




Kyligence 4.5 全新产品发布,推出了业内期盼已久的智能分层存储(Smart Tiered Storage™️)功能,将 ClickHouse 有机融合在 Kyligence 产品的基座中。无论是数据中心还是多云部署,Kyligence 都能全面覆盖各类分析场景,用户无需维护复杂的数据平台,即可获得统一的查询分析体验。
今天本文就将带大家一览智能分层存储功能的技术原理、实现方式和核心优势,同时8月12日我们也将举办网络研讨会,您可以在文末点击“阅读原文”或扫码报名参与。
Demo视频也同步奉上~!
分层存储 势在必行
维护成本高:不同的系统所带来的学习成本和维护成本都很高;
数据一致性低:数据会分布在不同的系统中,容易导致数据不一致以及数据孤岛问题;
问题排查难:一旦出现问题,排查链路长,难度高;
低效工作多:上下游需要做很多的对接工作。
智能分层存储 VS ClickHouse
第一层:MPP 引擎层——将数据存储在 MPP 引擎中(存放表索引 Table Index)
第二层:分布式存储层——将数据存储在 HDFS 对象存储中(存放预计算后的聚合索引)
第三层:查询下压层——查询可下推到其他数据源,如 SparkSql
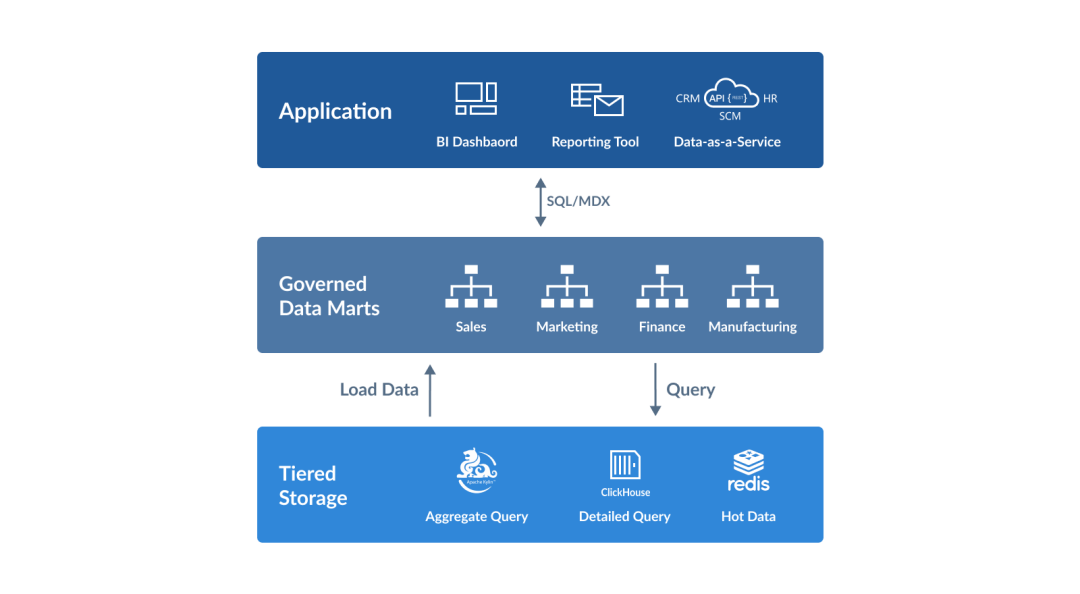
适用场景
超多维度列的 ad-hoc 查询 (如标签)
明细查询
点查场景
业务价值
降低单条查询的成本;
增加系统整体的并发度;
赋能用户灵活优化模型,进行聚合索引的创建。
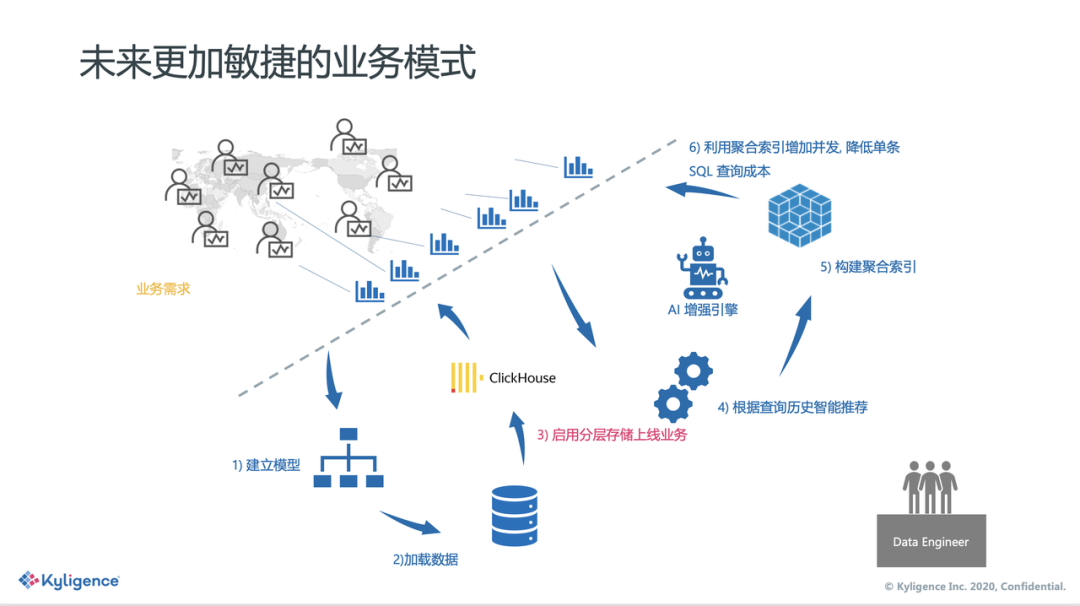
简单、高效、统一的用户体验
数据分析师: 对于分析师来讲,分层存储是透明的,所有的查询分析由系统来进行智能路由,用户无法感知到底层的区别,用户也无需关心底层查询是由哪个引擎来回答的,系统会智能的挑选最优的引擎来回答。通过分层存储功能,同时屏蔽了 ClickHouse SQL 兼容性的问题,可以无缝对接各种主流 BI 应用,第三方数据应用等。
数据开发工程师: 对于数据开发工程师来讲,系统可以根据模型的数据表采样结果,维度和度量的设置,对用户智能提示是否需要启用分层存储功能。已启用分层存储功能的模型数据将会自动随着构建任务导入至 ClickHouse 集群中, 无需用户手动导入。
运维人员: 对于运维人员来讲,已有的 ClickHouse 集群可以轻松对接,若没有现有 ClickHouse 集群,则能够轻松部署,并提供了监控报警,弹性伸缩,数据恢复等功能,大大减少运维成本。
长按二维码 立即报名
更有惊喜礼品等你领
↓↓↓

关于 Kyligence

