) 1) "127.0.0.1"
2) (integer) 6380
3) "e34482fb5455d94959f5b46b41fc17cf72646a4c"
4) 1) "127.0.0.1"
2) (integer) 6383
3) "208df20aedbbf1687ac66386fc064771793504e6"
3) 1) (integer) 5802
2) (integer) 5802
3) 1) "127.0.0.1"
2) (integer) 6381
3) "fcceb74f27471d80e991b33e23817200b47866ff"
4) 1) "127.0.0.1"
2) (integer) 6384
3) "6964ab0161d106093024f643bbe03bf9daf57760"
4) 1) (integer) 5803
2) (integer) 10922
3) 1) "127.0.0.1"
2) (integer) 6380
3) "e34482fb5455d94959f5b46b41fc17cf72646a4c"
4) 1) "127.0.0.1"
2) (integer) 6383
3) "208df20aedbbf1687ac66386fc064771793504e6"
5) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 6381
3) "fcceb74f27471d80e991b33e23817200b47866ff"
4) 1) "127.0.0.1"
2) (integer) 6384
3) "6964ab0161d106093024f643bbe03bf9daf57760"
下线master节点
[dev@localhost create-cluster]$ redis-cli --cluster del-node 127.0.0.1:6379 b48e9109610b9952cde3f032f77563e441a3d75d
>>> Removing node b48e9109610b9952cde3f032f77563e441a3d75d from cluster 127.0.0.1:6379
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
[dev@localhost create-cluster]$ redis-cli cluster nodes ## 查看当前集群节点状态
fcceb74f27471d80e991b33e23817200b47866ff 127.0.0.1:6381@16381 master - 0 1622452136635 10 connected 5802 10923-16383
208df20aedbbf1687ac66386fc064771793504e6 127.0.0.1:6383@16383 slave e34482fb5455d94959f5b46b41fc17cf72646a4c 0 1622452136000 9 connected
6964ab0161d106093024f643bbe03bf9daf57760 127.0.0.1:6384@16384 slave fcceb74f27471d80e991b33e23817200b47866ff 0 1622452138653 10 connected
e34482fb5455d94959f5b46b41fc17cf72646a4c 127.0.0.1:6380@16380 master - 0 1622452137642 9 connected 5461-5801 5803-10922
e8e05250b518f5e774ce12f9cd8ff0c285c96bd5 127.0.0.1:6379@16379 myself,master - 0 1622452136000 8 connected 0-5460
3eee4e2dc41e924d313b6fef575fab40055b69d9 127.0.0.1:6382@16382 slave e8e05250b518f5e774ce12f9cd8ff0c285c96bd5 0 1622452137000 8 connected
请求路由
请求重定向
在集群模式下,Redis接收任何键相关命令时首先计算键对应的槽,再根据槽找出所对应的节点,如果节点是自身,则处理键命令;否则回复 MOVED重定向错误,通知客户端请求正确的节点。这个过程称为MOVED重定向。
hash_tag
如果键值包含{hash_tag}
,计算键值对应的槽时会使用大括号内的内容进行计算,可以利用此特性保持业务相关性强的内容分不到同一个槽内。
Pipeline同样可以受益于hash_tag,由于Pipeline只能向一个节点批量发送执行命令,而相同slot必然会对应到唯一的节点,降低了集群使用Pipeline的门槛
Smart客户端
客户端通过缓存槽与节点映射关系来进行命令的执行,当出现Move重定向错误时,向正确的节点发送命令并更新本地缓存。流程如下:
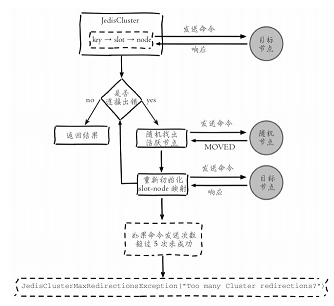
针对高并发的场景,客户端与Redis实例通信这里是绝对的热点代码。集群协议通过Smart客户端全面高效的支持需要一个过程,因此用户在选择Smart客户端时要重点审核集群交互代码,防止线上踩坑。必要时可以自行优化修改客户端源码。
ASK重定向
当一个slot数据从源节点迁移到目标节点时,期间可能出现一部分数据在源节点,而另一部分在目标节点。
1.当集群进行槽迁移时,客户端根据本地缓存发送命令到源节点,如果源节点存在数据则直接返回2.如果键对象不存在,可能在目标节点中,节点返回ASK重定向错误,格式为(error)ASK {slot} {targetIP} : {targetPort}
3.客户端提取目标节点信息,发送asking
命令打开客户端连接标识,再执行键命令,如果存在则执行,不存在则返回不存在信息。
•ASK和MOVE虽然都返回目标节点,但是意义不同,ASK返回表示当前正在迁移键,不确定何时能完成,客户端此时不需要更新本地缓存。而MOVE重定向表示当前键已经在其他节点,需要更新本地缓存。
集群环境下对于使用批量操作的场景,建议优先使用Pipeline方式,在客户端实现对ASK重定向的正确处理,这样既可以受益于批量操作的IO优化,又可以兼容slot迁移场景。
故障转移
故障发现
集群内通过ping/pong来进行节点通信,消息可以传播槽信息、主从状态、节点故障等。
主观下线
如果其他节点在cluster-node-timeout
时间内没有回复自己发出的ping请求,会将此节点标记为pfail
状态。
客观下线
当节点被客观下线后,其状态会随消息在进群内散播。当cluster-node-timeout*2
时间内有超过半数的节点认为该节点下线,集群会删除该节点。
下线的有效期为
cluster-node-timeout*2
,如果到达时间时没有超过半数节点认为该节点下线,那么故障节点将不会下线导致故障转移失败。应根据实际情况适当调大cluster-node-timeout
配置。
故障恢复
下线主节点的从节点发现自身复制的主节点下线时,进行故障恢复工作。
资格检查
从节点与主节点断线时间超过cluster-node-time*cluster-slavevalidity-factor
时,该从节点不具备故障转移资格。
准备选举时间
各个从节点根据自身偏移量设置不同的延时选举时间,偏移量大的节点优先发起选举。
发起选举
当从节点定时任务发现到达故障选举时间failover_auth_time
到达后,发起选举,流程如下:
1.更新配置纪元2.广播选举消息
选举投票
持有槽的主节点会处理故障选举消息,当一个从节点在cluster-node-timeout*2
时间内获取N/2+1个投票时,该从节点会晋升为主节点。
替换主节点
当从节点收集到足够的选票之后,触发替换主节点操作:
1.当前从节点取消复制变为主节点2.执行cluster DelSlot操作撤销故障主节点负责的槽,并执行cluster AddSlot把这些槽委派给自己。3.向集群广播自己的pong消息,通知集群内所有节点当前从节点变为主节点并接管故障主节点的槽信息。
故障转移时间
估算故障转移时间
1.主观下线(pfail)识别时间 = cluster-node-timeout
2.主观下线状态消息传播时间<=cluster-node-timeout/2。消息通信机制对超过cluster-node-timeout/2
未通信节点会发起ping消息,消息体在选择包含 哪些节点时会优先选取下线状态节点,所以通常这段时间内能够收集到半数 以上主节点的pfail报告从而完成故障发现3.从节点转移时间<=1000毫秒。由于存在延迟发起选举机制,偏移量最大的从节点会最多延迟1秒发起选举。通常第一次选举就会成功,所以从 节点执行转移时间在1秒以内
根据以上分析可以预估出故障转移时间,如下:
failover-time(毫秒) ≤ cluster-node-timeout + cluster-node-timeout/2 + 1000因此,故障转移时间和
cluster-node-timeout
参数息息相关,默认15s
集群运维
集群完整性
参数cluster-require-full-coverage
控制集群槽未完成分配时,集群是否可用,默认为false
。大多数业务应设置为ture
带宽消耗
集群内Gossip消息通信会消耗带宽,官方建议集群最大规模在1000以内。
建议:
1.在满足业务要求的前提下避免大集群。可以根据业务场景拆分为多个小集群2.适度提高cluster-node-timeout
降低消息发送频率,但是同时会导致故障转移速度变慢,应根据业务场景平衡二者。3.条件允许部署在多个机器上。
Pub/Sub广播问题
集群模式下,频繁应用Pub/Sub功能时,会严重消耗集群带宽。针对这种情况建议使用Sentinel结构专门用于Pub/Sub功能,从而规避这一问题。
集群倾斜
数据倾斜
•节点和槽分配严重不均,使用如下命令查看并处理
[blog@localhost ~]$ redis-cli --cluster info 127.0.0.1:6379 # 查看集群槽分配情况
127.0.0.1:6379 (e8e05250...) -> 0 keys | 5461 slots | 1 slaves.
127.0.0.1:6381 (fcceb74f...) -> 0 keys | 5461 slots | 1 slaves.
127.0.0.1:6380 (e34482fb...) -> 0 keys | 5462 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
[blog@localhost ~]$ redis-cli --cluster rebalance 127.0.0.1:6379 # 重新平衡槽
>>> Performing Cluster Check (using node 127.0.0.1:6379)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
*** No rebalancing needed! All nodes are within the 2.00% threshold.
•不同槽对应键数量差异过大
过度使用{hash_tag}
时,会导致槽对应的键数量分布不均匀。通过cluster countkeysinslot {slot}
可以查看槽内对应的键数量,再使用cluster countkeysinslot {slot} {count}
循环迭代出槽下所有的键,进而发现过度使用{hash_tag}
的键。
•集合对象包含大量元素
大对象可以使用redis-cli --bigkeys
命令查找,找到后应根据业务进行拆分,另外,集群槽数据迁移通过对键执行migrate
操作完成,键过大可能导致migrate
超时导致数据迁移失败。
•内存相关配置不一致
主要指hash-max-ziplist-value
、set-max-inset-entries
等压缩数据结构配置。当集群大量使用hash、set等数据结构,配置不同可能导致集群内节点占用内存不同,导致内存量倾斜。
请求倾斜
集群内请求量过大并且集中在少部分节点时将导致集群负载不均。常出现在热点键场景,当键命令消耗较低时影响有限,当使用复杂命令如hgetall
、smembers
时影响很大。避免方式如下:
1.合理设计键,热点大集合拆分或使用hmget
代替hgetall
避免整体读取2.不要使用热点key作为hash_tag,避免热点key映射到同一个节点3.对于一致性要求不高的场景,客户端使用本地缓存代替热键调用
手动故障转移
在从节点上执行cluster failover
会发起手动故障转移流程,如下:
1.从节点通知主节点停止处理所有客户端请求2.主节点发送对应从节点延迟复制的数据3.从节点处理延迟复制的数据,直到与主节点偏移量一致4.从节点立刻发起选举投票,选举成功后断开复制成为主节点,之后向集群内广播pong消息,5.旧主节点接收消息后更新自身配置变为从节点,解除客户端请求阻塞,重定向到新主节点上执行请求。6.旧主节点变为从节点后,向新的主节点发起全量复制流程
•cluster failover force
: 从节点直接进行选举,不需要确认和主节点偏移量,用于主节点宕机的场景。•cluster failover takeover
: 从节点直接更新配置纪元并替换主节点,用于无法完成选举的情况:超过半数节点故障,网络不通畅导致规定时间内无法完成选举,导致当前节点失去选举资格(断线时间超过cluster-node-time*cluster-slavevalidity-factor
)
手动故障转移时,在满足当前需求的情况下建议优先级:cluster failver>cluster failover force>cluster failover takeover
数据迁移
redis提供了迁移数据的命令,redis-cli --cluster import host:port --from <arg> --copy --replace
,命令内部采用批量scan和migrate的方式迁移数据。其缺点如下:
1.迁移只能从单机节点向集群环境导入数据2.不支持在线迁移数据,迁移数据时应用方必须停写,无法平滑迁移数据3.迁移过程中途如果出现超时等错误,不支持断点续传只能重新全量导入4.使用单线程进行数据迁移,大数据量迁移速度过慢
这里推荐使用唯品会开发的
redis-migrate-tool
,该工具可满足大多数Redis迁移需求,特点如下:•支持单机、Twemproxy、Redis Cluster、RDB/AOF等多种类型的数据迁移•工具模拟成从节点基于复制流迁移数据,从而支持在线迁移数据,业务方不需要停写•采用多线程加速数据迁移过程且提供数据校验和查看迁移状态等功能
更多细节见GitHub:https://github.com/vipshop/redis-migrate-tool。
本章重点回顾
1.Redis集群数据分区规则采用虚拟槽方式,所有的键映射到16384个槽中,每个节点负责一部分槽和相关数据,实现数据和请求的负载均衡2.搭建集群划分三个步骤:准备节点,节点握手,分配槽。可以使用redis-trib.rb create
或者redis-cli --cluster
命令快速搭建集群3.集群内部节点通信采用Gossip协议彼此发送消息,消息类型分为:ping消息、pong消息、meet消息、fail消息等。节点定期不断发送和接受 ping/pong消息来维护更新集群的状态。消息内容包括节点自身数据和部分其他节点的状态数据4.集群伸缩通过在节点之间移动槽和相关数据实现。扩容时根据槽迁移计划把槽从源节点迁移到目标节点,源节点负责的槽相比之前变少从而达 到集群扩容的目的,收缩时如果下线的节点有负责的槽需要迁移到其他节 点,再通过cluster forget命令让集群内其他节点忘记被下线节点5.使用Smart客户端操作集群达到通信效率最大化,客户端内部负责计算维护键→槽→节点的映射,用于快速定位键命令到目标节点。集群协议通 过Smart客户端全面高效的支持需要一个过程,用户在选择Smart客户端时建 议review下集群交互代码如:异常判定和重试逻辑,更新槽的并发控制等。节点接收到键命令时会判断相关的槽是否由自身节点负责,如果不是则返回 重定向信息。重定向分为MOVED和ASK,ASK说明集群正在进行槽数据迁 移,客户端只在本次请求中做临时重定向,不会更新本地槽缓存。MOVED 重定向说明槽已经明确分派到另一个节点,客户端需要更新槽节点缓存6.集群自动故障转移过程分为故障发现和故障恢复。节点下线分为主观下线和客观下线,当超过半数主节点认为故障节点为主观下线时标记它为 客观下线状态。从节点负责对客观下线的主节点触发故障恢复流程,保证集群的可用性7.开发和运维集群过程中常见问题包括:超大规模集群带宽消耗, pub/sub广播问题,集群节点倾斜问题,手动故障转移,在线迁移数据等
[^1]: 关于Gossip协议可参考P2P 网络核心技术:Gossip 协议[3]
References
[1]
Redis开发与运维: https://book.douban.com/subject/26971561/[2]
官方文档: https://redis.io/topics/cluster-tutorial[3]
P2P 网络核心技术:Gossip 协议: https://zhuanlan.zhihu.com/p/41228196
