






布隆过滤器

问:请描述HBase的布隆过滤器
答:
布隆过滤器可以用于快速判断一个数据是否存在一个集合中。它的原理是,创建一个长度为n的二进制数组,初始状态下值均为0;然后将当前集合中的数据进行哈希计算后,将数组中的对应位置变为1。
比如,字符串"hbase"经过哈希计算后,值为3,那么将原数组[0,0,0,0,0]更改为[0,0,0,1,0]。那么,要查询的数据也会先经过哈希计算,在数组中快速寻找,如果已经置为1,说明数据可能在这个集合中,如果为0,说明一定不在集合中。
所以布隆过滤器是一种粗略的过滤手段。但因为它算法简单,使用的存储开销小,在大数据场景中是一种很不错的优化方式。
而且为了增加数据查询的准确性,一般会使用多个不同的哈希函数进行计算。比如,h1、h2、h3,这样会得到3个不同的位置,同时将其置为1。如果在查询数据时,同时发现这3个位置均为1,则说明很大的概率可以在当前集合中找到期望的数据,否则一定不在当前集合中。
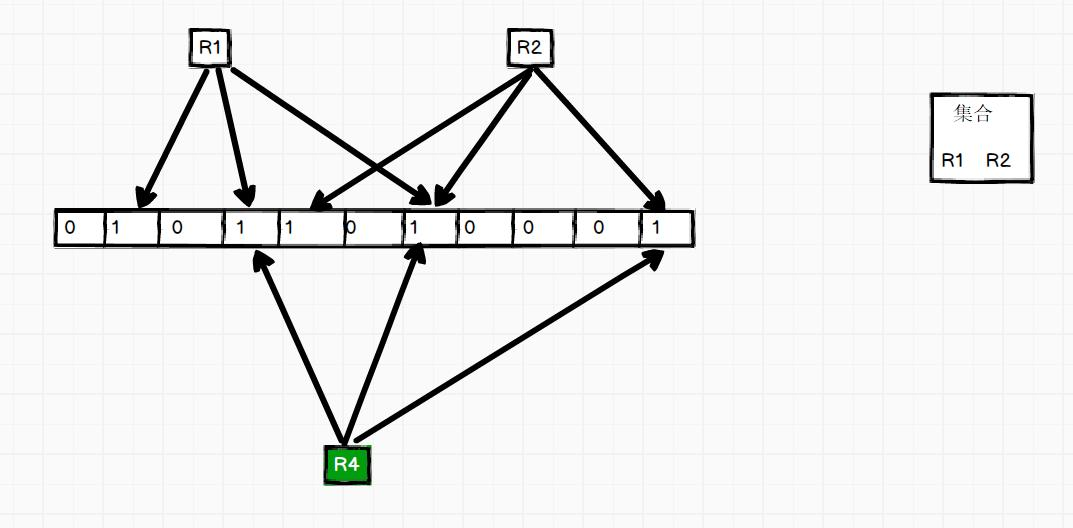
从HBase 0.96以来,默认启用基于行的Bloom Filters。在查询某行数据时,使用布隆过滤器可以快速排除一些HFile,以减少数据的读取量。
当然HBase除了默认的行级别(row)的布隆过滤器,也支持行+列级别(row+column)的。
如果经常扫描整行数据,可以使用row方式的布隆过滤器,此时也可以加快行+列的查询速度。
如果经常查询某行某列的数据,可以使用row+column方式的布隆过滤器,但它不会加快对整行数据的查询效率。而且除非这一行只有一列,否则row+column的布隆过滤器会占用较多的存储空间。所以,当每个数据至少为几千字节时,它的效果最好。
可以使用命令,在列族上开启布隆过滤器。
create 'mytable',{NAME => 'colfam1', BLOOMFILTER => 'ROWCOL'}
布隆过滤器存储在HFile的元数据中,当Region被部署到某个RegionServer中时,HFile会被读取,将布隆过滤器加载到内存中。
布隆过滤器开启后,在生产环境中是否有效,此时可以查看RegionServer中的blockCacheHitRatio值,如果开启后值增加,说明是正优化。
今天的单点,你是否get到了呢?每日单点,用5分钟收获一点!今天你打卡了没?



【单点】每日突破,MapReduce调优篇

【单点】每日突破,HDFS缓存篇

【单点】每日突破,HDFS读写篇

【收藏】一键获取数舟所有文章
理解大数据,可以换一个角度
扫描二维码
获取更多精彩
数 舟

