




01 NHANES研究设计
NHANES采用的是复杂多阶段的概率抽样 (a complex, multistage, probability sampling design),并且对某些亚组进行oversampling(不知道中文怎么翻译好,保证有足够的亚组人群纳入研究)。其实这也是之后数据分析较为独特的原因。
多阶段抽样主要包含4个阶段:分别是县 (counties)、城市街区 (segments)、住户 (households)、个人 (individuals)。
02 样本权重
样本权重(sample weight):反映了个体抽样的不等概率,这也是由之前的复杂多阶段抽样造成的。需要在之后的分析过程中进行校正。
03 权重选择
权重的选择需要注意以下四点。
1.所有变量都在in-home interview中收集,采用wtint4yr(注意变量名称,int,多周期的话要注意使用合并权重)。
2.一些变量是在MEC中收集,采用wtmec4yr(注意变量名称,mec,多周期的话要注意使用合并权重)。
3.一些变量是调查子样本的一部分,采用相应子样本的权重,如研究变量中有空腹甘油三酯(接受检测的人大约是接受MEC检查的样本的一半),采用wtsaf4yr,多周期的话要注意使用合并权重。
4.一些变量来自24小时饮食召回(24-hour dietary recall):变量来自第一天的recall,采用wtdrd1;使用两天的recall进行分析,采用wtdr2d,多周期的话要注意使用合并权重。
还需要提醒一点的是:选择样本数量最少的关注变量对应的权重进行校正。
04 多周期权重合并
单个周期样本量偏小,为了扩大样本量,研究者很多时候都会合并多个周期。但权重作为一个相对特殊的变量,是不能直接用原始值的。
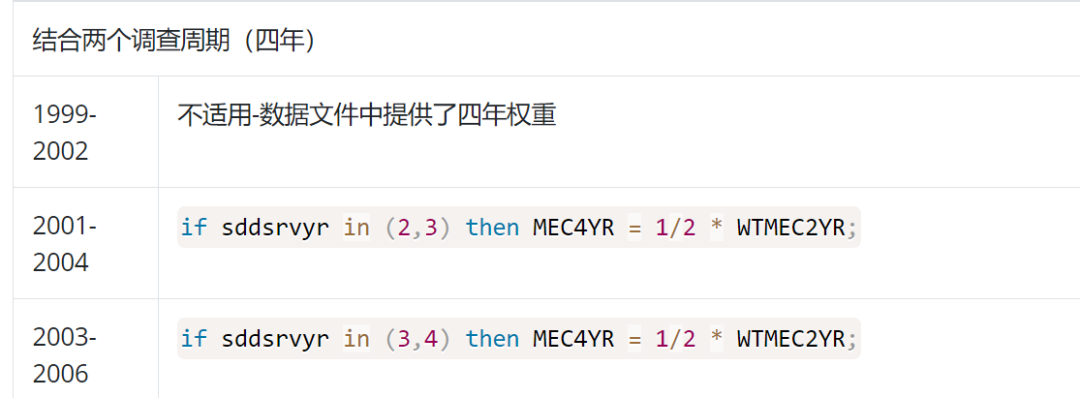
1.分析1999-2002四年(2 cycles)数据时,使用数据集中四年权重,如wtint4yr、wtmec4yr。
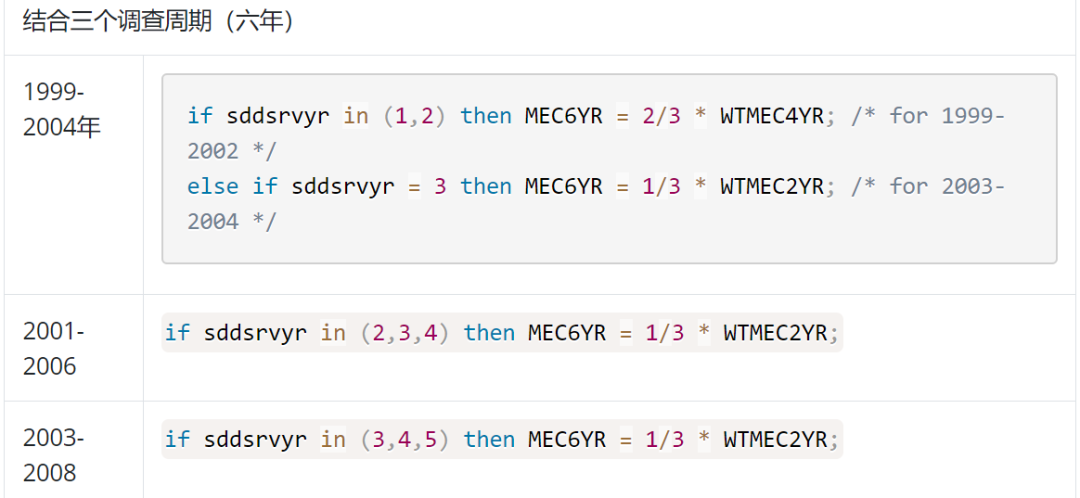
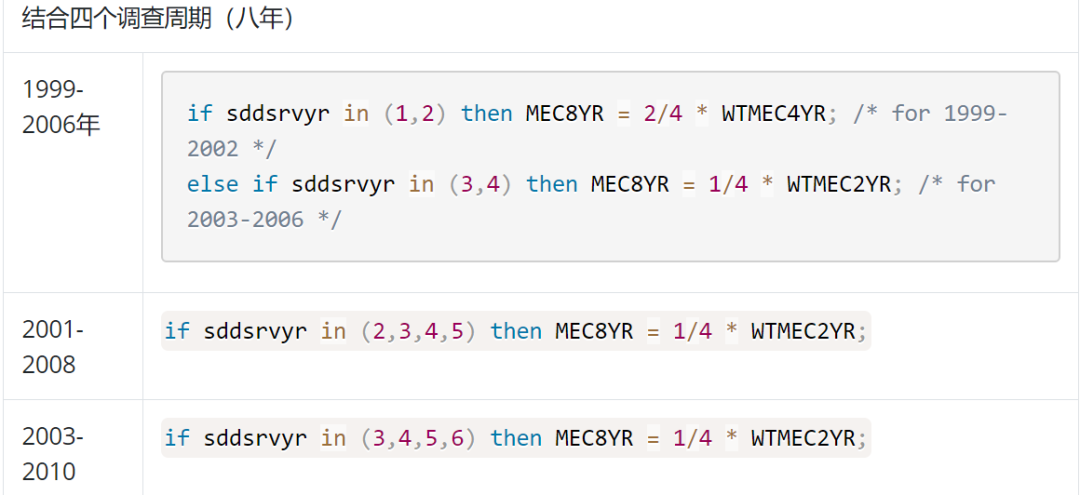
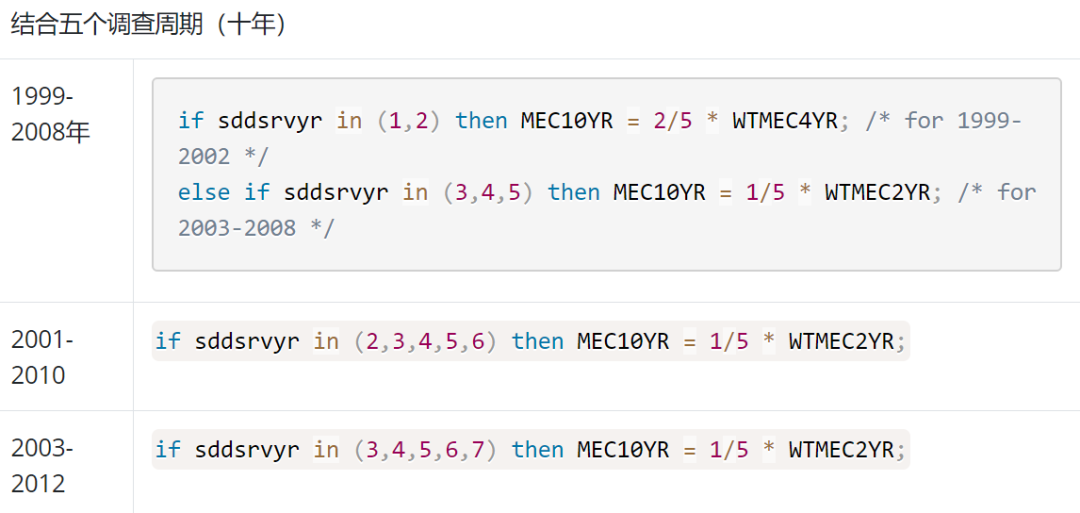
2.2001-2002及以后的样本权重,乘以相应的比例即可,具体见下图。
↑
左右滑动查看更多,需要说明的是sddsrvyr是周期变量,1=1999-2000,2=2001-2002,以此类推
05 样本权重计算与否时的结果区别(以频数、百分比计算结果为例)
未校正权重代码及结果:
* Unweighted interview sample *;proc freq data = demo order=formatted;tables ridreth3 nocum;/*以下5行均为格式设置,整体格式设置代码附在最后*/format ridreth3 r3ordf. ;title "Percent of 2015-2016 sample, by race and Hispanic origin";title2 "Unweighted interview sample";footnote "Non-Hispanic other includes non-Hispanic persons who reported a race other than white, black, or Asian or who reported multiple races.";label ridreth3 ="Race and Hispanic origin";run;
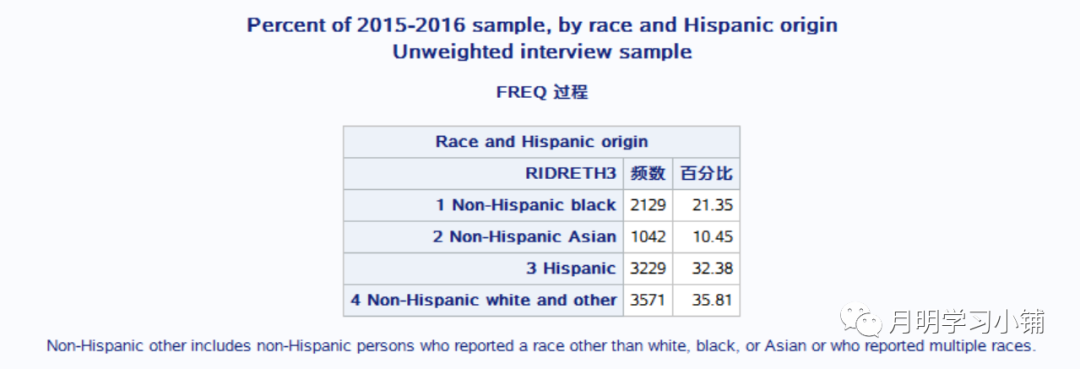
校正权重代码及结果:
* Weighted with interview sample weight *;proc freq data = demo order=formatted;tables ridreth3 nocum ;weight wtint2yr; *以下5行均为格式设置,整体格式设置代码附在最后*/format ridreth3 r3ordf. ;title "Percent of 2015-2016 sample, by race and Hispanic origin";title2 "Weighted with interview weight";footnote "Non-Hispanic other includes non-Hispanic persons who reported a race other than white, black, or Asian or who reported multiple races.";label ridreth3 ="Race and Hispanic origin";run;
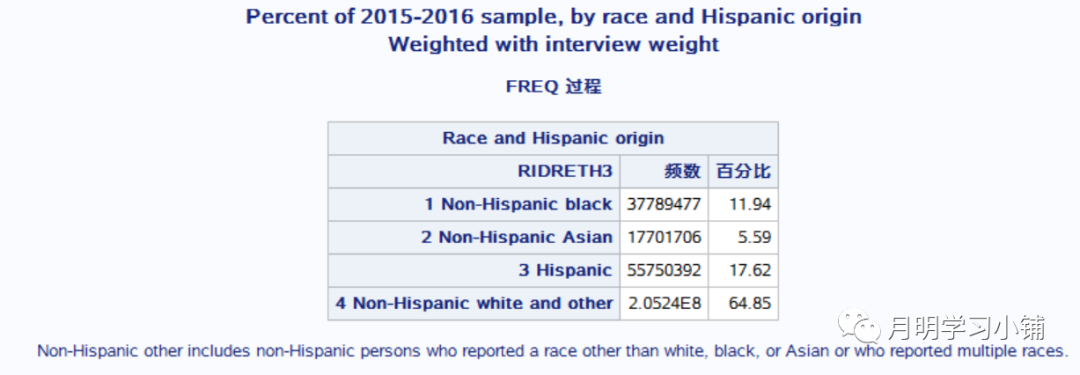
可以看到校正与不校正结果差别还是很大的,校正的结果更符合美国实际人群的分布(美国non-hispanic white other肯定是最多的)。举这个例子的目的就是为了体现校正sample weight的重要性
06 参考内容
https://wwwn.cdc.gov/nchs/nhanes/tutorials/module3.aspx https://wwwn.cdc.gov/nchs/data/tutorials/module3_examples_SAS_Survey.sas
07 整体格式设置代码
*******************;** Download data **;*******************;** Paths to 2015-2016 data files on the NHANES website *;* DEMO demographic *;filename demo_i url 'https://wwwn.cdc.gov/nchs/nhanes/2015-2016/demo_i.xpt';libname demo_i xport;* BPX blood pressure exam *;filename bpx_i url 'https://wwwn.cdc.gov/nchs/nhanes/2015-2016/bpx_i.xpt';libname bpx_i xport;* BPQ blood pressure questionnaire *;filename bpq_i url 'https://wwwn.cdc.gov/nchs/nhanes/2015-2016/bpq_i.xpt';libname bpq_i xport;* Download SAS transport files and create temporary SAS datasets *;data demo;set demo_i.demo_i(keep=seqn riagendr ridageyr ridreth3 sdmvstra sdmvpsu wtmec2yr wtint2yr ridexprg );run;data bpx_i;set bpx_i.bpx_i;run;data bpq_i;set bpq_i.bpq_i;run;** Prepare dataset for hypertension example **;data bpdata;merge demobpx_i (keep = seqn bpxsy1-bpxsy4 bpxdi1-bpxdi4)bpq_i (keep = seqn bpq050a);by seqn;**Hypertension prevalence**;** Count Number of Nonmissing SBPs & DBPs **;n_sbp = n(of bpxsy1-bpxsy4);n_dbp = n(of bpxdi1-bpxdi4);** Set DBP Values Of 0 To Missing For Calculating Average **;array _DBP bpxdi1-bpxdi4;do over _DBP;if (_DBP = 0) then _DBP = .;end;** Calculate Mean Systolic and Diastolic **;mean_sbp = mean(of bpxsy1-bpxsy4);mean_dbp = mean(of bpxdi1-bpxdi4);** "Old" Hypertensive Category variable: taking medication or measured BP > 140/90 **;* as used in NCHS Data Brief No. 289 *;* variable bpq050a: now taking prescribed medicine for hypertension *;if (mean_sbp >= 140 or mean_dbp >= 90 or bpq050a = 1) then HTN_old = 100;else if (n_sbp > 0 and n_dbp > 0) then HTN_old = 0;** Create Hypertensive Category Variable: "new" definition based on taking medication or measured BP > 130/80 **;** From 2017 ACC/AHA hypertension guidelines **;* Not used in Data Brief No. 289 - provided for reference *;if (mean_sbp >= 130 or mean_dbp >= 80 or bpq050a = 1) then HTN_new = 100;else if (n_sbp > 0 and n_dbp > 0) then HTN_new = 0;* race and Hispanic origin categories for hypertension analysis - generate new variable named raceEthCat *;select (ridreth3);when (1,2) raceEthCat=4; * Hispanic ;when (3) raceEthCat=1; * Non-Hispanic white ;when (4) raceEthCat=2; * Non-Hispanic black ;when (6) raceEthCat=3; * Non-Hispanic Asian ;when (7) raceEthCat=5; * Non-Hispanic other race or Non-Hispanic persons of multiple races *;otherwise;end;* age categories for adults aged 18 and over *;if 18<=ridageyr<40 then ageCat_18=1;else if 40 <=ridageyr<60 then ageCat_18=2;else if 60 <=ridageyr then ageCat_18=3;* Define subpopulation of interest: non-pregnant adults aged 18 and over who have at least 1 valid systolic OR diastolic BP measure *;inAnalysis = (ridageyr >=18 and ridexprg ne 1 and (n_sbp ne 0 or n_dbp ne 0)) ;drop bpxsy1-bpxsy4 bpxdi1-bpxdi4;run;**********************************************************************************************;** Estimates for graph - Distribution of race and Hispanic origin, NHANES 2015-2016 *;* Module 3, Examples Demonstrating the Importance of Using Weights in Your Analyses *;* Section "Adjusting for oversampling" *;**********************************************************************************************;proc format;* format to combine and reorder the levels of race and Hispanic origin variable ridreth3 *;value r3ordf1,2="3 Hispanic"3,7="4 Non-Hispanic white and other"4="1 Non-Hispanic black"6="2 Non-Hispanic Asian";run;
