




引言
我的博客:http://yunsonbai.top
随着业务的发展,为了满足越来越多的业务需求,逐渐从原来的单机到多机再到基于docker的集群,发展到集群会带来新的问题需要解决,比如日志散落在各个实例上,对于日志的统计分析带来了新的要求,一台一台的去查显然是不合理的,这就引出本文讨论的主题:
分布式日志收集。
简单介绍一下用到的组件/工具
filebeat
文档:
https://www.elastic.co/cn/beats/filebeat
我觉得这里边已经说的很清楚为啥使用filebeat做日志收集器了
优势:
基于golang的轻量级日志采集器,配置启动出奇的简单
按官方说法elastic专门为成千上万机器日志收集做的收集器
kafka
文档: https://kafka.apache.org/
优势:
应该说kafka的诞生就是为日志收集做服务的
几乎可以认为kafka集群没有qps上限,单机都能到10W/s的吞吐,完全分布式。[可怕]
好文推荐: https://www.infoq.cn/article/kafka-analysis-part-1
ELK
E: ElasticSearch
文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
优势: 高度可扩展的开源全文搜索和分析引擎,可快速、实时存储、搜索和分析数据。(网上太多了)
好文推荐:
https://juejin.im/entry/5bef7046e51d4557fe34e812
L: Logstash
文档:
https://www.elastic.co/cn/products/logstash
优势: 实时流水线功能,分析合并来源(MySQL、Redis、kafka)数据,并输出到目标(es、file等)存储地址
好文推荐:
https://cloud.tencent.com/developer/article/1353068
K: kibana
文档:
https://www.elastic.co/cn/products/kibana
优势: 完备的前端展示
grafana
是什么: 可以理解和kibana一样的东西,出于个人的喜爱,它真的很黑炫酷
文档: https://grafana.com/
其他说明
其实没有花太多篇幅介绍上边的组件的使用和原理,本文的分享重点不在这里,只是分享用什么样的架构来使用这些组件,关于这些组件的原理和使用我分享了几篇好文章以及官方文档,大家可以参考,另外网上这种介绍文章很多,接下来分享我的目前日志量和收集架构
架构情况说明
架构图:
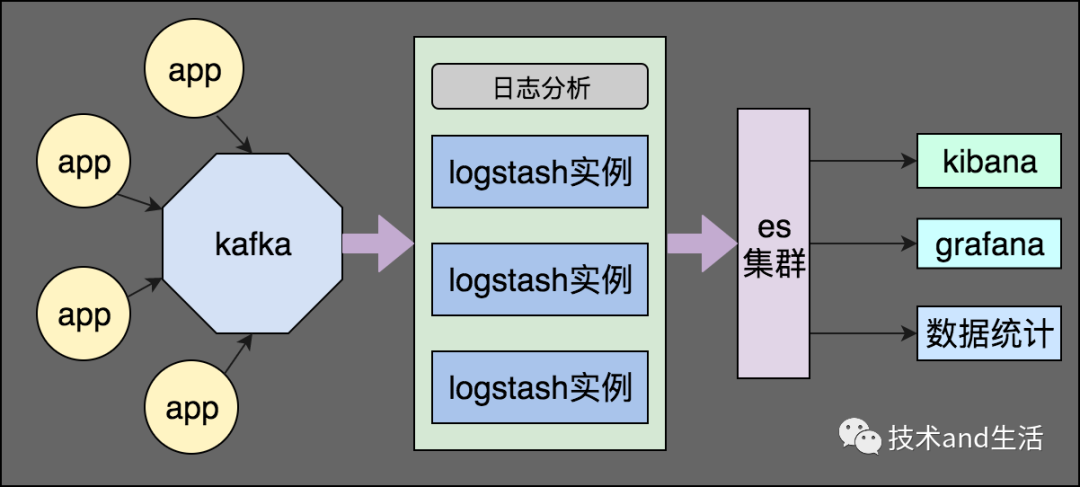
实例数: 全部基于docker部署,各类角色的实例数过千
日志量: 日均日志约4.6亿条, 占空间约140G。
目前收集架构负载: 十几个es节点个位数负载,个位数logstash节点也几乎没有负载。
版本说明: filebeat、logstash、es、kibana版本要一致
组件使用注意点
filebeat
打包说明: 镜像在打包时,要添加上filebeat可执行文件(可在官网下载),可以使用supervisor管理服务。
filebeat配置文件可参考以下例子:
filebeat.prospectors:- input_type: logpaths: /var/log/nginx.logdocument_type: nginx_logfields:cluster_name: ${CLUSTER_NAME}host: ${HOST}log_topics: app1_nginx # nginx日志- input_type: logpaths: /var/applog/*.logdocument_type: applogfields:cluster_name: ${CLUSTER_NAME}host: ${HOST}log_topics: app1_log # 应用日志output.kafka:hosts: ["kafka1:9092","kafka2:9092",...,"kafkaN:9092"]topic: '%{[fields][log_topics]}'partition.round_robin:reachable_only: falserequired_acks: 1compression: gzip
logstash
机器数量: 可以找几台虚机(4c+8G)启动,个数和kafka的节点数一致。
input和output: kafka(filebeat日志流向的kafka)和es集群
配置注意
关于filter
一般会用到的有grok(正则切割日志)、json(json解析)、mutate(组合命令remove_field(去除无用字段)等等)很多这里不一一介绍了,推荐一个可以在线测试grok语法是否正确的工具:http://grokdebug.herokuapp.com/
配置样例
input {kafka{bootstrap_servers => "kafka1:9092,kafka2:9092,...,kafkaN:9092" # 前边的kafkaauto_offset_reset => "latest"group_id => "app1"consumer_threads => 1decorate_events => truecodec => "json"topics => ["app1_log"]}}filter {if [fields][log_topics] == "app1_log" {grok {match => {"message" => '(?<time_local>[^\|]*)\|(?<code_line>[^\|]*)\|(?<level>[^\|]*)\|(?<log_json>.*)'}}mutate {gsub => ["log_json", "[\|]", "_"] # 替换|为_}json {source => "log_json"remove_field=>["log_json"]}}# 可以有多个if# remove not care fieldmutate{remove_field => ["field1", "field2"]}}output {if [fields][log_topics] == "app1_log" {elasticsearch {hosts => ["es1:9200", "es2:9200",..,"esN:9200"]index => "app1_log-%{+YYYY.MM.dd}"}}# 可以有多个if}
关于es
注意修改number_of_shards数量等于节点数,es的number_of_shards默认为5,跳过一次坑,没有修改number_of_shards,虽然机器多,但是日志散落不均匀导致总有es的某几个节点负载比较高,其他的却很清闲。
关于数据展示
kibana:一张老图
grafana
统计脚本: python、golang、java任选
总结
日志对于监控系统流量、提升系统性能、发现系统问题等有着十分重要的意义,可以说有些日志对于系统的演变来说起着决定性的作用。所以日志的收集是一项很重要且很有意思的工作,也可以说是一门学问,如何规范的输出日志方便后边的收集,如何压缩日志尽量减少磁盘的使用,如何控制日志结构使搜索更快等等这些问题。本文重点分享了当前我采用的收集方式,欢迎大家提出纠正和宝贵的意见。
