




1.to_sql一步到位

import pandas as pdimport sqlalchemyuser = 'user' # 数据库用户名password = 'password' # 数据库密码ip = '192.168.0.1:1521/orcl' # 数据库地址conn = sqlalchemy.create_engine('oracle+cx_oracle://'+user+':'+password+'@'+ip)sql = '''select * from table'''df = pd.read_sql(sql,conn)df.to_sql('tablename',conn,if_exists='append',index=False)
pip install sqlalchemy # 安装sqlalchemy库
engine = create_engine("postgresql+psycopg2://user:password@host/dbname")engine = create_engine("mysql+pymysql://scott:tiger@localhost/test")# create_engine的第一个参数的组成内容dialect[+driver]://user:password@host/dbname
DataFrame.to_sql(name, # 要插入数据的表名称con, # 数据库连接对象schema=None, # 数据库模式,具体看数据库if_exists='fail', # 如果插入数据的表已经存在,那么,fail:返回失败;append:追加到原表;replace:替换原表数据index=True, # 是否插入DataFrame的index列的数据index_label=None, # index列数据插入后的列名称chunksize=None, # 每次执行插入操作的数据条数。100:每次插入100条。None:一次性插入所有数据dtype=None, # 插入数据的数据类型method=None) # 插入操作。{None,multi,callable} None:标准插入操作;multi:为单个insert操作指定多行值;callable:callable with signature (pd_table, conn, keys, data_iter).callable暂时没搞懂
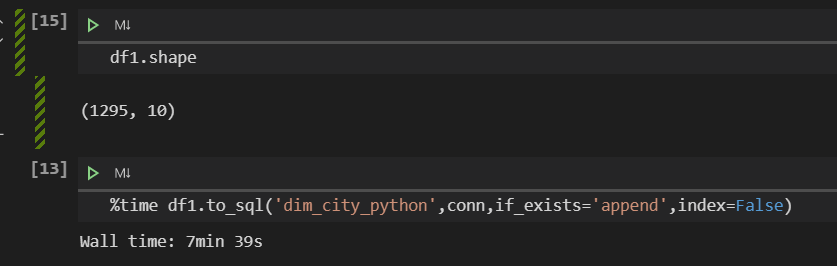
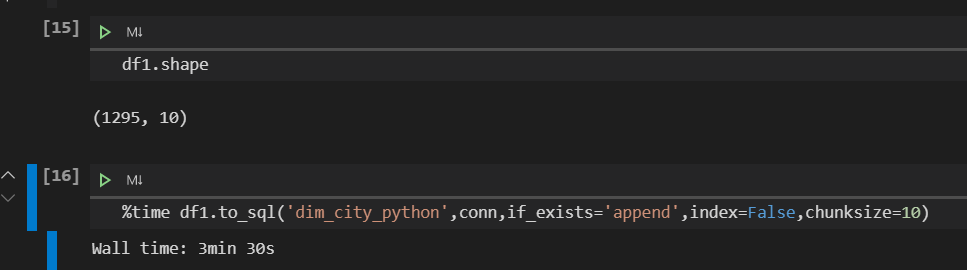
2.insert第一版
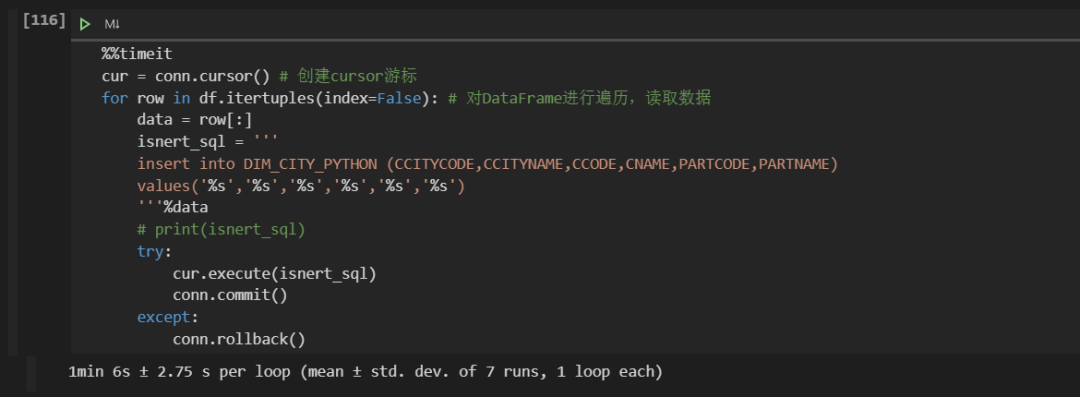
import cx_Oracleuser = 'user'password = '123456'ip = '192.168.0.1:1521/orcl'conn = cx_Oracle.connect(user,password,ip) # 创建数据库连接对象cur = conn.cursor() # 创建cursor游标for row in df1.itertuples(index=False): # 对DataFrame进行遍历,读取数据data = row[:]isnert_sql = '''insert into DIM_CITY_PYTHON (CCITYCODE,CCITYNAME,CCODE,CNAME,PARTCODE,PARTNAME)values('%s','%s','%s','%s','%s','%s')'''%data# print(isnert_sql)try:cur.execute(isnert_sql)conn.commit()except:conn.rollback()
for col in df:print(col)
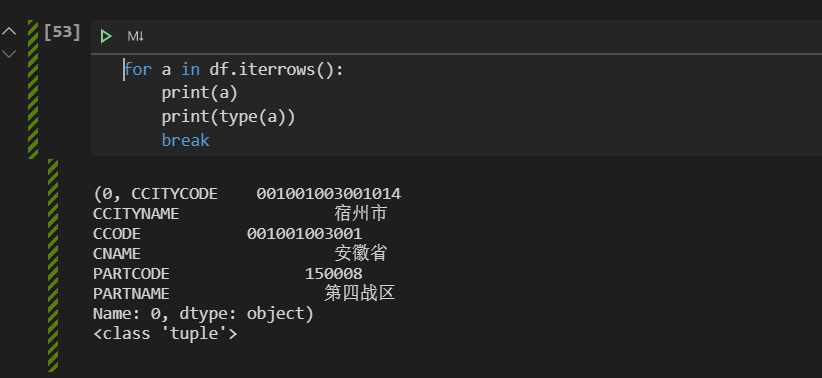
for label,values in df.items():print(label,values)
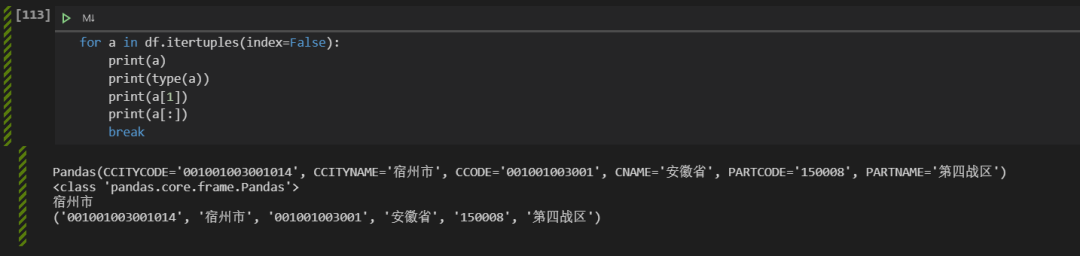
3.insert第二版
insert into table (a,b,c,d……) --字段select values1,values2,values3…… from dual --要插入的值。from dual 是oracle的写法。union allselect values1,values2,values3…… from dualunion allselect values1,values2,values3…… from dual……
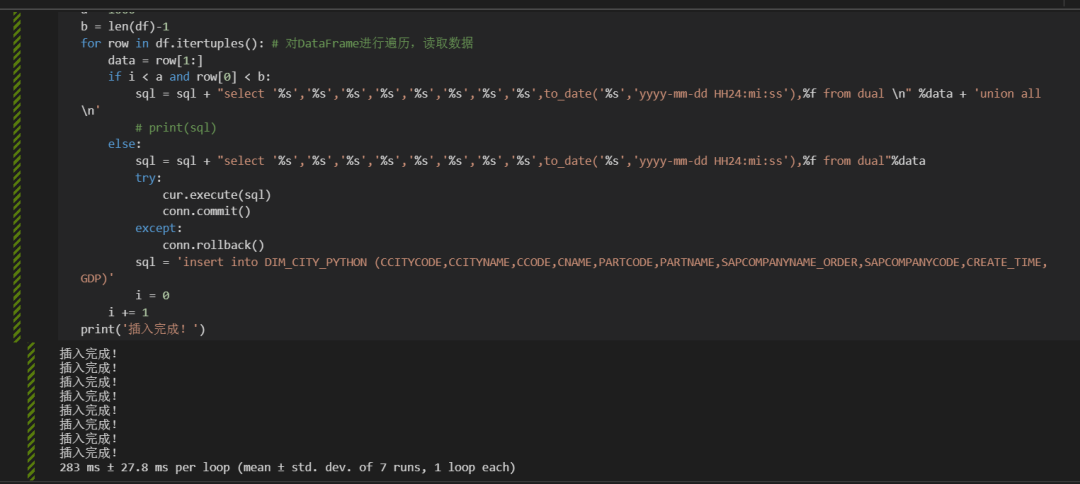
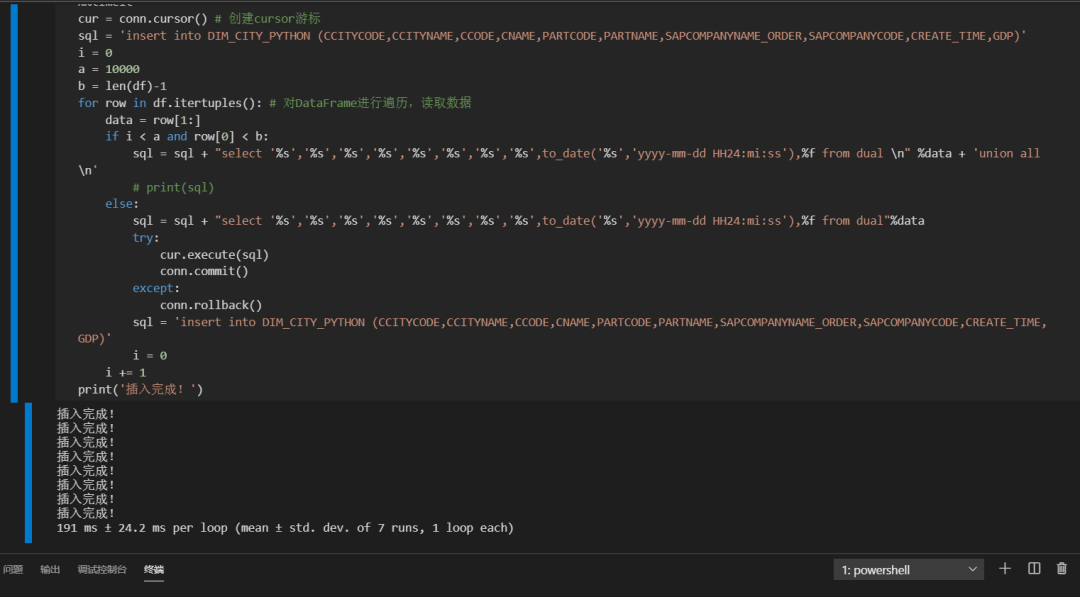
%%time # jupyter notebook的魔法函数,可以查看代码块的执行时间cur = conn.cursor() # 创建cursor游标sql = 'insert into DIM_CITY_PYTHON (CCITYCODE,CCITYNAME,CCODE,CNAME,PARTCODE,PARTNAME,SAPCOMPANYNAME_ORDER,SAPCOMPANYCODE,CREATE_TIME,GDP)'i = 0 # 设置起始值a = 1000 # 设置每次插入的数据条数b = len(df)-1for row in df.itertuples(): # 对DataFrame进行遍历,读取数据data = row[1:] # 获取遍历DataFrame中的要插入的字段值。row[0]是索引值。data是个tuple,所以下面的sql代码后面直接使用的%dataif i < a and row[0] < b:sql = sql + "select '%s','%s','%s','%s','%s','%s','%s','%s',to_date('%s','yyyy-mm-dd HH24:mi:ss'),%f from dual \n" %data + 'union all \n'else:sql = sql + "select '%s','%s','%s','%s','%s','%s','%s','%s',to_date('%s','yyyy-mm-dd HH24:mi:ss'),%f from dual"%datatry:cur.execute(sql)conn.commit()except:conn.rollback()sql = 'insert into DIM_CITY_PYTHON (CCITYCODE,CCITYNAME,CCODE,CNAME,PARTCODE,PARTNAME,SAPCOMPANYNAME_ORDER,SAPCOMPANYCODE,CREATE_TIME,GDP)'i = 0i += 1print('插入完成!')
4.insert第三版-万能插入代码
# oracle数据库的万能插入数据代码。只要给出的插入数据字段能跟数据库表对应上。def get_conn():user = 'user'pwd = '123456'ip = 'localhost:1521/orcl'conn = cx_Oracle.SessionPool(user,pwd,ip,min=2,max=6).acquire()return conndef insert_data(name,data): # name:插入的表名称;data:要插入的数据的DataFrame格式with get_conn() as conn: # get_conn() 获取数据库连接对象的函数cur = conn.cursor()columns = data.columns # 获取要出入数据的列名称tmp = ''fields = ''length_columns = len(columns)for i in range(length_columns): # 获取要插入的列的数量及插入代码tmp = tmp + ':' + str(i+1)fields = fields + columns[i]if i < length_columns-1:tmp += ','fields += ','insert_sql = ''' # 要执行插入操作的SQLinsert into %s (%s)values(%s)'''%(name,fields,tmp)insert_data = []for rows in data.itertuples(): # 遍历要插入的数据DataFramerow = rows[1:] # 获取需要插入的数据。注意:rows[0]是索引。insert_data.append(row)if (rows[0]+1) % 10000 == 0 or rows[0] == len(data)-1: # 每次插入10000条。跟上面代码不同的是,我们这里直接使用索引来判断每次插入的数量和是否达到最后一行数据。cur.executemany(insert_sql,insert_data)conn.commit()insert_data = []


# oracleinsert into table_name (字段1,字段2,字段3……)values (:1,:2,:3……) # 注意这里的数字是从1开始的,结尾的数字要跟上面的字段数量对应上# sqlserverinsert into table_name(字段1,字段2,字段3……)values (%s,%d,%s……) # 这里的s/d要跟上面字段的数据类型对应上
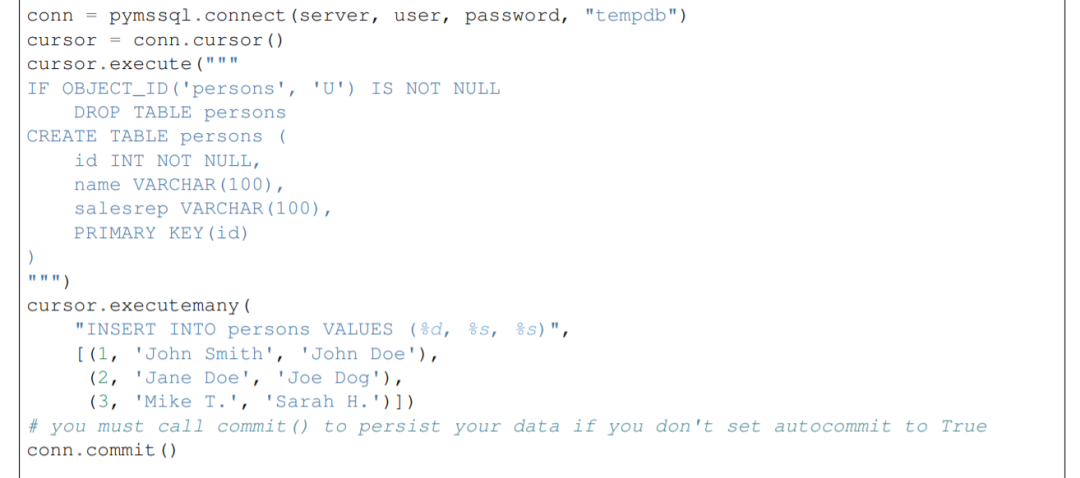
下图是sqlserver的示例代码
要插入的数据格式:
它是一个列表数据,列表内部存储的是每行数据的元组。
data = [( 110, "Parent 110"),( 2000, "Parent 2000"),( 30000, "Parent 30000"),( 400000, "Parent 400000"),(5000000, "Parent 5000000")]cursor.executemany(""" insert into ParentTable (ParentId, Description) values (:1, :2)""", data)
而当我们使用itertuples()方法对DataFrame进行遍历时,刚好得到的结果就是元组类型的每行数据。因此我们获取它的遍历结果放入一个空列表中,就能得到executemany()方法所需的data了。
人生苦短,我用Python!
一切皆是信息,万物源自比特!数字化必定会深刻革命我们的办公和生活!
简道云,中小企业数字化之路的绝佳伴侣!
Python,把自己从低效、重复的消耗中解放出来!
本公众号将分享数字化的实践、学习、思考。也许涉及信息化系统设计、各种办公软件、数据分析、理论知识、实践案例…… 感谢你与我一同成长……
如果有关企业数字化的疑问、思考和讨论 或者 关于简道云的应用搭建、数据工厂、仪表盘等疑问咨询或者合作,欢迎与我联系。(关注公众号,可以找到我的联系方式)
文章转载自龙小马的数字化之路,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
