




定义
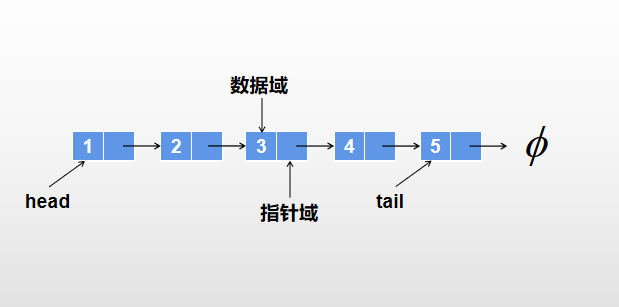
链表由一系列结点(链表中每一个元素称为结点)组成,每个结点包括两个部分:一个是存储数据项的数据域,另一个是存储下一个结点地址的指针域。链表的第一个节点称为头结点,链表的最后一个结点称为尾结点。由于每个结点的指针域可以被视为指向下一个节点的指针或者链接,所以遍历链表的过程也称为链表跳跃或者指针跳跃。
Python实现链表
# 创建结点类
class LNode(object):
# 设置数据域属性和指针域属性
def __init__(self, data, p=0):
self.data = data
self.next = p
# 创建链表类
class LinkList(object):
# 初始头指针指向空
def __init__(self):
self.head = LNode(0)
# 链表初始化函数
def initList(self, data):
#创建头结点
self.head = LNode(data[0])
p = self.head
#逐个为 data 内的数据创建结点, 建立链表
for i in data[1:]:
node = LNode(i)
p.next = node
p = p.next
# 判断链表是否为空
def isEmpty(self):
return self.head.next == 0
# 获取链表长度
def getLength(self):
if self.isEmpty():
return "isEmpty"
p = self.head
len = 0
while p:
len += 1
p = p.next
return len
# 遍历链表
def traveList(self):
if self.isEmpty():
return "isEmpty"
p = self.head
while p:
print(p.data,)
p = p.next
# 向链表插入数据
def insertElem(self, key, index):
if self.isEmpty():
return "isEmpty"
if index < 0 or index > self.getLength()-1:
print()
p = self.head
i, pre = 0, 0
while i <= index:
pre = p
p = p.next
i += 1
# 遍历找到索引值为index的结点后, 在其后面插入结点
node = LNode(key)
pre.next = node
node.next = p
# 删除数据
def deleteElem(self, index):
if self.isEmpty():
return "isEmpty"
if index < 0 or index > self.getLength()-1:
print()
i, pre = 0, 0
p = self.head
# 遍历找到索引值为index的结点
while p.next:
pre = p
p = p.next
i += 1
if i == index:
pre.next = p.next
p = None
return 1
# 若p的下一个结点为尾结点,则删除
pre.next = None
单向链表
单向链表(单链表)是链表的一种,其特点是链表的链接方向是单向的,对链表的访问要通过顺序读取从头部开始。
单向链表的一个重要属性就是没有预先确定的大小,它所占用的空间取决于当前链表中数据项的个数,所以不会造成空间的浪费。
单向链表的基本思想:创建一个新的结点,数据域存储新的数据项,然后
如果将新结点插入单向链表的头部,那么先将新结点的指针域设置为指向当前头结点,然后设置链表的头指针指向新结点。 如果将新结点插入单向链表的尾部,那么先将新节点的指针域设置为空,再将当前尾结点的指针域设置为指向新结点,最后将尾指针指向新结点。 上述两种插入方法如下,操作代码如下:
# 向单链表的头部插入结点
def add.first(L,e):
newest = Node(e) # 创建一个新结点,数据域为e
newest.next = L.head # 设置新结点的指针域指向单链表L的当前头结点
L.head = newest # 设置头指针指向新结点
L.size = L.size + 1 # 单链表长度加1
# 向单链表的尾部插入结点
def add.last(L,e):
newest = Node(e) # 创建一个新结点,数据域为e
newest.next = None # 设置当前结点的指针域指向空
L.tail.next = newest # 设置当前尾结点的指针域指向新结点
L.tail = newest # 设置尾指针指向新结点
L.size = L.size + 1 # 单链表长度加1
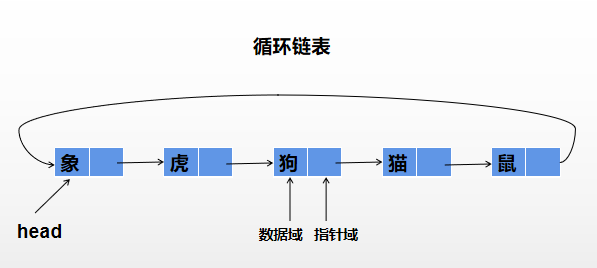
循环链表
循环链表是与单链表一样,是一种链式的存储结构,所不同的是,循环链表的尾结点的指针域是指向该循环链表的头结点,从而构成一个环形的链。
循环链表的运算与单链表的运算基本一致。所不同的有以下几点:
在建立一个循环链表时,必须使其最后一个结点的指针指向表头结点,而不是像单链表那样置为NULL。此种情况还使用于在最后一个结点后插入一个新的结点。 在判断是否到达表尾时,是判断该结点链域的值是否是表头结点,当链域值等于表头指针时,说明已到表尾。而不是像单链表那样判断链域值是否为NULL。
循环链表的特点是无须增加存储量,仅对表的链接方式稍作改变,即可使得表处理更加方便灵活。
注意:
循环链表中没有NULL指针。涉及遍历操作时,其终止条件是判别它们是否等于某一指定指针,如头指针或尾指针等。 在单链表中,从一已知结点出发,只能访问到该节点及其后续结点,无法找到该节点之前的任何结点。而在循环链表中,从任一结点出发都可以访问到表中所有结点,这一优点使某些运算在循环链表上易于实现。
双向链表
双向链表也叫双链表它的每个数据结点中都有两个指针,分别指向直接后继(后一个结点)和直接前驱(前一个结点)。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。
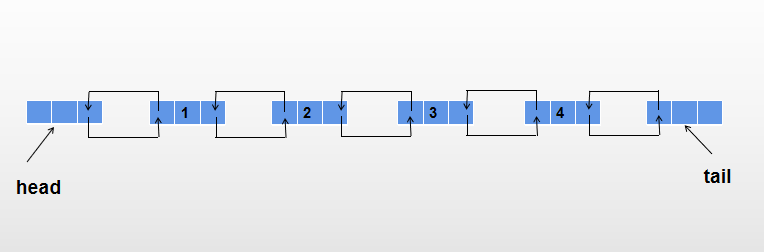
双向链表其实是单向链表的改进。当我们对单向链表进行操作时,有时你要对某个结点的直接前驱进行操作时,又必须从表头开始查找。这是由单向链表结点的结构所限制的,因为单链表每个结点只有一个存储直接后继结点地址的指针域。而在双向链表中,结点除含有数据域外,还有两个指针域,一个存储直接后继结点地址,一般称之为右指针域;一个存储直接前驱结点地址,一般称之为左指针域。
双向链表的插入操作步骤:
第一步:将新结点的左指针域设置为指向原直接前驱的右指针域,将新结点的右指针域设置为指向原直接后继的左指针域;
第二步:将原直接前驱的右指针域设置为指向新结点的左指针域,将原直接后继的左指针域设置为指向新结点的右指针域。
双向链表的删除操作步骤:
第一步:先将该结点的直接前驱的右指针域设置为指向该结点的直接后继的左指针域,再将该结点的直接后继的左指针域设置为指向该结点的直接后继的右指针域;
第二步:删除该结点。
