




本节我们先会提供两种解决方法,然后介绍hadoop集群Yarn的capacity-scheduler容量调度器机制,其实这块属于Yarn内容。
一、增加ApplicationMaster资源比例
[qiusheng@node01 hadoop]$ vim capacity-scheduler.xml
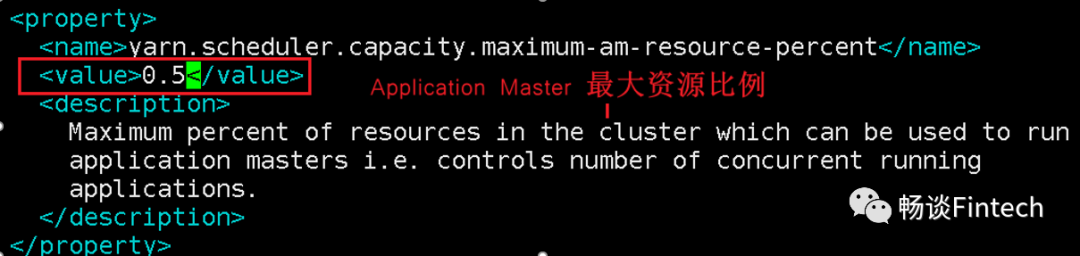
2、分发capacity-scheduler.xml配置文件
[qiusheng@node01 hadoop]$ xsync__nodes.sh capacity-scheduler.xml
# 2021-04-26# authored by qiusheng# function: any path to xsync all nodes#!/bin/bash# 1.判断传入的参数的个数if [ $# -lt 1 ]thenecho Not enough params!exit;fi# 2.遍历循环所有节点nodefor hostnode in node01 node02 node03doecho =============== $hostnode ===============#3.循环遍历所有目录,挨个发送for file in $@do#4.判断文件是否存在if [ -e $file ]then#5.获取父目录pdir=$(cd -P $(dirname $file);pwd)#6.获取当前文件的名称fname=$(basename $file)#7.创建文件夹即使有文件ssh $hostnode "mkdir -p $pdir"rsync -av $pdir/$fname $hostnode:$pdirelseecho $file does not exists!fidonedone
3、重新启动yarn集群
sbin/stop-yarn.shsbin/start-yarn.sh
二、增加Yarn容量调度器多队列
按照计算引擎创建队列:hive、spark、flink 按照业务创建队列:下单、支付、点赞、评论、收藏等
3、修改容量调度器配置文件
默认在Yarn的配置下,容量调度器只有一条default队列。在capacity-scheduler.xml中可以配置多条队列。
如下图:除了默认的default队列,再增加1个hive队列。


<property><name>yarn.scheduler.capacity.root.hive.capacity</name><value>50</value><description>1、hive队列的容量为50%</description></property><property><name>yarn.scheduler.capacity.root.hive.user-limit-factor</name><value>1</value><description>2、一个用户最多能够获取该队列资源容量的比例,取值0-1</description></property><property><name>yarn.scheduler.capacity.root.hive.maximum-capacity</name><value>80</value><description>3、hive队列的最大容量(自己队列资源不够,可以使用其他队列资源上限)</description></property><property><name>yarn.scheduler.capacity.root.hive.state</name><value>RUNNING</value><description>4、开启hive队列运行,如果不设置,则队列不能使用</description></property><property><name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name><value>*</value><description>5、访问控制,控制谁可以将任务提交到该队列,*表示任何人</description></property><property><name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name><value>*</value><description>6、访问控制,控制谁可以管理(包括提交和取消)该队列的任务,*表示任何人</description></property><property><name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name><value>*</value><description>7、指定哪个用户可以提交配置任务优先级</description></property><property><name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime</name><value>-1</value><description>8、hive队列中任务的最大生命时长,以秒为单位。任何小于或等于零的值将被视为禁用。</description></property><property><name>yarn.scheduler.capacity.root.hive.default-application-lifetime</name><value>-1</value><description>9、hive队列中任务的默认生命时长,以秒为单位。任何小于或等于零的值将被视为禁用。</description></property>

xsync__nodes.sh capacity-scheduler.xml
[qiusheng@node01 hadoop]$ cluster.sh stop[qiusheng@node01 hadoop]$ cluster.sh start
三、测试Yarn容量调度器多队列
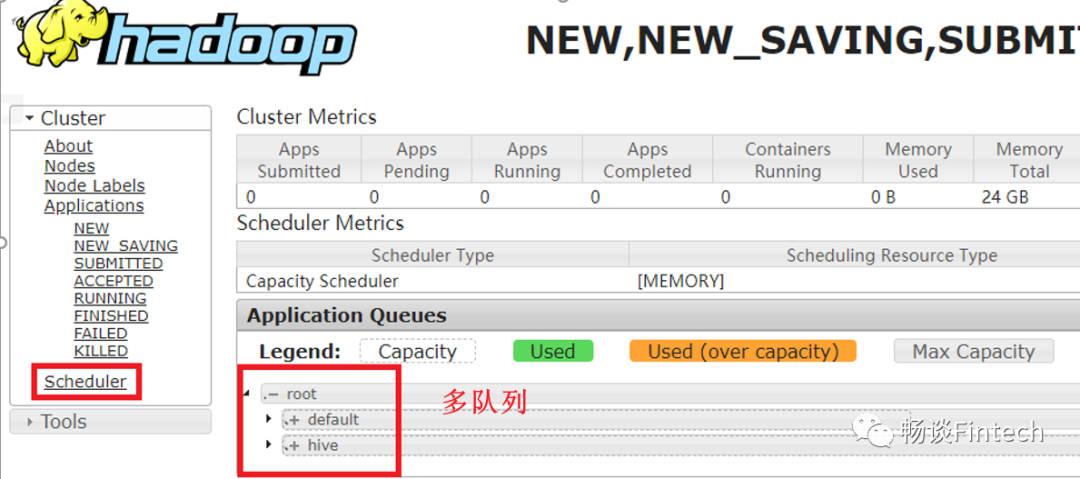
insert into table student values(2,'list');
随后在开启一个MR队列,我们这里利用hadoop集群自带的圆周率计算问题
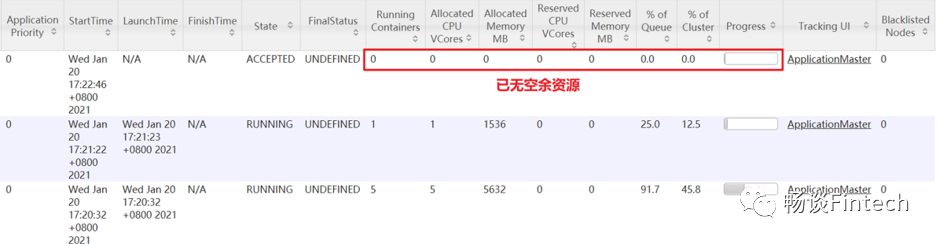
4、再次观察Resource ManagerUI界面
http://192.168.8.132:8088/cluster,我们可以看到hive on spark的任务已经执行,但是MR任务没有执行。这个是为什么呢?

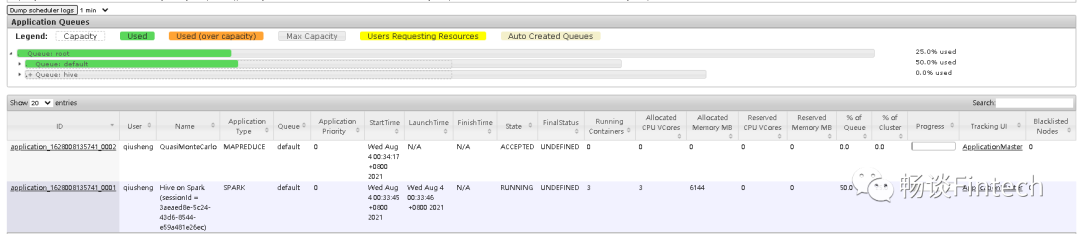
然后再开一个MR任务还是刚才hadoop集群自带的PI任务,指定hive队列使用
 我们再看队列queues里面,root下面hive队列和default队列都被使用了;
我们再看队列queues里面,root下面hive队列和default队列都被使用了;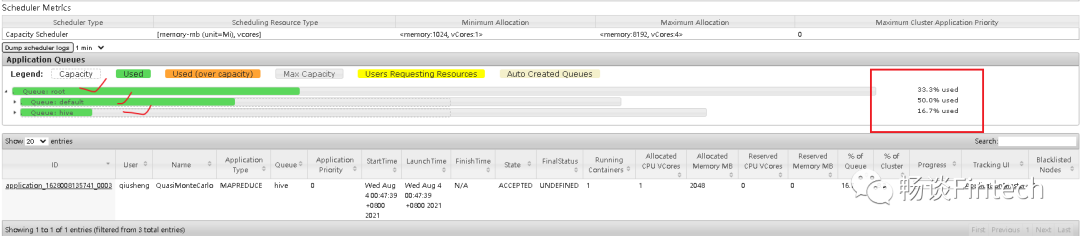
其中hive队列详细信息
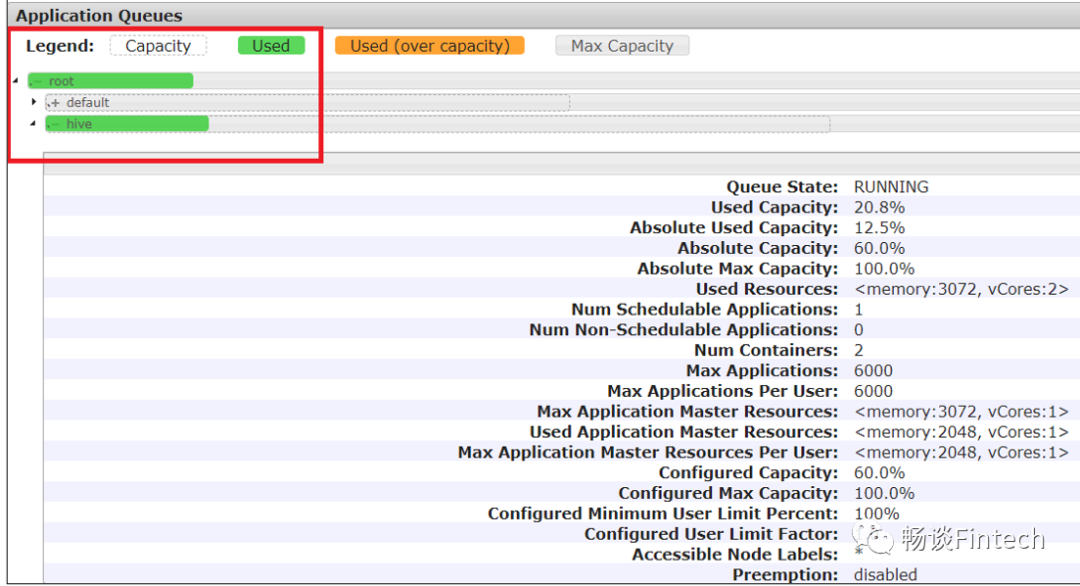
修改yarn-site.xml
添加proriety属性
<property><name>yarn.cluster.max-application-priority</name><value>5</value></property>
分发文件后,重启yarn
xsync__nodes.sh yarn-site.xmlsbin/stop-yarn.shsbin/start-yarn.sh
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar pi 5 1000000
再次提交优先级高的任务。
-D mapreduce.job.priority=5
hadoop jar /opt/module/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar pi -D mapreduce.job.priority=5 5 1000000
我们看这个job,拿到了高级优先任务。

四、Yarn容量调度器
1、Capacity Scheduler容量调度器
Hadoop作业调度器主要有三种:FIFO、容量(Capacity Scheduler)和公平(Fair Scheduler)。ApacheHadoop3.1.3默认的资源调度器是Capacity Scheduler。
如下图所示Capacity Scheduler:

多队列模式
root下面有queueA\B \C等队列,每个队列配置一定的资源。
采用FIFO模式
每个队列采用first in first out模式。
动态共享资源
如果一个队列中的资源还有剩余,比如上图中队列B还有50%资源空闲,可以暂时共享给其他需要资源的队列比如A或者C,而且一旦B队列有新的应用job提交,则其他队列A或者C会把当前队列结束后,归还借调的资源给B。
多租户、多application共享
支持多用户,多application应用的job同时运行,为了防止一个用户的作业独占该队列的大部分资源,调度器可以调整配置每个用户提交的作业的资源的比列。避免单队列堵塞等待。
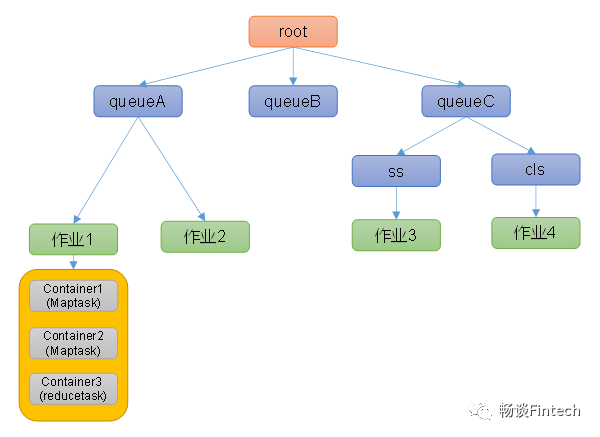
如上图所示:
queue队列资源分配 从root开始,使用深度优先算法,优先选择资源占用率最低的队列分配资源 A队列资源分配了20%,先给A队列分配job。 job作业资源分配 默认是按照提交到Yarn的作业的优先级以及提交时间的顺便分配资源。 A对列中的job1、job2 contain资源分配 按照容器的优先级分配资源,如果有 优先级相同,则按照“数据本地性”原则来分配资源。 数据本地性原则 数据和任务job在同一个节点即同一台服务器上 数据和任务job在同一个节点即同一个机柜的机架上 数据和任务job不在在同一个节点,也不在同一个机柜的机架上
总结:
增加ApplicationMaster资源比例; 容量调度器多对队列配置; 容量调度器队列分配算法; 模拟多队列测试并查看UI;
