




版权声明:本文由神州数码云基地团队整理撰写,若转载请注明出处。
TiDB源码研究系列第三篇,立足于SQL生命周期的解析SQL阶段,详细介绍Paser模块。
通过上一篇SQL的一生我们基本了解一句SQL在TiDB中所需要经历的一系列操作,其中的第一步就是解析SQL,从文本解析为抽象语法树(AST),也就是我们今天要学习的Parser模块。
https://zhuanlan.zhihu.com/p/305704259
这个模块的学习需要一定的基础知识,对词法解析和语法解析需要有一定的了解,不然学习起来会非常的费力,我也是一开始对这些没有充分的了解,中间走了不少弯路。所以如果你已经具备这一块的知识,那么想要了解TiDB的Parser模块可以直接看官方的源码阅读系列:
https://link.zhihu.com/?target=https%3A//pingcap.com/blog-cn/tidb-source-code-reading-5/
当然,你如果和我一样也是初步入门这一块的学习,那么你就可以继续往下看了,开始初步了解TiDB中的Parser模块。
首先,我们需要了解词法分析和语法分析这两个概念,属于编译原理中的基本概念(大学学的 都快忘了),这里我不做理论解释了,有兴趣的可以回去复习复习下编译原理,我就直接带入例子简单的讲解下过程。
当我们有一句SQL传进来的时候,它是以一个文本的形式拿到的,简单讲就是一个String类型的,我们这里拿一句简单的SQL看一下: "Select * From student Where id = 1",他会经历词法分析和语法分析两个过程:
词法分析:
从左向右去读这个字符串,每读到一个单词就单独提出来,那么在这个语句中它会读到哪些单词?分别是:“Select”, “*”, “From”, "student", "Where", "id", "=", "1" 这么几个单词,这个地方就不在叫他为单词了,我们称作这些为 Token , Token 我们先简单的分两种,第一种是我们一开始就知道他是什么,比如“Select”,“From”,“Where”,这是SQL语句中我们所规定的单词,也就是关键字,第二种则是 “student”,“id” 和 “1” 这种,他是由用户定义的,我们会给这些Token进行分类,来代表着他不同的意义,比如他是关键字,或者是字符,或者是数字,或者是运算符等等,这个都由我们来进行规定,也就是需要写规则文件,来扫描时匹配到了对应的字符串时,就会返回相对应的Token给我们。
语法分析:
在经过词法分析后,我们就获得了一堆Token,而且我们也都知道这些Token的意义,因为是我们自己定义的,下面就是将他们组装成一句话,看看这句话到底什么意思,他到底想要我们干什么,简单的说,我们要开始寻找主谓宾,“Select” 代表他是一个查询语句,“From” 后面需要接表名,从那张表中查询,“Where” 后面接限定条件,这都是我们赋予这些短语的含义,一句查询SQL的结构需要有哪些Token,他们的顺序如何,都是我们接下来需要定义的规则,通过规则来解读这些Token,并形成有对应含义的结构供我们使用,也就是语法分析的过程。
对于词法分析和语法分析有所了解后,我们其实就可以总结一下这个过程是什么,往简单的地方说就是定义规则,定义Token,然后定义Token的组合方式,很简单,有了这些规则,我们就可以去创建各种语言了。接下来,我们需要有东西帮我们去解析,依赖这些规则帮我们解析成我们能接受的样子,到程序中,也就是需要有东西依靠我们定义的规则解析一个字符串,解析成我们在程序中可以使用与辨别的形式,这个形式就是语法树,也就是开始讲的抽象语法树,而这个帮我们解析的东西也就叫词法分析器和语法分析器。
说到词法分析器和语法分析器,我们就要到程序中去实现,这个过程非常复杂,毕竟一种语言,肯定涉及到各种Token 和 组合规则,语言有多复杂,规则就有多么复杂,这个时候就需要一个工具去帮我们生成分析器,这里就要拿出一个工具了 Lex & Yacc。
https://link.zhihu.com/?target=http%3A//dinosaur.compilertools.net/
直接看 Lex&Yacc 也是非常硬核的一件事(大部分人可能点进连接后又退了出来),这个不适合我们新手来学习,所以我们知道他是帮我们生成分析器的工具就好了,后面在具体代码中会讲到这个过程。我们看张图简单的理解下:
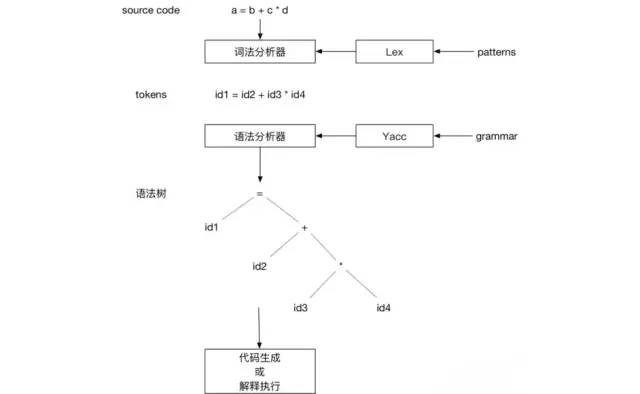
最右边的这个Patterns和Grammar就是我们定义的词法规则和语法规则了,重点,下面问题来了,具体我们要怎么去定义这个规则呢?看下面这个形式(lex 和 yacc 的规则定义格式相同)
... definitions ...%%... rules ...%%... subroutines ...
通过 %% 分为三个部分,最上面是定义的名称,例如各种Token,表达式啥的,中间是规则,也就是重点关注的位置,这部分在词法和语法中都非常的重要,官方文档中提供的例子我们来看看,先看下 Lex 的规则文件:
... definitions ...%%/* 变量 */[a-z] {yylval = *yytext - 'a';return VARIABLE;}/* 整数 */[0-9]+ {yylval = atoi(yytext);return INTEGER;}/* 操作符 */[-+()=/*\n] { return *yytext; }/* 跳过空格 */[ \t] ;/* 其他格式报错 */. yyerror("invalid character");%%... subroutines ...
词法中的规则,看的就很直接,左边定义了扫出的字符串内容,利用正则,如果字符串匹配左边的正则,则进行右边的大括号中的程序运行,比如整数那里,如果匹配了,就会将扫描出来的字符串整体作为一个 INTEGER Token 来返回, 我们就相当于获取了一个整数的Token。第三个部分是空的,我们暂时不用管。
下面继续看一看 Yacc 规则文件的例子:
%token INTEGER VARIABLE%left '+' '-'%left '*' '/'......%%program:program statement '\n'|;statement:expr { printf("%d\n", $1); }| VARIABLE '=' expr { sym[$1] = $3; };expr:INTEGER| VARIABLE { $$ = sym[$1]; }| expr '+' expr { $$ = $1 + $3; }| expr '-' expr { $$ = $1 - $3; }| expr '*' expr { $$ = $1 * $3; }| expr '/' expr { $$ = $1 $3; }| '(' expr ')' { $$ = $2; };%%......
在Yacc的配置文件中,前面先定义了不同种类的Token,中间有一个%left,是指的左结合,那为什么又有两个left,是为了区分优先级,越往下优先级越高,所以’*‘,’/‘的优先级高于’+‘,’-‘。
中间就是规则,通过规则将Token 不断的结合成一个表达式,形成一棵树。语法规则是BNF定义的(巴科斯范式可以百度下,这里不多讲)我们来简单看一下规则的结构,有三个产生式,问题来了,这个地方的产生式是什么,又回到了大学编译原理了,这里还是老规则,不做过多理论解释,简单了解下:
产生式一般就是左边是一个非终结符(非终结符就是可以被再分的),右边则是非终结符和终结符相结合的式子(终结符就是不可再分),整体意思就是左边的非终结符可以转换成右边的表达式(同理右边的表达式也能转成左边的非终结符),那么基于非终结符和终结符的特性,我们可以将一个非终结符根据产生式一直分解为由终结符组成的一串表达式,同理一串由终结符组成的式子我们也可以通过产生式转成某一个非终结符。
回到最上面的列子中,“Select”, “*”, "from", "student" ,这是我们通过语法分析获取到的Token,都是终结符,他们是不可能再分的,那么下面定义下产生式来组合一下:
// 我们先来定义下产生式 双引号引着的我们就代表是终结符.反之则是非终结符// 第一个产生式是SelectStmt,也就是一个查询表达式SelectStmt:// 可以变成下面这个表达式, 从什么表中拿什么字段SelectFiled FromTableSelectFiled:// 可以是一个字段列表"Select" FieldList// 可以是所有字段 *| "Select" "*"FromTable:// 从那个表中"From" TableListFieldList:// 可以是一个字段"Field"// 可以是多个字段, 这个地方可以使用递归思想,也就是可以扩展无数个字段| FieldList "," "Field"TableList:// 可以是一个表名"Table"// 可以是多个表名,同字段| "TableList" "," "Table"// 好了,下面开始解析我们上面那句SQL,记住从左往右依次来,"."代表我们读到的位子Select . * From student// Select 匹配到,是终结符,没有相关表达式转换,不变=》Select * . From student// 读到"*"发现 "Select" "*" 可以变成转换式 SelectFiled 于是转换=》SelectFiled . From student// 继续读发现到from 没有可以转换的产生式,不变=》SelectFiled From . student// 继续右边移,发现到student 可以匹配成TableList,转换=》SelectFiled From TableList .// 继续往右发现没了,于是重读,发现 From TableList 可以转换=》SelectFiled FromTable .// 最后这两个可以继续匹配成SelectStmt=》SelectStmt通过一系列的转换,最后我们获得了一个SelectStmt的表达式这个过程可以构造成一颗树,我们根据树的结构就可以处理这句SQL了这个例子只是一个很简单的列子,真实的结构会相当复杂
看完上面这些我们现在就有了一定的基础,上面讲的比较简单和片面,因为这些都不是我们的重点,现在我们想想当初看这篇文章是为了什么,肯定是为了源码的学习啊,所有我们还是得回归TiDB源码之中。TiDB的源码中将Parser模块单独分离出来做了一个库:
https://link.zhihu.com/?target=https%3A//github.com/pingcap/parser
没有下载到本地的,可以单独拉下来看,当然前面如果在本地启动了TiDB的话,Go会自动将所有的依赖包下载下来,本地也是可以找到的。接下来我们进入源码,现在TiDB中找到Parser使用的地方,这个我们在前面SQL的一生中已经介绍到了,直接就可以找到,在 TiDB/Session/session.go 文件中,找到 func (s *session) Parse(ctx context.Context, sql string) ([]ast.StmtNode, error) 这个方法:
// Parse parses a query string to raw ast.StmtNode.func (s *session) Parse(ctx context.Context, sql string) ([]ast.StmtNode, error) {charsetInfo, collation := s.sessionVars.GetCharsetInfo()parseStartTime := time.Now()stmts, warns, err := s.ParseSQL(ctx, sql, charsetInfo, collation)......return stmts, nil}
简化代码,后面大部分是错误处理,和处理信息或警告的相关代码,先不管,主要内容就这么两句,第一个获取连接中的字符集和排序规则,这是我们解析所需要的参数,然后就转到s.ParseSQL(ctx, sql, charsetInfo, collation)中,进一步处理:
func (s *session) ParseSQL(ctx context.Context, sql, charset, collation string) ([]ast.StmtNode, []error, error) {if span := opentracing.SpanFromContext(ctx); span != nil && span.Tracer() != nil {span1 := span.Tracer().StartSpan("session.ParseSQL", opentracing.ChildOf(span.Context()))defer span1.Finish()}defer trace.StartRegion(ctx, "ParseSQL").End()s.parser.SetSQLMode(s.sessionVars.SQLMode)s.parser.EnableWindowFunc(s.sessionVars.EnableWindowFunction)return s.parser.Parse(sql, charset, collation)}
这段代码也相当简单,上面还是做一个全局跟踪的记录,下面则是获取两个参数,第一个是SQL解析模式,对应的是MySQL中的 sql_mode,使用默认的。第二个是是否开启窗口函数,这是MySQL 8.0 中添加的新特性,有兴趣的可以多了解下。设置完成后继续调用s.parser.Parse(sql, charset, collation),我们继续跟进:
// Parse parses a query string to raw ast.StmtNode.// If charset or collation is "", default charset and collation will be used.func (parser *Parser) Parse(sql, charset, collation string) (stmt []ast.StmtNode, warns []error, err error) {......var l yyLexerparser.lexer.reset(sql)l = &parser.lexeryyParse(l, parser)......return parser.result, warns, nil}
终于,我们到了Parser这个库下面来了(这个地方如果使用了Goland,并且开启了GoRoot下的文件索引,那么按住Ctrl 点击方法名,会直接跟进到Parser库中,比较方便)。我么来看看代码,方法比较简单,很直观,声明了一个 yyLexer ,然后调用了 yyParser 这个方法,大概就这么两个过程,这个地方我们就需要联系到前面讲到的知识了,Lexer是词法解析器,Parser是语法解析器,前面也讲到了 一般的话,解析器是由 Lex&Yacc工具生成的,但是在Go语言中,只有Yacc工具实现,叫做 goYacc,没有成熟的Lex实现,所以TiDB中的Lex实现是手码出来的,在 Parser/lexer.go 中,它实现了 goYacc 要求的接口,前面我们讲了词法解析器的功能,这个地方不再进去详细看了,大家有兴趣可以研究一下具体实现。
重点来了,当有了Lexer后,需要语法解析器了,也就是 yyParse(l, parser) 这个方法,如果大家直接点进去了,可能会呆住(我第一次点进去惊了),你的编译器也会呆住(卡住),因为这个文件非常大,它有1.9W行的代码,将近2W行,这个文件是由 goYacc 工具生成的,一开始我是跟着断点走进来的,所以忽略了这一点,直接看代码去了,由于是自动生成的,代码没有多少备注,参数非常多,一开始我就是跟着断点一直走这一串逻辑,浪费了很多时间,而且编译器在这个文件中,每走一步都需要花费将近半分钟,你大概就能懂我跑一句SQL解析耗费了大量时间去看这个方法逻辑。其实它的功能还好理解的,也就是我们前面讲到的,用Lexer解析出来的Token 生成一颗抽象语法树,对于这个文件,你只用知道这点就好,具体的你不需要了解(除非你很有兴趣或者需求),现在好了,我们知道他是由规则自动生成的方法,所以我们主要重点应该放在规则文件上,也就是 Parser/parser.y 这个文件中,点进去,这个文件也不小,将近1.3W行。
parser.y文件中的结构和内容,我们在上面简单的讲到过,只不过这里的更加复杂,规则更加的多,这里还是简单的在分析一下:
%{最先会看到这个大括号里面主要是些声明引入的包等等这个括号中的内容会原封不动的出现在生成文件里面 (就是parser.go这个文件里)%}// 下面就是一个联合体,这个联合体会翻译成一个结构体,在parser.go中会找到相对应的结构体yySymType,主要用来从保存在解析过程中被压入堆栈的项的属性和类型,可以是终结符或者非终结符/*type yySymType struct {yys intoffset int offsetitem interface{}ident stringexpr ast.ExprNodestatement ast.StmtNode}*/%union {offset int // offsetitem interface{}ident stringexpr ast.ExprNodestatement ast.StmtNode}// 这些就是定义Toke(终结符)和表达式(非终结符),还有符号的优先级,结合类型%token <ident>%token <item>%token not2%type <expr>%type <statement>.......%precedence sqlCache sqlNoCache%precedence lowerThanIntervalKeyword%precedence interval%precedence lowerThanStringLitToken%precedence stringLit......%right assignmentEq%left pipes or pipesAsOr%left xor%left andand and%left between......// 上面是第一部分,由%%分割后进入第二部分,也就是定义规则,上面我们举了个简单的列子,这里的明显要更加复杂点// 除了匹配Token并不段向上结合外,我们还会发现它在匹配到相对应的句型后有一个大括号,里面action 则是匹配成功后,进行的一些操作,比如说构建树节点// 这个地方在我刚开始发的官方讲解文档中有一个小例子,如果还是有疑惑,可以在看看%%// 产生式和Alter Table的语法是对应的AlterTableStmt:"ALTER" IgnoreOptional "TABLE" TableName AlterTableSpecListOpt AlterTablePartitionOpt// 当匹配到上面的句型时,就会进行括号中的操作{// $5 表示句型中的第五个 也就是 AlterTableSpecListOpt 这个部分// 相同道理$1 就是 ALTER $2 就是 IgnoreOptional .....// $$ 就代表这整个语句specs := $5.([]*ast.AlterTableSpec)if $6 != nil {specs = append(specs, $6.(*ast.AlterTableSpec))}$$ = &ast.AlterTableStmt{Table: $4.(*ast.TableName),Specs: specs,}}| "ALTER" IgnoreOptional "TABLE" TableName "ANALYZE" "PARTITION" PartitionNameList AnalyzeOptionListOpt{$$ = &ast.AnalyzeTableStmt{TableNames: []*ast.TableName{$4.(*ast.TableName)}, PartitionNames: $7.([]model.CIStr), AnalyzeOpts: $8.([]ast.AnalyzeOpt)}}| "ALTER" IgnoreOptional "TABLE" TableName "ANALYZE" "PARTITION" PartitionNameList "INDEX" IndexNameList AnalyzeOptionListOpt{$$ = &ast.AnalyzeTableStmt{TableNames: []*ast.TableName{$4.(*ast.TableName)},PartitionNames: $7.([]model.CIStr),IndexNames: $9.([]model.CIStr),IndexFlag: true,AnalyzeOpts: $10.([]ast.AnalyzeOpt),}}// 最后上面这个产生式 AlterTableStmt 构建出来的结构对应的就是下面这个结构体, 在 ast/ddl.go 中// AlterTableStmt is a statement to change the structure of a table.type AlterTableStmt struct {ddlNodeTable *TableNameSpecs []*AlterTableSpec}......
有了规则文件,就可以通过规则文件来生成解析器了,也就是这里的parser.go,利用goYacc工具,这个地方大家可能会遇到一个坑,那就是我们的Go环境中原本就有这个工具,又或者你自己去Github 上面拉取了goYacc的代码,自己在本地build 一个exe执行文件,然后放到 $GOPATH/bin 下面,然后执行下面的命令:
goyacc -o parser.go parser.y
就会发现报错:

原因是TiDB对于goYacc做了一些修改,大家其实直接在Parser这个库的文件夹下面就会发现有一个goyacc的文件,所以我们直接在这个里面build一下,就会出现一个goyacc.exe的执行文件,再放到 $GOPATH/bin 下面,再去跑上面那个命令就能成功了。
到了这里我们对TiDB中的Parser模块就有了一个基本的了解,同时也知道数据库中是如何将一句SQL解析成制定的树结构的,其实讲的还是偏基础和入门,但是有了这么一些的基础后,我们就知道如何入手修改这个模块,增加更多的解析规则,从而支持原本并不支持的一些语句。
有句道:万事开头难,有了这个开头后,我们便有了切入点,找准这个切入点,继续深入,就可以去优化和改进这些模块,增加更多需求,当然开头难了,后面也许会更难,所以需要更多的精力去学习。
最后希望这篇文章能帮你在TiDB的学习路上轻松那么一点点,后面我还会继续记录我的学习路程(很有可能会从入门到放弃)。
出处:https://zhuanlan.zhihu.com/p/313497250
