




一. 前言
TiKV 是负责整套分布式数据库存储工作的,TiKV 其实并没有直接向磁盘上写数据,而是把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责。
RocksDB 简介
RocksDB 是由 Facebook 基于 LevelDB 开发的一款提供键值存储与读写功能的 LSM-tree 架构引擎。用户写入的键值对会先写入磁盘上的 WAL (Write Ahead Log),然后再写入内存中的跳表(SkipList,这部分结构又被称作 MemTable)。
LSM-tree 引擎由于将用户的随机修改(插入)转化为了对 WAL 文件的顺序写,因此具有比 B 树类存储引擎更高的写吞吐。
内存中的数据达到一定阈值后,会刷到磁盘上生成 SST 文件 (Sorted String Table),SST 又分为多层(默认至多 6 层),每一层的数据达到一定阈值后会挑选一部分 SST 合并到下一层。
通过 TiKV 架构图加深下了解:
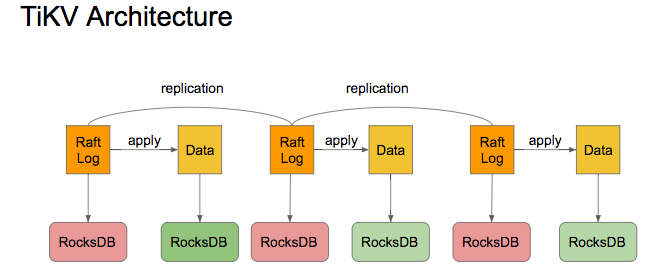
我们的需求
我们生产数据库有部分表设计的非常不合理,字段类型为 vachar(2000),vachar(1000) 等等超大的字段。如果把这部分数据迁入 TiDB 中,转成 KV 的存储形式,会严重影响 TiKV 的使用。
二. Titan 引擎
1. Titan 简介
USENIX FAST 在几年前发布表一篇论文,是关于一种高度基于 SSD 优化的设计,利用 SSD 高效的随机读写性能,通过将 value 分离出 LSM-tree 的方法来达到降低写放大的目的。
https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf
PingCAP 基于该论文,研发了一个基于 RocksDB 的高性能单机 key-value 存储引擎,命名为 Titan。
2. Titan 的目标
Titan 是属于 TiKV 的子项目,首先必须兼容 RocksDB,也要能让用户平滑地把基于 RocksDB 的 TiKV 升级至基于 Titan 的 TiKV。总结一下 Titan 的设计目的:
支持将 value 从 LSM-tree 中分离出来单独存储,以降低写放大。
已有 RocksDB 实例可以平滑地升级到 Titan,这意味着升级过程不需要人工干预,并且不会影响线上服务。
100% 兼容目前 TiKV 所使用的所有 RocksDB 的特性。
尽量减少对 RocksDB 的侵入性改动,保证 Titan 更加容易升级到新版本的 RocksDB。
3. Titan 架构
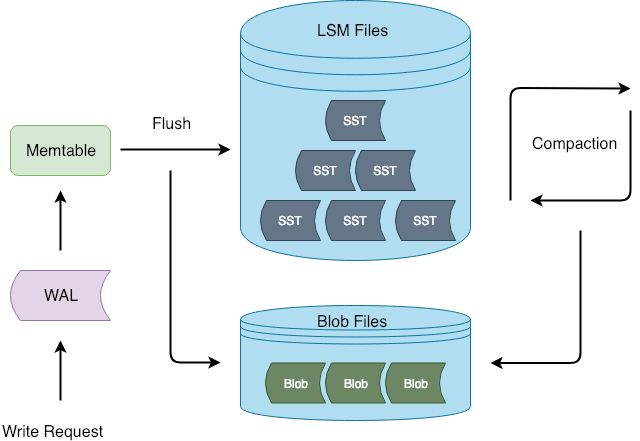
Titan 在 Flush 和 Compaction 的时候将 value 分离出 LSM-tree,这样写入流程可以和 RocksDB 保持一致,减少对 RocksDB 的侵入性改动。
4. Titan 实现
Titan 主要是通过以下几个组件去实现的,BlobFile、TitanTableBuilder 和 GC。
BlobFile
BlobFile 是用来存放从 LSM-tree 中分离出来的 value 的文件.
BlobFile 特点总结:
BlobFile 中的 key-value 是有序存放的,目的是在实现 iterator 的时候可以通过 prefetch 的方式提高顺序读取的性能。
每个 blob record 都保留了 value 对应的 user key 的拷贝,这样做的目的是在进行 GC 的时候,可以通过查询 user key 是否更新来确定对应 value 是否已经过期,但同时也带来了一定的写放大。
TianTableBuilder
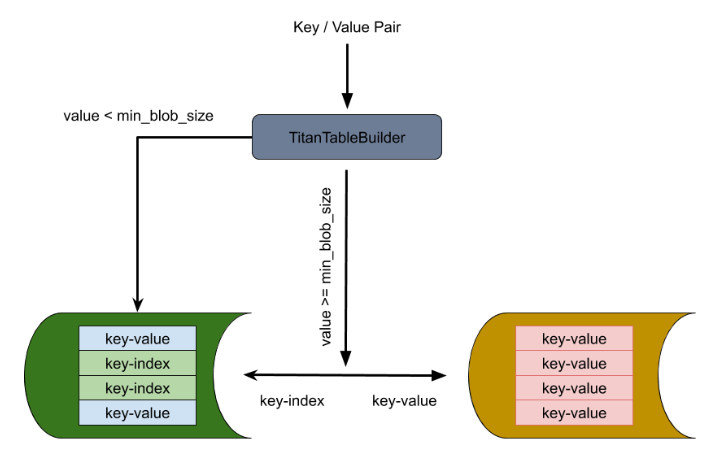
TitanTableBuilder 是实现分离 key-value 的关键,它通过判断 value size 的大小来决定是否将 value 分离到 BlobFile 中去。如果 value size 大于等于 min_blob_size 则将 value 分离到 BlobFile,并生成 index 写入 SST;如果 value size 小于 min_blob_size 则将 value 直接写入 SST。
该流程还支持将 Titan 降级回 RocksDB。在 RocksDB 做 compaction 的时候,将分离出来的 value 重新写回新生成的 SST 文件中。
GC
由于在 LSM-tree compaction 进行回收 key 时,储存在 blob 文件中的 value 并不会一同被删除,因此需要 GC 定期来将已经作废的 value 删除掉。在 Titan 中有两种 GC 方式可供选择:
定期整合重写 Blob 文件将作废的 value 剔除(传统 GC)
在 LSM-tree compaction 的时候同时进行 blob 文件的重写(Level-Merge)
三. Titan 的使用
适用场景
适用场景:
前台写入量较大,RocksDB 大量触发 compaction 消耗大量 I/O 带宽或者 CPU 资源,造成 TiKV 前台读写性能较差。
前台写入量较大,由于 I/O 带宽瓶颈或 CPU 瓶颈的限制,RocksDB compaction 进度落后较多频繁造成 write stall。
前台写入量较大,RocksDB 大量触发 compaction 造成 I/O 写入量较大,影响 SSD 盘的寿命。
使用限制
使用限制:
Value 较大。即 value 平均大小比较大,或者数据中大 value 的数据总大小占比比较大。目前 Titan 默认 1KB 以上大小的 value 是大 value,根据实际情况 512B 以上大小的 value 也可以看作是大 value。注:由于 TiKV Raft 层的限制,写入 TiKV 的 value 大小还是无法超过 8MB 的限制,可通过 raft-entry-max-size 配置项调整该限制。
没有范围查询或者对范围查询性能不敏感。Titan 存储数据的顺序性较差,所以相比 RocksDB 范围查询的性能较差,尤其是大范围查询。在测试中 Titan 范围查询性能相比 RocksDB 下降 40% 到数倍不等。
磁盘剩余空间足够。Titan 降低写放大是通过牺牲空间放大达到的。另外由于 Titan 逐个压缩 value,压缩率比 RocksDB(逐个压缩 block)要差。这两个因素一起造成 Titan 占用磁盘空间比 RocksDB 要多,这是正常现象。根据实际情况和不同的配置,Titan 磁盘空间占用可能会比 RocksDB 多一倍。
如何开启
Titan 在 TiKV 中是默认关闭的,通过 TiKV 的配置文件来决定是否开启和设置 Titan,相关的配置项包括 [rocksdb.titan] 和 [rocksdb.defaultcf.titan]:
[rocksdb.titan]
enabled = true
一旦开启 Titan 就不能回退回 RocksDB 了。
四. 总结
Titan 在个别场景下,比如对大 value 的支持,确实能带来很多帮助,但也会带来比如范围查询性能下降的问题。开与不开,还需要根据实际业务情况确定。压测期间可以额外做下关于 Titan 的测试,了解下 Titan 与现有业务场景的契合度。
