




作者
digoal
日期
2016-07-25
标签
PostgreSQL , 任意字段 , 分词 , 匹配
背景
在有些应用场景中,可能会涉及多个字段的匹配。
例如这样的场景,一张表包含了几个字段,分别为歌手,曲目,专辑名称,作曲,歌词, 。。。
用户可能要在所有的字段中以分词的方式匹配刘德华,任意字段匹配即返回TRUE。
传统的做法是每个字段建立分词索引,然后挨个匹配。
这样就导致SQL写法很冗长,而且要使用大量的OR操作。 有没有更好的方法呢?
当然有,可以将整条记录输出为一个字符串,然后对这个字符串建立分词索引。
但是问题来了,整条记录输出的格式是怎么样的,会不会影响分词结果。
PostgreSQL 行记录的输出格式
```
create table t1(id int, c1 text, c2 text, c3 text);
insert into t1 values (1 , '子远e5a1cbb8' , '子远e5a1cbb8' , 'abc');
postgres=# select t1::text from t1;
t1
(1,子远e5a1cbb8,子远e5a1cbb8,abc)
(1 row)
postgres=# \df+ record_out
List of functions
Schema | Name | Result data type | Argument data types | Type | Security | Volatility | Owner | Language | Source code | Description
------------+------------+------------------+---------------------+--------+----------+------------+----------+----------+-------------+-------------
pg_catalog | record_out | cstring | record | normal | invoker | stable | postgres | internal | record_out | I/O
(1 row)
```
record类型输出对应的源码
src/backend/utils/adt/rowtypes.c
```
/
* record_out - output routine for any composite type.
/
Datum
record_out(PG_FUNCTION_ARGS)
{
...
/ And build the result string /
initStringInfo(&buf);
appendStringInfoChar(&buf, '('); // 首尾使用括弧
for (i = 0; i < ncolumns; i++)
{
...
if (needComma)
appendStringInfoChar(&buf, ','); // 字段间使用逗号
needComma = true;
...
/ Detect whether we need double quotes for this value /
nq = (value[0] == '\0'); / force quotes for empty string /
for (tmp = value; tmp; tmp++)
{
char ch = tmp;
if (ch == '"' || ch == '\\' ||
ch == '(' || ch == ')' || ch == ',' ||
isspace((unsigned char) ch))
{
nq = true;
break;
}
}
/* And emit the string */
if (nq)
appendStringInfoCharMacro(&buf, '"'); // 某些类型使用""号
for (tmp = value; *tmp; tmp++)
{
char ch = *tmp;
if (ch == '"' || ch == '\\')
appendStringInfoCharMacro(&buf, ch);
appendStringInfoCharMacro(&buf, ch);
}
if (nq)
appendStringInfoCharMacro(&buf, '"');
}
appendStringInfoChar(&buf, ')');
...
```
scws分词的问题
看似不应该有问题,只是多个逗号,多了双引号,这些都是字符,scws分词应该能处理。
但是实际上有点问题,例子:
这两个词只是末尾不一样,多个个逗号就变这样了
```
postgres=# select * from ts_debug('scwscfg', '子远e5a1cbb8,');
alias | description | token | dictionaries | dictionary | lexemes
-------+-------------+-------+--------------+------------+---------
k | head | 子 | {} | |
a | adjective | 远 | {simple} | simple | {远}
e | exclamation | e5a | {simple} | simple | {e5a}
e | exclamation | 1cbb | {simple} | simple | {1cbb}
e | exclamation | 8 | {simple} | simple | {8}
u | auxiliary | , | {} | |
(6 rows)
postgres=# select * from ts_debug('scwscfg', '子远e5a1cbb8');
alias | description | token | dictionaries | dictionary | lexemes
-------+-------------+----------+--------------+------------+------------
k | head | 子 | {} | |
a | adjective | 远 | {simple} | simple | {远}
e | exclamation | e5a1cbb8 | {simple} | simple | {e5a1cbb8}
(3 rows)
```
问题分析的手段
PostgreSQL分词的步骤简介
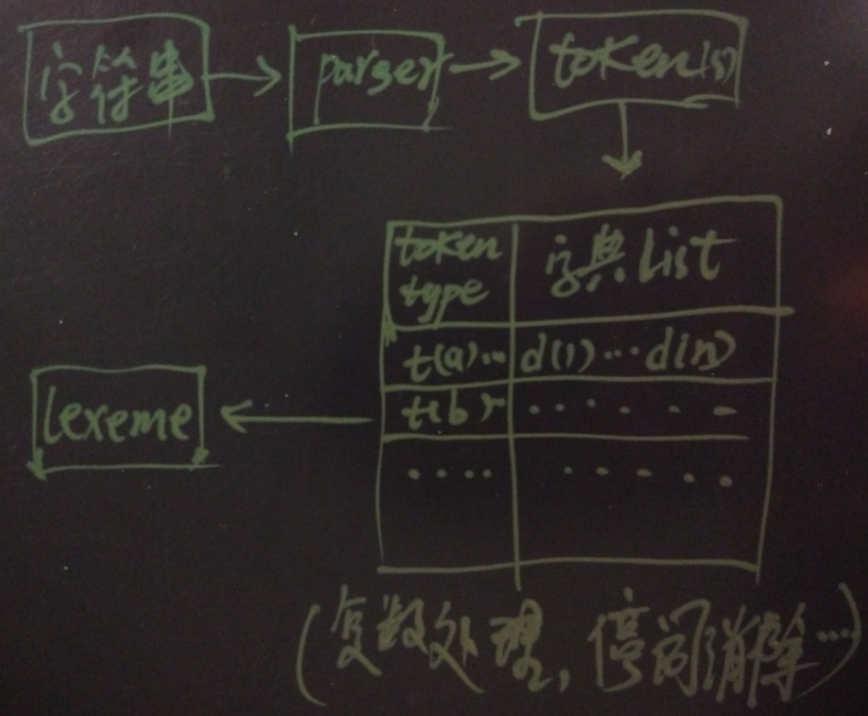
1. 使用parse将字符串拆分成多个token,以及每个token对应的token type
所以创建text search configuration时,需要指定parser,parser也是分词的核心
Command: CREATE TEXT SEARCH CONFIGURATION
Description: define a new text search configuration
Syntax:
CREATE TEXT SEARCH CONFIGURATION name (
PARSER = parser_name |
COPY = source_config
)
同时parser支持哪些token type也是建立parser时必须指定的
Command: CREATE TEXT SEARCH PARSER
Description: define a new text search parser
Syntax:
CREATE TEXT SEARCH PARSER name (
START = start_function ,
GETTOKEN = gettoken_function ,
END = end_function ,
LEXTYPES = lextypes_function
[, HEADLINE = headline_function ]
)
查看已创建了哪些parser
postgres=# select * from pg_ts_parser ;
prsname | prsnamespace | prsstart | prstoken | prsend | prsheadline | prslextype
---------+--------------+--------------+------------------+------------+---------------+----------------
default | 11 | prsd_start | prsd_nexttoken | prsd_end | prsd_headline | prsd_lextype
scws | 2200 | pgscws_start | pgscws_getlexeme | pgscws_end | prsd_headline | pgscws_lextype
jieba | 2200 | jieba_start | jieba_gettoken | jieba_end | prsd_headline | jieba_lextype
(3 rows)
查看parser支持的token type如下
scws中的释义
http://www.xunsearch.com/scws/docs.php#attr
postgres=# select * from ts_token_type('scws');
tokid | alias | description
-------+-------+---------------
97 | a | adjective
98 | b | difference
99 | c | conjunction
100 | d | adverb
101 | e | exclamation
102 | f | position
103 | g | word root
104 | h | head
105 | i | idiom
106 | j | abbreviation
107 | k | head
108 | l | temp
109 | m | numeral
110 | n | noun
111 | o | onomatopoeia
112 | p | prepositional
113 | q | quantity
114 | r | pronoun
115 | s | space
116 | t | time
117 | u | auxiliary
118 | v | verb
119 | w | punctuation
120 | x | unknown
121 | y | modal
122 | z | status
(26 rows)
2. 每种toke type,对应一个或多个字典进行匹配处理
ALTER TEXT SEARCH CONFIGURATION name
ADD MAPPING FOR token_type [, ... ] WITH dictionary_name [, ... ]
查看已配置的token type 与 dict 的map信息
postgres=# select * from pg_ts_config_map ;
3. 第一个适配token的字典,将token输出转换为lexeme
(会去除stop words),去复数等。
以下几个函数可以用来调试分词的问题
- ts_token_type(parser_name text, OUT tokid integer, OUT alias text, OUT description text)
返回指定parser 支持的token type
- ts_parse(parser_name text, txt text, OUT tokid integer, OUT token text)
指定parser, 将字符串输出为token
- ts_debug(config regconfig, document text, OUT alias text, OUT description text, OUT token text, OUT dictionaries regdictionary[], OUT dictionary regdictionary, OUT lexemes text[])
指定分词配置,将字符串输出为token以及额外的信息
上面的例子,我们可以看到使用scws parser时,输出的token发生了变化
```
postgres=# select * from pg_ts_parser ;
prsname | prsnamespace | prsstart | prstoken | prsend | prsheadline | prslextype
---------+--------------+--------------+------------------+------------+---------------+----------------
default | 11 | prsd_start | prsd_nexttoken | prsd_end | prsd_headline | prsd_lextype
scws | 2200 | pgscws_start | pgscws_getlexeme | pgscws_end | prsd_headline | pgscws_lextype
jieba | 2200 | jieba_start | jieba_gettoken | jieba_end | prsd_headline | jieba_lextype
(3 rows)
postgres=# select * from ts_parse('scws', '子远e5a1cbb8,');
tokid | token
-------+-------
107 | 子
97 | 远
101 | e5a
101 | 1cbb
101 | 8
117 | ,
(6 rows)
```
如何解决
在不修改scws代码的情况下,我们可以先将逗号替换为空格,scws是会忽略空格的
```
postgres=# select replace(t1::text, ',', ' ') from t1;
replace
(1 子远e5a1cbb8 子远e5a1cbb8 abc)
(1 row)
postgres=# select to_tsvector('scwscfg', replace(t1::text, ',', ' ')) from t1;
to_tsvector
'1':1 'abc':6 'e5a1cbb8':3,5 '远':2,4
(1 row)
```
行全文检索 索引用法
```
postgres=# create or replace function rec_to_text(anyelement) returns text as $$
select $1::text;
$$ language sql strict immutable;
CREATE FUNCTION
postgres=# create index idx on t1 using gin (to_tsvector('scwscfg', replace(rec_to_text(t1), ',', ' ')));
CREATE INDEX
SQL写法
postgres=# explain verbose select * from t1 where to_tsvector('scwscfg', replace(rec_to_text(t1), ',', ' ')) @@ to_tsquery('scwscfg', '子远e5a1cbb8');
QUERY PLAN
Bitmap Heap Scan on public.t1 (cost=4.50..6.52 rows=1 width=100)
Output: c1, c2, c3, c4
Recheck Cond: (to_tsvector('scwscfg'::regconfig, replace(rec_to_text(t1.), ','::text, ' '::text)) @@ '''远'' & ''e5a1cbb8'''::tsquery)
-> Bitmap Index Scan on idx (cost=0.00..4.50 rows=1 width=0)
Index Cond: (to_tsvector('scwscfg'::regconfig, replace(rec_to_text(t1.), ','::text, ' '::text)) @@ '''远'' & ''e5a1cbb8'''::tsquery)
(5 rows)
```
参考
-
http://www.xunsearch.com/scws/docs.php#attr
-
https://github.com/jaiminpan/pg_jieba
-
https://github.com/jaiminpan/pg_scws
-
https://yq.aliyun.com/articles/7730
-
分词速度,每CPU核约4.44万字/s。
```
postgres=# create extension pg_scws;
CREATE EXTENSION
Time: 6.544 ms
postgres=# alter function to_tsvector(regconfig,text) volatile;
ALTER FUNCTION
postgres=# select to_tsvector('scwscfg','中华人民共和国万岁,如何加快PostgreSQL结巴分词加载速度');
to_tsvector
'postgresql':4 '万岁':2 '中华人民共和国':1 '分词':6 '加快':3 '加载':7 '结巴':5 '速度':8
(1 row)
Time: 0.855 ms
postgres=# set zhparser.dict_in_memory = t;
SET
Time: 0.339 ms
postgres=# explain (buffers,timing,costs,verbose,analyze) select to_tsvector('scwscfg','中华人民共和国万岁,如何加快PostgreSQL结巴分词加载速度') from generate_series(1,100000);
QUERY PLAN
Function Scan on pg_catalog.generate_series (cost=0.00..260.00 rows=1000 width=0) (actual time=11.431..17971.197 rows=100000 loops=1)
Output: to_tsvector('scwscfg'::regconfig, '中华人民共和国万岁,如何加快PostgreSQL结巴分词加载速度'::text)
Function Call: generate_series(1, 100000)
Buffers: temp read=172 written=171
Planning time: 0.042 ms
Execution time: 18000.344 ms
(6 rows)
Time: 18000.917 ms
postgres=# select 8*100000/18.000344;
?column?
44443.595077960732
(1 row)
```
cpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 1
Core(s) per socket: 32
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz
Stepping: 2
CPU MHz: 2494.224
BogoMIPS: 4988.44
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 30720K
NUMA node0 CPU(s): 0-31
祝大家玩得开心,欢迎随时来 阿里云促膝长谈 业务需求 ,恭候光临。
阿里云的小伙伴们加油,努力做 最贴地气的云数据库 。
PostgreSQL 许愿链接
您的愿望将传达给PG kernel hacker、数据库厂商等, 帮助提高数据库产品质量和功能, 说不定下一个PG版本就有您提出的功能点. 针对非常好的提议,奖励限量版PG文化衫、纪念品、贴纸、PG热门书籍等,奖品丰富,快来许愿。开不开森.
9.9元购买3个月阿里云RDS PostgreSQL实例
PostgreSQL 解决方案集合
德哥 / digoal's github - 公益是一辈子的事.

