











SQL> --计算各个部门的最高工资、最低工资和总工资SQL> SELECT e.deptno, MAX(e.sal) max_sal, MIN(e.sal) min_sal, SUM(e.sal) sum_sal2 FROM emp e3 GROUP BY e.deptno;DEPTNO MAX_SAL MIN_SAL SUM_SAL------ ---------- ---------- ----------30 2850 950 940020 3000 800 1087510 5000 1300 8750SQL> --计算各个部门各个岗位的平均工资,注意ORDER BY排序要放在GROUP BY分组之后SQL> SELECT e.deptno, e.job, AVG(e.sal) avg_sal2 FROM emp e3 GROUP BY e.deptno, e.job4 ORDER BY e.job, e.deptno;DEPTNO JOB AVG_SAL------ --------- ----------20 ANALYST 300010 CLERK 130020 CLERK 95030 CLERK 95010 MANAGER 245020 MANAGER 297530 MANAGER 285010 PRESIDENT 500030 SALESMAN 1400
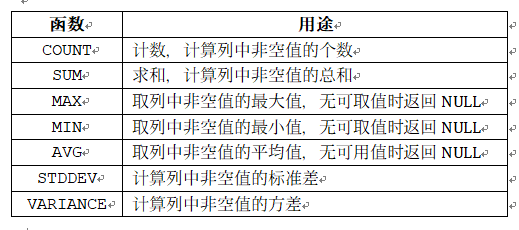
SUM 和 AVG 必须用于计算数值数据,但是 MAX 和 MIN 可以计算各种数据类型,比如日期和字符串,注意字符串的大小比较是通过比较 ASCII 标准转换结果实现的
SQL> --计算各个部门最早和最晚入职员工的入职日期SQL> SELECT e.deptno2 ,MAX(e.hiredate) last_hiredate3 ,MIN(e.hiredate) first_hiredate4 FROM emp e5 GROUP BY e.deptno;DEPTNO LAST_HIREDATE FIRST_HIREDATE------ ------------- --------------30 1981/12/3 1981/2/2020 1983/1/12 1980/12/1710 1982/1/23 1981/6/9
值得注意的是,聚合函数总是忽略列中的空值,如果分组内指定列没有可以用于计算的非空值(全部是空值,或者甚至组内没有行),则诸如 SUM、MAX、MIN、AVG 等聚合运算函数返回 NULL
SQL> --聚合函数总是避开空值(注意COMM列中的NULL值)SQL> SELECT e.deptno, e.comm FROM emp e;DEPTNO COMM------ ---------2030 300.0030 500.002030 1400.003010201030 0.0020302010SQL> SELECT e.deptno, MAX(e.comm) max_comm, MIN(e.comm) min_comm, SUM(e.comm) sum_comm2 FROM emp e3 GROUP BY e.deptno;DEPTNO MAX_COMM MIN_COMM SUM_COMM------ ---------- ---------- ----------30 1400 0 22002010
SQL> --COUNT函数是忽略空值而计数的SQL> SELECT e.deptno2 ,COUNT(e.comm) not_null_comm_count3 ,COUNT(e.empno) emp_count4 FROM emp e5 GROUP BY e.deptno;DEPTNO NOT_NULL_COMM_COUNT EMP_COUNT------ ------------------- ----------30 4 620 0 510 0 3SQL> --即便作用于没有行的分组,聚合函数仍然坚持返回结果SQL> SELECT MAX(1), MIN(1), SUM(1), AVG(1), COUNT(1) FROM dual WHERE 1 = 0;MAX(1) MIN(1) SUM(1) AVG(1) COUNT(1)---------- ---------- ---------- ---------- ----------0
COUNT 函数常用于计数各个分组内的行数,这时需要注意使用非空的列或者定义伪列更为可靠
SQL> --COUNT(1)与COUNT(col)SQL> SELECT e.deptno, COUNT(e.comm) not_null_comm_count, COUNT(1) emp_count2 FROM emp e3 GROUP BY e.deptno;DEPTNO NOT_NULL_COMM_COUNT EMP_COUNT------ ------------------- ----------30 4 620 0 510 0 3SQL> --COUNT(*)与COUNT(col)SQL> SELECT e.deptno, COUNT(e.comm) not_null_comm_count, COUNT(*) emp_count2 FROM emp e3 GROUP BY e.deptno;DEPTNO NOT_NULL_COMM_COUNT EMP_COUNT------ ------------------- ----------30 4 620 0 510 0 3SQL> --注意表中有一行为“空”行SQL> SELECT * FROM cux_count_star_test;ID----------100300SQL> SELECT COUNT(1) count_1, COUNT(id) count_col, COUNT(*) count_star2 FROM cux_count_star_test;COUNT_1 COUNT_COL COUNT_STAR---------- ---------- ----------3 2 3
HAVING 条件用于对分组后的结果进行进一步的筛选限制
SQL> --计算平均工资高于2000的部门的最高工资、最低工资SQL> SELECT e.deptno, MAX(e.sal) max_sal, MIN(e.sal) min_sal2 FROM emp e3 GROUP BY e.deptno4 HAVING AVG(e.sal) > 2000;DEPTNO MAX_SAL MIN_SAL------ ---------- ----------20 3000 80010 5000 1300

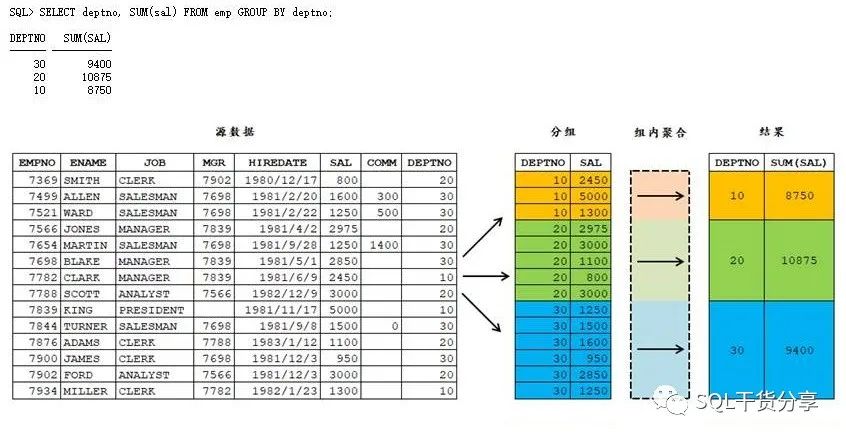
一开始是排除 GROUP BY [HAVING] 条件,根据 WHERE 条件等限定原始数据的选取范围
然后,特别需要强调的一步是,根据 GROUP BY 列表和参与聚合运算的列形成一个虚拟的数据集,并在这个集中进行分组,最后才在各组内进行指定的聚合运算
SQL> SELECT deptno, ename, SUM(sal) FROM emp GROUP BY deptno;SELECT deptno, ename, SUM(sal) FROM emp GROUP BY deptno*ORA-00979: 不是 GROUP BY 表达式
需要说明的是,聚合函数与数据分组并不是必须同时使用的:数据分组可以不引用聚合函数,使用聚合函数也可以不进行数据分组(或者说此时视表中全部行为一个组)
SQL> --数据分组实现DISTINCT去重效果SQL> SELECT deptno, job FROM emp GROUP BY deptno, job;DEPTNO JOB------ ---------30 CLERK10 CLERK20 ANALYST30 SALESMAN20 CLERK10 MANAGER10 PRESIDENT20 MANAGER30 MANAGERSQL> --统计表中总共有多少行SQL> SELECT COUNT(1) FROM emp;COUNT(1)----------14
今天的课程就讲到这里,下节课我们学习多张表联合查询


文章转载自SQL干货分享,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
