





在 12c 中,优化器进行了较大的改变,推出了 Adaptive query optimization,从整体上说,Adaptive query optimization 可以看作如下两部分:
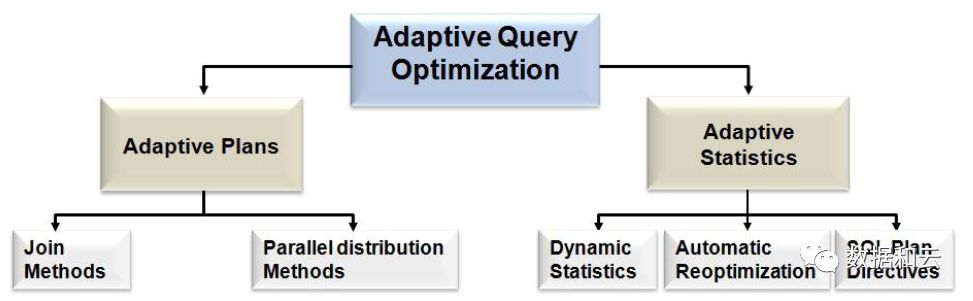
一部分是自适应执行计划,一部分是自适应统计信息。
这里注意一下,
• Adaptive Plans – 是在第一次执行的时候,从default plan变成adaptive plan。
• Automatic Re-optimization -是在第二次执行的时候
• Statistics Feedback 以前叫Cardinality Feedback
• Dynamic Statistics 以前叫Dynamic Sampling
• SQL Plan Directives(SPD) 到目前12.1为止,你可以认为是动态采样的持久化
好,我们今天讨论的主题是最后一项,SQL Plan Directives(SPD)。
我们来一起看看 SPD。在2013年6月oracle官方的白皮书『Oracle Database 12c 中的优化器』中,提到:
SPD是根据从自动重新优化获得的信息自动创建的。SQL 计划指令是优化器用于生成更优执行计划的附加信息。例如,当联接在其联接列中具有数据偏差的两个表时,SQL 计划指令可指导优化器使用动态统计获得更准确的联接基数估算。
所以,当 SQL 第一次运行时,oracle发现统计信息估计的值和实际执行过程中发现值差距较大(misestimate),需要重新优化,就会生成SPD。也就是说,如果我们看到v$sql的is_reoptimizable字段为Y,说明这个语句需要重新优化,在第二次执行的时候,或者类似sql执行的时候,SPD介入。在12.1中,SPD的唯一一个type,就是动态采样(Dynamic sampling)。
Oracle会在misestimate的情况下,让SPD介入。从目前收集到的信息看,如下基数不准,会让oracle认为misestimate。
• single table cardinality misestimate
• join cardinality misestimate
• query block cardinality misestimate
• group by cardinality misestimate
• having cardinality misestimate
我们来看这样一个例子。
1
我创建了一个表,并生成一些数据,收集统计信息
--初始化
conn test/test
drop table big_table;
create table big_table as
select 'iPhone' as product,
mod(rownum, 5) as channel_id,
mod(rownum, 1000) as cust_id
from dual
connect by level <= 2000000
UNION ALL
select 'Motorola' as product,
mod(rownum, 5) as channel_id,
mod(rownum, 1000) as cust_id
from dual
connect by level <= 10
UNION ALL
select 'Nokia' as product,
mod(rownum, 5) as channel_id,
mod(rownum, 1000) as cust_id
from dual
connect by level <= 20401
UNION ALL
select 'Samsung' as product,
mod(rownum, 5) as channel_id,
mod(rownum, 1000) as cust_id
from dual
connect by level <= 1000000;
exec dbms_stats.gather_table_stats(user,'BIG_TABLE',cascade=>true);
exit
2
删除所有已经存在的SPD,并且清空 shared pool;
sqlplus -S "/ as sysdba"
set pages 0
set line 10000
set echo off
set feedback off
set heading off
set trimspool on
spool drop_spd.sql
select 'exec dbms_spd.DROP_SQL_PLAN_DIRECTIVE('||''''||DIRECTIVE_ID||''''||');' from dba_sql_plan_directives;
spool off
exit
sqlplus "/as sysdba"
@drop_spd
alter system flush shared_pool;
3
第一次执行这个 sql
--TestTime 1:
conn test/test
set line 1000
set pages 1000
set termout off
select *+gather_plan_statistics*/
cust_id, channel_id, product
from big_table
where product = 'Motorola'
and channel_id = 1
order by product
/
select* from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));

我们看到,即使收集了统计信息,在执行过程中的 E-rows 和 A-rows 还是相去甚远。
我们检查 v$sql 的 is_reoptimizable 字段,可以看到是Y。
col DIRECTIVE_ID for 999999999999999999999
col OWNER for a10
col object_name for a10
col SUBOBJECT_NAME for a10
col sql_text for a90
col spd_text for a45
col internal_state for a30
select sql_id, child_number, sql_text, is_reoptimizable from v$sql where sql_text like '%+gather_plan_statistics%big_table%'
/

我们来看一下此时SPD的信息,我们用到了2个视图:dba_sql_plan_dir_objects和dba_sql_plan_directives。注意由于SPD是每隔15分钟才刷入数据字典中持久化,我们手工进行flush一次,就不用等15分钟,可以直接看了。
conn as sysdba
exec dbms_spd.FLUSH_SQL_PLAN_DIRECTIVE;
select aa.directive_id,aa.owner,aa.object_name,aa.subobject_name,aa.object_type,
state,
extract(bb.notes, '/spd_note/internal_state/text()' ) internal_state,
extract(bb.notes, '/spd_note/spd_text/text()' ) as spd_text,
bb.type,bb.reason from dba_sql_plan_dir_objects aa,dba_sql_plan_directives bb
where aa.directive_id=bb.directive_id and aa.object_name in ('BIG_TABLE')
order by 10,1
/

可以看到(点图放大),SPD针对的是对象级,是我的 table BIG_TABLE 和其字段PRODUCT和CHANNEL_ID。而当时用到的条件是: where product = ‘Motorola’ and channel_id = 1,通过实际执行,oracle认为这个表,和这2个字段的信息不准。
上图中的几个字段稍微解释一下:
a. SPD_TEXT是{EC(TEST.BIG_TABLE)[CHANNEL_ID, PRODUCT]}。Oracle认为你用来这2个字段进行查询,而这2个字段缺少联合统计信息。这里的E和C,以及可能出现其他的字符,解释如下:
E – equality_predicates_only
C – simple_column_predicates_only
J – index_access_by_join_predicates
F – filter_on_joining_object
举例来说,通常这样的条件会认为如下的信息misestimate:
from DEMO_TABLE where a=1 and b=1 and c=1 and d=1;
• {EC(DEMO.DEMO_TABLE)[A, B, C, D]}
• missing_stats, has_stats with extended statisticsfrom DEMO_TABLE where a+b=c+d;
• {E(DEMO.DEMO_TABLE)[A, B, C, D]}
• missing_stats, permanent as no statistics can helpfrom DEMO1 join DEMO2 using(KEY) where DEMO2.a=1;
• {(DEMO.DEMO1) – F(DEMO.DEMO2)}
b. INTERNAL_STATE 是NEW,表示是第一次,我们一会可以看看第二次执行的时候,会是如何。
NEW – 1st pass
MISSING_STATS – needs extended stats(gathered automagically)
HAS_STATS – extended stats have now been gathered(Intermediate State – new statements may still need SPD’s)
PERMANENT – extended stats have now been gathered(but SPD still needed because of != predicates)
c. TYPE是DYNAMIC_SAMPLING,表示下次执行时,如果此SPD介入,会执行动态采样。
d. REASON表示为什么oracle会认为这个语句需要SPD介入。因为oracle认为SINGLE TABLE CARDINALITY MISESTIMATE。
这个字段的值有:
• single table cardinality misestimate
• join cardinality misestimate
• query block cardinality misestimate
• group by cardinality misestimate
• having cardinality misestimate
这个字段要结合extract之后的notes,也就是上面的SPD_TEXT一起看。
好,我们再来看看,此时有没有动态采样介入。我们看看v$sql中,是否有DS_SVC hint的sql:
select sql_text from v$sql where sql_text like '%DS_SVC%'
/

我们看到,此时没有动态采样的介入。
4
我们再来继续测试,同样的 SQL 语句,第二次执行的情况:

我们看到此时的 E-rows 已经和 A-rows 一样,也就是说,此时再次执行,cursor 还在缓存的时候,直接使用statistics feedback,生成 child number 为1的 cursor。注意,此时动态采样也还是没介入的。

5
如果我们 flush shared pool,我们来看看是什么情况:
conn as sysdba
alter system flush shared_pool;
--TestTime 1:
conn test/test
set line 1000
set pages 1000
set termout off
select *+gather_plan_statistics*/
cust_id, channel_id, product
from big_table
where product = 'Motorola'
and channel_id = 1
order by product
/
select* from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
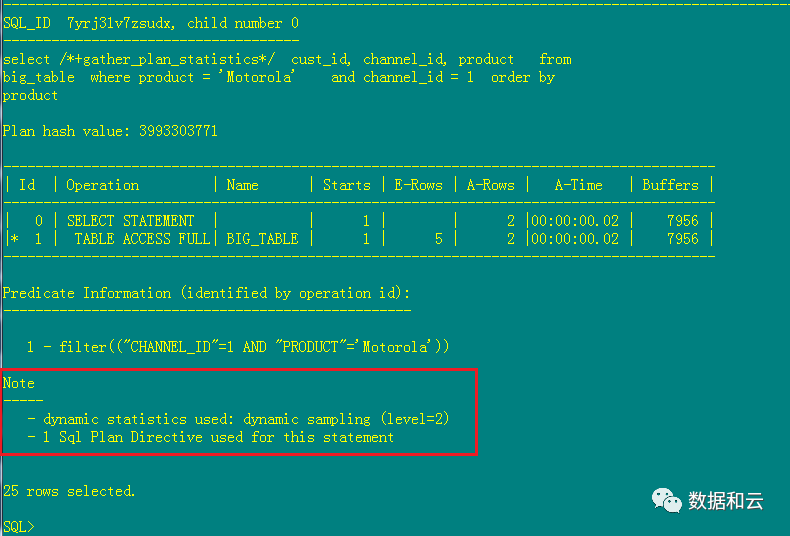
我们看到,当同一个SQL,发生硬解析的时候,SPD介入,执行动态采样。
我们再来看看是否在v$sql中有了动态采样的信息:
可以看到已经有很多关于 DS_SVC 的动态采样的语句了。
注意,此处的动态采样,不是ADS(Automatic Dynamic Statistics)引起的,是SPD引起的。所以说,12c的动态采样比11g要多的多,很大程度上,是SPD引起的。
11g的表如果收集的统计信息,就不再会动态采样。而 12c 中,即使表收集了统计信息,还是会被 SPD 触发,进行动态采样。
我们再来看看SPD中的信息:
注意这里的Internal状态从NEW已经变成了MISSING_STATS。
到这里,你可能已经意识到了SPD会造成比11g多的动态采样,但是,是否只是影响同一个sql?
之前说过,SPD是针对对象级的,不是SQL级的,所以,当我有一个类似的sql触发时,第一次硬解析的时候,SPD也会介入。
6
我再运行一个“类似” SQL:
--TestTime 2:
conn test/test
set line 1000
set pages 1000
set termout off
select *+gather_plan_statistics*/
cust_id, channel_id, product
from big_table
where product = 'Nokia'
and channel_id = 1
order by product;
select* from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));

可以看到,也触发了SPD,SPD指导优化器再次进行动态采样。
而由于在第一次跑的时候,进行了动态采样,且E-rows和A-rows之间差距小,Oracle认为它不需要is_reoptimizable: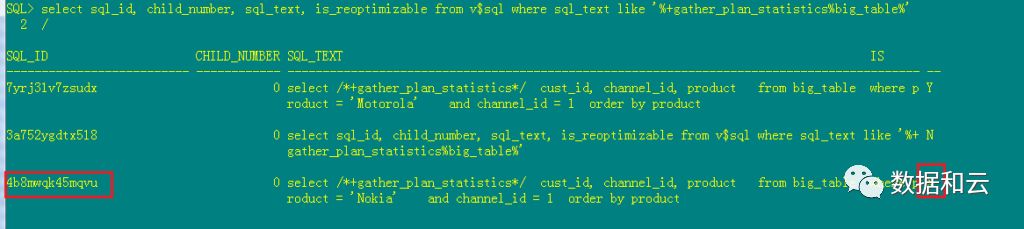
7
再运行另一个“类似” sql:
--TestTime 3:
conn test/test
set line 1000
set pages 1000
set termout off
select *+gather_plan_statistics*/
cust_id, channel_id, product
from big_table
where product = 'iPhone'
and channel_id = 4
order by product;
select* from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
也是同样道理,SPD介入,执行动态采样,但是is_reoptimizable是N.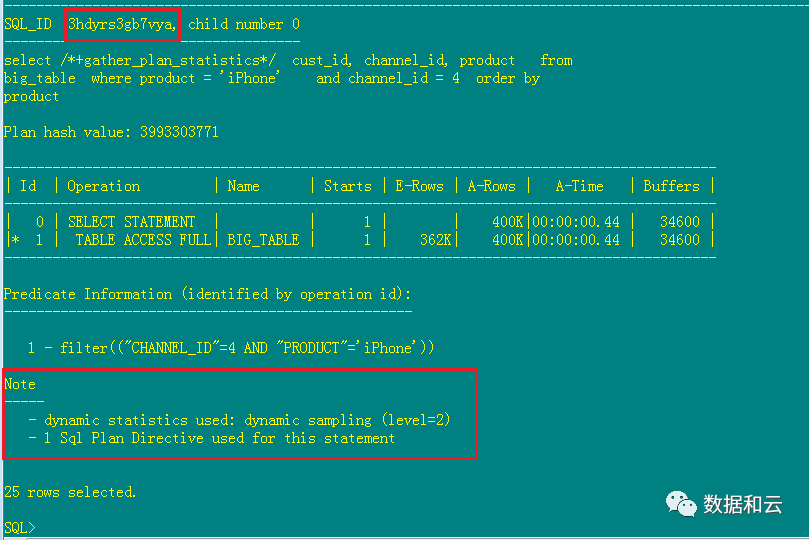

但是,此时的DS_SVC,由于这些“类似”SQL的动态采样,在v$sql中渐渐变多了。
注:“类似”,是指语句中也有where product = ‘Motorola’ and channel_id = 1的语句。只要是这样的语句,SPD都会介入。
我只是跑了4个,就已经出现了15个动态采样的递归sql,在生产环境中,会更严重一些,如v$sql中总共9万多个sql,其中7万多个是这样的带DS_SVC的sql。
而由于12c中每次动态采样都需要被result cache,此时就会出现Result cache的latch争用。见Document 2002089.1High Latch Free Waits on ‘Result Cache: RC Latch’ In 12C when RESULT_CACHE_MODE = MANUAL
从上面的测试可以看出,SPD的介入应该是比较靠前的,当同一个语句再次执行的时候,如果已经缓存,就采用Statistics Feedback,如果没缓存,在hard parse之初就介入了SPD,如果SPD的信息还是missing,要求动态采样,则在后面的执行的时候,都走了动态采样;如果SPD中missing的信息已经被收集,则SPD就从USABLE更新成SUPERSEDED,此时就不走动态采样;
另外,当“类似”语句进入的时候,也是同样道理。
用流程图表示,基本就是下面这个图的绿框部分:(整个图是Adaptive query optimization)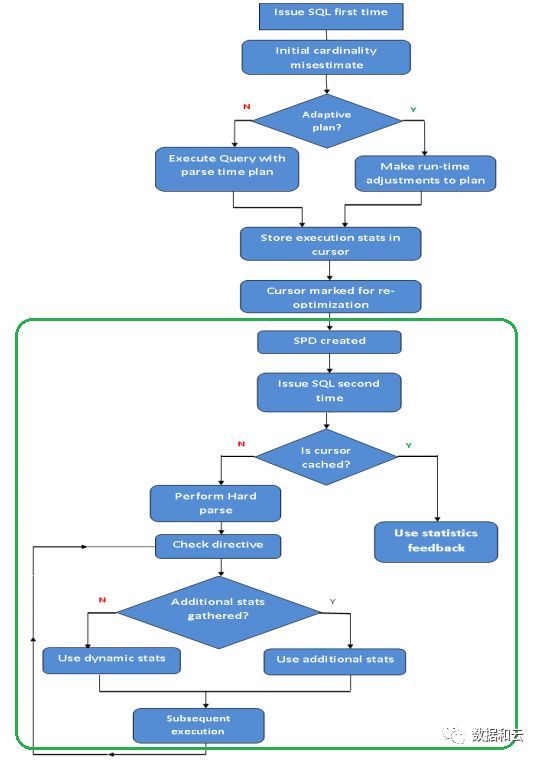
那么,什么样的情况,才会让SPD认为信息已经收集齐了,STATE列从USABLE变成SUPERSEDED,INTERNAL_STATE列从MISSING_STATS变成HAS_STATS。从我的测试看,条件非常严格。不仅仅要收集所有列的直方图,还要收集(CHANNEL_ID, PRODUCT)的extended stats.收集完之后,再次硬解析的时候,才会不走动态采样。
select
dbms_stats.create_extended_stats
('TEST', 'BIG_TABLE', '(CHANNEL_ID,PRODUCT)')
from dual;
EXEC DBMS_STATS.gather_table_stats('TEST', 'BIG_TABLE', method_opt => 'for all columns size 254');
select TABLE_NAME,COLUMN_NAME,HISTOGRAM from dba_tab_col_statistics where table_name='BIG_TABLE';
alter system flush shared_pool;
--TestTime 2:
conn test/test
set line 1000
set pages 1000
set termout off
select /*+gather_plan_statistics*/
cust_id, channel_id, product
from big_table
where product = 'Nokia'
and channel_id = 1
order by product;
 检查SPD的状态,可以看到变成如下了:
检查SPD的状态,可以看到变成如下了:

此时,动态采样不再进行。(由于收集了非常精确的统计信息,E-rows完全等于A-rows)
那么既然SPD这么容易造成动态采样,且动态采样容易有Result cache的latch(可以通过修改_optimizer_ads_use_result_cache=false来让动态采样不进result cache),且即使关闭了result cache的动态采样,还是容易在v$sql中积累大量DS_SVC的hint的递归sql,消耗shared pool,我们如何来解决由SPD引起的动态采样呢?
>>>解决方案<<<
1. 禁用Adaptive query optimization。OPTIMIZER_ADAPTIVE_FEATURES = FALSE,这是最大的总开关。
2. 禁用SPD产生新的directive:_sql_plan_directive_mgmt_control = 0(注意还要将原来已经存在的directive改成disable或者drop)
3. 禁用SPD的动态采样:_optimizer_dsdir_usage_control = 0
>>>参考文献<<<
Doc ID 2002089.1 High Latch Free Waits on 'Result Cache: RC Latch' In 12C
Doc ID 2031605.1 Adaptive Query Optimization
Doc ID 2002108.1 Dynamic Sampling Level Is Changed Automatically in 12C
Doc ID 2033658.1 Dictionary Queries Running Slow in 12C PDBs
Doc ID 2097793.1 [INTERNAL]Commonly Reported Known Issues for Database
作者:何剑敏
投稿:有投稿、寻求报道意向技术人请联络 wenmin.yin@enmotech.com
更多精彩请关注 “数据和云” 微信

