




本教程内容整体架构参照《小白学SAS》数据清洗部分,结合NHANES数据库实际情况对架构进行部分调整。可以认为本教程是一篇经验贴。
所提到的经验都是以SAS为基础,朋友们如果有用其他软件的,推而广之即可。基本原理还是一样的。
NHANES数据其实是tidy data(与raw data不同),变量也有相应的codebook。在核对比较这一部分不需要再花时间。
所以,我们关注的重点就放在数据合并(包括纵向合并和横向合并),删除重复值,缺失值处理,创建子集以及产生新变量。
01 纵向合并
以下内容按照先纵向合并再横向合并的顺序进行介绍。在本文中,纵向合并包括对不同周期同一类型数据的合并。
不同周期很好理解,就比如我们把2001-2002年的数据与2003-2004年的数据合并起来。但越是看起来简单的事情,越需要小心。我们这也不例外。
1.常出现的问题:变量名不同。以饮酒问卷为例,其中有一个问题为任何1年内是否至少喝过12杯酒精饮料。1999-2000年该问题对应的变量名为ALQ100;2001-2002年该问题对应的变量名为ALD100;2003-2004年到2015-2016年该问题对应的变量命名为ALQ101。
2.可能出现的问题:变量长度不同、变量类型不一致。合并1999年之后的数据集一般不会出现变量长度不同、类型不一致的问题,但是将NHANES Ⅲ与1999年之后数据集(官网未说明如何合并这两部分数据,合并时更需小心及多方查证)合并时可能出现该问题。
同一类型是指包含类似信息的数据集。如包含人口学变量(数据集名字中带有demo),包含有关饮酒的信息(数据集名字中带有alq)。

↑
NHANES数据库数据文件分类,图中最小分支即为上述一种类型
最后附上SAS代码示例,供大家参考。
/*以合并2001-2002、2003-2004年人口学变量数据集为例,保留seqn、性别、年龄、种族*/data demo0102; set DATA0102.demo_b; keep SEQN RIAGENDR RIDAGEYR RIDRETH1; run;data demo0304; set DATA0304.demo_c; keep SEQN RIAGENDR RIDAGEYR RIDRETH1; run;data demo; set demo:;run;proc sort nodupkey; by SEQN; run; /*排序,同时排除出现重复seqn的情况*//*以合并2001-2002、2003-2004年饮酒相关数据集为例,保留1年内是否至少喝过12杯酒精饮料对应变量*//*drinking*/data alq0102; set DATA0102.alq_b(rename=(ALD100=ALQ101)); keep SEQN ALQ101; run;data alq0304; set DATA0304.alq_c; keep SEQN ALQ101; run;data alq; set alq:;run;proc sort nodupkey; by SEQN; run;
02 横向合并
横向合并在纵向合并完成的基础上进行,需要考虑的问题主要有两点。
1.排序后才能合并;
2.根据之前推送,我们还是以domain语句为例进行说明。使用domain语句就意味着我们不删除不符合纳入标准的人群。在合并时,就不应取交集,而应该取并集。
最后附上SAS代码示例,供大家参考。
/*纵向合并时已排序。横向合并demo以及alq数据集,取并集。*/data analysis;merge demo alq;by seqn;run;
03 删除重复值
正常合并过程一般是不会产生重复值的。seqn是NHANES中每个参与者的唯一标识符,数据集中一般不会出现重复的情况(膳食回顾等中可能出现重复,大家用到的时候仔细查看就好)。加上这步骤很大程度是为了保险,我仍建议大家加上这一步。
实际操作时,多把删除重复值的操作放在纵向合并之后。这与seqn是唯一标识符的说法是对应的。详情可参见纵向合并SAS代码。
04 缺失值
NHANES中一般只把missing设置为点(也就是.)。还需要考虑到的两种常见情况是拒绝(编码为7或者77或者777等)和不知道(编码为9或者99或者999等)。
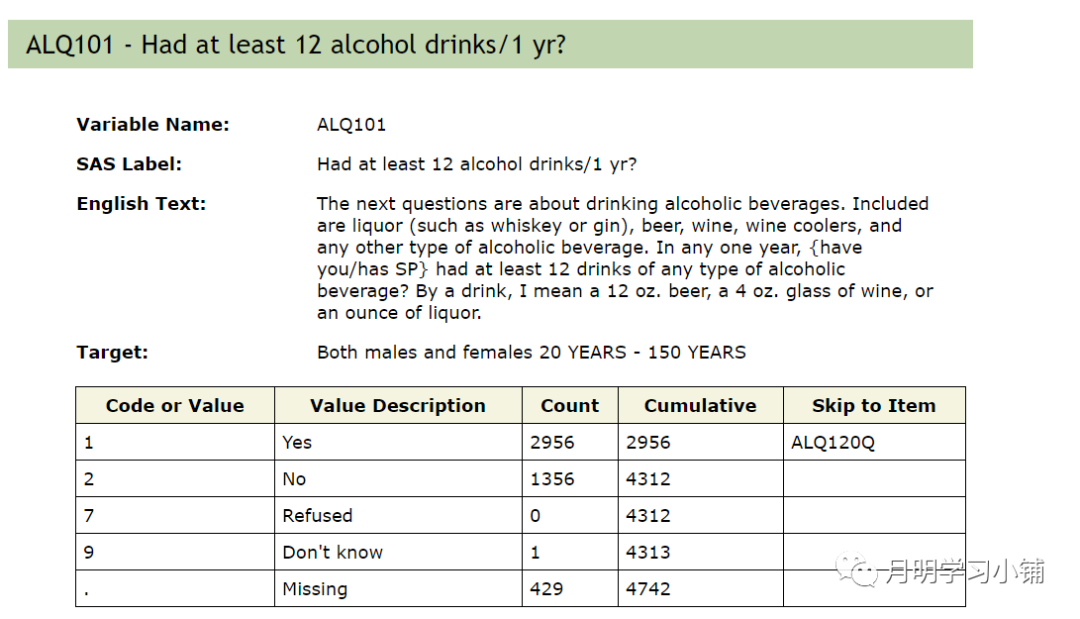
↑
2003-2004年ALQ101赋值情况(分类变量)
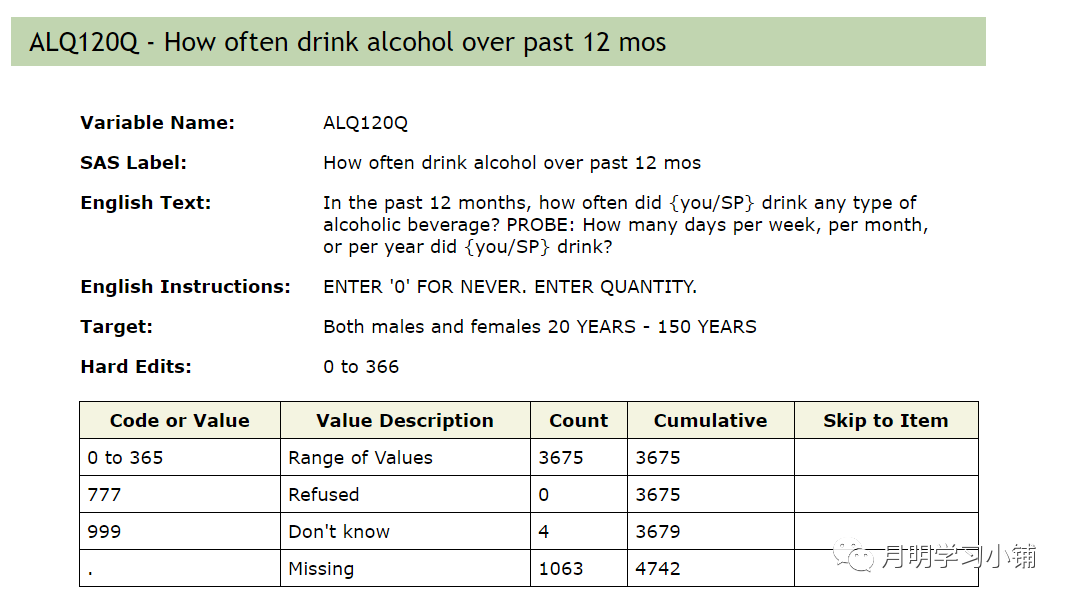
↑
2003-2004年ALQ120Q赋值情况(连续变量)
在进行分类变量赋值时可能看不出来明显影响。但是对于连续变量,可能会导致赋值的极大偏差。以上图中的ALQ120Q为例,如果不把777、999改为缺失的话,统计软件会认为这些人最近1年喝了777或者999次酒。
对于缺失变量,常见的处理办法是填补和删除。在既往用NHANES数据发表的文章中,做法并不完全相同,但多采用多重填补的方法处理缺失数据。(我之后单独做推送详细聊聊)
05 创建子集
创建子集包括创建特定记录子集和创建变量子集两种。但特定记录子集在我们用domain语句的前提下不存在。所以我们只讨论创建变量子集的情况。
原始NHANES数据集内容很多,体积也很大。其实我们并不会用到这么多,用keep语句保留我们需要的变量即可。详情可参见纵向合并SAS代码。
06 产生新变量
按照纳入标准生成新变量,符合纳入标准可编码新变量值为1,不符合可编为0。纳入标准就因人而异了,我在这就以一篇文献的纳入标准作为例子供大家参考。
For this analysis, we included adults 20 years and older participating in the NHANES from 1999 to 2002,with the exception of adults 60 years and older from the NHANES conducted between 1999 and 2000, during which pyrethroid metabolites were not measured in that subpopulation.
07 一点总结
数据清洗是数据分析之前的重要步骤,也是保证数据分析结果可靠的关键步骤。
数据清洗本身就是一件繁琐的事情,更需要耐心。在程序运行的过程后多多核对,才能保证最后生成合理并且可用的数据集。
之前也有朋友提到过其他做法,纵向合并的时候按照不同类型同一周期数据集进行合并。就我个人而言,我不是很推荐这种做法,因为这样很容易忽视不同周期同一类型数据变量名不同的问题。
祝好,周末愉快。之前私信问RCS问题的朋友再私信我一下哈,我发现后台超过48小时就不能回复了。我这边如果是自己知道或者确实不了解的问题,48小时之内都会回复大家;我认识朋友有了解这一问题的,回复时间会稍长,可以之后再提醒我一下哈。
如果有帮助,记得点赞、在看、转发哦~
08 参考内容
https://wwwn.cdc.gov/nchs/nhanes/tutorials/module1.aspx
Bao W, Liu B, Simonsen DW, Lehmler HJ. Association Between Exposure to Pyrethroid Insecticides and Risk of All-Cause and Cause-Specific Mortality in the General US Adult Population. JAMA Intern Med. 2020;180(3):367-374.
小白学SAS
- 值得一读的往期文章 -

后台回复SDSE获取标准误与标准差区别讲解视频

后台回复domain获取推文参考全部资料
