






1
名词解释:
Grid vs Cluster:Grid 强调环境的异构性,系统中同一功能的组件可以有不同的配置,Cluster 强调环境的同构型,系统中同一功能的组建配置相差不大。
IMDG(内存数据网格):一种数据全分布在多个服务器内存里面存储的数据结构;内存作为数据存储;分布式存储网络;对象存储模式(通常采用K/V模式);服务节点都是Active状态;服务节点需要经常性增加或者减少(Hazelcast、Terracotta Enterprise Suite; Gemfire、Coherence、Gigaspaces XAP Elastic Caching Edition、IBM eXtreme Scale、JBoss Infinispan)。
Data Fabric:将数据孤岛(不同业务系统之间,以及事务性数据库、数据仓库、数据湖、日志,半结构化和非结构化数据源、应用存储、社交媒体存储和云存储)之间数据全部连接打通形成通畅的数据通路,以方便应用程序之间连接和数据共享的方式 (NetApp、MapR等)。
Data Lake:所有数据存储的数据湖。
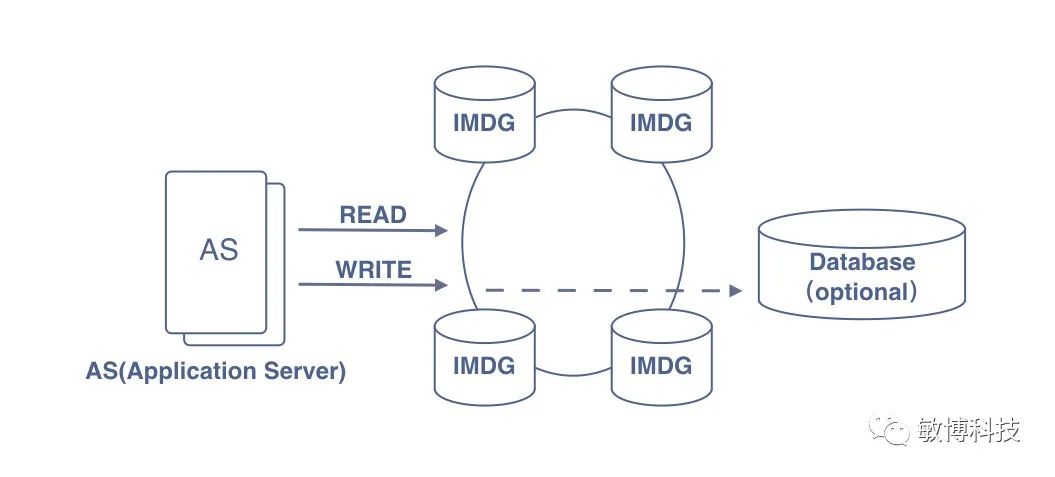
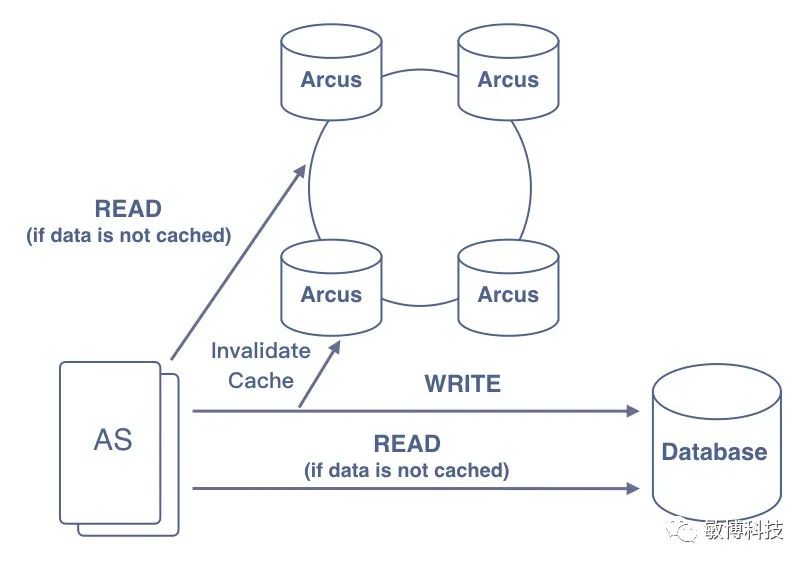
IMDG 技术架构
Ignite 应用场景
纯内存存储:
同时支持数据持久化到本地磁盘
多模数据库:
对内存分页管理,使用K/V存储结构将数据存储到内存页中,支持SQL语法操作数据
事务型数据库:
在K/V层支持事务,未来在SQL层会支持事务
微服务平台架构:
拥有在同一套计算资源上实现存储和业务处理服务的能力,所以ignite可以直接支持微服务架构
内存数据存储网络:
大数据加速器、Web服务会话管理、Spring 缓存、集群管理
高吞吐量的ACID事务处理 缓存即服务 数据库缓存 实时欺诈检测 IoT项目中的复合事件处理 实时分析 HTAP程序 快速数据处理或者lambda架构中的数据流处理
Ignite 应用场景技术架构
数据缓存与高吞吐率事务处理

数据缓存
应用程序无需重新编写:支持ORM、作为Mybatis、Hibernate的二级缓存 除作为应用程序缓存,也可以作为BPM、ESB的缓存(BPM存储业务应用的上下文在数据库中,ESB在应用程序之间共享和传输数据与状态)
网购(电商平台)、信用卡、借记卡、广告营销等通常需要高吞吐率事务处理 Ignite可以用本地持久化来保存提交的事务,以提高运行时的事务处理性能
HTAP
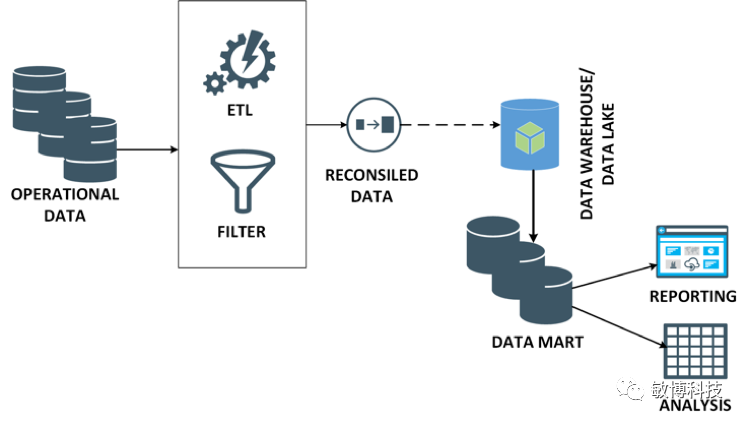
系统组件多,维护成本高 为了发挥历史数据的作用,OLAP系统要存储很多历史数据进行分析,所以存储成本越来越高 难以做到实时分析(因为数据要从OLTP系统传输到OLAP系统)


内存数据库可以用来做OLTP事务,数据分析可以利用Ignite的持久化功能进行获取和分析 在多种数据分析、数据挖掘功能的情况下,Ignite可以同步持久化到Cassandra系统中,由Cassandra来提供分析功能,而且这中间也是没有ETL时延的
FastData & BigData
FastData
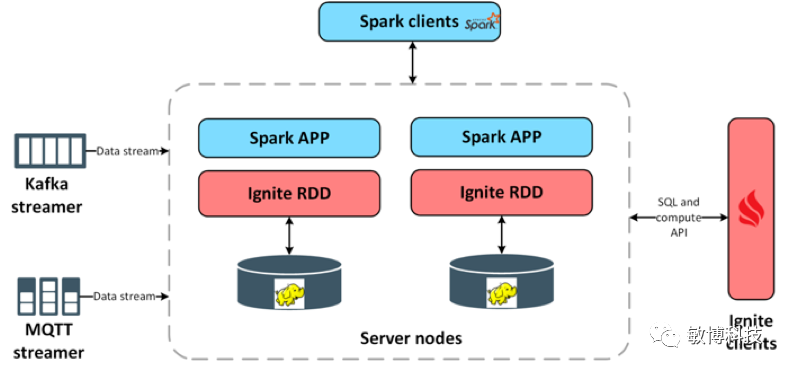
弹性可扩展以及容错的方式来处理流式数据 Ignite支持以规则引擎模式处理数据和流引擎模式处理数据 Ignite支持Spark RDD和DataFrame API,这样不仅可以处理流数据中的关联关系和发现数据中的一些模式,同时也可以加快数据处理效能
BigData Acceleration
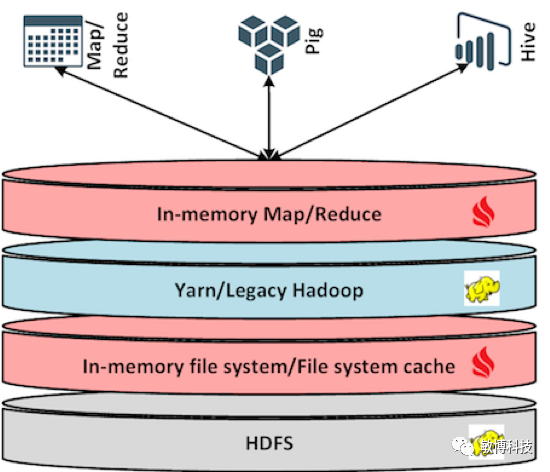
Ignite提供了多种有用的组件来支持Hadoop的MapReduce任务运行在内存里面以及一些文件系统操作,它支持自动将一些必要的库和程序跨JVM在内存里面发布,可以将任务启动时间缩小到毫秒级
因为Ignite里面也集成了MapReduce的执行引擎,所以MapReduce程序可以不用修改任何代码即可在Ignite上运行,这个特别适合已经建立好了Hadoop环境的机构
Legacy Lambda
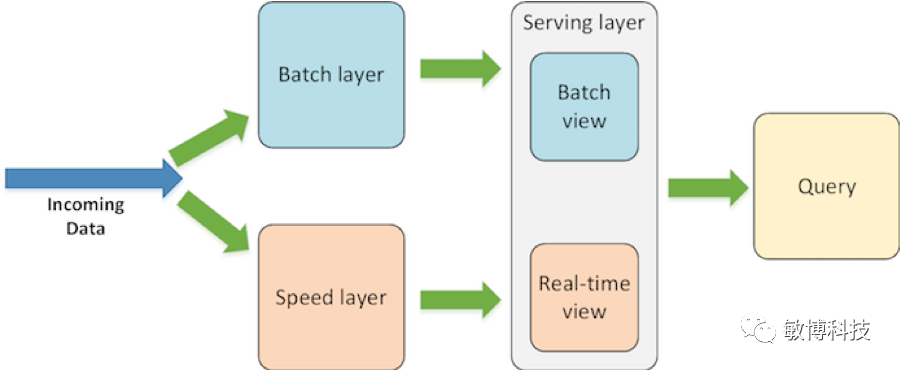
数据传送两份,一份作为批处理,一份作为实时处理(流处理/快速处理),不更改原始数据,批处理程序提前将需要查询的数据进行预处理变成批量视图,实时处理程序处理实时数据弥补批处理延时过高的不足形成实时视图,查询结果汇集批量视图和实时视图
批处理:一次写入,多次大块读;实时处理:随机读写,增量计算;服务层:随机读,批量计算和批量写入操作
实时处理:Hadoop&Spark,实时处理:Storm;服务层:Hive
Ignite Lambda
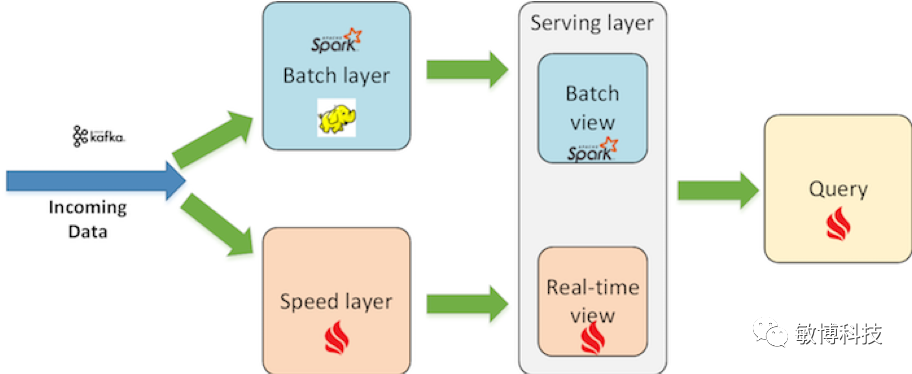
使用Ignite作为实时处理或者查询处理部分任务
批处理:Hadoop&Spark,实时处理:Ignite;服务层:Hive&Ignite

欲盘更多干货,且看(下)集分解

MemFire Cloud是基于MemFireDB云原生和线性扩展能力而打造的数据库云服务,致力于为互联网用户提供一站式数据库自助服务,实现按需使用,随用随取,最大化的节约成本,加速用户的业务创新。

