




前言
公司的项目存储层框架使用的是mybatis-plus框架,框架很好不了解或者没用过的可以去看看官方文档,自带的service,和mapper基本能应付日常的增删改查操作,但是自带的mapper却没有批量插入功能,使用起来很不爽,而且service的saveBatch方法,在处理大批量数据时表现也不尽人意,所以打算重写下saveBatch方法;
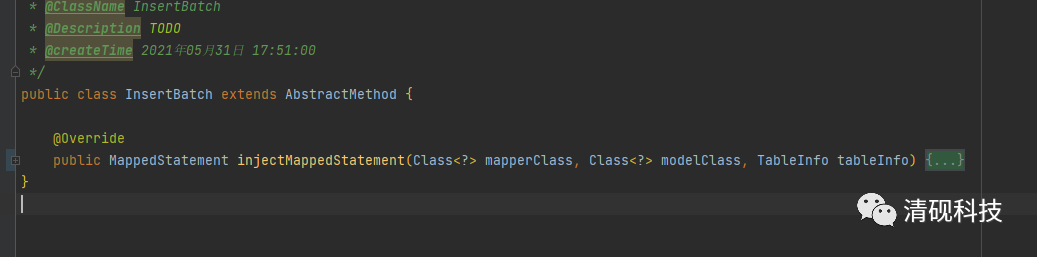
mapper添加自定义方法insertBatch
查看官方文档关于自定义mapper方法的地方
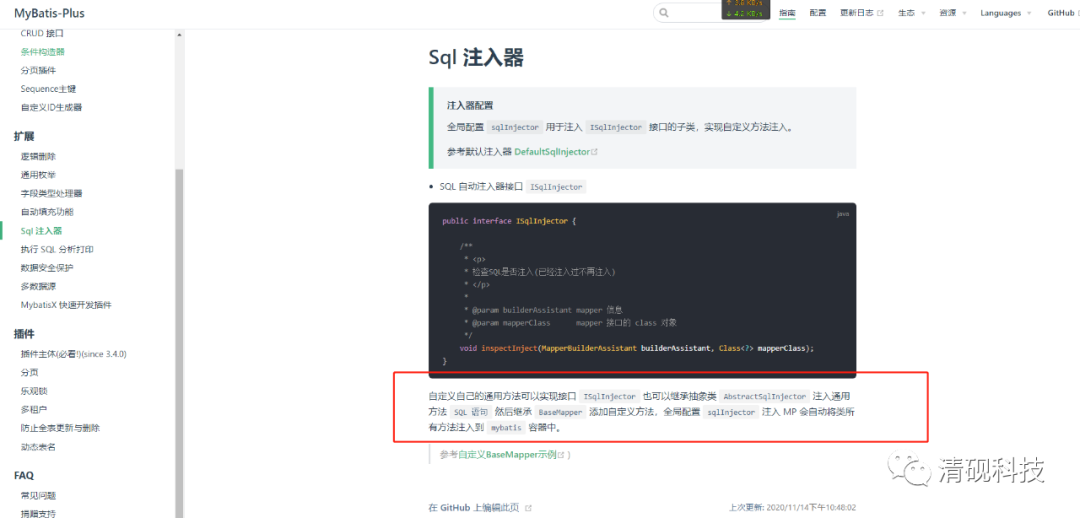
按照文档创建需要的三个类
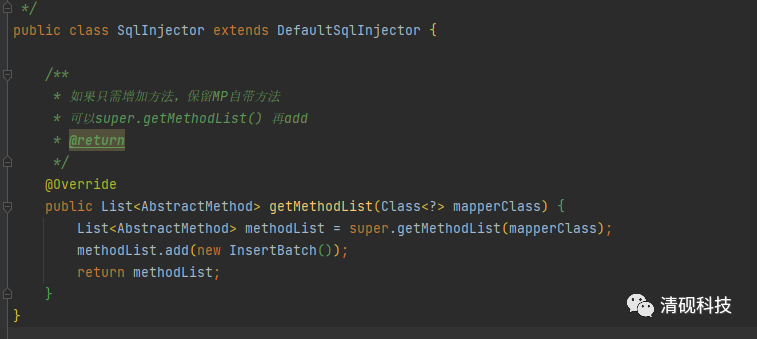
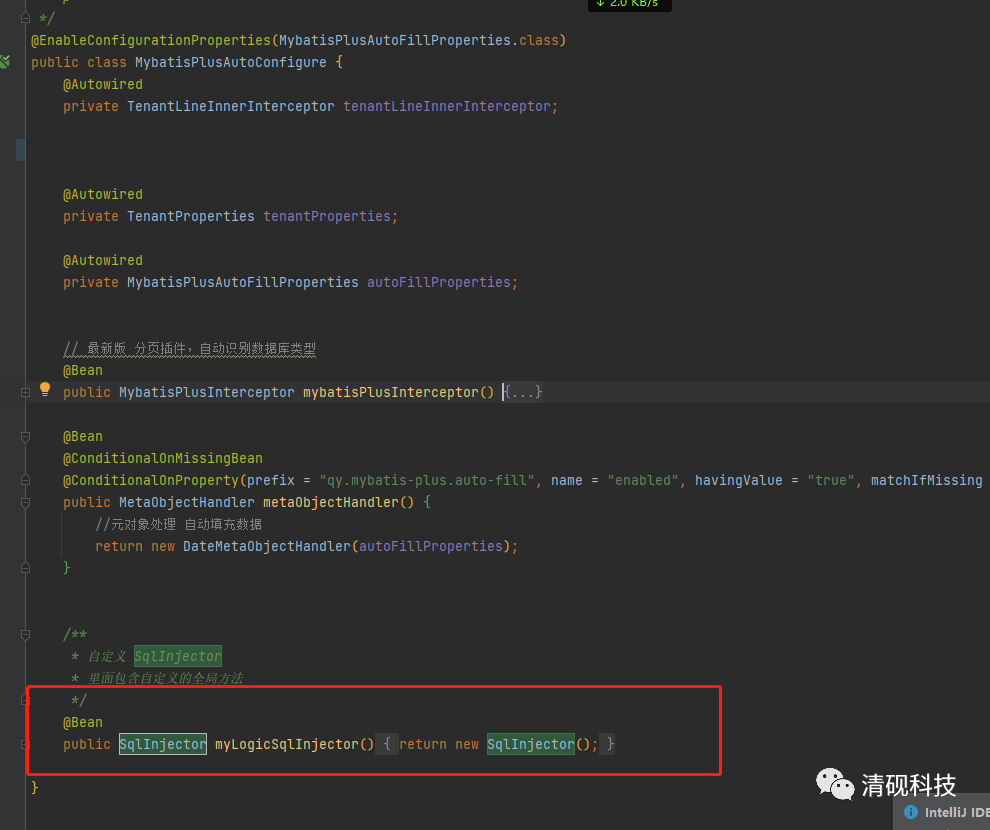
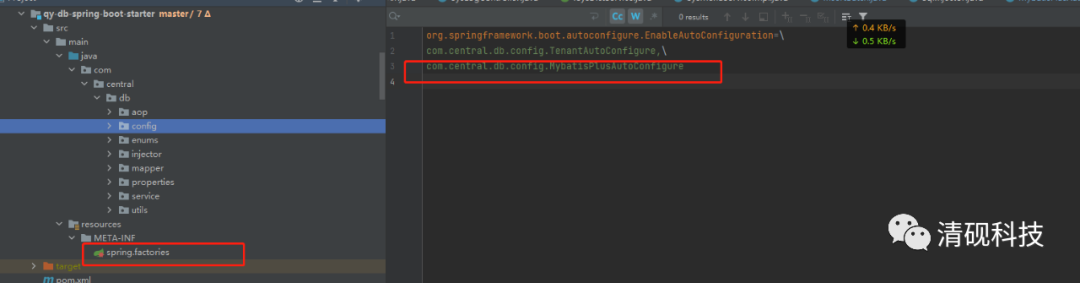
这边需要注意一点要将SqlInjector类交给spring管理,不然自定义方法不会生效(因为我将这些代码放在自定义start里面,所以这样配置)
接下来就可以来写InsertBatch方法的逻辑了
以向sys_dict这个表插入数据举例
CREATE TABLE "public"."sys_dict" (
"id" varchar(36) COLLATE "pg_catalog"."default" NOT NULL DEFAULT ''::character varying,
"version" int8 DEFAULT 1,
"creator" varchar(64) COLLATE "pg_catalog"."default",
"create_time" timestamp(6),
"updater" varchar(64) COLLATE "pg_catalog"."default",
"update_time" timestamp(6),
"is_del" varchar(6) COLLATE "pg_catalog"."default" DEFAULT 'N'::character varying,
"dict_key" varchar(100) COLLATE "pg_catalog"."default",
"dict_code" varchar(100) COLLATE "pg_catalog"."default",
"description" varchar(255) COLLATE "pg_catalog"."default",
"dict_value" varchar(255) COLLATE "pg_catalog"."default",
"status" varchar(255) COLLATE "pg_catalog"."default",
"tenant_id" varchar COLLATE "pg_catalog"."default",
CONSTRAINT "sys_dict_pkey" PRIMARY KEY ("id")
);
我们要生成的sql语句应该是这样的
INSERT INTO sys_dict ( id,dict_key,dict_code,description,dict_value,status,tenant_id,create_time,update_time,creator,updater,version,is_del ) VALUES <foreach collection="list" index="index" item="item" separator=",">
(#{item.id},#{item.dict_key},#{item.dict_code},#{item.description},#{item.dict_value},#{item.status},#{item.tenant_id},#{item.create_time},#{item.update_time},#{item.creator},#{item.updater},#{item.version},'N')
</foreach>
完善后的方法
public class InsertBatch extends AbstractMethod {
@Override
public MappedStatement injectMappedStatement(Class<?> mapperClass, Class<?> modelClass, TableInfo tableInfo) {
KeyGenerator keyGenerator = new NoKeyGenerator();
// INSERT_BATCH("insertBatch", "插入一条数据(选择字段插入)", "<script>\nINSERT INTO %s %s VALUES %s\n</script>"),;
SqlMethod sqlMethod = SqlMethod.INSERT_BATCH;
List<TableFieldInfo> fieldList = tableInfo.getFieldList();
//foreach中的字段
StringBuilder sb = new StringBuilder("#{item."+tableInfo.getKeyProperty()+"},");
//插入的列
StringBuilder colSb = new StringBuilder(tableInfo.getKeyColumn()+",");
//值字段
fieldList.stream().forEach(field->{
boolean logicDelete = field.isLogicDelete();
//给逻辑删除字段赋值
if(logicDelete){
sb.append("'").append(field.getLogicNotDeleteValue()).append("'").append(COMMA);
}else {
sb.append(field.getInsertSqlProperty("item."));
}
colSb.append(field.getInsertSqlColumn());
});
//列字段
String sqlScript = colSb.toString();
//获取 带 trim 标签的脚本
String columnScript = SqlScriptUtils.convertTrim(sqlScript.substring(0,sqlScript.length()-1),
LEFT_BRACKET, RIGHT_BRACKET, null, COMMA);
String allInsertSqlPropertyMaybeIf = sb.toString();
allInsertSqlPropertyMaybeIf= "("+allInsertSqlPropertyMaybeIf.substring(0,allInsertSqlPropertyMaybeIf.length()-1)+")";
//完整的foreach
String valuesScript = SqlScriptUtils.convertForeach(allInsertSqlPropertyMaybeIf,"list",null,"item", COMMA);
String keyProperty = null;
String keyColumn = null;
// 表包含主键处理逻辑,如果不包含主键当普通字段处理
if (StringUtils.isNotBlank(tableInfo.getKeyProperty())) {
if (tableInfo.getIdType() == IdType.AUTO) {
/** 自增主键 */
keyGenerator = new Jdbc3KeyGenerator();
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();
} else {
if (null != tableInfo.getKeySequence()) {
keyGenerator = TableInfoHelper.genKeyGenerator(sqlMethod.getMethod(), tableInfo, builderAssistant);
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();
}
}
}
//拼接完后的sql
String sql = String.format(sqlMethod.getSql(), tableInfo.getTableName(), columnScript, valuesScript);
SqlSource sqlSource = languageDriver.createSqlSource(configuration, sql, modelClass);
return this.addInsertMappedStatement(mapperClass, modelClass,sqlMethod.getMethod(), sqlSource, keyGenerator, keyProperty, keyColumn);
}
}
测试insertBatch方法
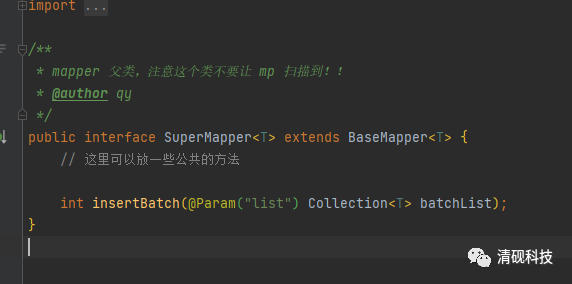
首先SysDictMapper要继承SuperMapper类
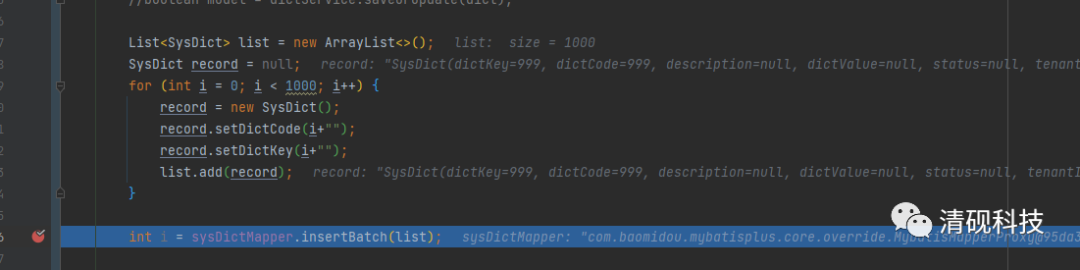
插入一千条数据
打印的日志是这样的
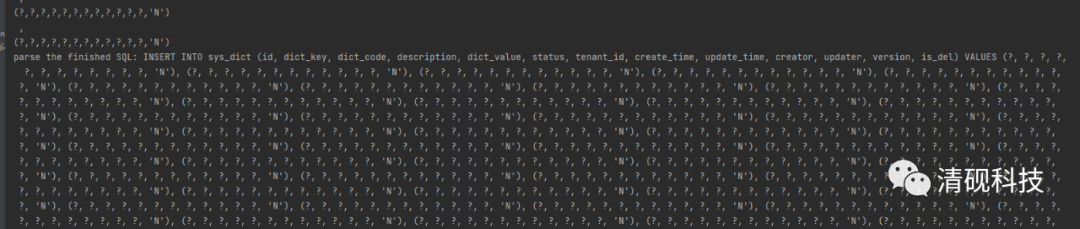
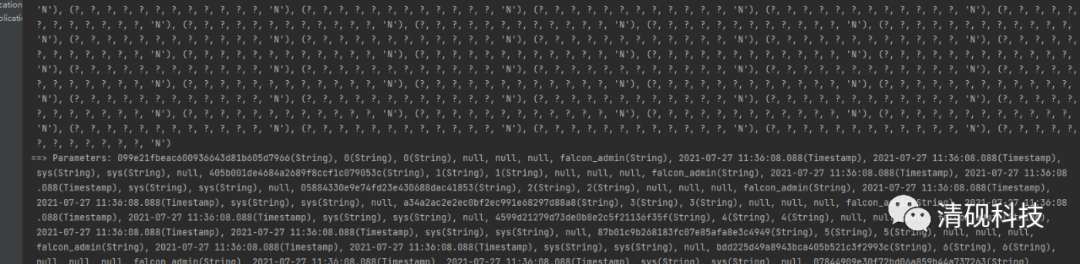
数据库插入的数据也没有问题
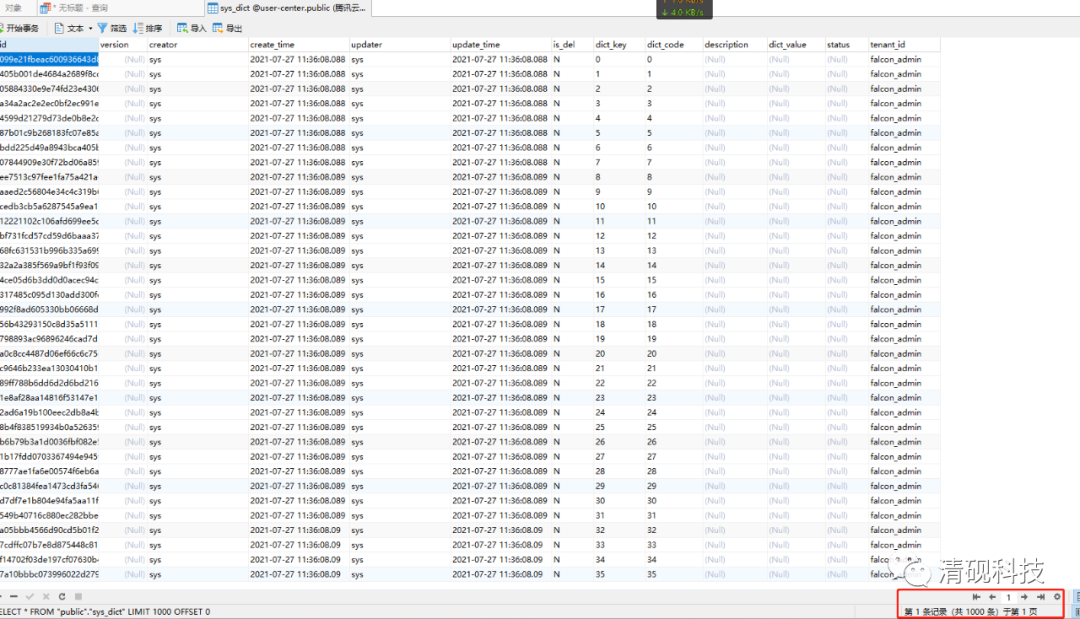

插入1000条数据耗时269毫秒
mapper添加自定义方法insertBatch结束
注意:每次批量插入的数据要根据实际情况,如果一次插入的过多,拼接的sql太长,在执行sql的时候数据库会报错,切记!!!
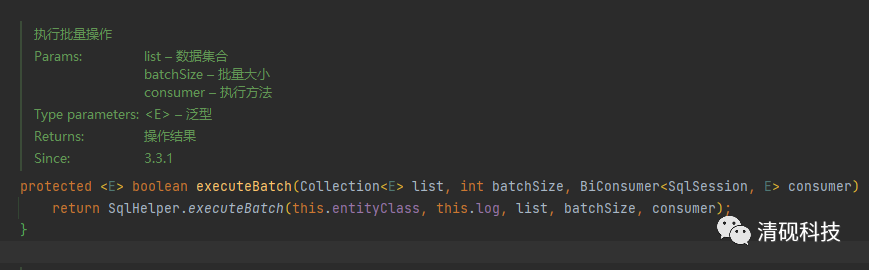
重构service的saveBatch方法
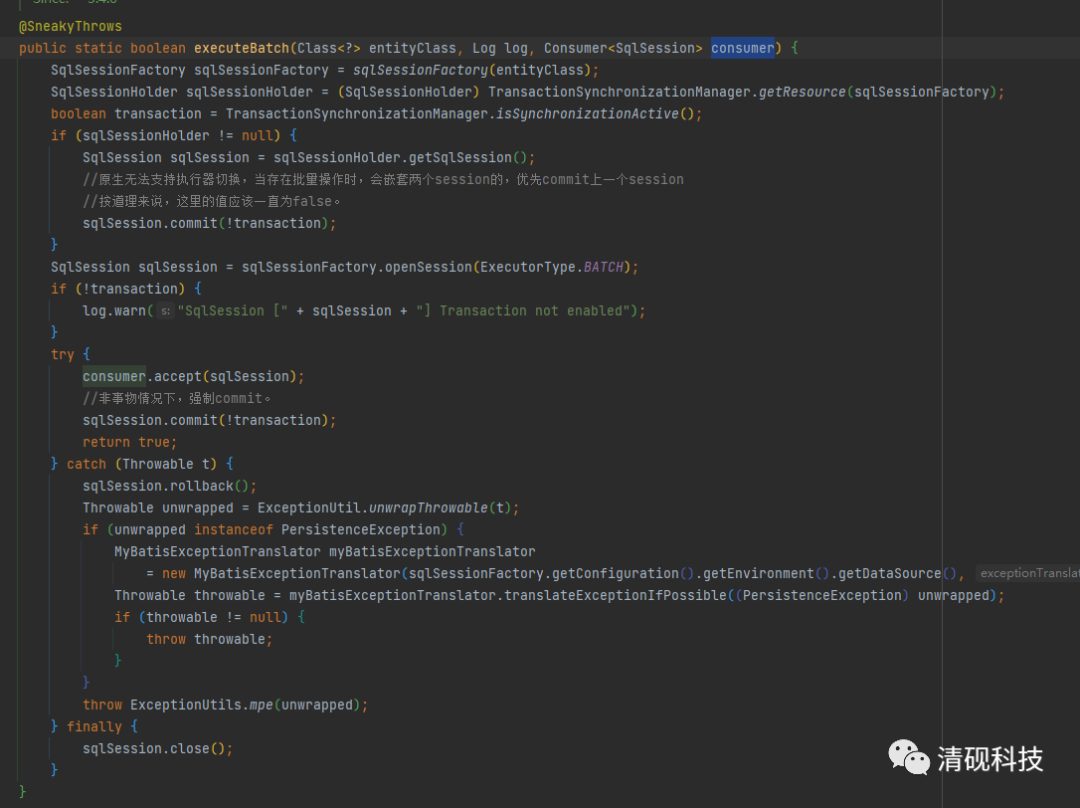
我们先来看看mybatis-plus的批量保存方法是怎么实现的
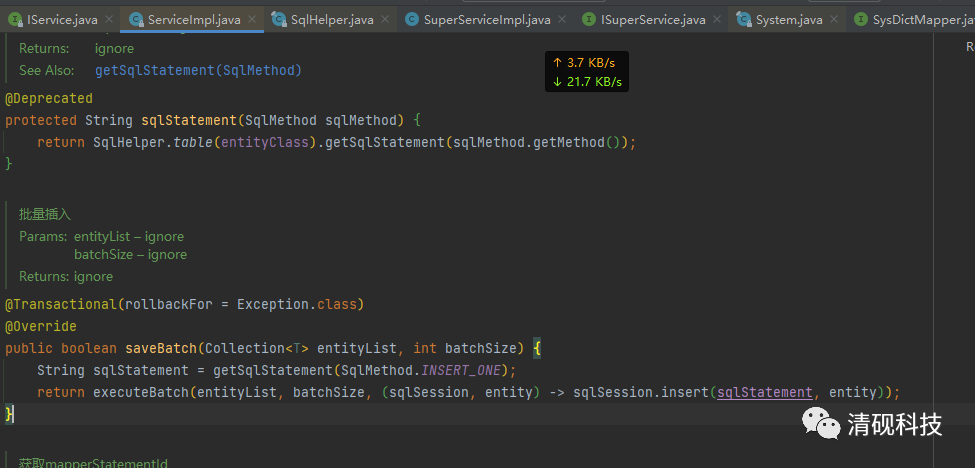
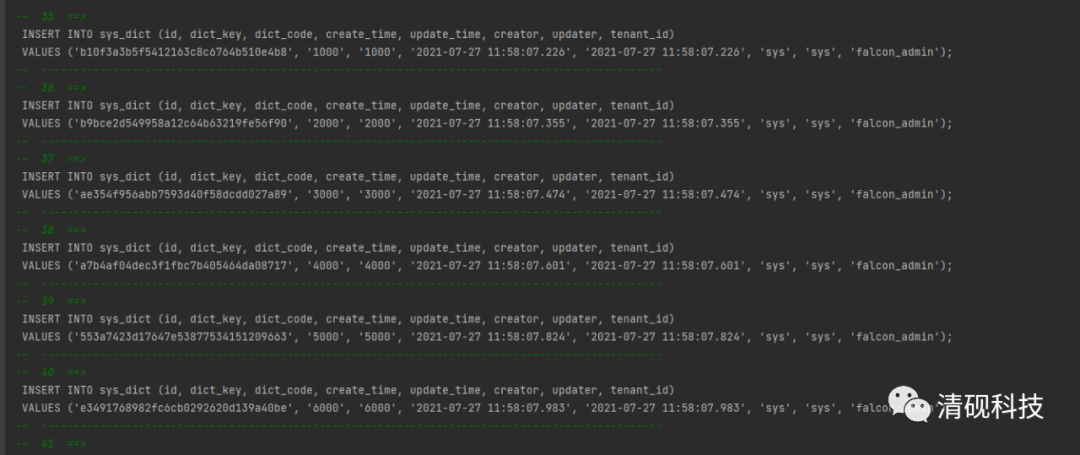
插入10000条数据
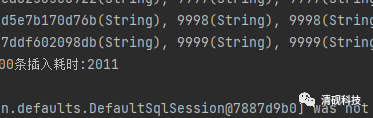
耗时:2011毫秒
发现每次插入是格式是
INSERT INTO sys_dict (id, dict_key, dict_code, create_time, update_time, creator, updater, tenant_id)
VALUES ('e3491768982fc6cb0292620d139a40be', '6000', '6000', '2021-07-27 11:58:07.983', '2021-07-27 11:58:07.983', 'sys', 'sys', 'falcon_admin');
这显然不是我们想要的结果
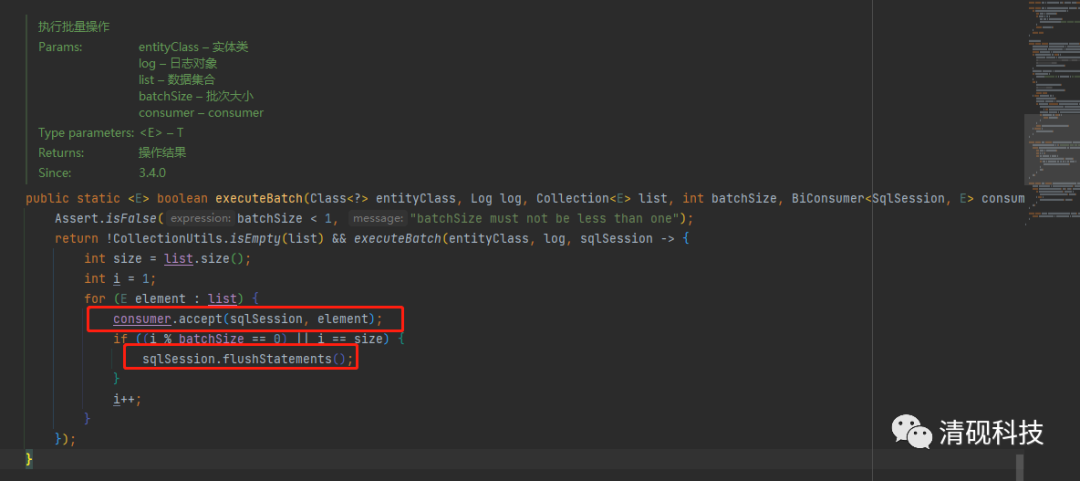
下面来开始改造
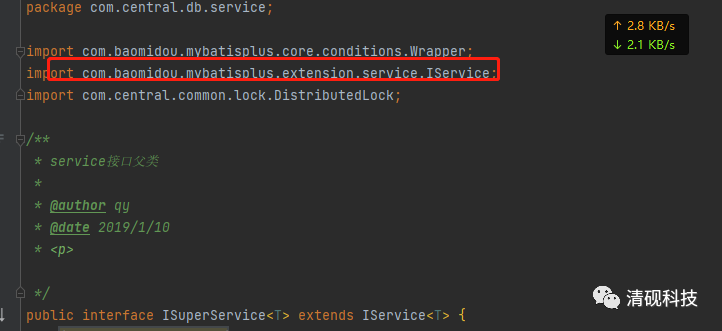
首先定义接口ISuperService继承mybatisplus的IService
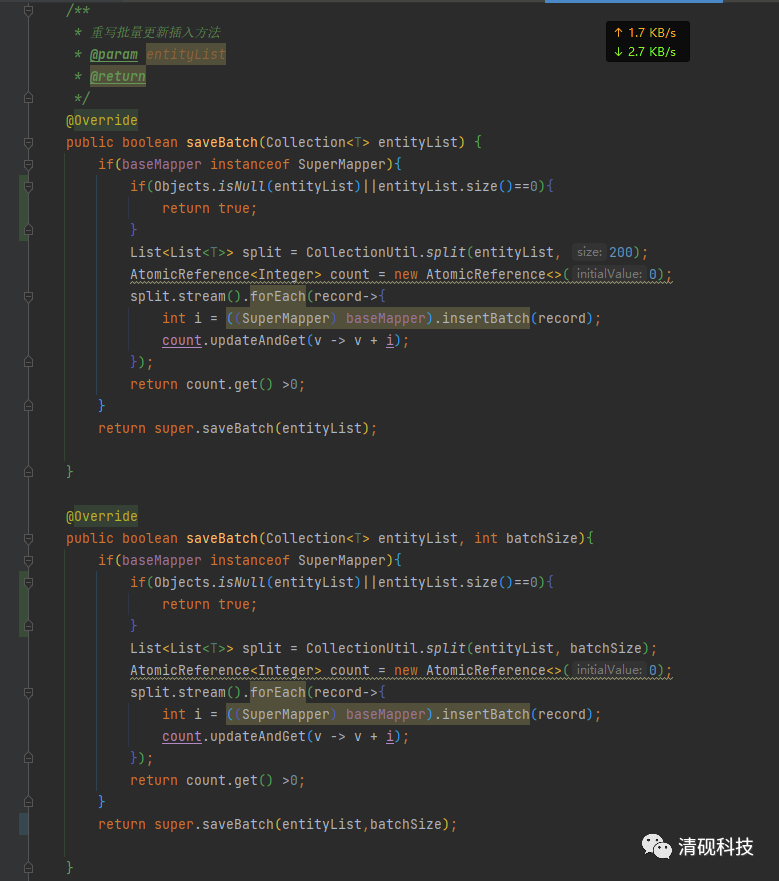
然后在实现类里重写saveBatch方法
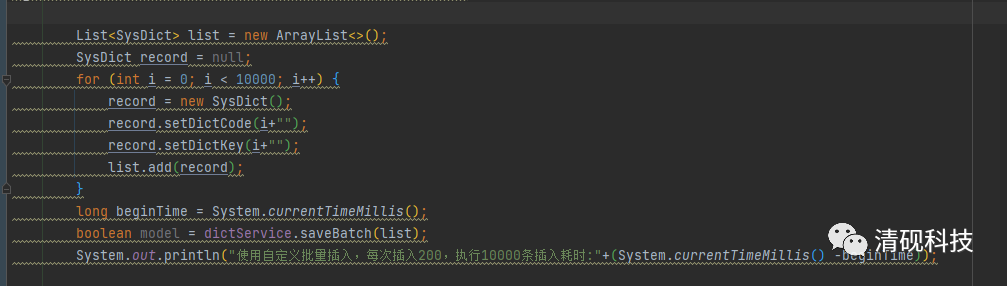
插入一万条数据(空表),对比
每次插入200条,耗时2095
插入500条,耗时:2170
插入800条,耗时:1973
插入1000条,耗时:2394
而mybatisplus插入一万条数据平均耗时大概是2000
插入10w条数据对比:
mybatisplus插入10w条数据耗时:21556
自定义插入10w条数据每次插入800条耗时::13723
通过测试对比发现 当数据量比较小时二者差别不是很大,但自定义的方法会因为分批插入,再数据高于设置的批量插入数量时会稍微耗时一点,但差别不大;当数据量很大是时,比如插入10w条数据,这时候我们自定义的批量插入方法耗时会大大降低
这里测试每次插入数据设置为800,耗时是最低的
到这里我们的功能就实现了,感谢大家阅读,当然点个关注更好。
