




一、概述
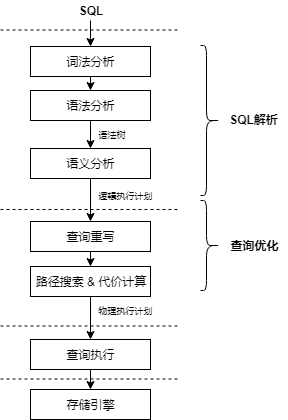
二、SQL解析
(1) 词法分析:从查询语句中识别出系统支持的关键字、标识符、操作符、终结符等,确定每个词自己固有的词性。常用工具如flex。
(2) 语法分析:根据SQL语言的标准定义语法规则,使用词法分析中产生的词去匹配语法规则,如果一个SQL语句能够匹配一个语法规则,则生成对应的抽象语法树(abstract synatax tree,AST)。常用工具如Bison。
(3) 语义分析:对抽象语法树进行有效性检查,检查语法树中对应的表、列、函数、表达式是否有对应的元数据,将抽象语法树转换为查询树。

(一) 词法分析
//定义操作符op_chars [\~\!\@\#\^\&\|\`\?\+\-\*\/\%\<\>\=]operator {op_chars}+//定义数值类型integer {digit}+decimal (({digit}*\.{digit}+)|({digit}+\.{digit}*))decimalfail {digit}+\.\.real ({integer}|{decimal})[Ee][-+]?{digit}+realfail1 ({integer}|{decimal})[Ee]realfail2 ({integer}|{decimal})[Ee][-+]
{operator} {// “/*”“--”不是操作符,他们起注释的作用int nchars = yyleng;char *slashstar = strstr(yytext, "/*");char *dashdash = strstr(yytext, "--");if (slashstar && dashdash){// 如果”/*”和”—”同时存在,选择第一个出现的作为注释if (slashstar > dashdash)slashstar = dashdash;}else if (!slashstar)slashstar = dashdash;if (slashstar)nchars = slashstar - yytext;// 为了SQL兼容,'+'和'-'不能是多字符操作符的最后一个字符,例如'=-',需要将其作为两个操作符while (nchars > 1 &&(yytext[nchars-1] == '+' ||yytext[nchars-1] == '-')){int ic;for (ic = nchars-2; ic >= 0; ic--){if (strchr("~!@#^&|`?%", yytext[ic]))break;}if (ic >= 0)break; // 如果找到匹配的操作符,跳出循环nchars--; // 否则去掉操作符 '+'和'-',重新检查}……return Op;}
Makefile片段scan.cpp: scan.lifdef FLEX$(FLEX) $(FLEXFLAGS) -o'$@' $<# @if [ `wc -l <lex.backup` -eq 1 ]; then rm lex.backup; else echo "Scanner requires backup, see lex.backup."; exit 1; fielse@$(missing) flex $< $@endif
scan.l840 {operator} {841 ……851 if (slashstar && dashdash)scan.cppcase 59:YY_RULE_SETUP#line 840 "scan.l"{……if (slashstar && dashdash)
PG_KEYWORD("abort", ABORT_P, UNRESERVED_KEYWORD)PG_KEYWORD("absolute", ABSOLUTE_P, UNRESERVED_KEYWORD)PG_KEYWORD("access", ACCESS, UNRESERVED_KEYWORD)PG_KEYWORD("account", ACCOUNT, UNRESERVED_KEYWORD)PG_KEYWORD("action", ACTION, UNRESERVED_KEYWORD)PG_KEYWORD("add", ADD_P, UNRESERVED_KEYWORD)PG_KEYWORD("admin", ADMIN, UNRESERVED_KEYWORD)PG_KEYWORD("after", AFTER, UNRESERVED_KEYWORD)……
{identifier} {……// 判断是否为关键词keyword = ScanKeywordLookup(yytext,yyextra->keywords,yyextra->num_keywords);if (keyword != NULL){……return keyword->value;}……yylval->str = ident;yyextra->ident_quoted = false;return IDENT;}
(二) 语法分析
typedef struct SelectStmt {NodeTag type; // 节点类型List* distinctClause; // DISTINCT子句IntoClause* intoClause; // SELECT INTO子句List* targetList; // 目标属性List* fromClause; // FROM子句Node* whereClause; // WHERE子句List* groupClause; // GROUP BY子句Node* havingClause; // HAVING子句List* windowClause; // WINDOW子句WithClause* withClause; // WITH子句List* valuesLists; // FROM子句中未转换的表达式,用来保存常量表List* sortClause; // ORDER BY子句Node* limitOffset; // OFFSET子句Node* limitCount; // LIMIT子句List* lockingClause; // FOR UPDATE子句HintState* hintState;SetOperation op; // 查询语句的集合操作bool all; // 集合操作是否指定ALL关键字struct SelectStmt* larg; // 左子节点struct SelectStmt* rarg; // 右子节点……} SelectStmt;
simple_select:SELECT hint_string opt_distinct target_listinto_clause from_clause where_clausegroup_clause having_clause window_clause{SelectStmt *n = makeNode(SelectStmt);n->distinctClause = $3;n->targetList = $4;n->intoClause = $5;n->fromClause = $6;n->whereClause = $7;n->groupClause = $8;n->havingClause = $9;n->windowClause = $10;n->hintState = create_hintstate($2);n->hasPlus = getOperatorPlusFlag();$$ = (Node *)n;}……
simple_select:……| values_clause { $$ = $1; }| TABLE relation_expr……| select_clause UNION opt_all select_clause{$$ = makeSetOp(SETOP_UNION, $3, $1, $4);}| select_clause INTERSECT opt_all select_clause{$$ = makeSetOp(SETOP_INTERSECT, $3, $1, $4);}| select_clause EXCEPT opt_all select_clause{$$ = makeSetOp(SETOP_EXCEPT, $3, $1, $4);}| select_clause MINUS_P opt_all select_clause{$$ = makeSetOp(SETOP_EXCEPT, $3, $1, $4);};
target_list:target_el { $$ = list_make1($1); }| target_list ',' target_el { $$ = lappend($1, $3); };target_el: a_expr AS ColLabel……| a_expr IDENT……| a_expr……| '*'……| c_expr VALUE_P……| c_expr NAME_P……| c_expr TYPE_P……;
typedef struct ResTarget {NodeTag type;char *name; // AS指定的目标属性的名称,没有则为空List *indirection; // 通过属性名、*号引用的目标属性,没有则为空Node *val; // 指向各种表达式int location; // 符号出现的位置} ResTarget;
from_clause:FROM from_list { $$ = $2; }| /*EMPTY*/{ $$ = NIL; };from_list:table_ref { $$ = list_make1($1); }| from_list ',' table_ref { $$ = lappend($1, $3); };table_ref: relation_expr……| relation_expr alias_clause……| relation_expr opt_alias_clause tablesample_clause……| relation_expr PARTITION '(' name ')'……| relation_expr BUCKETS '(' bucket_list ')'……| relation_expr PARTITION_FOR '(' maxValueList ')'……| relation_expr PARTITION '(' name ')' alias_clause……| relation_expr PARTITION_FOR '(' maxValueList ')'alias_clause……| func_table……| func_table alias_clause……| func_table AS '(' TableFuncElementList ')'……| func_table AS ColId '(' TableFuncElementList ')'……| func_table ColId '(' TableFuncElementList ')'……| select_with_parens……| select_with_parens alias_clause……| joined_table……| '(' joined_table ')' alias_clause……;
relation_expr:qualified_name……| qualified_name '*'……| ONLY qualified_name……| ONLY '(' qualified_name ')'……;qualified_name:ColId……| ColId indirection……
typedef struct RangeVar {NodeTag type;char* catalogname; // 表的数据库名char* schemaname; // 表的模式名char* relname; // 表或者序列名char* partitionname; //记录分区表名InhOption inhOpt; // 是否将表的操作递归到子表上char relpersistence; / 表类型,普通表/unlogged表/临时表/全局临时表Alias* alias; // 表的别名int location; // 符号出现的位置bool ispartition; // 是否为分区表List* partitionKeyValuesList;bool isbucket; // 当前是否为哈希桶类型的表List* buckets; // 对应的哈希桶中的桶int length;#ifdef ENABLE_MOTOid foreignOid;#endif} RangeVar;
where_clause:WHERE a_expr { $$ = $2; }| /*EMPTY*/ { $$ = NULL; };
a_expr: c_expr { $$ = $1; }| a_expr TYPECAST Typename{ $$ = makeTypeCast($1, $3, @2); }| a_expr COLLATE any_name……| a_expr AT TIME ZONE a_expr……| '+' a_expr……;
typedef struct A_Expr {NodeTag type;A_Expr_Kind kind; // 表达式类型List *name; // 操作符名称Node *lexpr; // 左子表达式Node *rexpr; // 右子表达式int location; // 符号出现的位置} A_Expr;
(三) 语义分析
struct ParseState {struct ParseState* parentParseState; // 指向外层查询const char* p_sourcetext; // 原始SQL命令List* p_rtable; // 范围表List* p_joinexprs; // 连接表达式List* p_joinlist; // 连接项List* p_relnamespace; // 表名集合List* p_varnamespace; // 属性名集合bool p_lateral_active;List* p_ctenamespace; // 公共表达式名集合List* p_future_ctes; // 不在p_ctenamespace中的公共表达式CommonTableExpr* p_parent_cte;List* p_windowdefs; // WINDOW子句的原始定义int p_next_resno; // 下一个分配给目标属性的资源号List* p_locking_clause; // 原始的FOR UPDATE/FOR SHARE信息Node* p_value_substitute;bool p_hasAggs; // 是否有聚集函数bool p_hasWindowFuncs; // 是否有窗口函数bool p_hasSubLinks; // 是否有子链接bool p_hasModifyingCTE;bool p_is_insert; // 是否为INSERT语句bool p_locked_from_parent;bool p_resolve_unknowns;bool p_hasSynonyms;Relation p_target_relation; // 目标表RangeTblEntry* p_target_rangetblentry; // 目标表在RangeTable对应的项……};
typedef struct Node {NodeTag type;} Node;
(1) 创建一个新的Query节点,设置commandType为CMD_SELECT。
(2) 检查SelectStmt是否存在WITH子句,存在则调用transformWithClause处理。
(3) 调用transformFromClause函数处理FROM子句。
(4) 调用transformTargetList函数处理目标属性。
(5) 若存在操作符“+”则调用transformOperatorPlus转为外连接。
(6) 调用transformWhereClause函数处理WHERE子句和HAVING子句。
(7) 调用transformSortClause函数处理ORDER BY子句。
(8) 调用transformGroupClause函数处理GROUP BY子句。
(9) 调用transformDistinctClause函数或者transformDistinctOnClause函数处理DISTINCT子句。
(10) 调用transformLimitClause函数处理LIMIT和OFFSET子句。
(11) 调用transformWindowDefinitions函数处理WINDOWS子句。
(12) 调用resolveTargetListUnknowns函数将其他未知类型作为text处理。
(13) 调用transformLockingClause函数处理FOR UPDATE子句。
(14) 处理其他情况,如insert语句、foreign table等。
(15) 返回查询树。
typedef struct TargetEntry {Expr xpr;Expr* expr; // 需要计算的表达式AttrNumber resno; // 属性编号char* resname; // 属性名Index ressortgroupref; // 被ORDER BY和GROUP BY子句引用时为正值Oid resorigtbl; // 属性所属源表的OIDAttrNumber resorigcol; // 属性在源表中的编号bool resjunk; // 如果为true,则在输出结果时去除} TargetEntry;
Node* transformFromClauseItem(……){if (IsA(n, RangeVar)) {……} else if (IsA(n, RangeSubselect)) {……} else if (IsA(n, RangeFunction)) {……} else if (IsA(n, RangeTableSample)) {……} else if (IsA(n, JoinExpr)) {……} else……return NULL;}
typedef struct RangeTblEntry {NodeTag type;RTEKind rtekind; // RTE的类型……Oid relid; // 表的OIDOid partitionOid; // 如果是分区表,记录分区表的OIDbool isContainPartition; // 是否含有分区表Oid refSynOid;List* partid_list;char relkind; // 表的类型bool isResultRel;TableSampleClause* tablesample; // 对表基于采样进行查询的子句bool ispartrel; // 是否为分区表bool ignoreResetRelid;Query* subquery; // 子查询语句bool security_barrier; // 是否为security_barrier视图的子查询JoinType jointype; // 连接类型List* joinaliasvars; // 连接结果中属性的别名Node* funcexpr; // 函数调用的表达式树List* funccoltypes; // 函数返回记录中属性类型的OID列表List* funccoltypmods; // 函数返回记录中属性类型的typmods列表List* funccolcollations; // 函数返回记录中属性类型的collation OID列表List* values_lists; // VALUES表达式列表List* values_collations; // VALUES属性类型的collation OID列表……} RangeTblEntry;
typedef struct FromExpr {NodeTag type;List* fromlist; // 子连接链表Node* quals; // 表达式树} FromExpr;
typedef struct Query {NodeTag type;CmdType commandType; // 命令类型QuerySource querySource; // 查询来源uint64 queryId; // 查询树的标识符bool canSetTag; // 如果是原始查询,则为false;如果是查询重写或者查询规划新增,则为trueNode* utilityStmt; // 定义游标或者不可优化的查询语句int resultRelation; // 结果关系bool hasAggs; // 目标属性或HAVING子句中是否有聚集函数bool hasWindowFuncs; // 目标属性中是否有窗口函数bool hasSubLinks; // 是否有子查询bool hasDistinctOn; // 是否有DISTINCT子句bool hasRecursive; // 公共表达式是否允许递归bool hasModifyingCTE; // WITH子句是否包含INSERT/UPDATE/DELETEbool hasForUpdate; // 是否有FOR UPDATE或FOR SHARE子句bool hasRowSecurity; // 重写是否应用行级访问控制bool hasSynonyms; // 范围表是否有同义词List* cteList; // WITH子句,用于公共表达式List* rtable; // 范围表FromExpr* jointree; // 连接树,描述FROM和WHERE子句出现的连接List* targetList; // 目标属性List* starStart; // 对应于ParseState结构体的p_star_startList* starEnd; // 对应于ParseState结构体的p_star_endList* starOnly; // 对应于ParseState结构体的p_star_onlyList* returningList; // RETURNING子句List* groupClause; // GROUP子句List* groupingSets; // 分组集Node* havingQual; // HAVING子句List* windowClause; // WINDOW子句List* distinctClause; // DISTINCT子句List* sortClause; // ORDER子句Node* limitOffset; // OFFSET子句Node* limitCount; // LIMIT子句List* rowMarks; // 行标记链表Node* setOperations; // 集合操作List *constraintDeps;HintState* hintState;……} Query;
(四) 解析流程分析
CREATE TABLE warehouse(w_id SMALLINT PRIMARY KEY,w_name VARCHAR(10) NOT NULL,w_street_1 VARCHAR(20) CHECK(LENGTH(w_street_1)<>0),w_street_2 VARCHAR(20) CHECK(LENGTH(w_street_2)<>0),w_city VARCHAR(20),w_state CHAR(2) DEFAULT 'CN',w_zip CHAR(9),w_tax DECIMAL(4,2),w_ytd DECIMAL(12,2));
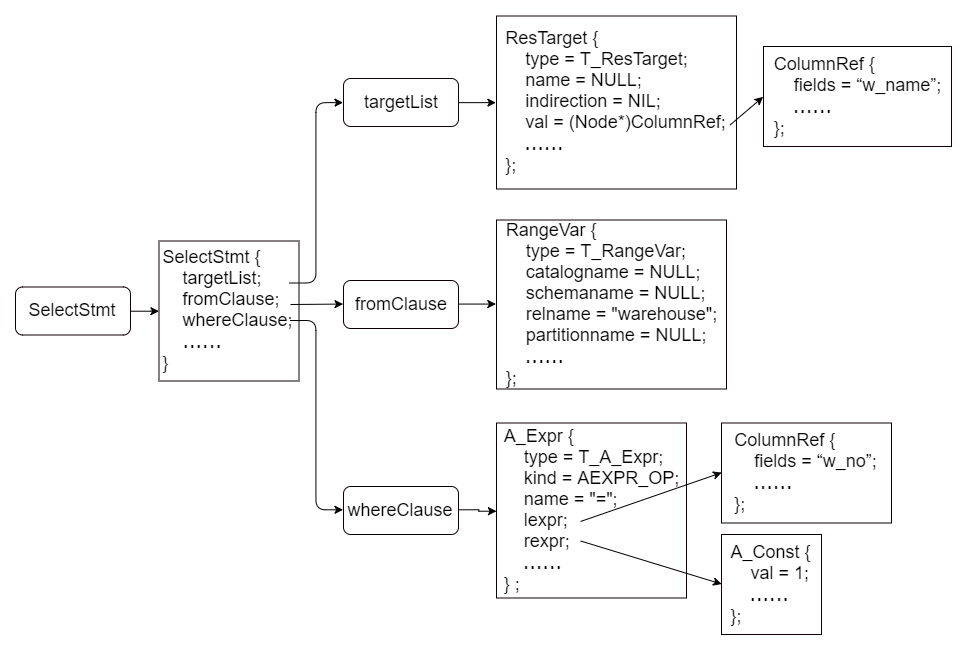
SELECT IDENT FROM IDENT WHERE IDENT “=” ICONST

(1) targetList链表中ResTarget字段val会根据目标属性的类型,指向不同的结构体。对于本节给出的用例,val指向结构体ColumnRef,存储目标属性在源表中的具体信息。
(2) fromClause存储FROM子句的指向对象,同样是包含若干个RangeVar结构体的链表,每个RangeVar存储范围表的具体信息。对于本节给出的用例,只有一个RangeVar结构体,字段relname值为warehouse。
(3) whereClause为Node结构,存储WHERE子句包含的范围表达式,根据表达式的不同,使用不同的结构体存储,如列引用ColumnRef、参数引用ParamRef、前缀/中缀/后缀表达式A_Expr、常量A_Const。对于本节给出的用例,使用A_Expr来存储表达式对象,并分别使用ColumnRef和A_Const存储左、右两个子表达式的具体信息。

文章转载自 openGauss,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
