





摘要:本文由以数据之名分享,正所谓“醉斩长鲸倚天剑,笑凌骇浪济川舟”。前面的四篇文章“Kettle知识库问答系列之三十而立、四十不惑、五十而耳知天命、六十而耳顺”,叙述了使用Kettle作为ETL开发的常见组件使用说明、业务场景实现逻辑、异常分析及组件性能优化相关内容。今天,我们跟着小编的节奏,继续探讨Kettle知识库问答系列之七十古稀篇,做到理念和实践的生动统一。

第063问:kettle Excel输入读取数据出现OOM?

第063答:由于Kettle Excel输入,表格引擎可以选择Excel 97 2003、Excel 2007 (Apache POI)、Excel 2007 (Apache POI Streaming)和 Open Office ODS四种类型,这里我们常用的一般是Excel 2007的Apache POI和Apache POI Streaming。

首先,一般我们经常默认选择表格引擎为Apache POI,而Apache POI引擎会一次性加载全部数据到内存,所以会占用大量的堆内内存,进而频繁触发OOM
异常。
其次,我们首先可以把表格引擎更改为Apache POI Streaming,该API引擎以串行方式处理Excel数据,即采用流模式分批次加载到内存,而不是将文件完全加载到内存中。极大的降低OOM的风险。
最后,我们还可以考虑一下优化点:
1、减少单批次输入数据量,缩减数据流字段传输(非必要字段提前排除),减少内存资源占用,提高gc回收效率。
2、适当调大jvm参数:"-Xmx1024m" "-XX:+HeapDumpOnOutOfMemoryError" 其中mx控制最大内存,另外一个参数打印dump文件
3、参考我的文章“Kettle知识库问答系列之三十而立”、“Kettle知识库问答系列之六十而耳顺”,关于性能优化及OOM说明章节
第064问:kettle SqlServer输出组件写入数据时,出现?

第064答:SqlServer对于表模型带有标识identity属性字段,默认不允许自己插入数据。
但如果需要自己插入数据,可以先对有标识列的字段要设置 set IDENTITY_INSERT 表名 on,然后再执行插入记录操作;插入完毕后恢复为 off 设置。
格式:set IDENTITY_INSERT 表名 onset IDENTITY_INSERT 表名 off
第065问:Linux Spoon测试Kettle部署情况,报异常Could not load SWT library. Reasons?
java.lang.UnsatisfiedLinkError: Could not load SWT library. Reasons:
no swt-pi-gtk-4335 in java.library.path
no swt-pi-gtk in java.library.path
/home/proot/.swt/lib/linux/x86_64/libswt-pi-gtk-4335.so: libXtst.so.6: cannot open shared object file: No such file or directory
Can't load library: home/proot/.swt/lib/linux/x86_64/libswt-pi-gtk.so
第065答:说明没安装 SWT library ,需要安装 SWT 库
yum -y install gtk2.i686 gtk2-engines.i686 PackageKit-gtk-module.i686it-gtk-module.x86_64 libcanberra-gtk2.x86_64 libcanberra-gtk2.i686 PackageK
第066问:Linux Spoon测试Kettle部署情况,报异常No more handles [gtk_init_check()?
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=256m; support was removed in 8.0(这里是使用jdk8,但却配置了jdk1.7的jvm参数)
org.eclipse.swt.SWTError: No more handles [gtk_init_check() failed]
at org.eclipse.swt.SWT.error(Unknown Source)
at org.eclipse.swt.widgets.Display.createDisplay(Unknown Source)
第066答:说明操作系统没有安装图形化界面
yum -y install "GNOME Desktop"

第067问:Kettle作业Job调用转换Trans如何控制顺序呢?
第067答:首先,顺序控制有如下二种场景:
一、job调用转换控制顺序
如果是单条链路,本身是有序的,SQL脚本除外;
如果是多条线路,线路间控制顺序可以使用等待SQL组件或者等待文件组件;
等待SQL组件示例,请回复waitsql获取。
二、转换内控制顺序
转换内每个组件都是单独的线程,所以除带有阻塞功能的组件外,数据流是线性行级别流转的;
转换内多条链路控制顺序,可以使用阻塞组件;
阻塞示例及说明,请参考文章“Kettle知识库问答系列之四十不惑”第32问;
数据流转顺序解释,请参考文章“Kettle知识库问答系列之六十而耳顺”第60问。
第068问:Kettle 数据重复表输出,如何解决数据冲突 ?
第068答:首先,要看输入数据流中是否有重复主键数据行?
如果有,先要做数据去重或者group by;
如果没有,我们再从组件组合使用上来阐述解决方案:
一、如果多次主键数据行,无需考虑业务更新:
1、输出前,先根据主键反查目标表,查询是否存在标记,存在则过滤掉donothing,不存在则输出
输入+数据库查询/数据库连接+过滤记录+输出
2、输出时,直接异常处理,写入日志、文本或数据库(主键冲突时,异常输出)
输入+输出+异常处理(日志)
二、如果多次主键数据行,需考虑业务更新:
1、输出前,先根据主键反查目标表,查询是否存在标记,存在则更新,不存在则输出
输入+数据库查询/数据库连接+过滤记录+输出
2、输出时,直接异常处理,更新(主键冲突时,异常的则作更新)
输入+输出+异常处理(更新)
3、输出改为插入更新
输入+插入更新
三、如果考虑数据库集群,主备延迟+读写分离前提
那么,1.1和2.1都会存在,主库数据已写入,备库延迟,导致反查标记异常,流程分支异常
综上所诉,推荐使用2.3插入更新方案;如不考虑更新且可以接收数据库服务端写入异常,可考虑1.2

第069问:Kettle作业Job 等待SQL如何用呢?
第069答:首先,假设我们有1个作业A、3个转换(B、C、D),要按照如下图顺序执行:
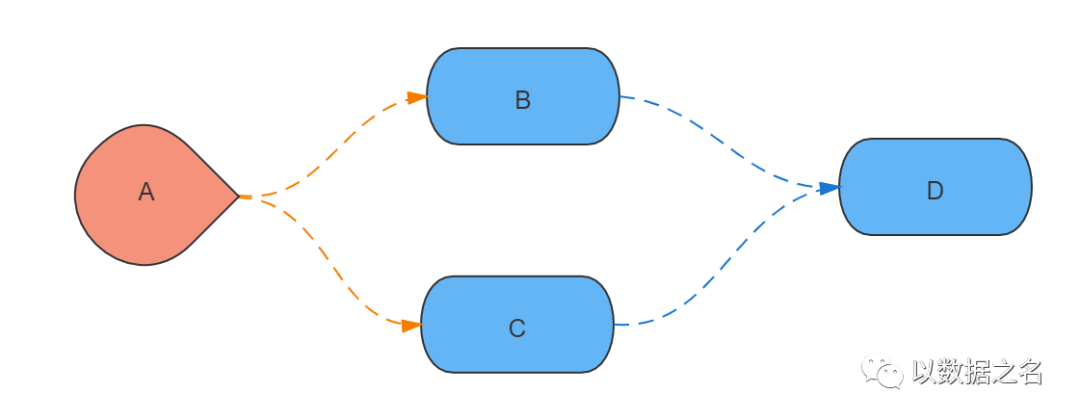
那么加上等待SQL之后的流程图如下:
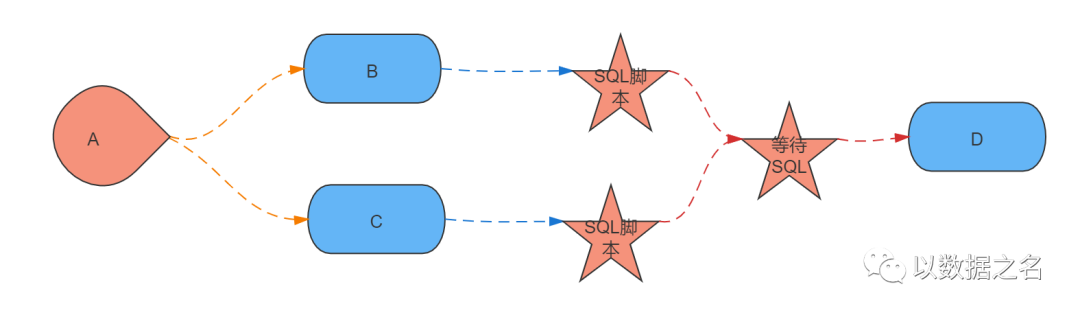
等待SQL会校验SQL脚本1和SQL脚本2操作后,结果记录是否匹配,匹配后再执行D
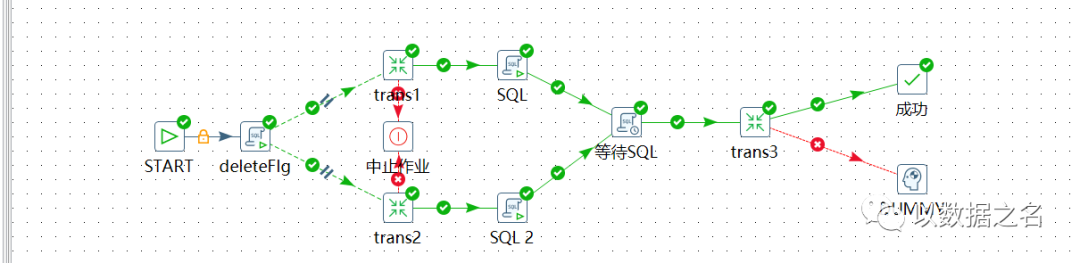
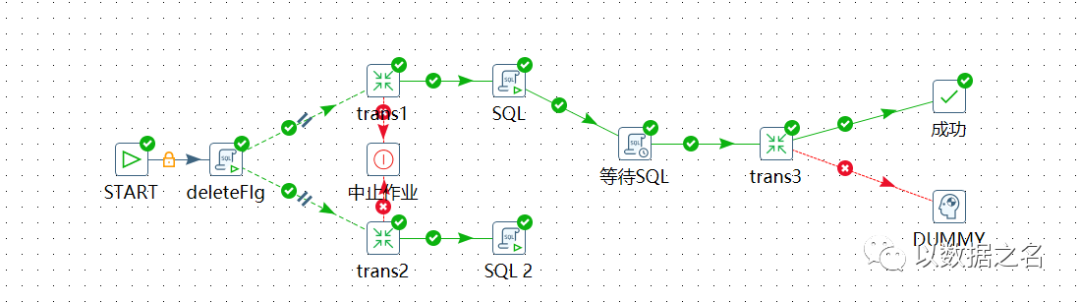
上图trans3会被执行2次,优化后流程

等待SQL组件示例,请回复waitsql获取。
第070问:Kettle作业Job 等待文件如何用呢?
第070答:首先,假设我们有1个作业A、3个转换(B、C、D),要按照如下图顺序执行:
那么加上等待文件之后的流程图如下:
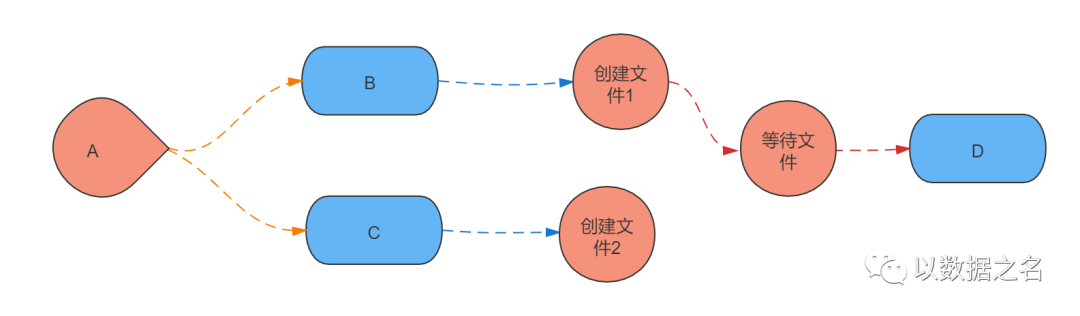
等待文件会校验创建文件1和创建文件2操作后,检查文件是否匹配,匹配后再执行D
第071问:Kettle 多个作业Job间依赖关系如何做呢 ?
第071答:首先,假设我们有A、B、C三个作业,想要A、B、C作业分别执行,但C某一步骤依赖于A、B。即A、B执行完,再执行C。换句话说:原子作业间如何维持依赖关系。这样做的好处有哪些呢?
作业间低耦合,运维简单
作业并行执行,效率更高
作业可靠性更高,A、B任何一个执行异常,相互不影响
其次,维持依赖关系,我们可以使用等待SQL组件或者等待文件组件,作为核心依赖控制信号,来维持作业间的业务逻辑关系,本例子以等待文件作为信号来实现,具体流程如下:
作业A:
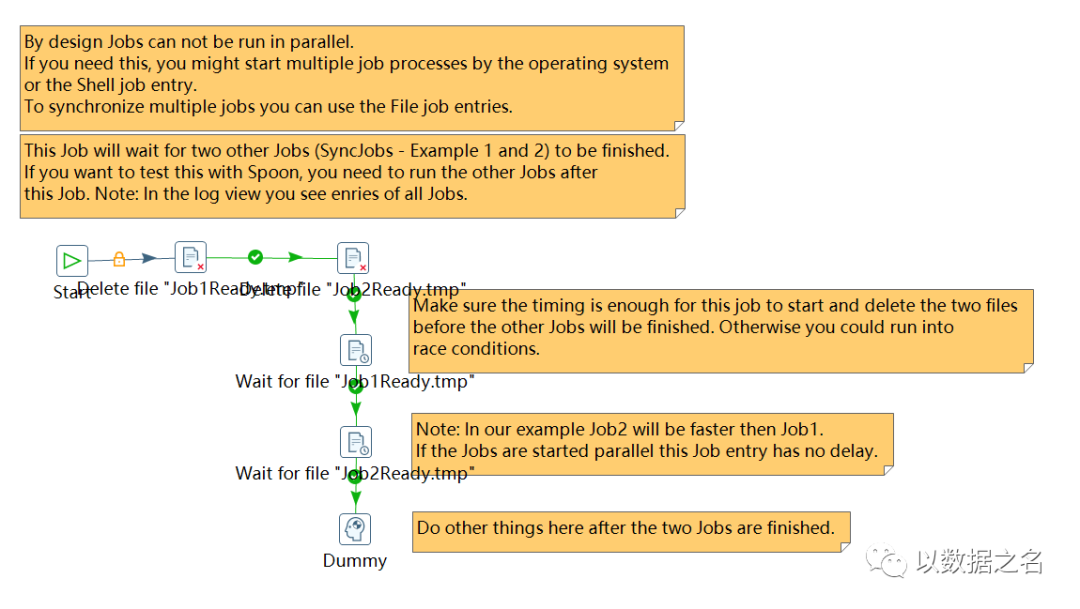
作业B:

作业C:
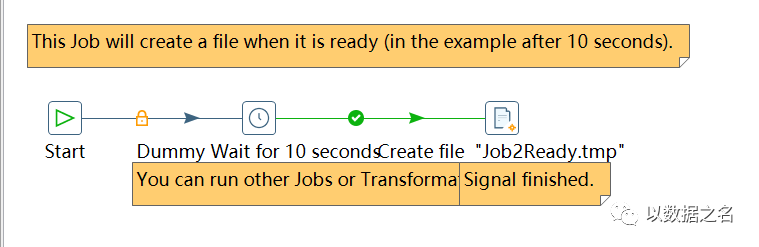
4、对应并行等待信号示例,请回复pwait获取。
第072问:Kettle 动态增加列 ?
第072答:首先,分两种方式去实现:
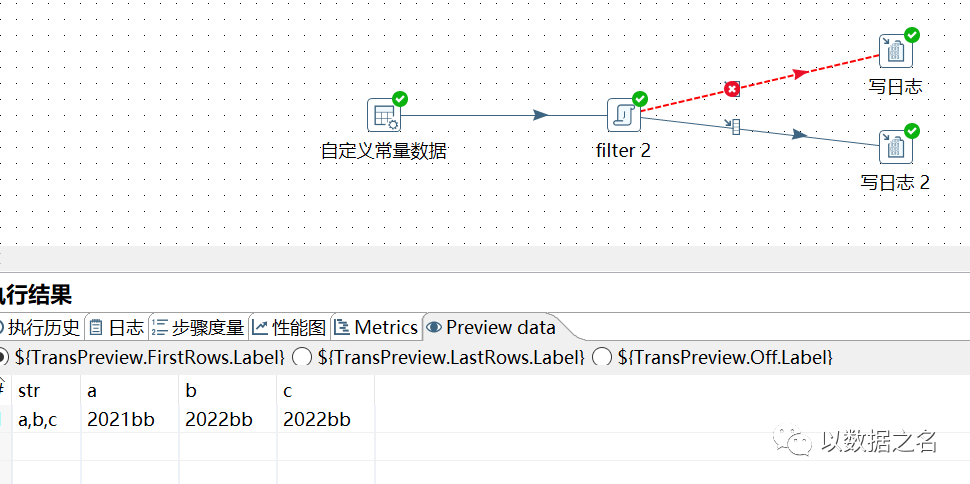
1、先创造输入流空列,如下a,b,c。然后遍历str动态获取a\b\c三个字段值,并分别对abc列做相同处理操作(如字符串处理,或者加解密操作等)
示例一:
关键代码:

处理流程图与执行结果:
示例二: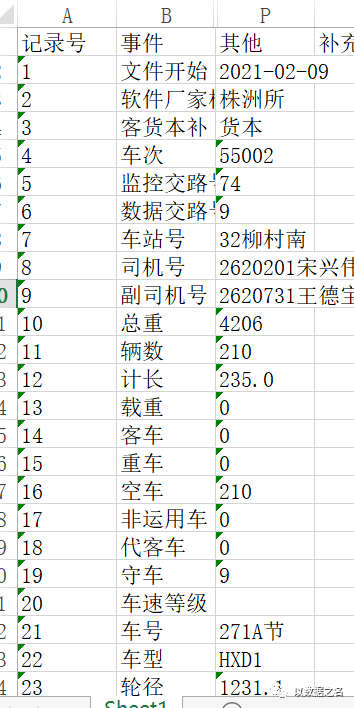 此处测试数据集由心痛提供,感谢鸣谢!
此处测试数据集由心痛提供,感谢鸣谢!
处理流程图:
虚构记录号为key,把事件和其他转成动态列,与其一一对应,最后剔除虚构key行
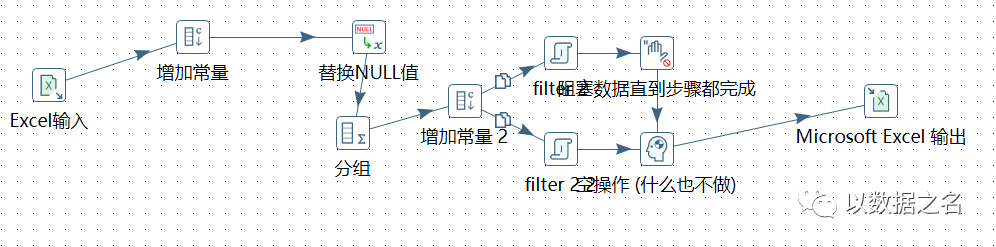


2、无需构造对应数据流,动态生成列key与value,此处示例代码由 提供,特别鸣谢!
提供,特别鸣谢!


3、回复dynamic,获取动态新增列示例

Kettle插件开发之KafkaConsumerAssignPartition篇
Kettle插件开发之KafkaConsumerAssignPartition篇
虽小编一己之力微弱,但读者众星之光璀璨。小编敞开心扉之门,还望倾囊赐教原创之文,期待之心满于胸怀,感激之情溢于言表。一句话,欢迎联系小编投稿您的原创文章!

