




本来是昨晚推送的,但内容有点问题需要修改,删除后又不能重新群发。只能今天发了,多有抱歉。
用domain语句(使用部分人群时官方推荐用法)和删除不符合要求的人群结果有无区别,这是我学习NHANES数据库时的最大困惑。在这次论证过程也碰到了诸多困难,20次其实只是多次尝试后最后确定下来的论证过程次数,也就是本次推送所包含的内容。当然结论也不是简单的是与否。文章有点长,感兴趣的朋友不妨耐心往下看看。
01 背景知识
我们之前推送的内容包括均数计算,频数计算,T检验,方差分析,卡方分析。
因为不同内容所需要的背景知识不同,我们归类进行介绍。
1.频数计算以及卡方分析用到的SAS过程为surveyfreq,所用语句为table。domain语句在surveyfreq过程中是无效语法,所以不在我们这次讨论范围内。之后我们做一期推送单独论证。
2.均数计算以及T检验中最重要的两个结果是估计值(Estimate)以及标准误(Standard Error)。不管是最后的置信区间(Confidence Interval)还是T检验的P值都是都是在这两个结果的基础上得出的,所以我们这次判断结果有无差异也是通过它们。
3.对上述两个结果(估计值以及标准误)有影响的三个因素包括:权重(Weight)、聚类(Clustering)、分层(Stratification)。聚类和分层两个因素对结果的影响可以通过自由度(Degrees of freedom)来体现,但不全面(下文会详细说明)。

↑
官方教程第三期对于影响方差估计因素的说明(三个因素都会影响到方差估计)
4.均数计算以及T检验自由度的计算方法(只针对复杂抽样设计):自由度=聚类数目-分层数目。以1999-2000年NHANES为例,计算方法为SDMVPSU与SDMVSTRA组合数目-SDMVSTRA数目。
5.方差分析自由度的计算方法:和简单随机抽样方差分析自由度计算方法相同。总自由度=N(观测数)-1;模型自由度=g-1(关注变量分组数-1,最小为1);误差自由度=N-g。模型自由度和误差自由度其实也就是组间自由度和组内自由度。可参考下图加以理解。

02 自由度及权重对均数计算和T检验的结果影响
因为均数计算和T检验的论证过程以及结果相同,而且T检验包含的知识点会更多。所以我们以T检验为例进行说明。
所有论证所用到的数据集与之前相同,仍是名为Analysis_data的数据集。
将影响因素进行两两组合,可以得到4种情况:
1.自由度不变,权重不变(通过删除部分人群的错误示范实现);
2.自由度改变,权重不变(通过直接改变分层值强行实现);
3.自由度不变,权重改变(通过直接改变权重值强行实现);
4.自由度改变,权重改变(通过取1999-2002年中1999-2000年数据实现)
首个代码和图片是按照官方推荐domain语句实现。其后4个代码和图片是和以上4种情况一一对应的。内容较多,建议点开图片详细对比查看。
/*数据集准备,亚组为年龄大于20岁*/data Analysis_data1;set Analysis_data;if wtmec4yr>0 and wtmec2yr>0;run;data Analysis_data2;set Analysis_data1;if ridageyr>20 then inc=1;else inc=0;run;data Analysis_data3;set Analysis_data1;if ridageyr>20;run;/*T检验,domain*/proc surveyreg data=ANALYSIS_DATA2 nomcar;stratum sdmvstra;cluster sdmvpsu;weight wtmec4yr;model bpxsar = riagendr/solution clparm vadjust=none;domain inc;run;
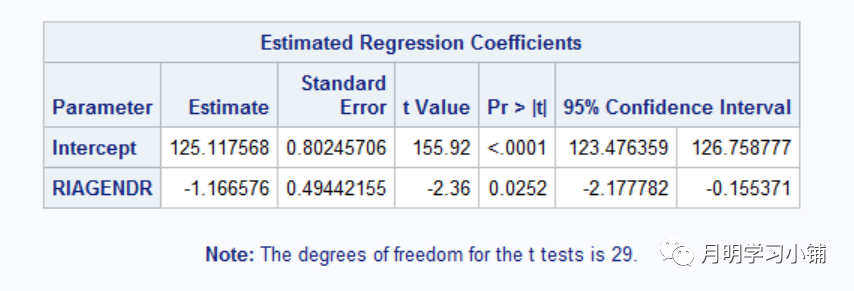
↑
官方推荐domain语句T检验结果
/*T检验,删除*/proc surveyreg data=ANALYSIS_DATA3 nomcar;stratum sdmvstra;cluster sdmvpsu;weight wtmec4yr;model bpxsar = riagendr/solution clparm vadjust=none;run;
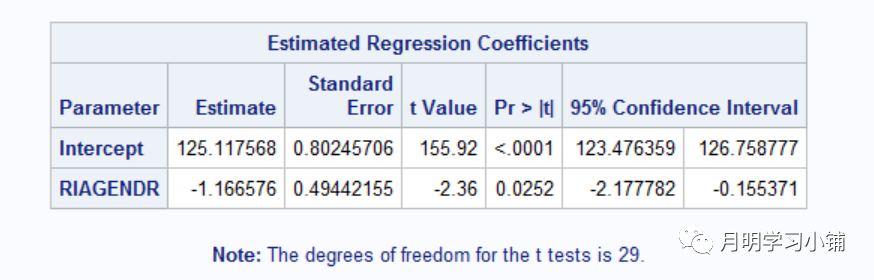
↑
删除部分人群错误示范T检验结果(与图1结果相同)
/*T检验,改变stra和cluster,domain*/data Analysis_data4;set Analysis_data2;if SDMVSTRA=28 then SDMVSTRA=27;run;proc surveyreg data=ANALYSIS_DATA4 nomcar;stratum sdmvstra;cluster sdmvpsu;weight wtmec4yr;model bpxsar = riagendr/solution clparm vadjust=none;domain inc;run;
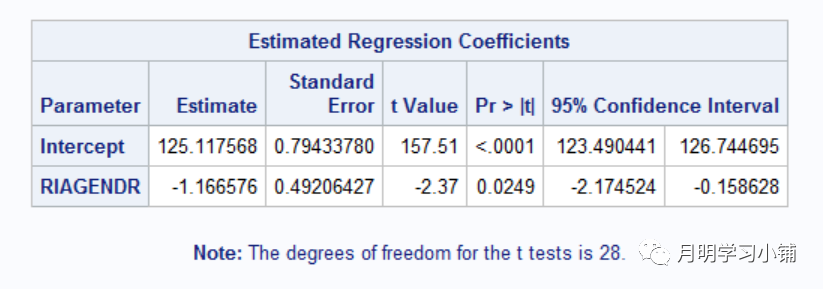
↑
直接改变分层值T检验结果(与图1相比估计值不变,标准误改变)
/*T检验,改变weight,domain*/proc surveyreg data=ANALYSIS_DATA2 nomcar;stratum sdmvstra;cluster sdmvpsu;weight wtmec2yr;model bpxsar = riagendr/solution clparm vadjust=none;domain inc;run;
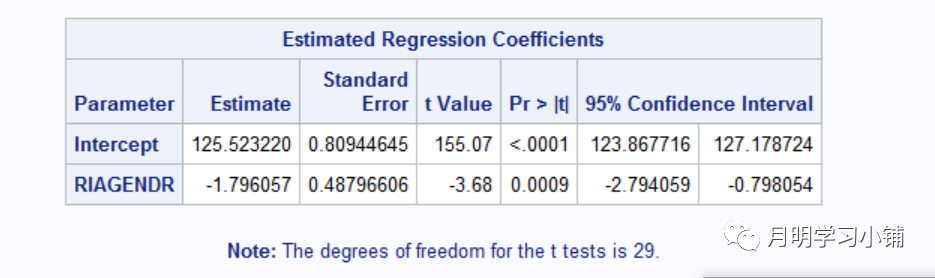
↑
直接改变权重值T检验结果(与图1相比估计值和标准误均改变)
/*使用1999-2000年亚组,四年权重*/proc surveyreg data=ANALYSIS_DATA2 nomcar;stratum sdmvstra;cluster sdmvpsu;weight wtmec4yr;model bpxsar = riagendr/solution clparm vadjust=none;domain SDDSRVYR;run;/*只保留1999-2000年,两年权重*/data Analysis_data5;set Analysis_data2;if SDDSRVYR=1;run;proc surveyreg data=ANALYSIS_DATA5 nomcar; *clm????mean?95%????*/stratum sdmvstra;cluster sdmvpsu;weight wtmec2yr;model bpxsar = riagendr/solution clparm vadjust=none;run;
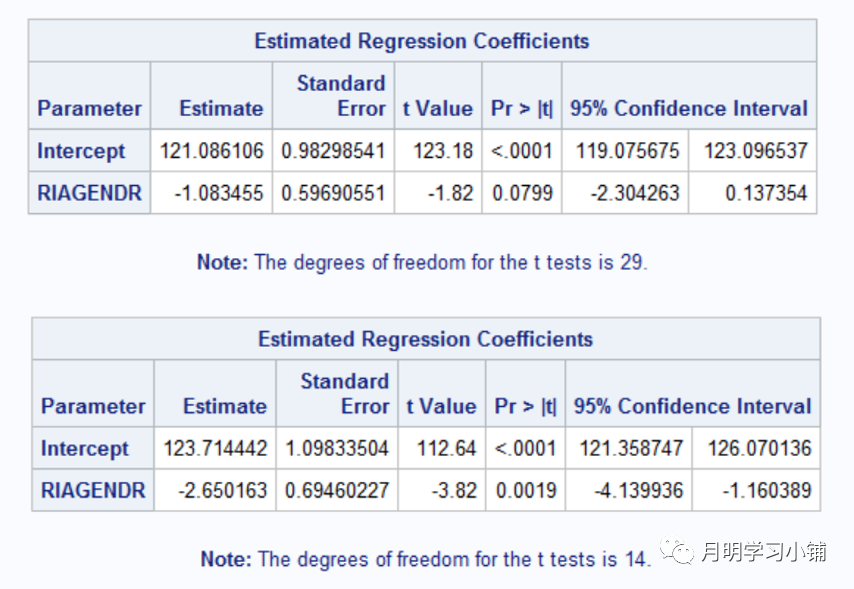
↑
使用1999-2000年数据T检验结果(图中两个结果相比,估计值和标准误均改变)
总之,自由度改变会影响到标准误,而权重改变会同时影响到估计值和标准误。删除部分人群会导致权重改变(权重其实就是抽样概率的倒数,删除的这部分人不会被抽到,剩下人被抽到的概率也会改变),所以对应以上4种情况,有两种符合要求:自由度不变,权重改变;自由度改变,权重改变。
而我们平时所常采用的删除人群的做法(第一种情况的错误示范),其实并没有考虑到权重的改变(我们也根本不知道权重是多少)。相当于是人为造成了自由度不变,权重不变的情况,导致结果和domain结果一致。
但值得一提的是,在我们误以为权重一致的前提下,删除人群引起自由度的改变(在样本量不大时有可能会出现),结果是否一致还需要细分。如果自由度改变影响到了复杂抽样设计本身,像我们采用的纳入标准导致分层和聚类改变时,结果是会改变的;但是自由度改变没有影响到复杂抽样设计本身,像我们从1999-2002年中取出1999-2000年数据那样,结果是不会改变的。
上面我补充的这一部分看不懂没关系。我明天再推送一篇,加上例子进行说明。
03 删除部分人群的方差分析结果讨论
其实,结合我之前补充的自由度知识。大家可以知道,即便是在误以为权重一样的前提下,删除部分人群也会导致自由度的改变,从而导致方差分析的结果不同。
不过按照domain语句算出的方差分析P值往往要比删除部分人群小,更容易出现发现各组之间差异有统计学意义的结论。
仔细想一想,或许在方差分析这根本就没有完美做法。用domain语句的话会导致自由度明显增大,样本量远超实际用到的原始人群;但是直接删除部分人群会导致权重取值无法得到。或许,这也是官方教程中没有方差分析的原因?
看不懂也没关系,例子我也还是在明天推文放出,今天推送内容确实有点多了。
04 一点总结
因为本身SAS的统计过程也是一个黑箱,其中的原理我也只知道一些皮毛。以上内容都是反推回去的,内容不一定正确,也欢迎后台留言讨论。
不管以上内容正确与否,我们仍可以用一个简单的方法保证数据分析基本无误。就是在分析数据的时候除了我们平时用的删除人群的做法(本文展示的第一种做法),把domain语句也跑一遍,比较两者结果。
其实就算是昨天晚上发推送,时间也还是过8点了,也不知道该如何表达自己的歉意。我明天推文给大家补上小红包。
逻辑不能自洽,是我写作这篇推文的最大阻碍。直到今天发出这篇推文,我才找到逻辑自洽的平衡点,才敢发给各位读者朋友,也不致心中愧疚。
祝好,大家周末愉快。早点休息,一定要注意身体哦。
如果有帮助的话要记得点赞、在看、转发哦。大家的支持是我继续写作的最大源动力。
05 参考内容
https://wwwn.cdc.gov/nchs/nhanes/tutorials/module4.aspx
SAS HELP
赵耐青老师的卫生统计学
