




前几天解决了一个数仓环境下Hive SQL不能并发执行的问题,周末抽时间把解决问题的过程梳理并记录一下。
由于数仓是基于Hive,底层计算是MapReduce,调度是YARN。
Apache Hadoop YARN:一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,解决集群资源利用率、资源统一管理和数据共享等方面的问题。也就是说 YARN 在 Hadoop 集群中充当资源管理和任务调度的框架。
遇到问题先分析问题:Hive层是没有限制不同Job的并发的设置的,然后是Mapreduce,它只是负责计算,不管Job的并发,最后定位到Yarn:调度问题。通过Yarn UI界面可以看到即便还有不少剩余资源,只有一个Job在执行,剩余Job在等待。
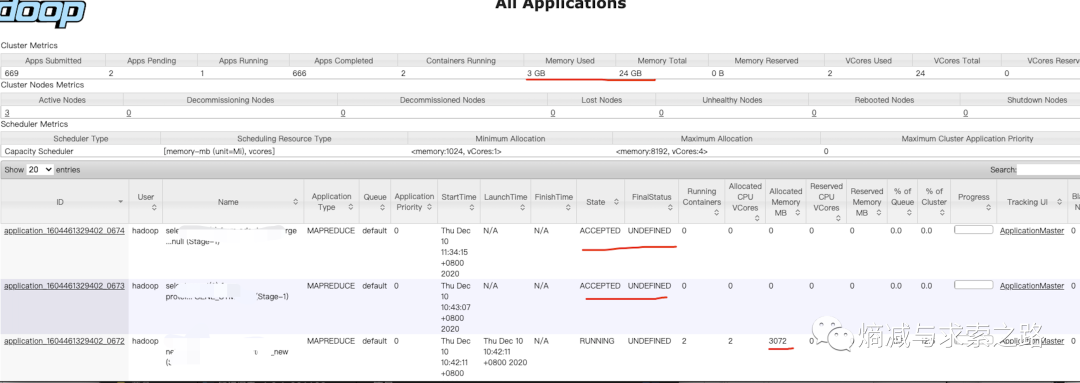
于是花了点时间研究了一下Yarn调度,线上环境默认的调度是Capacity Scheduler(常用的调度还有Fair Scheduler):是Hadoop的一种可插拔调度器,允许多租户安全地共享一个大型集群,以便在已分配容量的约束下及时分配应用程序的资源,详情介绍见官网:https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html。其中关于调度很重要的参数在配置文件中:capacity-scheduler.xml。
调度器的核心就是队列的分配和使用。
1.Capacity调度器默认有一个预定义的队列——root,所有的队列都是它的子队列(默认子队列default)。队列的分配支持层次化的配置,使用.来进行分割,比如yarn.scheduler.capacity.<queue-path>.queues。(下图 dev和default是root的子队列,以及每个队列的容量设置)
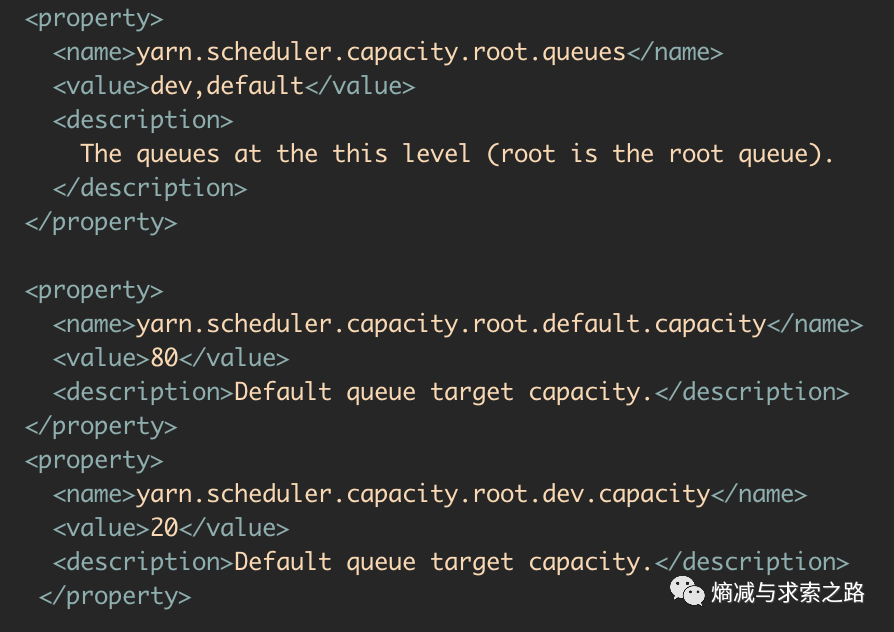
分层次的子队列(比如dev和default)如何使用?后面会讲一下。
2.队列属性参数:
| yarn.scheduler.capacity.<queue-path>.capacity | 队列容量,单位是百分比(%)。在一个层级上所有队列容量的和必须是100. 在资源空闲的情况下,队列中的应用程序可以消费比队列容量更多的资源,提供资源弹性。 |
| yarn.scheduler.capacity.<queue-path>.maximum-capacity | 队列的最大容量,单位是百分比(%),限制队列中应用程序的弹性。默认值-1表示禁用。 |
| yarn.scheduler.capacity.<queue-path>.minimum-user-limit-percent | 每个用户占用的最少资源。比如设置成了25%,那么如果有两个用户提交任务,那么每个任务资源不超过50%。如果3个用户提交任务,那么每个任务资源不超过33%。如果4个用户提交任务,那么每个任务资源不超过25%。如果5个用户提交任务,那么第五个用户需要等待才能提交。默认是100,即不去做限制。 |
yarn.scheduler.capacity.<queue-path>.user-limit-factor | 每个用户最多使用的队列资源占比,如果设置为50.那么每个用户使用的资源最多就是50%。 |
| yarn.scheduler.capacity.<queue-path>.maximum-allocation-mb | 队列为Resource Manager申请的每一个容器分配内存的最大限制。这个配置覆盖集群配置项 yarn.scheduler.maximum-allocation-mb。这个值必须小于或等于集群的最大值。 |
| yarn.scheduler.capacity.<queue-path>.maximum-allocation-vcores | 每个队列对Resource Manager申请的每一个容器分配虚拟计算核的最大限制。这个配置覆盖集群配置项yarn.scheduler.maximum-allocation-vcores。这个值必须小于或者等于集群的最大值。 |
3.运行中和挂起的应用程序的限制(Running and Pending Application Limits):
CapacityScheduler支持如下参数用来控制运行中和挂起的应用程序
| yarn.scheduler.capacity.maximum-applications/yarn.scheduler.capacity.<queue-path>.maximum-applications | 系统中最大并行应用程序数量,包括运行中和挂起状态的。每个队列的限制直接与队列容量和用户的限制相称。这是一个硬性的限制,在达到限制时任何应用程序提交都会被拒绝。默认值是10000。可以用yarn.scheduler.capacity.maximum-applications设置所有队列,也可以通过设置yarn.scheduler.capacity.<queue-path>.maximum-applications覆盖每一个队列。指定为整数。 |
| yarn.scheduler.capacity.maximum-am-resource-percent yarn.scheduler.capacity.<queue-path>.maximum-am-resource-percent | 集群中可以用于运行Application Master的最大资源占比————控制最大并发活跃应用程序数量。限制每一个队列与它的容量和用户限制相称。例如0.5表示50%。默认值是10%,可以通过 yarn.scheduler.capacity.maximum-am-resource-percent为所有队列设置,也可以通过设置yarn.scheduler.capacity.<queue-path>.maximum-am-resource-percent覆盖每个队列的。 |
到此问题就清晰了,由于yarn.scheduler.capacity.maximum-am-resource-percent默认的设置导致任务Pending了。所以根据业务情况酌情调大这个参数问题就解决了。
此外,调度的参数yarn.scheduler.capacity.resource-calculator为资源计算方法,默认是DefaultResourseCalculator,它只会计算内存。DominantResourceCalculator则会计算内存和CPU。
Yarn集群的几个重要参数:
缺省值见文件:https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
| yarn.nodemanager.resource.cpu-vcores | 表示该节点服务器上yarn可以使用的虚拟CPU个数,默认是8,推荐将值配置与物理核心个数相同,如果节点CPU核心不足8个,要调小这个值,yarn不会智能的去检测物理核心数 |
| yarn.scheduler.minimum-allocation-vcores | 单个容器最小可申请的虚拟核心数,默认为1 |
| yarn.scheduler.maximum-allocation-vcores | 单个容器最大可申请的虚拟核心水,默认为4,如果申请资源时,超过这个配置,会抛出InvalidResourceRequestException |
| yarn.nodemanager.resource.memory-mb | 设置该节点上yarn可使用的内存,默认为8G,如果节点内存资源不足8G,要减少这个值,yarn不会智能的去检测内存资源,一般这个设置yarn的可用内存资源,一般要预留总内存的15-20%的内存。 |
| yarn.scheduler.minimum-allocation-mb | 单个容器最小申请物理内存量,默认1024MB,根据自己的业务设定 |
| yarn.scheduler.maximum-allocation-mb | 单个容器最大申请物理内存量,默认为8291MB |
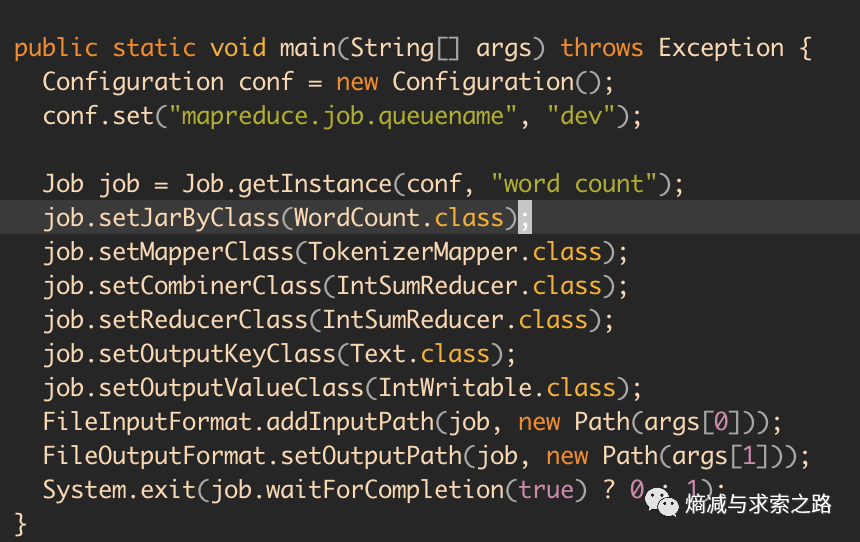
上面讲的分层次的子队列(比如dev和default)如何使用呢?前面谈到Capacity Scheduler允许多租户安全地共享一个大型集群,所以这里不同的子队列就是这个目的。mapred-default.xml的mapreduce.job.queuename默认值是default。如果yarn.scheduler.capacity.root.queues配置了不同的子队列dev和default,想要提交Job到dev如何做呢?提交MapReduce的Job时候带上这个mapreduce.job.queuename参数值就可以。
示例如下(https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html):
(全文完)
推荐近期文章:
Nebula Graph:Exchange工具Hive数据导入的踩坑之旅
我写的可能是错的,这是我当前的认知,或者隔一段时间后回头来看我都会否定它。
《熵减与求索之路》是我自己与自己对话的探索之路,如果顺便对你有启发,请给我反馈(正向和负向都可以),我可能正处于“愚昧之巅”而不自知。
交个朋友 扫码关注我:

