








SQL> SELECT g.category_name, g.class_name, SUM(g.stock)2 FROM demo_group_test g3 GROUP BY g.category_name, g.class_name;CATEGORY_NAME CLASS_NAME SUM(G.STOCK)-------------------- -------------------- ------------K K1 25K K2 80K K3 40Q Q1 20Q Q2 20Q Q3 506 rows selected
现在假设只计算 CATEGORY,CLASS 分组求和已经不能满足需要了,现在还想看个小计和总计,也就是按 CATEGORY 再加个小计,最后再加个全表的总计

SQL> SELECT *2 FROM (SELECT g.category_name, g.class_name, SUM(g.stock)3 FROM demo_group_test g4 GROUP BY g.category_name, g.class_name5 UNION ALL6 SELECT g.category_name, NULL, SUM(g.stock)7 FROM demo_group_test g8 GROUP BY g.category_name, NULL9 UNION ALL10 SELECT NULL, NULL, SUM(g.stock)11 FROM demo_group_test g12 GROUP BY NULL, NULL)13 ORDER BY category_name, class_name;CATEGORY_NAME CLASS_NAME SUM(G.STOCK)-------------------- -------------------- ------------K C1 25K C2 80K C3 40K 145Q C1 20Q C2 20Q C3 50Q 902359 rows selected
三种不同的分组,带来的将是对同一张表三次的扫描读取,如果我们使用 ROLLUP 则可以避免这种重复的扫描
SQL> SELECT g.category_name, g.class_name, SUM(g.stock)2 FROM demo_group_test g3 GROUP BY ROLLUP(g.category_name, g.class_name);CATEGORY_NAME CLASS_NAME SUM(G.STOCK)-------------------- -------------------- ------------K C1 25K C2 80K C3 40K 145Q C1 20Q C2 20Q C3 50Q 902359 rows selected




SQL> SELECT *2 FROM (SELECT g.category_name, g.class_name, SUM(g.stock)3 FROM demo_group_test g4 GROUP BY g.category_name, g.class_name5 UNION ALL6 SELECT g.category_name, NULL, SUM(g.stock)7 FROM demo_group_test g8 GROUP BY g.category_name, NULL9 UNION ALL10 SELECT NULL, NULL, SUM(g.stock)11 FROM demo_group_test g12 GROUP BY NULL, NULL13 UNION ALL14 SELECT NULL, g.class_name, SUM(g.stock)15 FROM demo_group_test g16 GROUP BY NULL, g.class_name)17 ORDER BY category_name, class_name;CATEGORY_NAME CLASS_NAME SUM(G.STOCK)-------------------- -------------------- ------------K C1 25K C2 80K C3 40K 145Q C1 20Q C2 20Q C3 50Q 90C1 45C2 100C3 9023512 rows selected
没跑儿的咱们现在拿 CUBE 来替换一下,表扫描次数立马从 4 次降到 1 次
SQL> SELECT g.category_name, g.class_name, SUM(g.stock)2 FROM demo_group_test g3 GROUP BY CUBE(g.category_name, g.class_name);CATEGORY_NAME CLASS_NAME SUM(G.STOCK)-------------------- -------------------- ------------235C1 45C2 100C3 90K 145K C1 25K C2 80K C3 40Q 90Q C1 20Q C2 20Q C3 5012 rows selected
所以说,GROUP BY CUBE(COL1,COL2,COL3) 就相当于




SQL> SELECT *2 FROM (SELECT g.category_name, NULL class_name, SUM(g.stock)3 FROM demo_group_test g4 GROUP BY g.category_name, NULL5 UNION ALL6 SELECT NULL, g.class_name, SUM(g.stock)7 FROM demo_group_test g8 GROUP BY NULL, g.class_name)9 ORDER BY category_name, class_name;CATEGORY_NAME CLASS_NAME SUM(G.STOCK)-------------------- -------------------- ------------K 145Q 90C1 45C2 100C3 90
这三个栗子合着都是换一下关键字就解决了
SQL> SELECT g.category_name, g.class_name, SUM(g.stock)2 FROM demo_group_test g3 GROUP BY GROUPING SETS(g.category_name, g.class_name);CATEGORY_NAME CLASS_NAME SUM(G.STOCK)-------------------- -------------------- ------------K 145Q 90C2 100C1 45C3 90
所以说,GROUP BY GROUPING SETS(COL1,COL2,COL3) 就相当于
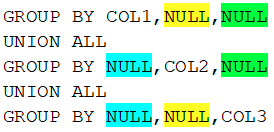

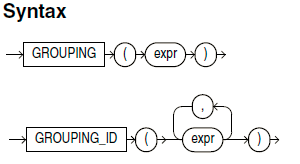
SQL> WITH rowgen AS2 (SELECT 0 bit_0, 1 bit_1 FROM dual),3 cubes AS4 (SELECT grouping_id(bit_0, bit_1) gid5 ,GROUPING(bit_0) bv_06 ,GROUPING(bit_1) bv_17 ,bit_08 ,bit_19 FROM rowgen10 GROUP BY CUBE(bit_0, bit_1))11 SELECT gid, bv_0 || bv_1 bit_vector, bit_0, bit_1 FROM cubes;GID BIT_VECTOR BIT_0 BIT_1---------- ------------ ---------- ----------3 112 10 11 01 00 00 0 1



文章转载自SQL干货分享,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
