




接下来的数据加密项目,会有很对刷大表数据的操作,届时可能会出现10G+的binlog(单条update刷整表的方式),会对服务器性能包括主从复制产生影响。在写应对方式前,还是先简单总结下 mysql binlog 的作用及特性。
binlog介绍
binlog简介
binlog 是mysql中的归档日志,是属于Server层的日志。binlog会记录数据库内的 DDL 和 DML 操作,因为记录了详细操作,所以它主要有以下两个特性:
mysql主从复制:原生的主从复制就是基于binlog去实现的;
数据恢复:若有误操作或者想找回数据,就可以去binlog里找出相对应的sql语句;
binlog与redo log的区别
两者都是log,概念很容易混淆,这里也简单说下两者区别。
redo log 存在于存储引擎层,binlog 则服务于server层。
redo log 重做日志
如果有一条更新sql,innodb引擎先把它写到 redo log 中,并更新内存。之后在固定时间或者资源空闲时间把记录更新到磁盘。
redo log 在mysql中的体现就是 ib_logfileX 文件,一般开启3-4个。
redo log可以保证数据库发生crash重启后,之前提交的数据不丢失,称之为crash-safe
binlog 归档日志
数据库间的同步都是基于 binlog 的,而且一些操作分析,也是通过 binlog 去处理的。
redo log 和 binglog 的不同点
redo log 是innodb引擎特有的;binlog是基于 server 层的,任何存储引擎都可以使用;
redo log 是物理日志,记录的是在数据页上做的修改;binlog是逻辑日志,记录语句的原始逻辑;
redo log 是循环写的,固定空间可能用完;binlog 是追加写入的,一个文件到达上限后,会切换到下个文件;
binlog 如何开启
需要在cnf文件里显示配置 log-bin=mysql-bin:
vim etc/my.cnf
log-bin=mysql-bin
binlog_format=row
binlog 的三种模式
一般有ROW、STATEMENT、MIXED三种复制模式
ROW 模式(我们所使用的)
不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。
优点:不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题
缺点:缺点是会产生大量的日志,尤其是alter table的时候会让日志暴涨
STATEMENT 模式
每一条会修改数据的sql语句会记录到binlog中
优点:并不需要记录每一条sql语句和每一行的数据变化,减少了binlog日志量,节约IO,提高性能
某些情况下会导致master-slave中的数据不一致(如sleep()函数, last_insert_id(),以及user-defined functions(udf)等会出现问题)
MIXED 模式
两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式
binlog 超过设置上限的情况
这数据库中,我们设置的 binlog 最大文件大小为1G:
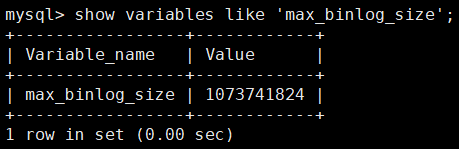
但是在实际环境中,出现了超过1G的情况:
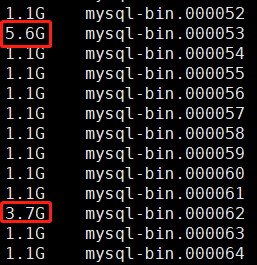
其实原因很简单,binlog 是在整个事务执行完后切触发切换日志的,这里截下八怪的提交流程图:
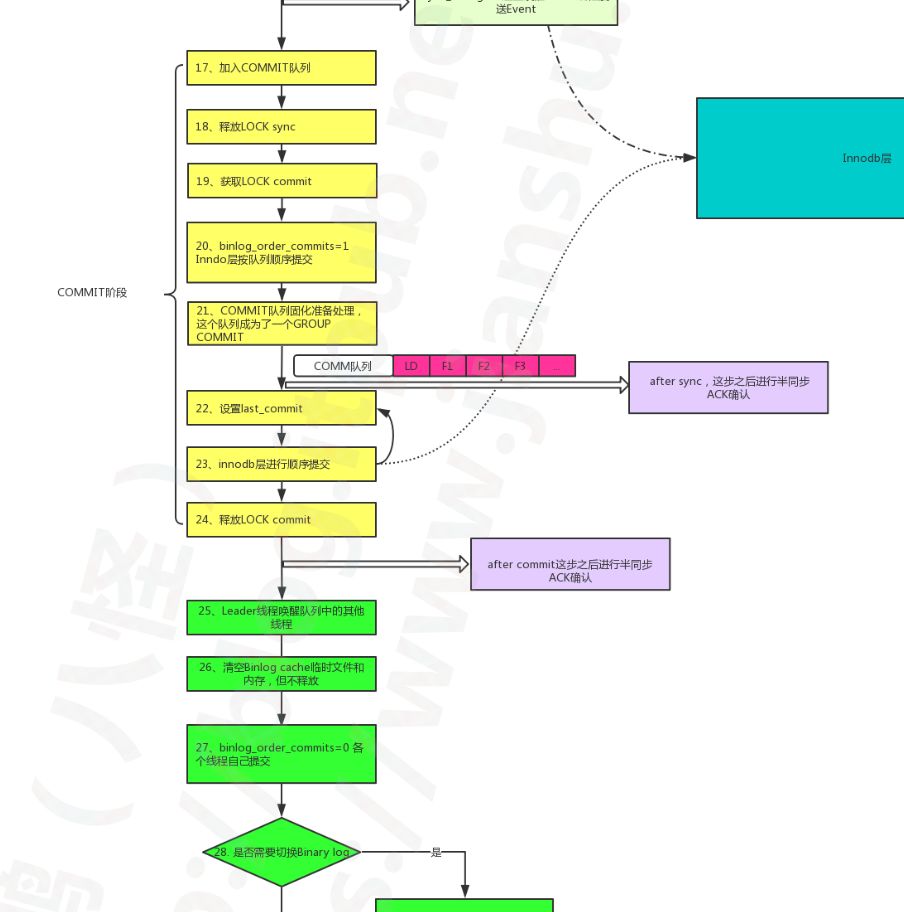
第28步是切换binlog,但是在这个节点,之前的事务都需要已提交。假如有条sql,要更新全表的数据,数据量1亿,数据文件大小2G,因为我们binlog是row模式的,所以这条sql所产生的binlog日志大小会远远超过2G。
binlog 过大会产生的问题
1. 写 binlog 造成机器性能的下降
当大事物提交后,数据库开始调用磁盘io去写binlog。假如服务器原本的 IOPS 就不是很高,写 binlog 时会进一步影响 io 性能,这时候数据库的写性能也会受到影响,严重点的话增删改的 sql 都会堵塞。
2. 主从同步中断报错
ERROR 1197 (HY000) at line 4: Multi-statement transaction required more than 'max_binlog_cache_size' bytes of storage; increase this mysqld variable and try again
在刷表动作结束后,从库报了主从中断,然后抛出了上面这个 error,字面意思就是 max_binlog_cache_size 参数设置的太小了。
这个 error 是由 _my_b_write 函数判断的:
{ "ER_TRANS_CACHE_FULL", 1197, "Multi-statement transaction required more than \'max_binlog_cache_size\' bytes of storage; increase this mysqld variable and try again" },
函数 _my_b_write 的代码:
if (pos_in_file+info->buffer_length > info->end_of_file) 判断binlog临时文件的位置加上本次需要写盘的数据大于info->end_of_file的大小则抛错
{
errno=EFBIG;
set_my_errno(EFBIG);
return info->error = -1;
}
抛错的代码在 MYSQL_BIN_LOG::check_write_error 函数中:
if (is_transactional)
{
my_message(ER_TRANS_CACHE_FULL, ER(ER_TRANS_CACHE_FULL), MYF(MY_WME));
}
遇到这个错也比较好解决,临时调整下 max_binlog_cache_size 即可:
mysql> set global max_binlog_cache_size=2068435456;
Query OK, 0 rows affected (0.05 sec)
再打开主从就能看到,从库可以正常去应用这个大的 binlog 文件了。
binlog 另两个问题分析
binlog 的基本概念都在上面了,接下来有两个有关比较特殊的 binlog 问题。
最后事务是小事务而不是最大的那个事务,为什么大事务束后没有切换binlog?
最后一个小事务和大事务提交时间相差了好几十分钟呢?
问题1
上面的流程图,在第10步其实只是设置了切换标记而已,实际的切换会等到本事务所在的commit队列都提交完成后才会进行binlog的切换。
这个过程中会有以下两个原因导致大事务并不是binlog的最后一个事务:
对于flush队列而言,大事务可能包含在队列中的某个位置,队列后面可能包含小事务;
对于sync队列而言,大事务的提交会在sync阶段耗费很多时间,假设为30秒,那么在这30秒内其他新的事务是可以进入新的flush队列的,也能够进行写binlog(不是fsync)的操作;
因此线上有压力的库,binlog的最后一个事务通常不是大事务。
问题2
有两种情况可能造成最后一个小事务和大事务之间时间差了好几十分钟:
对于自动事务提交,那么XID_EVENT会是命令发起的时间;
XID_EVENT:当事务提交时,不论是statement还是row格式的binlog都会添加一个XID_EVENT作为事务的结束,该事件记录了该事务的ID
还有种就是,对于显示开启事务‘begin commit’,那么XID_EVENT会是commit命令发起的时间,但是如果fsync时间足够久那么也会出现这种问题;
| A | B | 时刻 |
|---|---|---|
| 大事物flush | T1 | |
| 大事物sync | 小事物flush | T2 |
| 小事物flush | T3 | |
| 小事物flush | T4 | |
| 大事物sync结束 | T5 |
如果T5和T2之间相差几十分钟分钟,那么这期间进来的这些小事务依然保留在本binlog里面(因为还没切换29步才切换),那么就有可能看到小事务和大事务之间XID_EVENT(commit)时间相差很大了。
