





水有源,故其流不穷;
木有根,故其生不穷。
宋·胡宏《胡子知言·好恶》
摘要:本文由以数据之名分享,正所谓“河水背离源头就会枯竭,树木脱离树根不能生长”。源端数据源犹如源头活水,CDC(Capture Data Change,即捕获变化数据,可以基于增量日志,以极低的侵入性来完成增量数据捕获的工作)工具恰似取水利器。前面的这篇文章“Kettle插件开发之MQToSQL”,叙述了使用Kettle+Oracle GoldenGate双剑合璧,来提升ETL同步效率的经典增量同步场景。今天,我们跟着小编的节奏,继续看看新鲜出炉的“CDC工具选型秘籍之葵花宝典”,做到“源头活水自然来,增量抽取天然开”。
01
—
Oracle GoldenGate (非开源+软件免费&服务收费,****)
“Oracle GoldenGate”属于Oracle Fusion Middleware产品线,底层开发语言为Java,用于支持异构数据环境中的数据复制。
该产品集支持高可用性解决方案、实时数据集成、事务变更数据捕获、数据复制、转换以及运营和分析企业系统之间的验证。简而言之,Oracle GoldenGate 提供异构环境间事务数据的实时、低影响的捕获、路由、转换和交付。
源码地址:不开源
管理平台:Management Pack for Goldengate Director,不开源
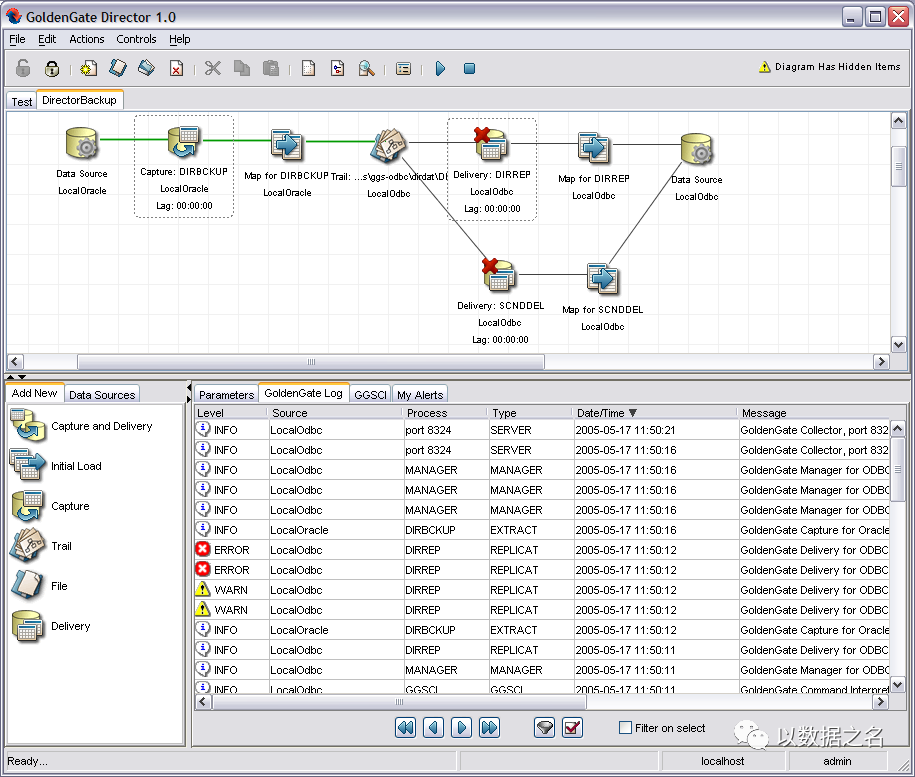
官方文档:https://docs.oracle.com/en/middleware/goldengate/big-data/12.3.2.1/index.html
部署手册:https://docs.oracle.com/en/middleware/goldengate/core/18.1/release-notes/introduction.html#GUID-54EFF08B-F901-49C9-BEAC-5B261301045A
架构原理:
一句话概括:基于日志捕获技术的实时增量数据集成。
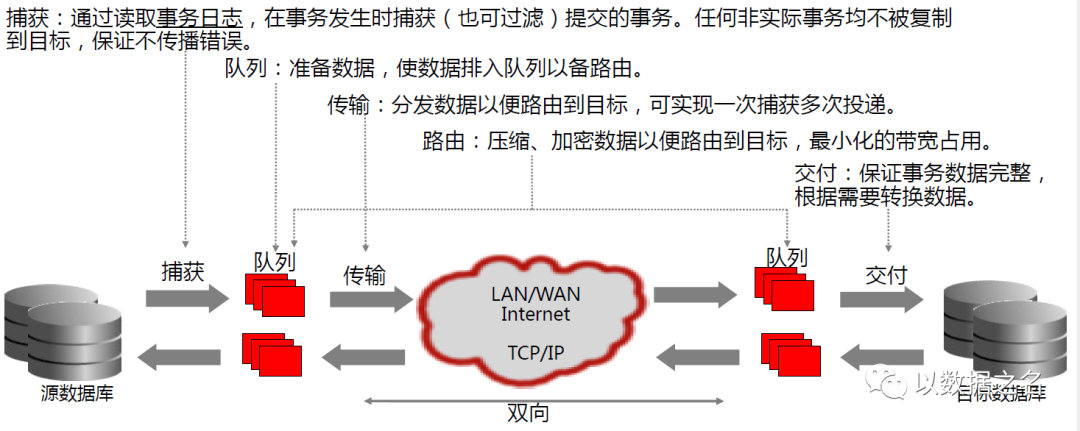
捕获Capture:通过读取事务日志,在事务发生时捕获Capture(也可配置Filter/Map实现过滤)提交的事务。任何非实际事务均不被复制到目标,保证不传播错误。
传输Data Pump:接收队列路由数据,并分发数据以便路由到目标,可以实现一次捕获多次投递
交付Replicat:接收通过网络传输,接收路由数据,保证事务数据完整,并根据需要转换数据。
产品特点:
底层开发语言为Java,可以二次开发消息分区插件等
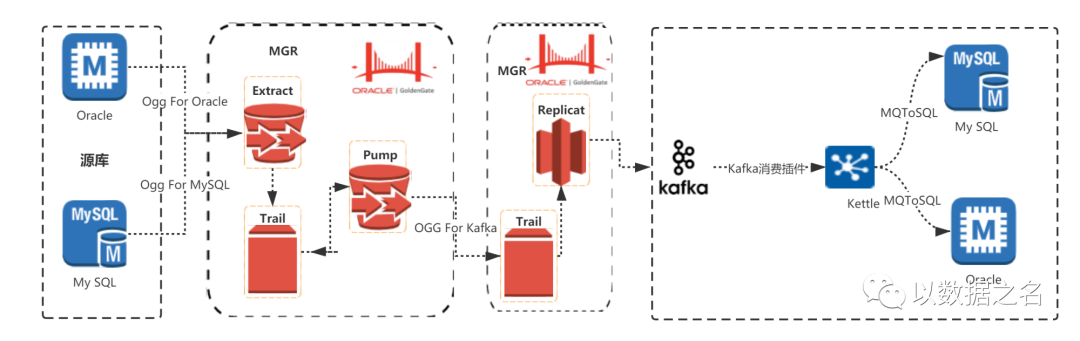
查看源码:ggjava/resources/lib/ggkafka-****.jar
核查关键配置:OGG与Kafka相关的配置类 oracle.goldengate.handler.kafka.impl.KafkaProperties、
Kafka默认的分区类如下,也可以自定义实现分区类代码org.apache.kafka.clients.producer.internals.DefaultPartitioner
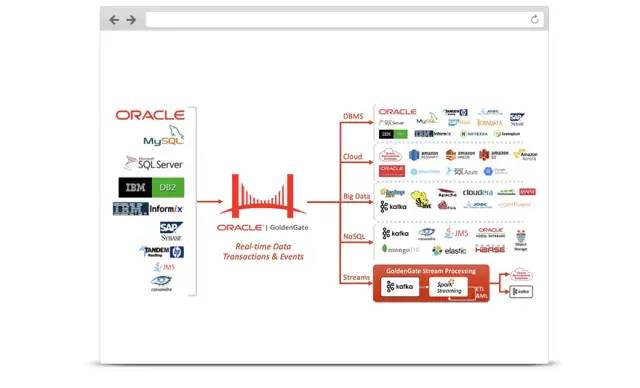
丰富的源端数据源和目标数据源支持,具体如下图
源端:MySQL、Oracle、SQLServer、DB2、SAP、JMS、Teradata等。
目标:RDBMS(Oracle、MySQL等)、Cloud(Amazon S3、Oracle Cloud等)、BigData(HDFS、Kafka等)、NoSQL(HBase、Elastic等)、Streams(Kafka Streams、Spark Streaming等)
非侵入
不建触发器,不建中间表,无需增量标记或时间戳字段
不在源表上进行数据查询
低影响
直接部署和运行在源端数据服务器时,CPU使用率<3%,内存和网络带宽要求极低
高实时
单条数据同步链路可以持续维持>160GB/小时的数据库日志处理能力,同步延迟在10秒之内
异构的源和目标
广泛支持异构硬件平台和操作系统下的多种不同数据库类型及版本,包括文件和消息队列
可靠性和事务完整
保障事务完整性和顺序
失败后自动从断点恢复,数据不重复、不遗漏
丰富的业务场景支持,具体可以覆盖如下:
数据库容灾/应急
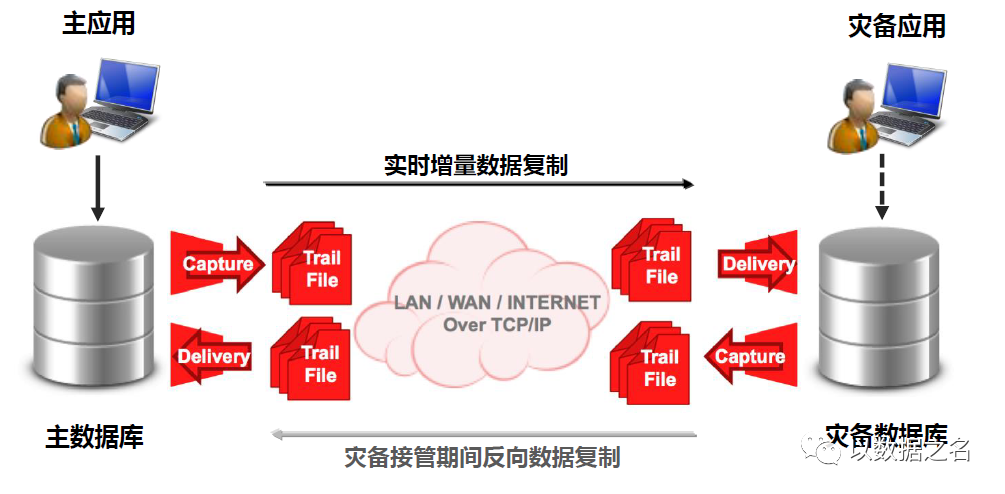
系统迁移/升级/维护
查询分载/集中查询
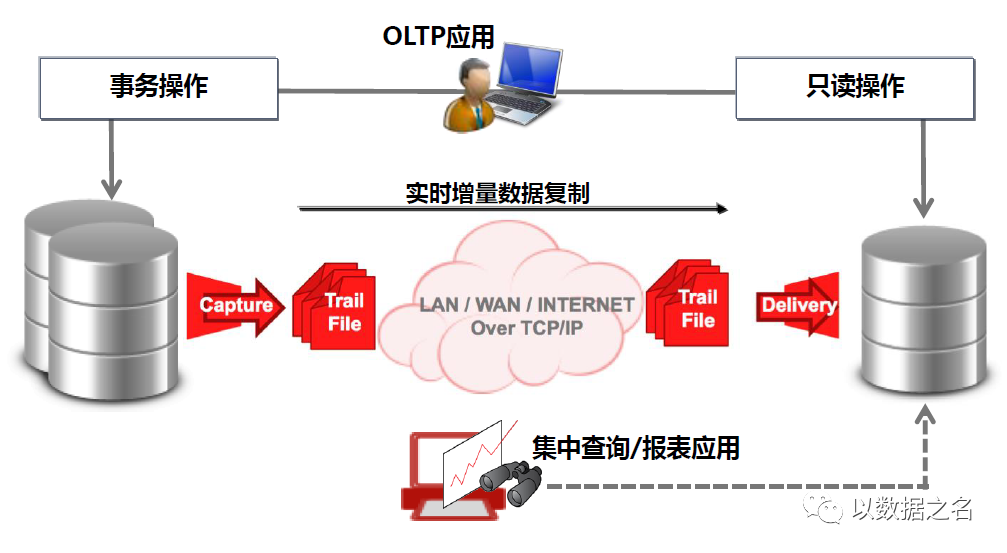
双活/多主数据中心
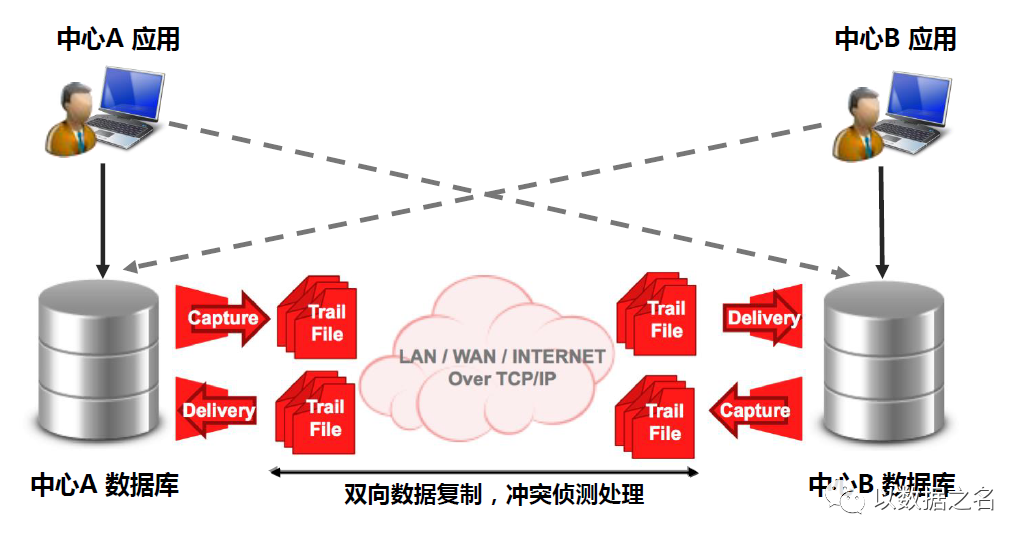
实时数据仓库/BI
数据集中/分发/同步
事件驱动集成
有条件可以尝试免费试用,但服务收费哦!
02
—
RedHat Debezium (开源,*****)
“RedHat Debezium”属于小红帽RedHat公司开源的一款CDC工具,用于支撑将多种数据源实时变更数据捕获,形成数据流输出的开源神器。
Debezium 是一组分布式服务,用于捕获数据库中的更改,以便您的应用程序可以看到这些更改并对其做出响应。Debezium 将每个数据库表中的所有行级更改记录在一个更改事件流中,应用程序只需读取这些流以查看更改事件发生的顺序。
源码地址:https://github.com/debezium
管理平台:https://github.com/debezium/debezium-ui
官方文档:https://debezium.io/documentation/
部署手册:https://debezium.io/documentation/reference/1.6/install.html
架构原理:
一句话概括:基于日志完成变更数据捕获管道的架构。
部署方式一、通过 Apache Kafka Connect部署 Debezium,Kafka Connect 是一个用于实现和操作的框架和运行时:
将记录发送到 Kafka 的源连接器,例如 Debezium
将记录从 Kafka 主题传播到其他系统的接收器连接器
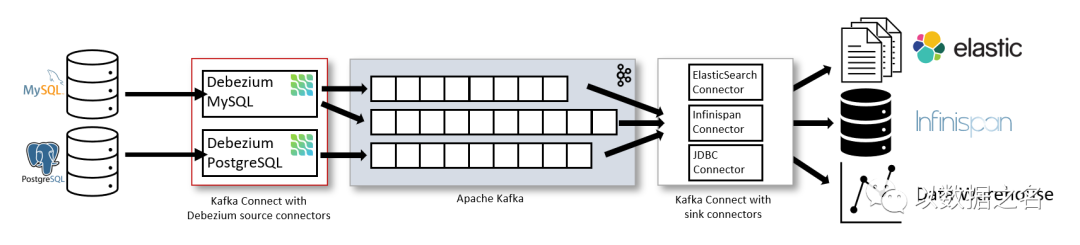
如图所示,部署了用于 MySQL 和 PostgresSQL 的 Debezium 连接器以捕获对这两种类型数据库的更改。每个 Debezium 连接器都建立与其源数据库的连接:
MySQL 连接器使用客户端库来访问
binlog
.PostgreSQL 连接器从逻辑复制流中读取。
除了 Kafka 代理之外,Kafka Connect 还作为单独的服务运行。
部署方式二、通过Debezium 服务器部署Debezium。Debezium 服务器是一个可配置的、随时可用的应用程序,它将更改事件从源数据库流式传输到各种消息传递基础设施。
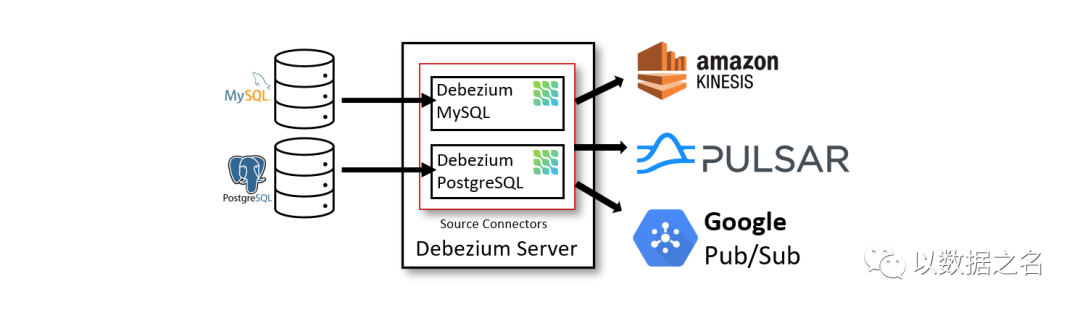
Debezium 服务器配置为使用 Debezium 源连接器之一来捕获源数据库中的更改。更改事件可以序列化为不同的格式,例如 JSON 或 Apache Avro,然后将发送到各种消息传递基础设施之一,例如 Amazon Kinesis、Google Cloud Pub/Sub 或 Apache Pulsar。
产品特点:
底层开发语言为Java,可以自定义二次开发
丰富的连接器支持,具体如下图
源端:MySQL、Oracle、SQL Server、Db2、PostgreSQL、MongoDB、Cassandra (Incubating)、Vitess (Incubating)等。
目标:Apache Kafka、Apache Pulsar、Amazon Kinesis等
基于日志的 CDC,确保捕获所有数据更改
通过读取数据库的日志,您可以获得所有数据更改的完整列表
事件延迟极低,同时避免增加 CPU负载
基于日志的 CDC 允许您近乎实时地对数据更改做出反应,而无需花费 CPU 时间反复运行轮询查询。例如,对于 MySQL 或 PostgreSQL,延迟在毫秒范围内。
对数据模型无影响
不需要确保写入应用程序或通过触发器捕获的所有表上严格维护更新时间戳
可以捕获删除
可以捕获旧记录状态和其他元数据
根据源数据库的功能,基于日志的 CDC 可以为更新和删除事件提供旧记录状态。也可以提供模式更改流(例如以应用的 DDL 语句的形式)并公开额外的元数据,例如事务 ID 或应用特定更改的用户
web端管理工具debezium-ui,配置和运维快速便捷
如果源端连接器支持,推荐使用,毕竟开源是王道!
03
—
Zendesk Maxwell (开源,***)
“Zendesk Maxwell”属于Zendesk公司开源的一款 MySQL CDC产品,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
This is Maxwell's daemon, an application that reads MySQL binlogs and writes row updates as JSON to Kafka, Kinesis, or other streaming platforms. Maxwell has low operational overhead, requiring nothing but mysql and a place to write to. Its common use cases include ETL, cache building/expiring, metrics collection, search indexing and inter-service communication. Maxwell gives you some of the benefits of event sourcing without having to re-architect your entire platform.
源码地址:https://github.com/zendesk/maxwell
管理平台:无
官方文档:http://maxwells-daemon.io/config/
部署手册:http://maxwells-daemon.io/quickstart/
架构原理:
一句话概括:Maxwell是一个能实时读取MySQL二进制日志binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka、RabbitMQ、Redis或其他流媒体平台的应用程序。
支持 SELECT * FROM table 的方式进行全量数据初始化
支持在主库发生failover后,自动恢复binlog位置(GTID)
可以对数据进行分区,解决数据倾斜问题,发送到kafka的数据支持database、table、column等级别的数据分区
工作方式是伪装为Slave,接收binlog events,然后根据schemas信息拼装,可以接受ddl、xid、row等各种event
产品特点:
底层开发语言为Java,可以自定义二次开发
丰富的连接器支持,具体如下图
源端:MySQL
目标:Apache Kafka、Amazon Kinesis、Nats、Google Cloud Pub/Sub、RabbitMQ、Redis、SNS等。
丰富业务场景支撑,具体可以覆盖以下场景
ETL
维护缓存
收集表级别的dml指标
增量到搜索引擎
数据分区迁移
切库binlog回滚方案等
如果源端为MySQL,推荐可以尝试使用,毕竟开源是王道!
04
—
Alibaba Canal (开源,****)
“Alibaba Canal”属于阿里巴巴公司开源的一款 MySQL CDC产品,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
源码地址:https://github.com/alibaba/canal
管理平台:https://github.com/alibaba/canal/wiki/Canal-Admin-QuickStart
官方文档:https://github.com/alibaba/canal/wiki
部署手册:https://github.com/alibaba/canal/wiki/QuickStart
架构原理:
一句话概括:基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
一、Canal 架构图
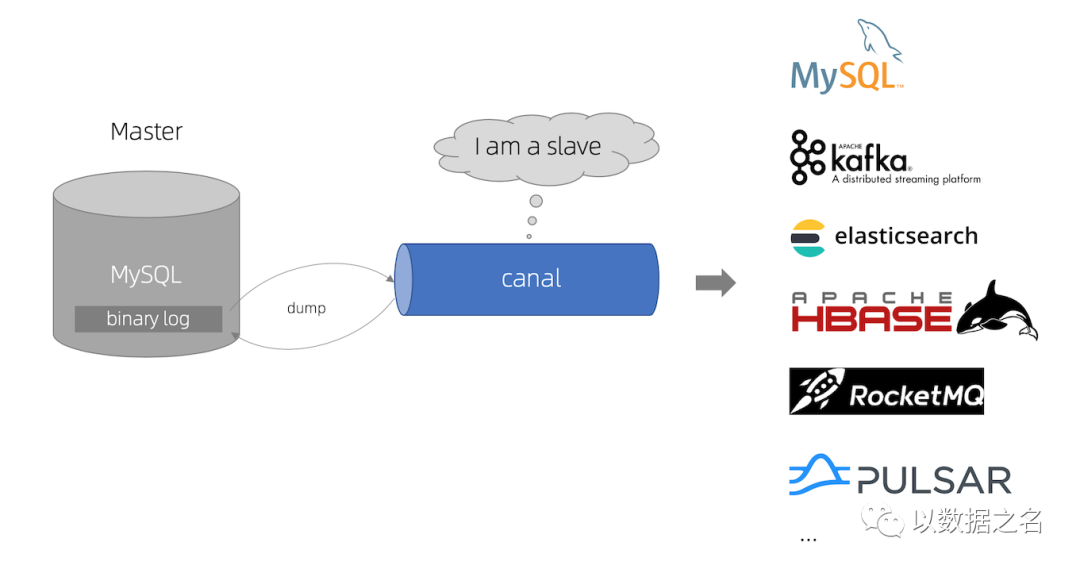
Slave模拟,Master Dump协议:canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
接收Master Dump,推送Slave:MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
解析 binary log 对象,完成CDC推送:canal 解析 binary log 对象(原始为 byte 流),推送至目标端
二、Canal HA架构图
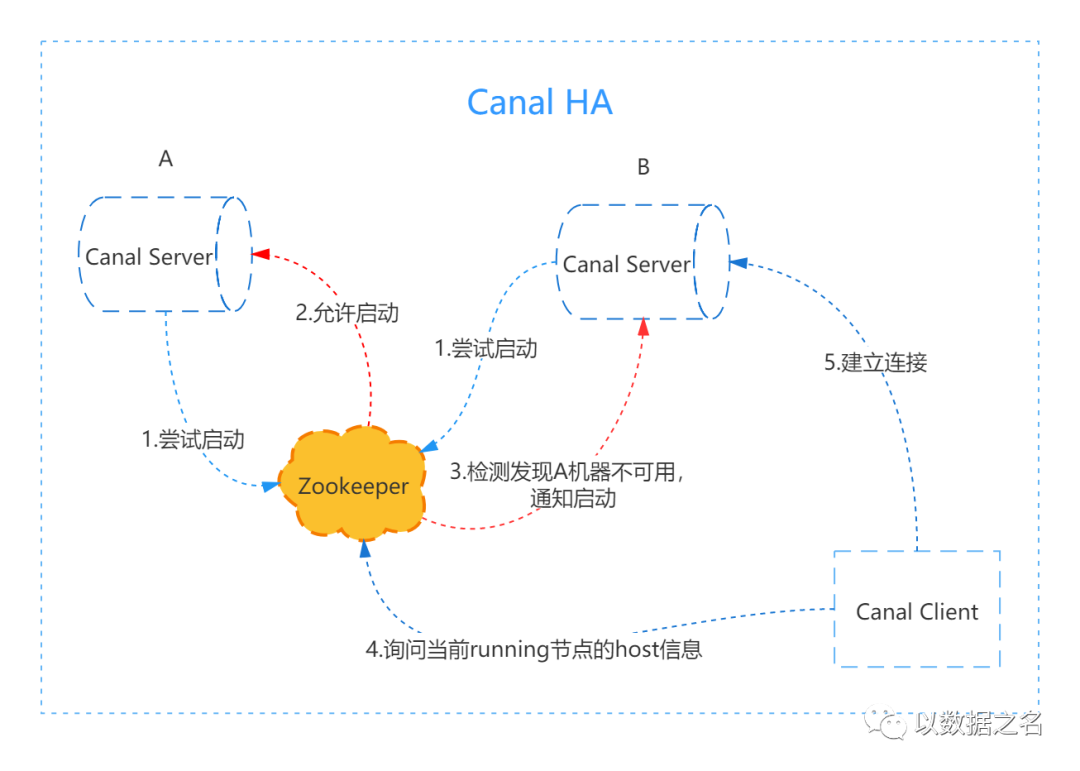
产品特点:
底层开发语言为Java,可以自定义二次开发
丰富的连接器支持,具体如下图
源端:支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
目标:MySQL、Apache Kafka、Elasticsearch、Apache HBase、RocketMQ、Plusar等。
丰富业务场景支撑,具体可以覆盖以下场景
数据库镜像
数据库实时备份
索引构建和实时维护(拆分异构索引、倒排索引等)
业务 cache 刷新
带业务逻辑的增量数据处理
web端管理工具canal-admin,配置和运维快速便捷
阿里还有另外两款产品Otter、yugong,可以了解下
如果源端为MySQL,推荐使用,毕竟开源是王道!
05
—
mysql_streamer (开源,***)
“mysql_streamer”属于Yelp公司开源的一款 MySQL CDC产品,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
Yelp的实时流平台的一个重要用途就是将数据变更流出去,从而让下游的子系统可以处理它们并保持数据更新。有两类我们要知道的SQL变更事件:
数据定义语言(Data Definition Language,DDL ):定义或者修改数据库结构或模式;
数据操作语言(Data Manipulation Language,DML ):修改数据行;
MySQLStreamer则负责:
不断从MySQL二进制文件中查看最新的日志,读取这两种类型的事件;
根据事件类型不同而进行相应处理,将DML事件发布到Kafka Topic中;
源码地址:https://github.com/Yelp/mysql_streamer
管理平台:无
官方文档:https://github.com/Yelp/mysql_streamer
https://engineeringblog.yelp.com/2016/08/streaming-mysql-tables-in-real-time-to-kafka.html
部署手册:https://github.com/Yelp/mysql_streamer
架构原理:
一句话概括:MySQLStreamer 是一个数据库更改数据捕获和发布系统。
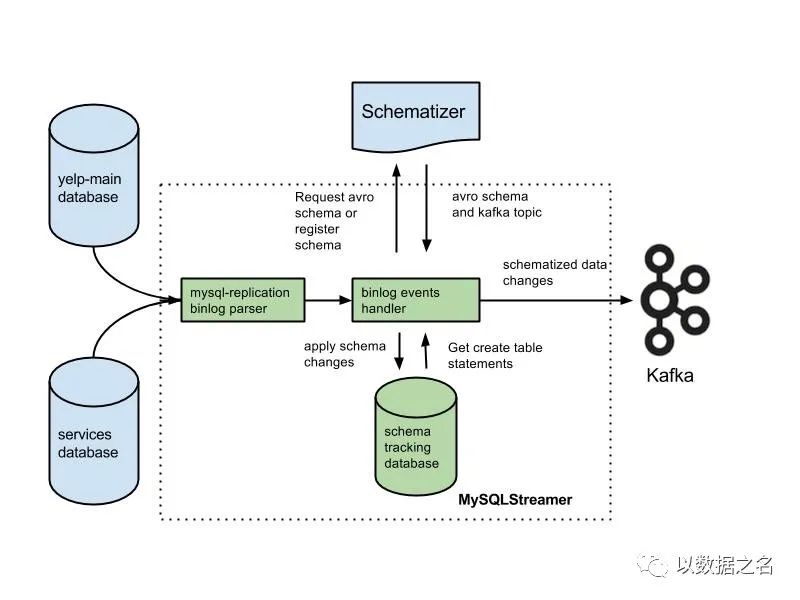
MySQLStreamer 启动时,它会在开始处理任何传入事件之前获取 Zookeeper 锁。为了防止MySQLStreamer 的多个实例在同一个集群上运行。
MySQLStreamer 通过 binlog 解析器从源数据库(如上图所示的 Yelp 数据库)接收事件。
如果多次使用相同的 create table 语句调用它,它将返回完全相同的 Avro 模式和主题。
数据事件使用接收到的 Avro 模式进行编码并发布到 Kafka 主题。数据管道的 Kafka Producer 维护要发布到 Kafka 的内部事件队列。
产品特点:
底层开发语言为Python,可以自定义二次开发
丰富的连接器支持,具体如下图
源端:MySQL 、Cassandra
目标:Apache Kafka、Elasticsearch、Redshift 等。
丰富业务场景支撑,具体可以覆盖以下场景
数据库实时备份
索引构建和实时维护
带业务逻辑的增量数据处理
如果源端为MySQL,推荐可以尝试,毕竟开源是王道!
06
—
Airbnb SpinalTap (开源,**)
“Airbnb SpinalTap”属于Airbnb公司开源的一款 MySQL CDC产品,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
SpinalTap 是一种通用的可靠变更数据捕获 (CDC) 服务,能够以低延迟检测跨不同数据源的数据突变,并将其作为标准化事件传播给下游消费者。
源码地址:https://github.com/airbnb/SpinalTap
管理平台:无
官方文档:https://github.com/airbnb/SpinalTap
部署手册:https://github.com/airbnb/SpinalTap
架构原理:
一句话概括:基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
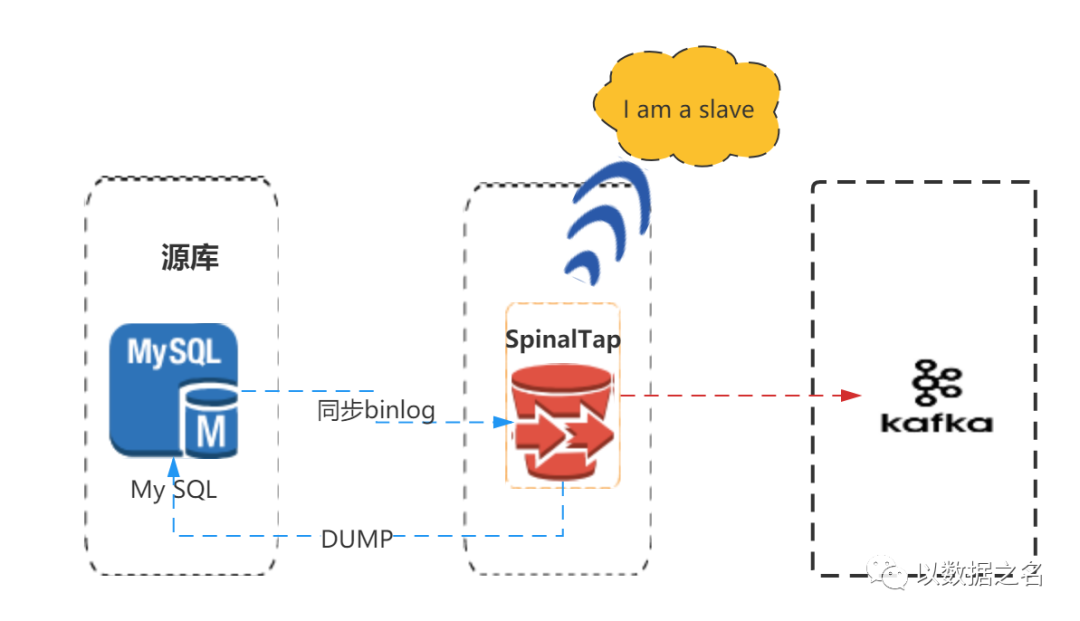
原理同MySQLStreamer 、Canal类似,都是把自己伪装成MySQL Slave实现。
产品特点:
底层开发语言为Java,可以自定义二次开发
丰富的连接器支持,具体如下图
源端:MySQL
目标:Apache Kafka。
源端为MySQL,没啥社区,官网文档太少。可以看看,不推荐使用!
07
—
Netflix DBLog (开源,**)
“Netflix DBLog”属于Netflix公司开源的一款 MySQL CDC产品,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
DBLog是一个基于Java的框架,能够实时捕获更改并获取转储。转储以块的形式获取,以便可以与实时事件交错,并且不会长时间停止实时事件处理。转储可以通过提供的API随时获取。这使得下游用户可以在最初或稍后的修复时捕获完整的数据库状态。
我们设计这个框架是为了尽量减少对数据库的影响。转储可以根据需要暂停和恢复。不管是对于失败后的恢复,还是数据库遇到瓶颈时停止处理,这都很重要。为了不影响应用程序的写操作,我们也不会获取表级锁。
DBLog允许将捕获的事件写入任何输出,甚至是另一个数据库或API。我们使用Zookeeper来存储与日志和转储处理相关的状态,并将其用于群首选举。我们在构建DBLog时考虑到了可插拔性,可以根据需要替换实现(比如用其他东西替换Zookeeper)。
源码地址:暂未开源
管理平台:无
官方文档:https://medium.com/netflix-techblog/dblog-a-generic-change-data-capture-framework-69351fb9099b
部署手册:暂无
架构原理:
一句话概括:对于MySQL我们使用shyiko/ MySQL -binlog-connector来实现binlog复制协议,以便从MySQL主机接收事件。对于PostgreSQL,我们通过wal2json插件使用复制槽,更改通过由PostgreSQL jdbc驱动程序实现的流复制协议接收。
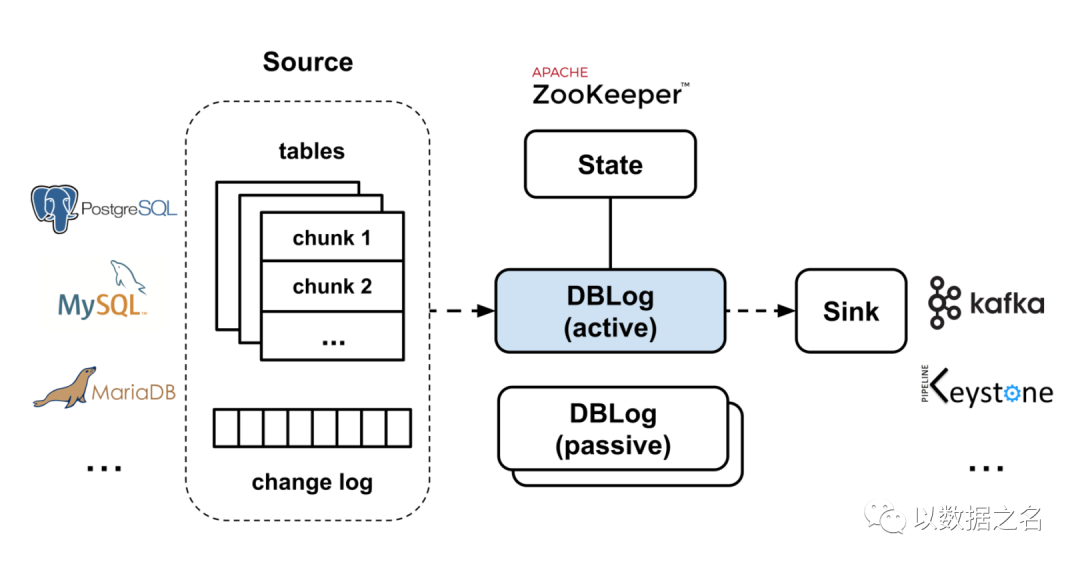
按顺序处理捕获到的日志事件。
转储可以随时进行,跨所有表,针对一个特定的表或者针对一个表的具体主键。
以块的形式获取转储,日志与转储事件交错。通过这种方式,日志处理可以与转储处理一起进行。如果进程终止,它可以在最后一个完成的块之后恢复,而不需要从头开始。这还允许在需要时对转储进行调整和暂停。
不会获取表级锁,这可以防止影响源数据库上的写流量。
支持任何类型的输出,因此,输出可以是流、数据存储甚或是API。
设计充分考虑了高可用性。因此,下游的消费者可以放心,只要源端发生变化,它们就可以收到变化事件。
产品特点:
丰富的连接器支持,具体如下图
源端:MySQL、Postgre SQL、……
目标:Apache Kafka、Keystone、……
转储事件和日志交错,两者都可以进行
允许随时触发转储
不使用表级锁
使用标准的数据库特性
传说很强大,超越CDC。了解下,还不能使用!

10|CDC专题
CDC葵花宝典系列之OGG MySQL For Kafka实战
虽小编一己之力微弱,但读者众星之光璀璨。小编敞开心扉之门,还望倾囊赐教原创之文,期待之心满于胸怀,感激之情溢于言表。一句话,欢迎联系小编投稿您的原创文章!

回复1,获取全平台解压缩密钥
回复2,获取kettle快速入门示例
回复kettle,获取离线和实时数据仓库资料和视频
回复code,获取全平台Kettle插件及实例源码
回复plugin,获取全平台插件Release包
回复ppt,获取全平台分享精彩PPT模板
回复etl,获取Kettle知识库系列资料
回复mysql,获取MySQL中英文指导学习手册
回复mail,获取Kettle实战系列之动态邮件附件
回复block,获取Kettle阻塞组件使用示例
回复multidir,获取Kettle Excel多级目录测试使用示例
