




CN、DN合设服务器亚健康
当FusionInsight Manager监控到服务器指标不合格(例如CPU使用率过高、内存空间不足),产生“重要”级别的告警,主机状态会处于“故障”状态,服务器就处于亚健康状态。对系统的影响表现为,作业执行缓慢或者作业执行超时。因此需要对亚健康的服务器进行隔离、修复后、再加入集群中。
- 停止应用层的作业下发。
- 停止数据库中的残留SQL。预计影响业务时长:2分钟。
在各CN服务器上连接数据库,执行如下命令停止残留SQL。
SELECT PG_TERMINATE_BACKEND(PID) FROM PG_STAT_ACTIVITY WHERE STATE='active' AND QUERY NOT LIKE '%TERMINATE%' AND APPLICATION_NAME NOT IN('JobScheduler','workload','WorkloadMonitor','cm_agent');
返回t表示有残留,SQL被停止。
pg_terminate_backend ---------------------- t (1 row)- 删除CN。预计影响业务时长:10分钟。
请参见删除Coordinator实例。
- 隔离故障服务器。预计影响业务时长:5分钟。
- 以omm用户身份登录CN所在服务器,执行source ${BIGDATA_HOME}/mppdb/.mppdbgs_profile命令启动环境变量。
- 获取故障服务器名称。
在FusionInsight Manager界面,选择“集群 > 待操作的集群名称 > 主机”查看状态为“故障”的“主机名称”。
- 停止故障服务器。
gs_om -t stop [-h HOSTNAME]
- 执行gs_om -t status --detail重新查看集群状态,查看停止故障服务器是否成功。
本例中假设故障的主机名称为“node2”。
集群状态为“Degraded”、是否平衡为“No”。“node2”的实例为“Down”、状态为“Unknown”。则表示停止“node2”服务器成功。[ Cluster State ] cluster_state : Degraded redistributing : No balanced : No[ Datanode State ] node node_ip instance state | node node_ip instance state | node node_ip instance state ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- 1 node1 10.0.0.1 6001 /gaussdb/data/data_dn1 P Primary Normal | 2 node2 10.0.0.2 6002 /gaussdb/data/data_dnS1 S Down Unknown | 3 node3 10.0.0.3 3002 /gaussdb/data/data_dnDS1 R Secondary Normal 2 node2 10.0.0.2 6003 /gaussdb/data/data_dn2 P Down Unknown | 3 node3 10.0.0.3 6004 /gaussdb/data/data_dnS2 S Primary Normal | 1 node1 10.0.0.1 3003 /gaussdb/data/data_dnDS2 R Secondary Normal 3 node3 10.0.0.3 6005 /gaussdb/data/data_dn3 P Primary Normal | 1 node1 10.0.0.1 6006 /gaussdb/data/data_dnS3 S Standby Normal | 2 node2 10.0.0.2 3004 /gaussdb/data/data_dnDS3 R Down Unknown此时GaussDB 200会自动将对应的备DN升主(DN主节点的“state”为“Primary”),使集群正常运行。备升主期间正在运行的作业会失败;备升主后启动的作业不会再受影响。
- 如果5分钟内故障服务器未自动恢复,GaussDB 200会自动将故障CN剔除,以不影响DDL执行。
- 如果集群部署和使用了负载均衡LVS,LVS会自动将连接切换到其他CN。用户只需重新执行失败作业并观察作业执行情况。预计影响业务时长:2分钟。
- 如果没有部署和使用LVS,需要手动调整应用层的作业调度,将原来连接这个CN执行的作业切换到其他CN上执行。预计影响业务时长:18分钟。
- 停止应用层的作业下发。
- 停止数据库中的残留SQL。
在各CN服务器上连接数据库,执行如下命令停止残留SQL。
SELECT PG_TERMINATE_BACKEND(PID) FROM PG_STAT_ACTIVITY WHERE STATE='active' AND QUERY NOT LIKE '%TERMINATE%' AND APPLICATION_NAME NOT IN('JobScheduler','workload','WorkloadMonitor','cm_agent');
返回t表示有残留,SQL被停止。
pg_terminate_backend ---------------------- t (1 row)- 将应用连接切换到其他CN。具体方法请根据应用层的实现执行,此处不做说明。
- 重新启动应用层的作业下发。
- 修复故障服务器。
请根据主机状态或告警中的提示修改问题。故障定位方法提供了部分故障处理和定位办法,可参考进行故障定位和恢复。同时建议您联系专业的操作系统和网络维护人员进行支撑。
- 加回故障服务器。
- 故障服务器修复后,请按如下办法进行实例加回。预计影响业务时长:8分钟。
- 以omm用户身份登录集群未故障的节点,执行source ${BIGDATA_HOME}/mppdb/.mppdbgs_profile命令启动环境变量。
- 执行gs_om -t status --detail重新查看集群状态。此时故障服务器上整个集群的balanced状态为“No”;原始为主的DN,其状态应该为“Standby Normal”。
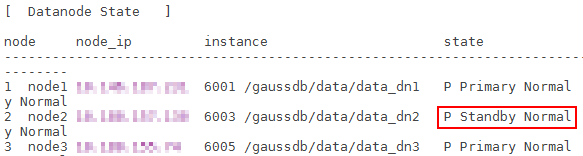
服务器修复到修复完成期间,对应DN实例的状态演进正常为:Down->Starting->Standby Normal。状态变换耗时视机器脱离集群时间而不同,脱离时间越长,状态切换时间越长。在此过程中作业运行不受影响。
如果服务器修复后DN长时间(例如,3分钟)未切换成“Standby Normal”,请尝试使用gs_om -t start -h HOSTNAME启动故障节点上的GaussDB 200进程,然后重新查询集群状态。如果状态依然未变成“Standby Normal”,可以通过故障定位方法中的办法确认服务器是否还存在其他问题,并推荐联系技术支持协助处理。
- 停止应用层的作业下发,准备重置DN实例状态和恢复CN。
- 停止数据库中的残留SQL。预计影响业务时长:2分钟。
在各CN服务器上连接数据库,执行如下命令停止残留SQL。
SELECT PG_TERMINATE_BACKEND(PID) FROM PG_STAT_ACTIVITY WHERE STATE='active' AND QUERY NOT LIKE '%TERMINATE%' AND APPLICATION_NAME NOT IN('JobScheduler','workload','WorkloadMonitor','cm_agent');
返回t表示有残留,SQL被停止。
pg_terminate_backend ---------------------- t (1 row)- 执行命令gs_om -t switch --reset重置实例状态。
说明:
switch为维护操作:确保集群状态正常,所有业务结束,并使用pgxc_get_senders_catchup_time()视图查询无主备追赶后,再进行switch操作。
执行gs_om -t status --detail重新查看集群状态。集群balanced状态应该已恢复为“Yes”。如果未恢复,请尝试再次重置,并查看状态。依然无法恢复balanced状态时,可以尝试通过查看日志进行问题定位,并联系技术工程师协助处理。
- 执行gs_replace命令尝试修复故障服务器上的CN实例。其中node2为故障服务器的hostname,请根据实际替换。关于故障实例修复的更多信息请参考修复MPPDBServer实例。
执行如下命令进行实例配置。
gs_replace -t config -h node2
您会看到异常CN先被删除然后被重新配置。这个过程中CN状态会由“Deleted”变为“Down”。
Fixing ETCD instances. Node is not installed etcd. Fixing all the CMAgents instances. There are [0] CMAgents need to be repaired in cluster. Configuring replacement instances. Successfully configured replacement instances. Successfully fixed all the CMAgents instances. Configuring Waiting for promote peer instances. . Successfully upgraded standby instances. Deleting failed CN from pgxc_node. Successfully deleted failed CN from pgxc_node. Dumping CN files from the Normal CN. Successfully dumped CN files from the Normal CN. Configuring replacement instances. Successfully configured replacement instances. Setting the SCTP. Successfully set the SCTP. Configuration succeeded.执行如下命令重启实例。这个过程中CN状态会由“Down”变为“Normal”。
gs_replace -t start -h node2Starting. ====================================================================== Successfully started instance process. Waiting to become Normal. ====================================================================== . ====================================================================== Start succeeded on all nodes. Start succeeded.如果尝试修复CN失败,可以尝试重新增加CN。
- 重新启动应用层的作业下发。
- 故障服务器无法修复时,请更换服务器后,按如下步骤操作。预计影响业务时长:数据量相关,一般为1到4小时。
- 停止应用层的作业下发,准备替换故障主机。
- 停止数据库中的残留SQL。
- 替换故障主机。
- 重新启动应用层的作业下发。
查看更多:华为GaussDB 200 服务器处于亚健康状态「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」关注作者【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。评论
- 执行命令gs_om -t switch --reset重置实例状态。
- 如果5分钟内故障服务器未自动恢复,GaussDB 200会自动将故障CN剔除,以不影响DDL执行。
- 删除CN。预计影响业务时长:10分钟。
