




HarperDB 的创始团队构建了第一个也是唯一一个用 Node.js 编写的数据库。几个月前,我们的 CEO Stephen Goldberg 受邀在 Women Who Code 聚会上发言,分享这个努力的故事。Stephen 讨论了数据库的架构层,演示了如何在 Node.js 中构建高度可扩展的分布式产品,并演示了 HarperDB 的内部工作原理。您可以在上面的链接中观看他的演讲,甚至可以阅读2017 年的一篇文章,但由于我们都喜欢 Node.js 并且这是一个有趣的话题,我将在此处进行总结。
我们选择在 Node 中构建数据库的主要(也是最简单的)原因是我们非常了解它。我们因为没有选择 Go 而受到抨击,但人们现在接受 Go 和 Node 本质上是正面交锋。我们的联合创始人之一扎克认识到,随着学习一个新语言所花费的时间,它永远不值得。
在 Node.js 中构建数据库的优点
- 我们已经知道 Node.js
- 轻的
- 快速发展
- 高度可扩展
- 新产品经理
HarperDB 团队具有大规模软件开发的背景。我们数据库的最初目标是创建一个工具,使开发人员能够专注于编码,而无需花费时间和精力进行数据库维护,同时仍然提供强大的解决方案。我们希望人们对他们使用的产品感到舒适和自信。我们的团队在 Node 以外的语言方面拥有丰富的经验,但我们在它的编程方面取得了巨大的成功。(虽然来自 Java,Stephen 起初认为 Node 很糟糕,但大约 90 天后他学会了喜欢它)。Node 是轻量级的,让我们可以快速开发,而且 npm 有令人难以置信的包。
在 Node.js 中构建数据库的缺点
- 当时不被接受为“企业级语言”。
- 不直接控制操作系统/文件系统。
- 性能不如 C/C++。
- 没有本地线程(现在有)。
我们确实遇到了一些麻烦,因为它是第一个用 Node.js 编写的数据库,我们没有选择跟随任何人的脚步。我们可能是最早在 Node 中构建的企业产品之一,至少是最以数据为中心的产品。人们对此提出质疑。一个人告诉斯蒂芬,他宁愿用勺子挖出自己的心脏,也不愿用 Node.js 编写数据库。现在人们已经意识到这是一个好主意,因为我们的产品中拥有所有这些令人难以置信的功能,而这些功能是我们不必构建的,并且是我们所做工作中固有的。我们确实遇到了无法直接控制文件系统中的操作系统的挑战。此外,C/C++ 速度更快,但可能更复杂,并且不一定具有水平可扩展性。这实际上取决于您是在寻找垂直计算还是水平计算。
技术栈

这就是我们的技术栈的样子。我们认为我们的Management Studio是 HarperDB 堆栈的一部分,它是在 React 中构建的,带有一个 Node 后端。绿色框表示构建在 HarperDB 之上的任何应用程序,例如,我们的Node-RED 节点可用于构建自定义工作流。HarperDB 技术完全构建在 Node.js 中,其中包含我们的接口和 HarperDB 核心。
我们的产品以 REST API 的形式呈现,它本质上只是一个 Express 应用程序,它是您如何与 HarperDB 交互的主要接口。我们的 NoSQL 解析器是我们内部构建的自定义解决方案。我们将 AlaSQL 用于我们的 SQL 解析功能,您可以在此处阅读更多信息,我们在此基础上使用自定义代码扩展了它们的功能,这是一个用于解析 SQL 的惊人 npm 包。我们提供由我们的合作伙伴构建的驱动程序,例如 ODBC 和 JDBC。最后,我们使用 SocketCluster 进行分布式计算和集群,这是CTO 在本次会议上提出的。
HarperDB 核心技术包含“秘方”。这使我们能够在没有数据重复的情况下完全索引,并为单个数据模型提供各种接口选项。在核心中,实现了许多 npm 包来扩展我们的功能。
最后,我们有多种存储介质选项。我们默认捆绑 LMDB,因为它比其他选项提供了显着的性能提升。HarperDB 核心包含可扩展代码,允许我们在未来添加额外的存储媒体选项。
REST API
- HarperDB 是一组微服务。
- 单个端点。
- 所有操作岗位。
- 无状态/RESTful。

在一家前公司,我们的团队处理了数百个具有不同端点的 API 的问题,这简直是疯了。人们可能会认为 HarperDB 只是一个端点很奇怪,但是如果您查看代码的主体,对于您执行的每个操作,您需要更改的只是主体,即前几行。这非常简单,在编写基于 REST 的应用程序时,您可以让它变得非常简单。这是您可以从我们这里获取并用于任何应用程序的东西!基本上,您向 API 发布一条消息,我们查看您正在执行的操作,并使用一组标准方法处理它。在过去的几年里,我们重写了很多应用程序,但这部分基本保持不变。
管理工作室
- 基于 HarperDB REST API 构建。
- 用 React Native 编写。
- 允许通过 GUI 控制您的 HarperDB 实例。
HarperDB Management Studio是一个构建在我们的微服务之上的 React 前端(所以我们吃自己的狗粮)。JavaScript 的一个很棒的地方是它的轻量级,无论您使用什么框架(Node、React 等),并且您可以轻松地将这些不同的层结合在一起。React 很棒,它改变了前端开发的质量,让我们的应用程序更易于访问。通过在此基础上构建,我们还同时测试了我们自己的 API,这使得它非常强大。我们的产品副总裁 Jaxon 选择在 Studio 中使用 React,而 Stephen 在 Express 中编写了我们的后端报告。
阿拉SQL
- SQL 搜索建立在 AlaSQL 之上。
- GitHub 链接。
- 允许增强的 SQL。
- 我们的开发人员为该项目做出了贡献。
我们为 HarperDB 的后端功能选择了 AlaSQL,它有一些我们没有的很棒的东西,并且允许我们连接诸如 Math.js 和 GeoJSON 之类的东西,所以它是一个令人难以置信的包。将 Node 用于这样的语言的一个惊人好处是,随着技术的进步,您想要和需要的大部分很酷的东西都在 npm 上。如果我们必须构建自己的 SQL 解析器,我们可能仍在构建 HarperDB。我们的竞争对手之一 FaunaDB 花了大约 4 年时间才上市,但我们在 6 个月内推出了我们产品的测试版,在 12 个月内推出了原始版本,几个月前我们刚刚发布了我们的云产品(大约3年后)。我们并不是说我们是天才,但是通过在 Node 中进行开发,我们必须站在像 AlaSQL 开发人员这样的人的肩膀上,这就是我们发现 npm 社区令人惊奇的地方。
数学.js
- HarperDB 在我们的 SQL 中使用 math.js 函数。
- 允许增强数学能力,同时利用 npm 社区的能力。
Maths.js 是另一个令人难以置信的包,用于处理平均值、数据科学等,我们将其连接到我们的 SQL 功能中。与 AlaSQL 结合使用并不难,而且功能非常强大。
 集群/复制
集群/复制
- 建立在 SocketCluster.io 上。
- 容错。
- 点对点。
- 表级复制。
- 全局共享模式。
- 分布式计算。
在 Node.js 中构建东西的另一个非常酷的特性是它本质上是无状态的,这意味着它不需要将数据保存在内存中,这对于跨会话服务客户端至关重要,这非常节省资源。大多数企业级应用程序都有可能变得非常不稳定的后台进程和状态变量。Node 是无状态的,专为 Web 设计,旨在水平扩展和点对点。使用 Node 框架的一个惊人好处是我们能够连接 SocketCluster 来支持我们的集群和复制。HarperDB 使用简单的 pub-sub 模型,因此我们通过将数据发布到不同节点订阅的不同聊天室来复制数据,并且可以水平分布。与其他语言相比,该节点可以水平扩展且资源密集度更低,
通过将 Node 放在大量计算机上(横向扩展),您可以显着提高框架的功能,同时降低成本、简化开发并成为一个很棒的社区的一部分。
LMDB 和文件系统
- 最初在文件系统上构建了我们的分解数据模型。
- 由于生成许多文件占用 inode 和过多的磁盘空间以及其他问题而出现问题。
- 在 LMDB 上重建数据模型。
- 巨大的性能提升。
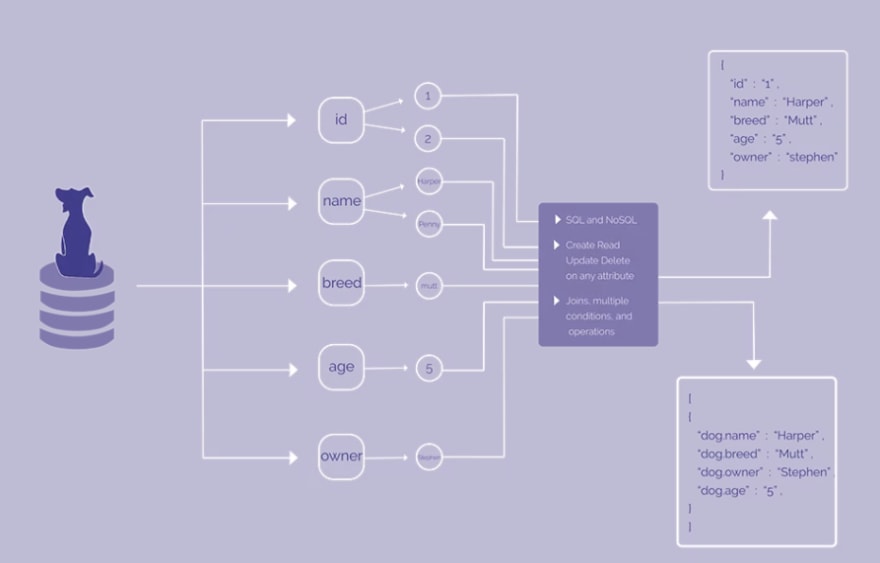
最初,我们直接将文件系统与上述 HarperDB 数据模型一起使用,这就是该产品的独特之处。当数据进来时,我们将它映射到我们的数据模型,它不是 SQL 引擎或 NoSQL 引擎。我们将这些数据分解为单独的属性,并将它们存储在文件系统的文件夹结构中。我们以原子方式存储每件事,您可以通过 SQL 和 NoSQL 进行查询。我们确实遇到了一些大规模的挑战,所以最近我们连接了一个名为 LMDB 的包,这是我们在其上操作的键值存储。我们能够在此基础上实现我们的精确数据模型,它提供了令人难以置信的性能提升。在最近的基准测试中,我们的速度比 MongoDB 快约 37 倍,这在很大程度上要归功于 LMDB。
再一次,通过利用令人惊叹的 Node 社区,我们能够专注于我们擅长的领域。
文章来源:https://dzone.com/articles/building-a-database-written-in-nodejs-from-the-gro
