




生产者何时建立与 Broker 的连接?如果有多台 Broker ,会建立多少连接?
在创建 KafkaProducer 实例时,生产者应用会在后台创建并启动一个名为 Sender 的线程,该 Sender 线程开始运行时首先会创建与 Broker 的连接。
如果配置了多个 Broker 实例,会创建多少个连接呢?
bootstrap.servers 中配置多少台机器,就会创建多少个连接。如果你配置了 100 台,那么就意味着会有 100 个初始化连接。通常 Producer 一旦连接到集群中的任一台 Broker,就能拿到整个集群的 Broker 信息,故没必要为 bootstrap.servers 指定所有的 Broker。
另外 Kafka 还支持强制将空闲的 TCP 连接资源关闭,Producer 端参数 connections.max.idle.ms 默认值为 9,即在 9 分钟内如果没有请求在这个连接上处理,那么 Kafka 就会帮你把这个连接关闭。用户可以在 Producer 端设置 connections.max.idle.ms=-1 禁掉这种机制。一旦被设置成 -1,TCP 连接将成为永久长连接。当然这只是软件层面的 “长连接” 机制,由于 Kafka 创建的这些 Socket 连接都开启了 keepalive,因此 keepalive 探活机制还是会遵守的。
除了 Producer 初始启动的时候创建连接,还有两个场景也会创建。
一个是发送消息的时候。
当 Producer 尝试给一个不存在的 Topic 发送消息时,Broker 会告诉 Producer 这个 Topic 不存在。此时 Producer 会发送 metadata 给 Broker 尝试获取最新的元数据信息。
Producer 通过 metadata.max.age.ms 参数定期地去更新元数据信息。
该参数的默认值是 300000,即 5 分钟,也就是说不管集群那边是否有变化,Producer 每 5 分钟都会强制刷新一次元数据以保证它是最及时的数据。
生产者端的消息是一条一条发送出去的吗?
你可能会说这个问题不是白问嘛,肯定是一条一条发出去的,难道还能一批一批的发出去呢。
其实不然,的确是一批一批的发出去的。
生产者客户端最外层是由两个线程协调运行的:
一个是主线程 Producer 线程; 一个是 Send 线程。
主线程负责生产消息,消息并不是直接交给 Send 线程,而是先交给一个叫做 消息累加器(RecordAccumlator) 的组件。
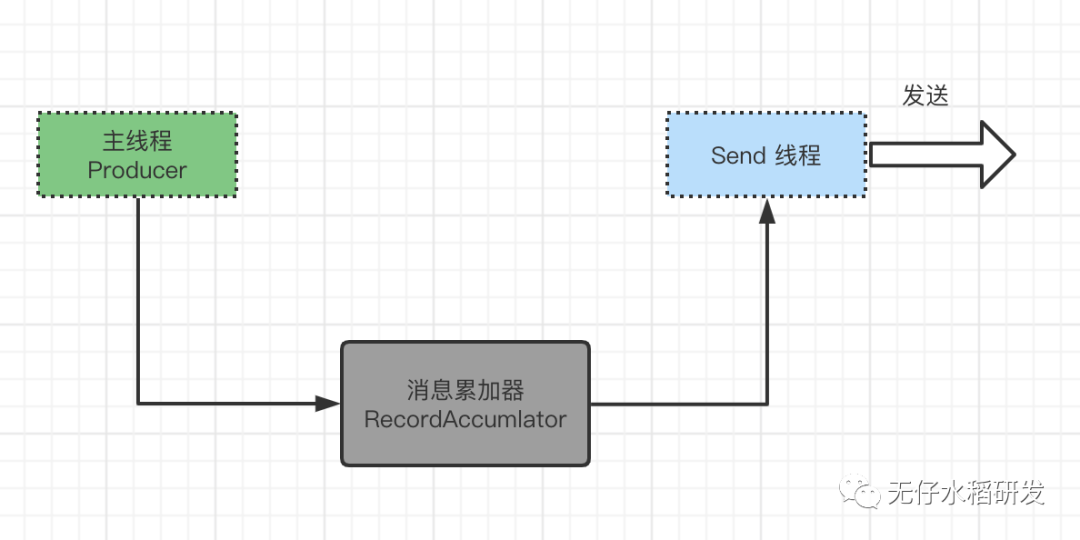
顾名思义,消息累加器的作用就是累加消息。消息累加器按照批次的概念发送消息。默认一个批次的大小为 16k,整个缓存块的大小为 32M。生产者每封装完一个批次发送后按照道理这个 16k 的空间是要回收的,但是如果按照这里来处理不久就会引发 Full GC,所以这里设计了一个内存池的概念,上一个批次使用的空间用完之后,把数据清空,将空间地址放入内存池中,保证内存池的大小是固定的就不会引发 Full GC。
默认一个 batch 是 16k,那么如果有一条消息大小超过了 16k 怎么办呢?
Producer 可以通过配置设置整个 batch 缓冲区的大小以及每一个 batch 的大小:
buffer.memory= //默认32MBbatch.size= //默认16KBlong nonPooledAvailableMemory //当前未分配的内存空间Deque<ByteBuffer> free //可用的byteBuffer空间,每一个ByteBuffer大小就是上面配置 batch.size
整个缓冲区可用的空间 = nonPooledAvailableMemory + free * batch.size。
最开始 free 是空的,所有的内存申请都会从 nonPooledAvailableMemory 中获取。用完之后空间不会被释放也不会被回收到 nonPooledAvailableMemory 中,而是放到 free 中。下一次使用的时候会先去 free 空间中查找是否有可用的 ByteBuffer,如果有就直接从 free 中获取。
如果当前消息大小超过 batch.size 的时候,这种消息会每一条创建一个 ProducerBatch 单独发送。并且创建的空间申请会先去检查 nonPooledAvailableMemory 的空间是否够用,如果不够会先去释放 free 的空间分配给 nonPooledAvailableMemory 以保证当前消息的空间够用。
Kafka Producer 单条消息默认最大值为 1M。
如果你的单条消息已经超过了 batch.size 的大小,那么当前每条消息都是单独发送出去的。这样就会影响 Producer 的吞吐量,所以生产环境要检查当前消息大小和 batch.size 的配置。
客户端整体发送消息的流程大概如下:
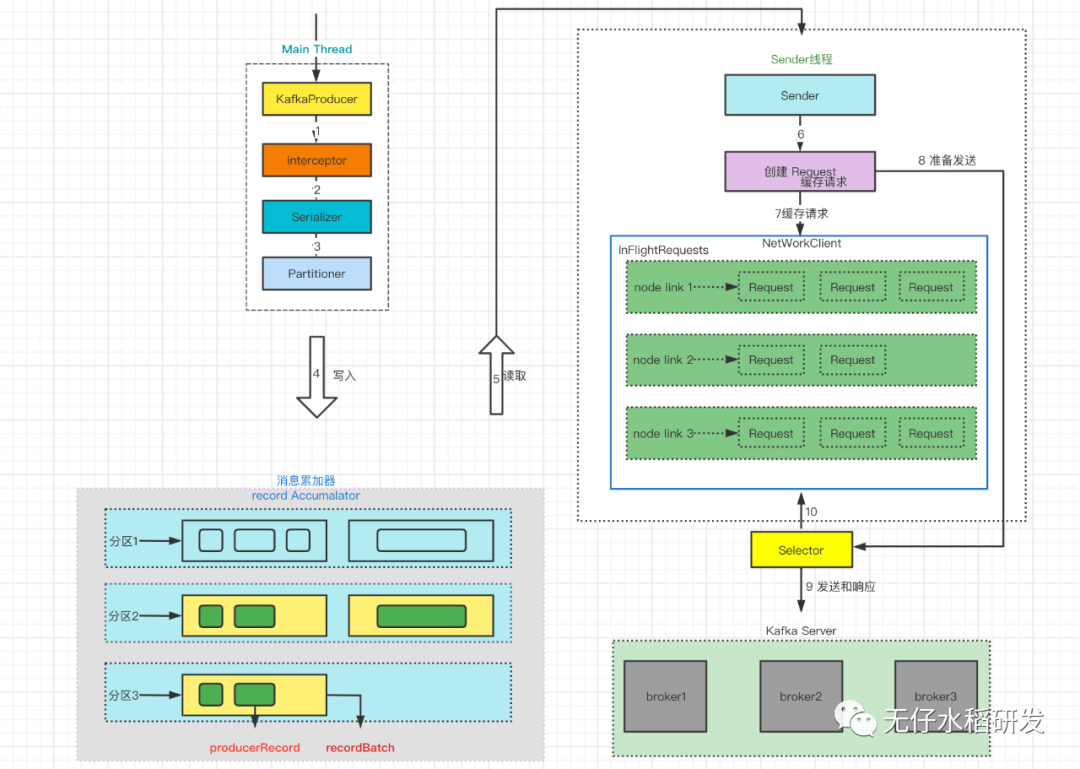
消息累加器中的 recordBatch 如果写满了的话就会开一个异步线程将当前 recordBatch 送给 Sender 线程进行发送处理。Sender 从 RecordAccumulator 中获取缓存的消息之后,会将消息格式 <分区,Deque> 转换为*<Node,List>*,Node 为 Kafka 集群中的 Broker 节点。之后 Sender 还会进一步封装成 <Node,Request> 的形式,这样就可以将 Request 请求发往各个 Node 。
请求在从 Sender 线程发往 Kafka 之前还会保存到 InFlightRequests 中,消息格式为 Map<NodeId,Deque>,主要作用是缓存了已经发出去但还没有收到响应的请求。InFlightRequests 可以通过配置参数来限制每个连接最多缓存的请求数。配置参数为 max.in.flight.requests.per.connection,默认值为 5。类似于 Go 中的 Channel,通道中的未响应请求数量达到 5 个将阻塞,当被缓存的未响应请求收到响应,可以继续添加。
你认为的幂等性和真实的幂等性
我们都知道 Kafka 实现了 三种形式的消息可靠交付逻辑:
最多一次(at most once):消息可能会丢失,但绝不会被重复发送。 至少一次(at least once):消息不会丢失,但有可能被重复发送。 精确一次(exactly once):消息不会丢失,也不会被重复发送。
Kafka 默认提供的交付可靠性保障是第二种,即至少一次。如果你使用最多一次的交付模式,需要将 Producer 的重试模式禁用掉,这样消息要么发送成功要么就失败,但绝不会重发。当然你对于消息的发送失败 0 容忍,那么你也可以选择最极端的精确一次模式。
对于 “精确一次” 语义而言等同于 “幂等性” 的概念。即这条消息无论客户端发送了多少次,对于服务端而言,它只能消费一条。如果是我们来实现这个功能考虑会怎么做呢?我想大多数人可以想到的方案都是一样的:即客户端针对每一条消息生成一条唯一的 id,服务端记录下这条 id,如果已经消费过,则不再重复消费。
事实上 Kafka 也是这么做的。Kafka 为了实现幂等性,它在底层设计架构中引入了 ProducerID 和 SequenceNumber:
ProducerID:在每个新的 Producer 初始化时,会被分配一个唯一的 ProducerID,这个 ProducerID 对客户端使用者是不可见的。 SequenceNumber:对于每个 ProducerID,Producer 发送数据的每个 Topic 和 Partition 都对应一个从 0 开始单调递增的 SequenceNumber 值。
有了这两个参数之后,对于常见的网络情况:
比如 Producer 第一次发送一条消息 A 给到 Broker,SequenceNumber = 0,在返回 ack 的时候因为网络抖动丢包,此时 Producer 通过超时机制触发重试逻辑给 Broker,因为第一次的消息 A 生成的 ProducerID 是固定的,SequenceNumber 在重试的时候还是 0,那么对于 Broker 而言,它那里已经记录了上次发送过来的 SequenceNumber 值,所以本次判断还是 0 的情况就不会再次消费。
但是,这里要加一个先决条件:幂等性只对于单分区而言是有效的,跨分区的时候幂等性不成立。
Producer 发送一条消息在发送之前已经决定好了要分配给哪个 Partition。所以只有当前被发送的 Partition 才保存过该 Producer 的最新 SequenceNumber。换成别的 Partition 肯定就没有这个记录,所以不存在幂等性。如果你非常想要实现幂等性,那么有两种处理办法:
要么你将消息的 key 值固定,有相同 key 的消息都会发往同一个 Partition。这样实现的还是单分区的幂等。 第二种方案就是通过 Kafka 提供的事务机制来解决跨分区的幂等性。
关于 Kafka 的事务机制本篇就不再详述,大家有兴趣可以翻阅相关博文。
