简介:介绍pg_dump、pg_dumpall、copy、pg_basebackup的使用。
1,pg_basebackup
1.1,pg_basebackup的原理简介
pg_basebackup ------ 获得一个PostgreSQL集簇的一个基础备份
pg_basebackup 是集合API函数pg_start_backup和 pg_stop_backup,在9.1版本之前的物理备份可以通过pg_start_backup和 pg_stop_backup函数来进行实现备份,对于pg_basebackup来说步骤较多,注意的事项也比较多(比如复制槽、表空间等问题)。
备份通过一个使用复制协议常规PostgreSQL连接制作。该连接必须由一个具有REPLICATION权限或者具有超级用户权限的用户ID建立,
并且pg_hba.conf必须允许该复制连接。
该服务器还必须被配置,使max_wal_senders设置得足够高以提供至少一个walsender用于备份以及一个用于WAL流(如果使用流)。
1.2,pg_basebackup的参数介绍
pg_basebackup [option…]
-h host ( --host=host ) 指定运行服务器的机器的主机名。
-U username ( --username=username) 指定连接的用户名。
-r rate ( --max-rate=rate ) 设置从源服务器收集数据的最大传输速率(10M 表示速率:10MB/s)
-F format (–format=format) 为输出选择格式。p/t -Ft -z
-P (–progress) 启用进度报告。
-R ( --write-recovery-conf ) 创建一个standby.signal文件,并将连接设置附加到目标目录(或使用tar格式的基本存档文件中)的postgresql.auto.conf文件中。
-c fast|spread ( --checkpoint=fast|spread ) 将检查点模式设置为 fast(立刻)或 spread(默认)
-D directory (–pgdata=directory) 设置目标目录以将输出写入
–tablespace-mapping 表空间
1.3,示例
举例1:
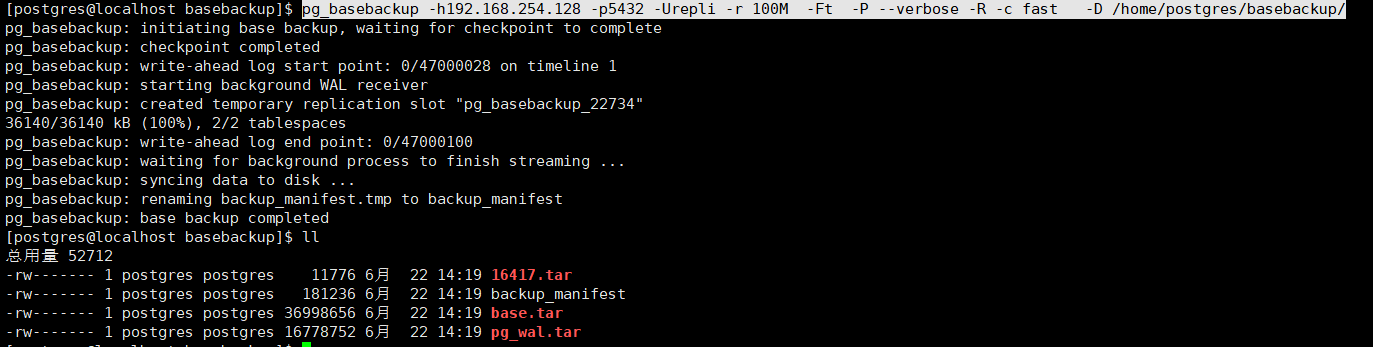
pg_basebackup -h192.168.254.128 -p5432 -Urepli -r 100M -Fp -P -R --verbose -c fast -D /home/postgres/basebackup/
(建议如果是制作从库,并且打算加上复制槽,可以加上参数-C --slot=slotname )


举例2:
pg_basebackup -h192.168.254.128 -p5432 -Urepli -r 100M -Ft -P --verbose -R -c fast -D /home/postgres/basebackup/
使用tar方式,如果有非默认表空间,会生成以该表空间的oid为名的压缩包,解压之后文件tablespace_map内包含独立表空间的绝对路径(如果想更改该路径可以在该文件中改动,并且需要在启动之后,在pg_tblspc中创建一下软连接)
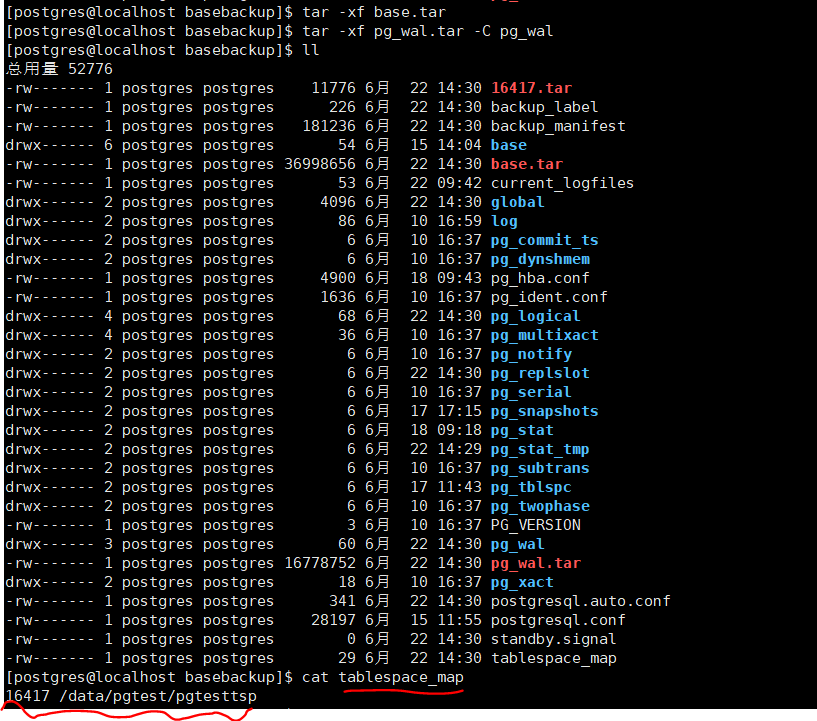
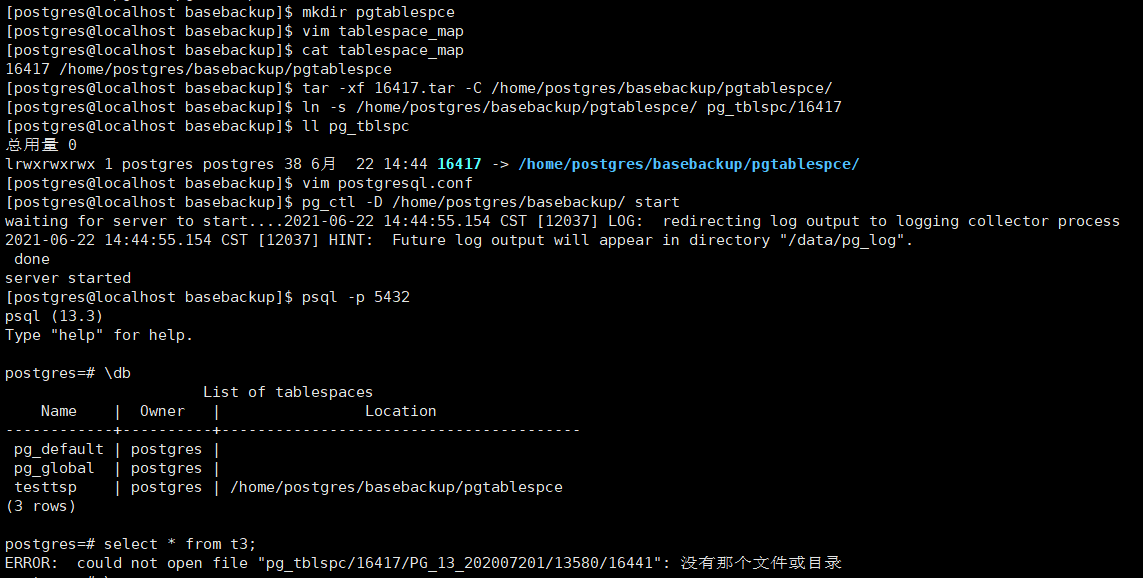
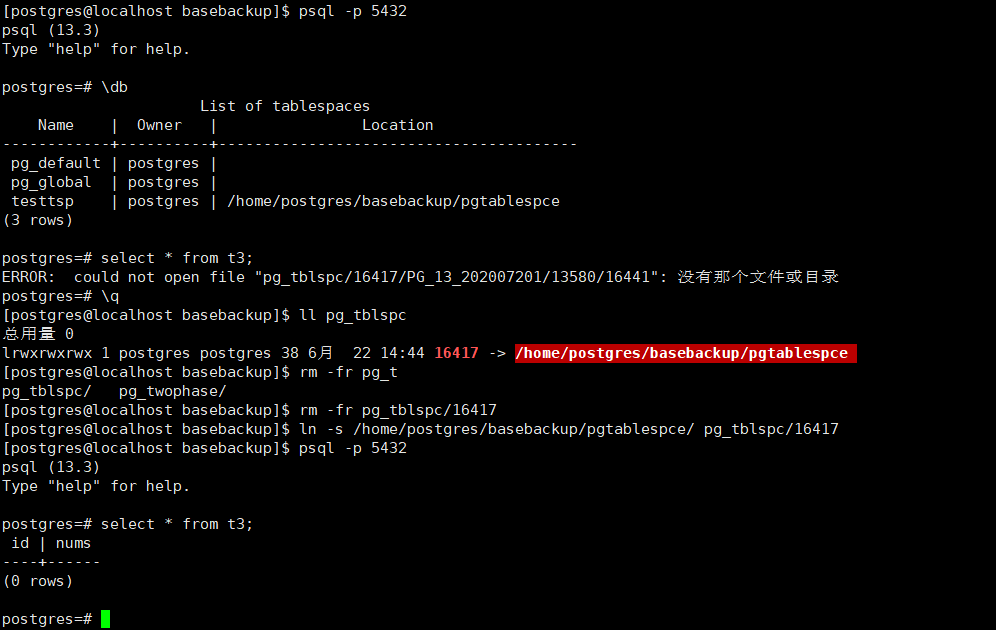
在此做测试的时候,如果再服务器启动前即便是设置好我们的tablespace_map,启动之后我们这里依然需要在启动之后在重新设置一下,个人感觉这个是需要一个待优化的地方。
附:查看那些有使用该表空间
select a.oid,a.relname,reltablespace,spcname,b.oid spcoid from pg_class a join pg_tablespace b on a.reltablespace=b.oid where b.oid=16417;

1.4,pg_basebackup的备份恢复
一般生产中用pg_basebackup来备份,可能会需要恢复到某个时间点上。这样就需要备份文件加wal日志来进行恢复。下面是演示过程:
环境介绍:
主:192.168.254.128 (创建了独立表空间)
备:192.168.254.129
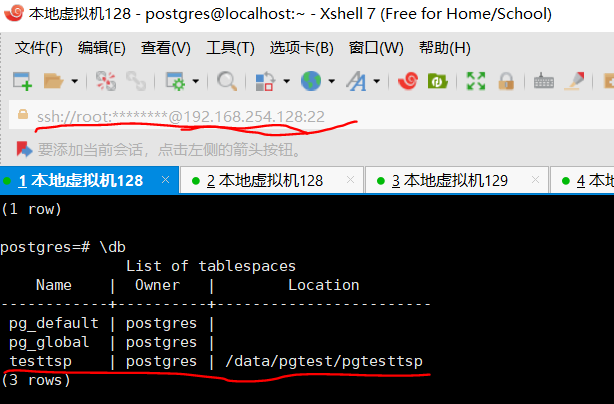
从192.168.254.129上进行备份:
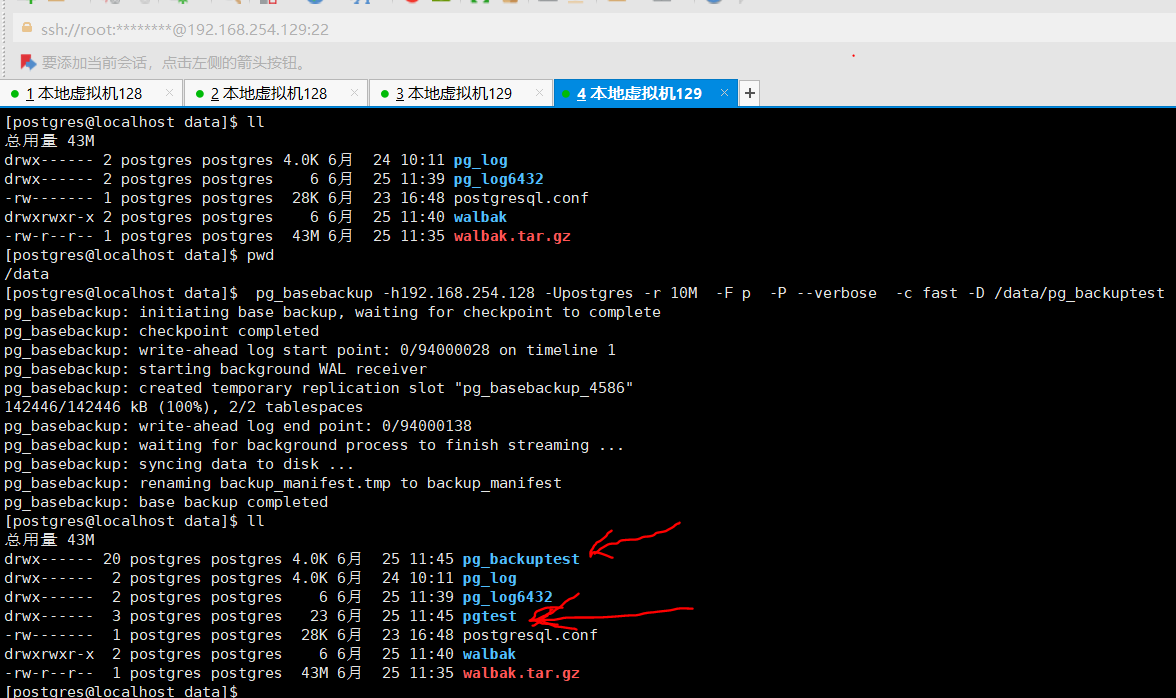
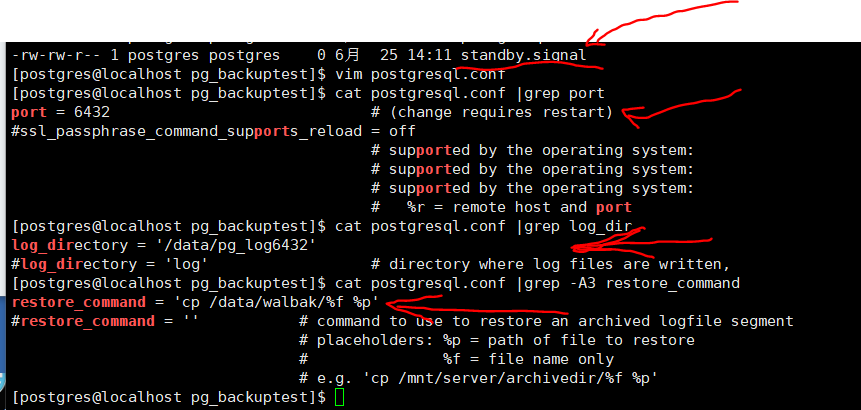
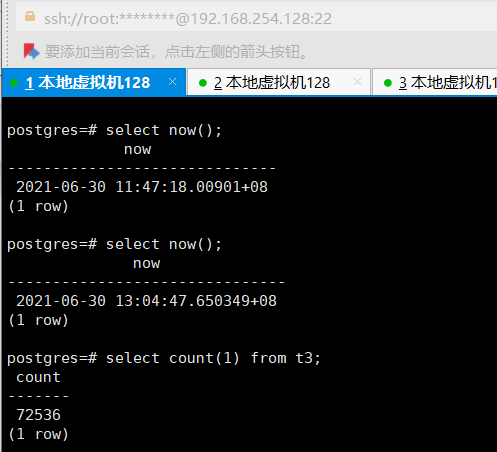
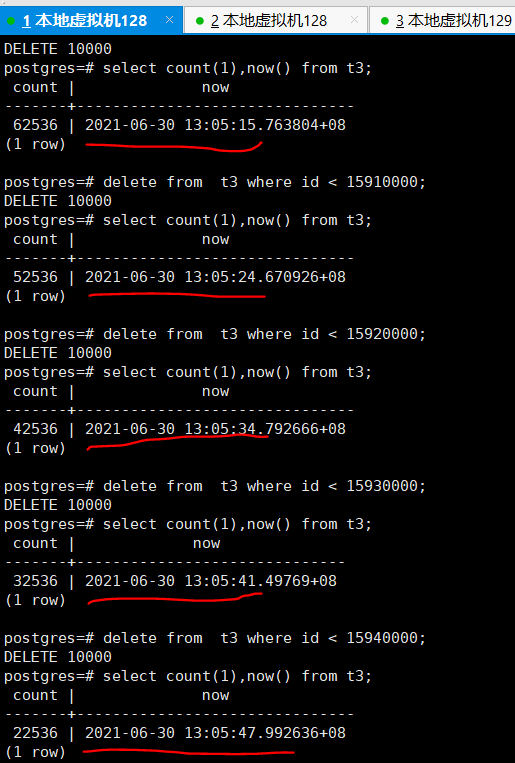
在192.168.254.128上进行删除数据操作,并记录下时间和对应的数据情况
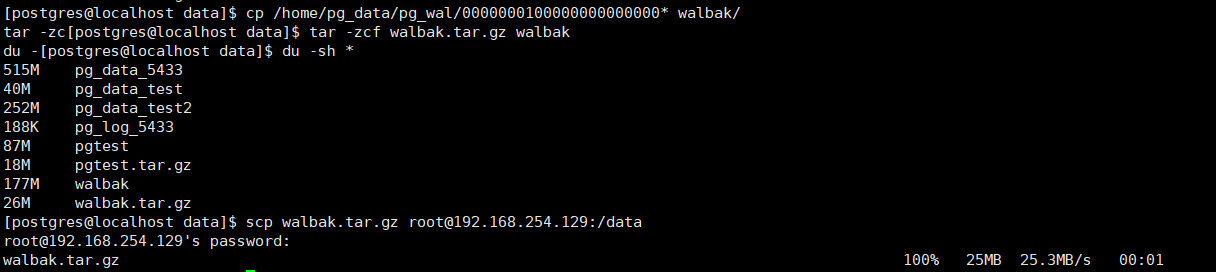
在128上打包wal日志,传输至129上进行相关测试
在129上设置恢复的时间点:

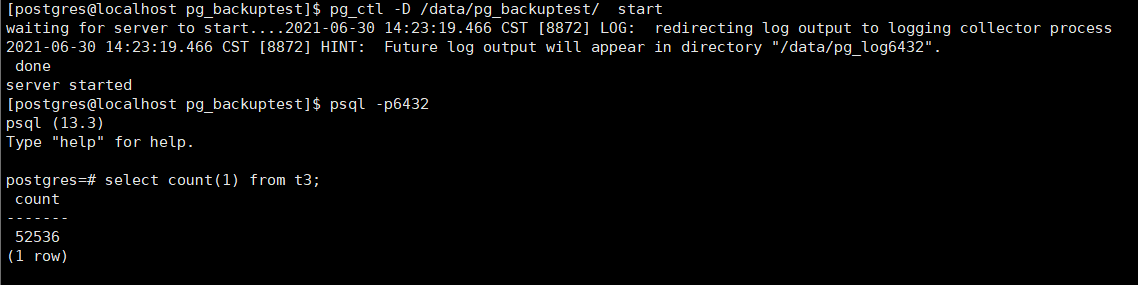
这里可以看到这里的t3数据量是和128这个时间点的数据量是吻合的
2,pg_dump/pg_dumpall pg_restore
2.1 介绍及参数
pg_dump/pg_dumpall 的备份方式是逻辑备份。
pg_dump只转储单个数据库。要备份一个集簇或者集簇中 对于所有数据库公共的全局对象(例如角色和表空间),应使用 pg_dumpall。pg_dump不阻塞其他用户访问数据库(读取或写入)。
pg_dumpall对一个集簇中所有的PostgreSQL数据库写出到(“转储”)一个脚本文件。该脚本文件包含可以用作psql的输入SQL命令来恢复数据库。它会对集簇中的每个数据库调用pg_dump来完成该工作。pg_dumpall还转储对所有数据库公用的全局对象(pg_dump不保存这些对象),也就是说数据库角色和表空间都会被转储。 目前这包括适数据库用户和组、表空间以及适合所有数据库的访问权限等属性。
pg_restore是一个用来从pg_dump创建的非文本格式归档恢复PostgreSQL数据库的工具
2.2 pg_dump选项:
-a ,–data-only只转储数据,而不转储数据定义。表数据、大对象和序列值都会被转储。
-n, --schema=PATTERN 只转储匹配pattern的模式,这会选择模式本身以及它所包含的所有对象
-s, --schema-only 只转储对象定义(模式),而非数据。这个选项是–data-only的逆选项
-t, --table=PATTERN 只转储名字匹配pattern的表
-T, --exclude-table=PATTERN 不转储匹配pattern模式的任何表
–column-inserts 将数据转储为带有显式列名的INSERT命令,这将使得恢复过程非常慢,这主要用于使转储能够被载入到非PostgreSQL数据库中
–inserts 将数据转储为INSERT命令(而不是COPY)
-F format,–format=format 选择输出的格式。format可以是下列之一:
p plain 输出一个纯文本形式的SQL脚本文件(默认值)。
c custom 输出一个适合于作为pg_restore输入的自定义格式归档。和目录输出格式一起,这是最灵活的输出格式,它允许在恢复时手动选择和排序已归档的项。这种格式在默认情况还会被压缩。
d directory 输出一个适合作为pg_restore输入的目录格式归档。这将创建一个目录,其中每个被转储的表和大对象都有一个文件,外加一个所谓的目录文件,该文件以一种pg_restore能读取的机器可读格式描述被转储的对象。一个目录格式归档能用标准 Unix 工具操纵,例如一个未压缩归档中的文件可以使用gzip工具压缩。这种格式默认情况下是被压缩的并且也支持并行转储。
t tar 输出一个适合于输入到pg_restore中的tar-格式归档。tar 格式可以兼容目录格式,抽取一个 tar 格式的归档会产生一个合法的目录格式归档。不过,tar 格式不支持压缩。还有,在使用 tar 格式时,表数据项的相对顺序不能在恢复过程中被更改。
-j njobs,–jobs=njobs 通过同时归档njobs个表来运行并行转储
-d, --dbname=DBNAME 指定要连接的数据库的名称
-h, --host=HOSTNAME 指定服务器正在运行的机器的主机名
-p, --port=PORT 端口
-U, --username=NAME 要作为哪个用户连接
2.3 pg_restore选项:
-l,–list 列出归档的内容的表格。这个操作的输出能被用作-L选项的输入。注意如果把-n或-t这样的过滤开关与-l一起使用,它们将会限制列出的项。
-L list-file,–use-list=list-file 只恢复在list-file中列出的归档元素,并且按照它们出现在该文件中的顺序进行恢复。注意如果把-n或-t这样的过滤开关与-L一起使用,它们将会进一步限制要恢复的项。
-T trigger ,–trigger=trigger 只恢复所提及的触发器。可以用多个-T开关指定多个触发器。
-1 --single-transaction 将恢复作为单一事务执行(即把发出的命令包裹在BEGIN/COMMIT中)。这可以确保要么所有命令完全成功,要么任何改变都不被应用。这个选项隐含了–exit-on-error。
2.4 pg_restore的局限性。
- 在恢复数据到一个已经存在的表中并且使用了选项–disable-triggers时,pg_restore会在插入数据之前发出命令禁用用户表上的触发器,然后在完成数据插入后重新启用它们。如果恢复在中途停止,可能会让系统目录处于错误的状态。
- pg_restore不能有选择地恢复大对象,例如只恢复特定表的大对象。如果一个归档包含大对象,那么所有的大对象都会被恢复,如果通过-L、-t或者其他选项进行了排除,它们一个也不会被恢复。
一旦完成恢复,应该在每一个被恢复的表上运行ANALYZE,这样优化器能得到有用的统计信息
2.5 实例:
- 转储并压缩数据库testaubu到testaubu.sql.gz文件中
$ pg_dump testaubu |gzip > testaubu.sql.gz
- 转储数据库testaubu中的表test1到testaubu_test1.sql文件中
$ pg_dump testaubu -t test1 > testaubu_test1.sql
导入:
$ psql -p6432 -d test2 < testaubu_test1.sql
或者直接不落地导入
$ pg_dump testaubu -t test1 | psql -p6432 -d test2
- 转储数据库testaubu中的以users开头的表到testaubu_users.sql文件中
$ pg_dump testaubu -t 'users*' > testaubu_users.sql
- 转储数据库postgres
$pg_dump -h192.168.254.128 -p5432 postgres -Fc > dumptest_postgresdump_c
用pg_restore进行恢复(需要注意,如果目标库中不存在源端所需的用户和表空间,需要提前建立好,否则会出问题)
$ pg_restore -p 4432 -d postgres dumptest_dump_c
- 转储 postgres数据库 并发5 输出到目录dumptest1 中
$ pg_dump -h192.168.254.128 -p5432 postgres -Fd -j5 -f dumptest1
$ pg_restore -p 4432 -d testdb1 -j5 /data/dumptest1/

- 备份恢复不落地方式
$ pg_dump -h192.168.254.128 -p5432 postgres -Fc | pg_restore -p 4432 -d testdb2
3, 单表数据备份恢复copy
copy命令在平时日常维护中使用较为广泛,一方面是数据csv的导出,另一方面是单表数据(特别是数据量不大时)的转移或者导出,都有很多的应用。
copy与\copy 差异:
- 权限:
copy需要superuser或pg_execute_server_program角色的用户;
\copy一般用户即可,只要对表有查询权限
- 位置
copy是去服务器端寻找或者导出
\copy 是在客户端进行寻找或者导出
3.1,导出数据:
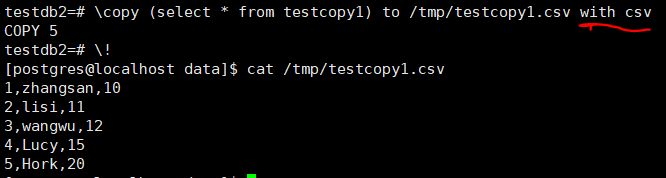
\copy (select * from testcopy1) to /tmp/testcopy1.csv with csv
其中只要()中是select语句,不管多复杂的sql,都可以进行特定数据的导出,这对于数据查询导出比较有用
3.2,表之间的数据转移
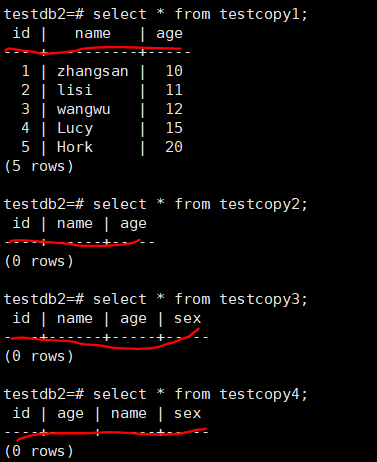
示例:
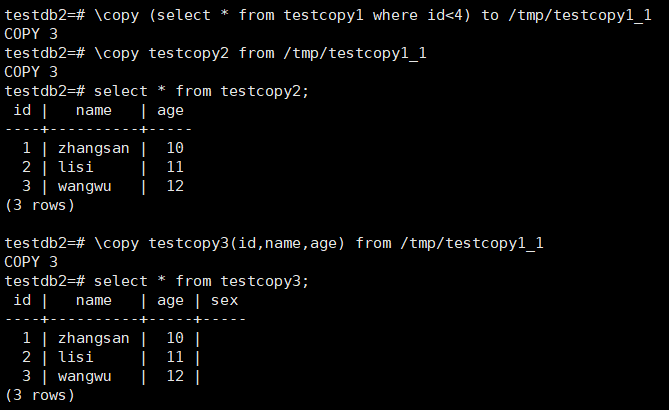
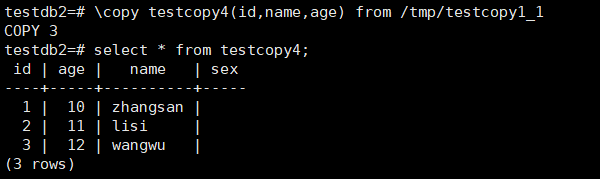
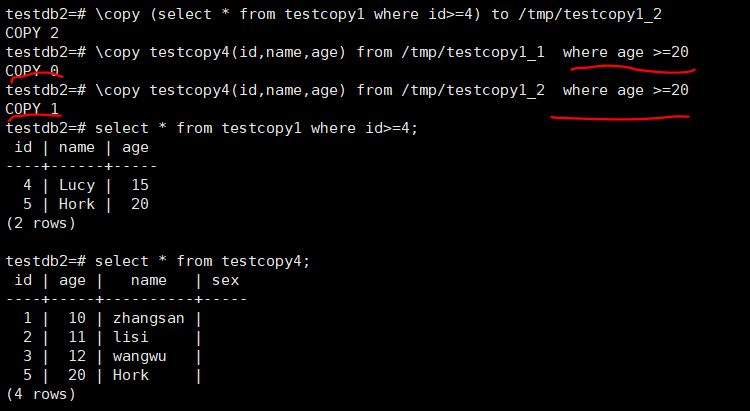
Pg 12版本以及以后copy from后面支持where条件: