




环境:REDHAT 7.4 + 19.3 RAC+ADG
问题发现:
7月份的一天,应客户要求使用NBU+RMAN备份的数据文件使用另外一个环境异机恢复,restore完成后,在recover时提示需要很早之前的归档文件(比最近一次全备时间要早)。
入手分析:
1、检查备份文件
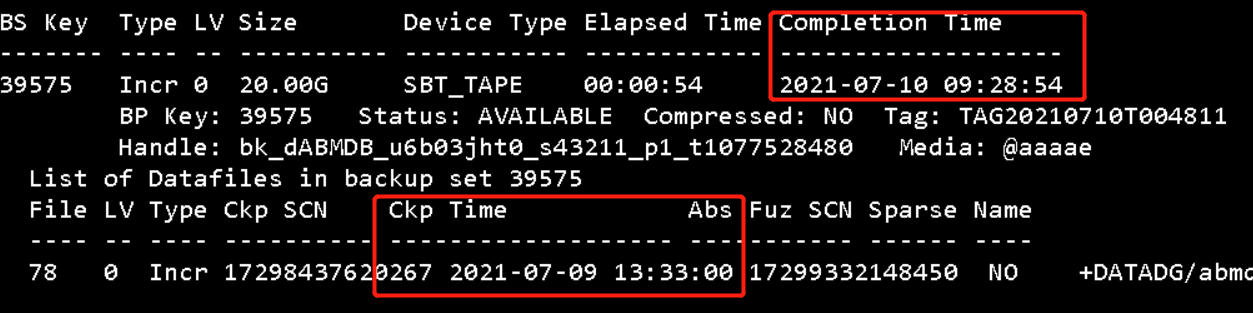
这里,我restore使用的是7-10的全备文件恢复,在recover 时提示我需要7月9日的归档文件。
2、查看数据文件检查点
SQL> select status, checkpoint_change#,
to_char(checkpoint_time, 'DD-MON-YYYY HH24:MI:SS')
as checkpoint_time, count(*) from v$datafile_header
group by status, checkpoint_change#, checkpoint_time
order by status, checkpoint_change#, checkpoint_time; 2 3 4 5
STATUS CHECKPOINT_CHANGE# CHECKPOINT_TIME COUNT(*)
------- ------------------ ----------------------- ----------
ONLINE 1.7300E+13 10-JUL-2021 23:50:10 338
SQL> select sysdate from dual;--当前时间
SYSDATE
-------------------
2021-07-15 21:03:06
很明显,ADG备库的CHECKPOINT_TIME 永远小于当前时间。
3、检查备库alert日志和redo应用状态都没有问题。
NAME VALUE UNIT TIME_COMPUTED
------------------------- -------------------- ------------------------------ ------------------------------
transport lag +00 00:00:00 day(2) to second(0) interval 07/16/2021 11:19:09
apply lag +00 00:00:00 day(2) to second(0) interval 07/16/2021 11:19:09
4、MOS查找分析
疑似由于 Bug 29056767 - STANDBY: Datafiles Checkpoint not Updated at Standby Database when Media Recover is running
于是检查参数 “_time_based_rcv_ckpt_target” 的值为180
5、修改参数并重启MRP验证
[BEGIN] 2021/7/16 11:18:31
SQL> show parameter name
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
cdb_cluster_name string
cell_offloadgroup_name string
db_file_name_convert string actdb, actstdby
db_name string actdb
db_unique_name string actstdby
global_names boolean FALSE
instance_name string actdb1
lock_name_space string
log_file_name_convert string actdb, actstdby
pdb_file_name_convert string
processor_group_name string
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
service_names string actstdby, actdb
SQL>
SQL> @adg_stat
PROCESS CLIENT_P SEQUENCE# STATUS
--------- -------- ---------- ------------
ARCH ARCH 44246 CLOSING
DGRD N/A 0 ALLOCATED
DGRD N/A 0 ALLOCATED
ARCH ARCH 44245 CLOSING
ARCH ARCH 40613 CLOSING
ARCH ARCH 40612 CLOSING
MRP0 N/A 40614 APPLYING_LOG
RFS LGWR 40614 IDLE
RFS Archival 0 IDLE
RFS UNKNOWN 0 IDLE
RFS LGWR 44249 IDLE
PROCESS CLIENT_P SEQUENCE# STATUS
--------- -------- ---------- ------------
RFS UNKNOWN 0 IDLE
RFS UNKNOWN 0 IDLE
RFS Archival 0 IDLE
RFS UNKNOWN 0 IDLE
RFS UNKNOWN 0 IDLE
16 rows selected.
SEQUENCE# APPLIED
---------- ---------
44248 YES
44247 YES
44246 YES
44245 YES
44244 YES
44243 YES
44242 YES
44241 YES
44240 YES
9 rows selected.
NAME VALUE UNIT TIME_COMPUTED
------------------------- -------------------- ------------------------------ ------------------------------
transport lag +00 00:00:00 day(2) to second(0) interval 07/16/2021 11:19:09
apply lag +00 00:00:00 day(2) to second(0) interval 07/16/2021 11:19:09
SQL>
SQL> select status, checkpoint_change#,
to_char(checkpoint_time, 'DD-MON-YYYY HH24:MI:SS')
as checkpoint_time, count(*) from v$datafile_header
group by status, checkpoint_change#, checkpoint_time
order by status, checkpoint_change#, checkpoint_time; 2 3 4 5
STATUS CHECKPOINT_CHANGE# CHECKPOINT_TIME COUNT(*)
------- ------------------ ----------------------- ----------
ONLINE 1.7300E+13 10-JUL-2021 23:50:10 338
SQL>
SQL>
SQL> select ksppinm as "hidden parameter",
ksppstvl as "value" from x$ksppi join x$ksppcv using (indx)
where ksppinm like '_time_based_rcv_ckpt%' order by ksppinm; 2 3
hidden parameter value
-------------------------------------------------------------------------------- --------------------
_time_based_rcv_ckpt_target 180
SQL>
SQL> alter system set "_time_based_rcv_ckpt_target"=0;
System altered.
SQL> alter database recover managed standby database cancel;
Database altered.
SQL> alter database recover managed standby database using current logfile disconnect from session;
Database altered.
SQL>
SQL> select ksppinm as "hidden parameter",
ksppstvl as "value" from x$ksppi join x$ksppcv using (indx)
where ksppinm like '_time_based_rcv_ckpt%' order by ksppinm; 2 3
hidden parameter value
-------------------------------------------------------------------------------- --------------------
_time_based_rcv_ckpt_target 0
SQL>
SQL> select status, checkpoint_change#,
to_char(checkpoint_time, 'DD-MON-YYYY HH24:MI:SS')
as checkpoint_time, count(*) from v$datafile_header
group by status, checkpoint_change#, checkpoint_time
order by status, checkpoint_change#, checkpoint_time; 2 3 4 5
STATUS CHECKPOINT_CHANGE# CHECKPOINT_TIME COUNT(*)
------- ------------------ ----------------------- ----------
ONLINE 1.7306E+13 16-JUL-2021 11:20:40 338
SQL>
SQL>
SQL> /
STATUS CHECKPOINT_CHANGE# CHECKPOINT_TIME COUNT(*)
------- ------------------ ----------------------- ----------
ONLINE 1.7306E+13 16-JUL-2021 11:20:40 338
SQL>
[END] 2021/7/16 11:22:54
验证OK,完美解决。
在自己测试中发现:当MRP进程节点DOWN,也会引发recover操作需要读取checkpoint scn时间点的归档文件,而不是从故障时间点开始恢复。
如果checkpoint time和当前时间相隔很远,归档丢失情况下,就需要重新做备库了,风险还是相当大的。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
