




PostGIS中使用空间索引来快速搜索空间中的对象。实际上,这意味着非常快速地回答以下形式的问题:
- “这里面的所有东西”或
- “这件东西附近的所有东西”
由于空间对象通常非常大且复杂(例如,海岸线通常由数千个点定义),因此空间索引使用“边界框”作为索引和搜索键:
- 边界框很小,固定大小,2D 框只有 4 个浮点数;和,
- 与测试诸如遏制之类的东西相比,边界框非常便宜。
所以空间索引的简单故事是:如果您计划进行空间查询(如果您正在存储空间对象,您可能会这样做),您应该为您的表创建一个空间索引。
创建空间索引非常简单:
CREATE INDEX mytable_geom_x ON mytable USING GIST (geom);
这将在几何列上创建一个 GIST 索引,使用几何的默认“运算符类”。故事结局?差远了。
这么多索引
仅对于PostGIS 几何类型,实际上就有10 个不同的运算符类!
SELECT opcname, amname
FROM pg_opclass oc
JOIN pg_am am ON (am.oid = oc.opcmethod)
JOIN pg_type typ ON (oc.opcintype = typ.oid)
WHERE typ.typname = 'geometry';
opcname | amname
--------------------------------+--------
btree_geometry_ops | btree
hash_geometry_ops | hash
gist_geometry_ops_2d | gist
gist_geometry_ops_nd | gist
brin_geometry_inclusion_ops_2d | brin
brin_geometry_inclusion_ops_3d | brin
brin_geometry_inclusion_ops_4d | brin
spgist_geometry_ops_2d | spgist
spgist_geometry_ops_3d | spgist
spgist_geometry_ops_nd | spgist
前两个运算符类,“btree”和“hash”索引,可以安全地忽略。最终用户无需创建这些索引,它们的存在只是为了启用某些核心数据库功能。
- 对于在查询中支持“ORDER BY”的任何类型,PostgreSQL 需要一个btree运算符类,并且几何类型是 sortable。
- 对于在查询中支持“DISTINCT”的任何类型,PostgreSQL 都需要一个哈希运算符类,就像几何一样。
其余索引都支持空间索引的核心特征:查找查询空间对象的边界框所包含的所有空间对象。
正如我们在列表中看到的,实现在用于提供功能(GIST、SPGIST 和 BRIN)的底层数据库访问方法和进行搜索的维度空间(2D、3D、4D)方面有所不同。
GIST vs SPGIST vs BRIN
GIST 访问方法是用于构建索引的通用 API ——“通用搜索树”是首字母缩略词所代表的意思 —— 用于几何类型的索引方案实现了R 树结构。R-Tree 支持范围广泛的不同空间用例和数据模式。高度重叠的数据,以及布局规则的数据。具有广泛可变空间范围的数据以及具有统一大小的数据。
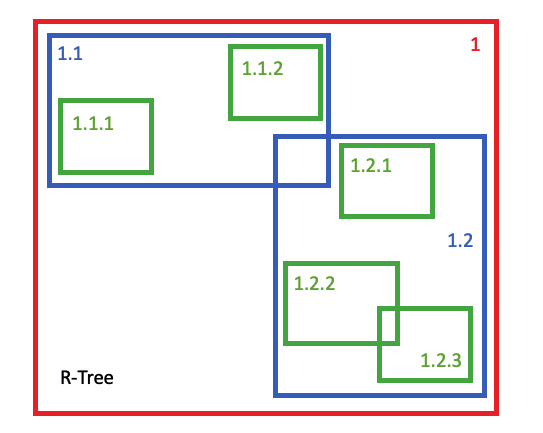
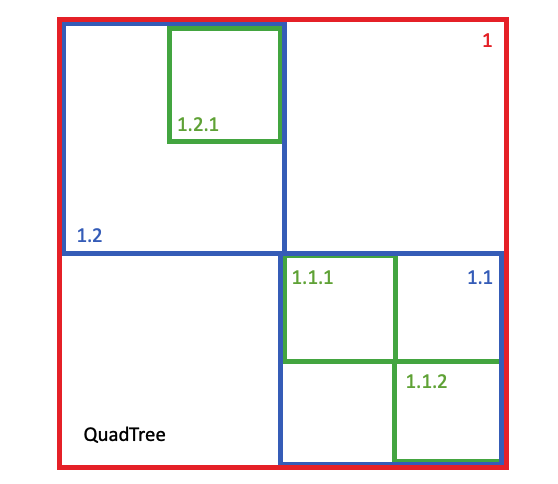
SP-GIST 访问方法也是一种通用方案,但专门针对“空间分区”进行了调整。也就是说,可以将索引节点拆分为两个完全不重叠的域的方案。用于几何类型的方案是四叉树的变体,在每次拆分时将每个节点划分为四个不重叠的子节点。
BRIN 访问方法(“块范围索引”)在完全不同的假设下运行。列的 BRIN 索引存储该列涵盖的每个数据库页面的范围。BRIN 索引是一个范围列表,将搜索空间的值映射到数据库表中的数据页。
结果是一个非常小的 BRIN 索引,即使对于非常大的表也是如此。但是,索引的有效性与数据的基本排序成正比。一个充满流时间戳数据的表,其中写入了新值但没有删除任何内容,将是时间戳列上 BRIN 索引的绝佳候选者,因为数据将按时间整齐排序。
在空间域中,按几何对数据进行预排序可以为 BRIN 生成一个非常“可搜索”的数据集,这就是我们在这篇文章中比较 BRIN 性能时对数据所做的。
比较索引构建
为了提供一些非常基本的性能比较,我们将查看 1M 随机点的测试数据集。
CREATE TABLE points AS
SELECT ST_MakePoint(
1000*random(),
1000*random(),
1000*random())::geometry(PointZ) AS geom,
pk
FROM generate_series(1,1000000) pk;
ALTER TABLE points ADD PRIMARY KEY (pk);

要为 BRIN 测试生成数据,我们将做同样的事情,但添加一个“ORDER BY geom”子句以按位置对数据进行预排序。
现在我们可以使用每种类型构建索引,并检查构建时间和大小。
Build Size GIST 15.0s 53 MB SPGIST 5.6s 44 MB BRIN 0.4s 24 KB
构建时间和索引大小的一些实质性差异!正如预期的那样,BRIN 索引构建速度快且非常小,但正如我们稍后将看到的那样,这是有代价的。与 SPGIST 相比,更通用的 GIST 索引在构建时间和大小方面都会受到惩罚。
比较查询时间
为了比较查询时间,我们使用了一个查询,该查询在数据区域上构建 1000 个随机框,然后使用空间索引运算符“&&”将这些框连接到数据表。
WITH xy AS (
SELECT 1000*random() AS x, 1000*random() AS y
FROM generate_series(1, 1000)),
boxes AS (
SELECT ST_MakeEnvelope(x-5, y-5, x+5, y+5) AS geom
FROM xy
)
SELECT Count(*)
FROM points, boxes
WHERE points.geom && boxes.geom;
通过对这个查询进行计时,我们可以了解索引性能,同时最大限度地减少查询启动开销对结果的影响。
Time GIST 230ms SPGIST 150ms BRIN 21810ms
在这里,我们看到了 BRIN 指数的下行空间。每次查询运行涉及 1000 次 box-vs-data 索引调用,因此 GIST 和 SPGIST 索引的平均每次调用远低于1ms。
另一方面,BRIN每次调用的平均时间约为 20毫秒。如果您只需要拨打一个电话,那么对于您的用例来说就足够了。然而,它指出了 BRIN 索引的特殊用途性质:对于大表,数据按与查询结构匹配的顺序顺序放置。
SPGIST 赢了?
到目前为止,新的 SPGIST 索引似乎超过了旧的 GIST 基础设施,但重要的是要记住 SPGIST 最强的地方:数据不重叠的地方,以及数据可以完美地划分为空间的地方。我们的统一随机点表是 SPGIST 表现优异的完美数据。
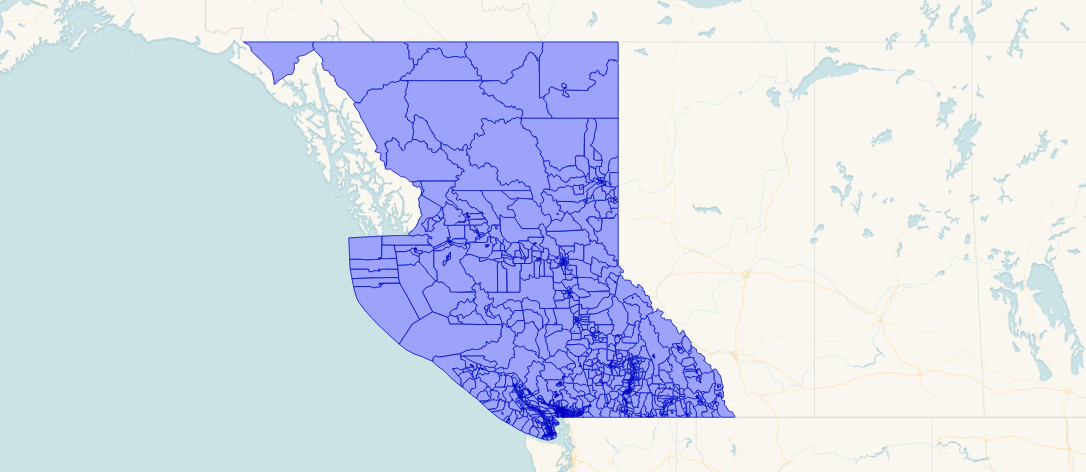
更公平的测试可能会使用更多真实世界的数据。这是不列颠哥伦比亚省 9349 个多边形的表格。它们不重叠(对 SPGIST 来说非常好)但大小不均匀。
仅测试 GIST 和 SPGIST,使用另一个包含 10,000 个框的随机框查询,我们得到以下结果:
Time GIST 270ms SPGIST 375ms
一般来说,当数据有很多重叠时,GIST 会优于 SPGIST。当重叠较少时,SPGIST 将优于 GIST。
从视觉上看,使用这种具有高度叠加的随机大小圆圈的合成数据集,GIST 的速度提高了约 5-15%。
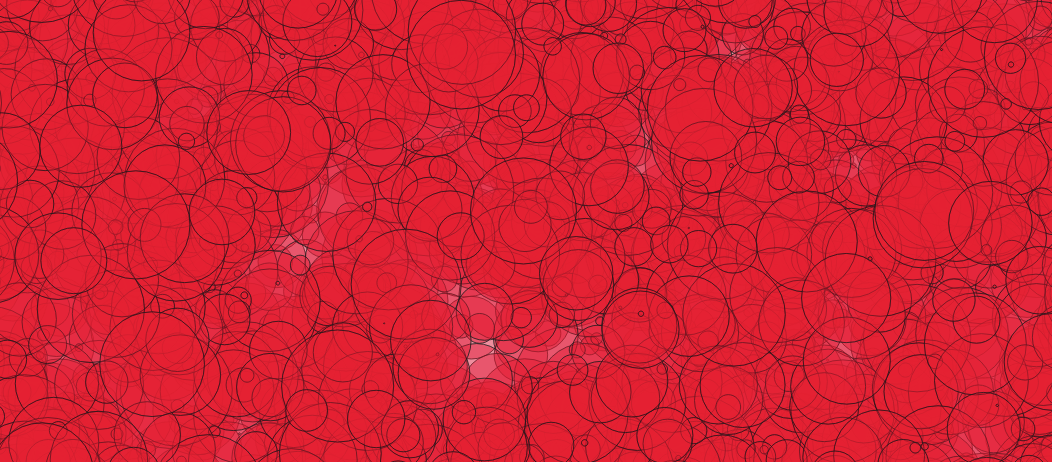
在使用这个由重叠较少的随机大小圆组成的合成数据集时,SPGIST 的速度提高了约 5-15%。
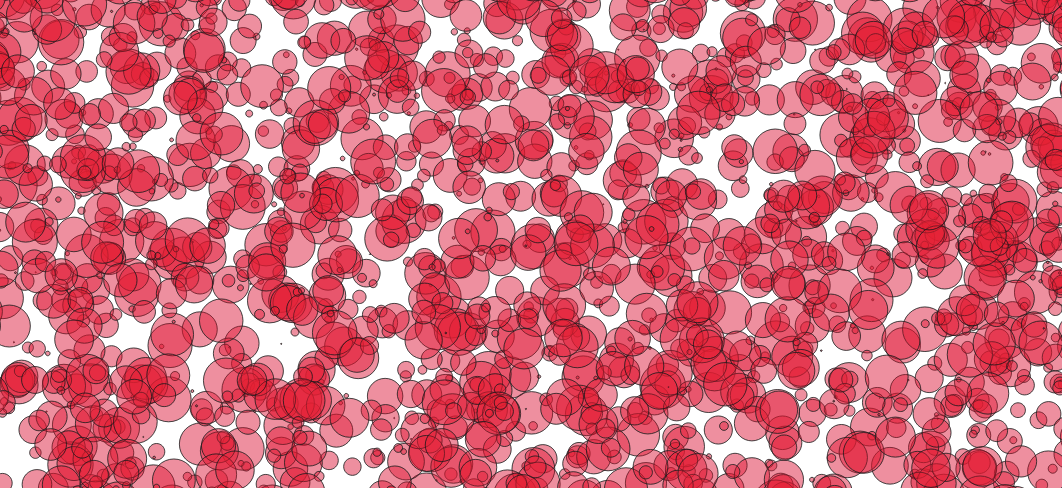
结论
- 空间数据需要一个空间索引!
- 不要忽视在久经考验的 GIST 上使用较新的 SPGIST 实现的可能性,特别是如果数据相对统一并且没有很多重叠。
- 仅当数据表很大并且以高度空间相关的顺序存储时才考虑 BRIN。
原文地址:https://blog.crunchydata.com/blog/the-many-spatial-indexes-of-postgis?xzs
