




审视和修改表定义概述
在分布式框架下,数据分布在各个DN上。一个或者几个DN的数据存在一块物理存储设备上,好的表定义至少需要达到以下几个目标:
- 表数据均匀分布在各个DN上,以防止单个DN对应的存储设备空间不足造成集群有效容量下降。选择合适分布列,避免数据分布倾斜可以实现该点。
- 表Scan压力均匀分散在各个DN上,以避免单DN的Scan压力过大,形成Scan的单节点瓶颈。分布列不选择基表上等值filter中的列可以实现该点。
- 减少扫描数据数据量。通过分区的剪枝机制可以实现该点。
- 尽量极少随机IO。通过聚簇/局部聚簇可以实现该点。
- 尽量避免数据shuffle,减小网络压力。通过选择join-condition或者group by列为分布列可以最大程度的实现这点。
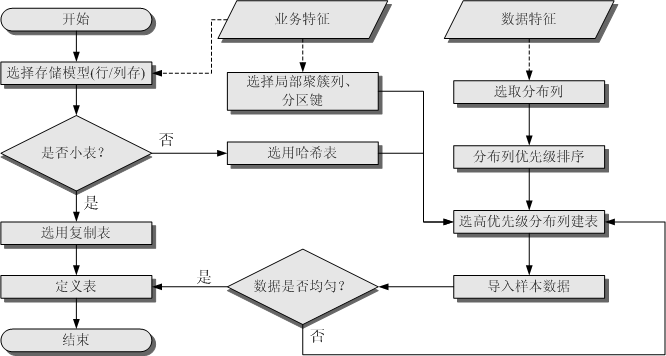
从上述描述来看表定义中最重要的一点是分布列的选择。创建表定义一般遵循图 1 表定义流程所示流程。表定义在数据库设计阶段创建,在SQL调优过程中进行审视和修改。
图1 表定义流程
查看更多:华为GaussDB 200 审视和修改表定义
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
