







SUM(d.schedule_qty) over(ORDER BY d.schedule_qty DESC rows BETWEEN unbounded preceding AND 1 preceding)
这是按照上面的分析原封不动写出的,但这么写又会带来一些麻烦,比如排在第一行的总是得到 NULL 值,还需要处理它,另外窗口声明写起来也很麻烦
SUM(d.schedule_qty) over(ORDER BY d.schedule_qty DESC, d.detail_id)
由于聚合函数 SUM 在分析模式下默认的窗口是逻辑窗口:从排在第一的值到当前值的范围,但如果像上面这样把主键这种不会重复的值引入排序的最次位置,就间接地实现了物理窗口的效果,从而省去了写窗口声明的代码量

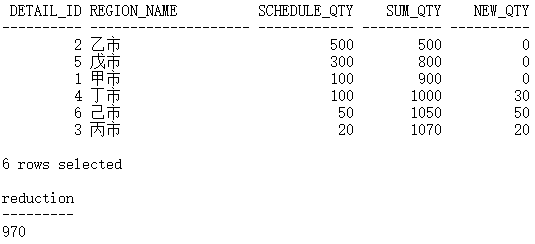
WITH sort_details AS(SELECT d.detail_id,d.region_name,d.schedule_qty,SUM(d.schedule_qty) over(ORDER BY d.schedule_qty DESC, d.detail_id) sum_qtyFROM demo_schedule_details d)SELECT s.detail_id,s.region_name,s.schedule_qty,s.sum_qty,CASEWHEN s.sum_qty <= :reduction THEN0WHEN s.sum_qty - :reduction <= s.schedule_qty THENs.sum_qty - :reductionELSEs.schedule_qtyEND new_qtyFROM sort_details s
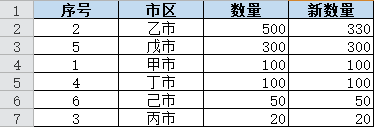
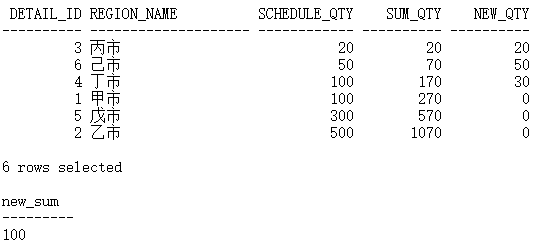
当总共调减 70 时,应该只在第一行减掉 70:
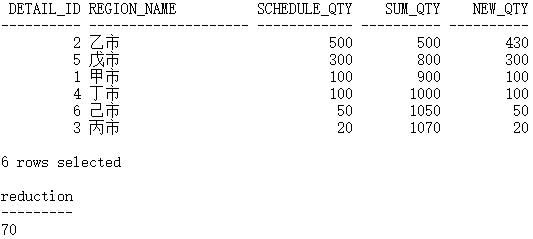
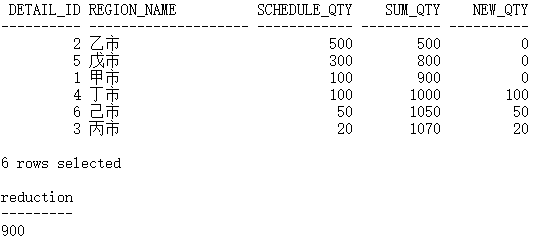

SQL> SELECT d.detail_id2 ,d.region_name3 ,d.schedule_qty4 ,SUM(d.schedule_qty) over(ORDER BY d.schedule_qty, d.detail_id DESC) sum_qty5 FROM demo_schedule_details d6DETAIL_ID REGION_NAME SCHEDULE_QTY SUM_QTY---------- -------------------- ------------ ----------3 丙市 20 206 己市 50 704 丁市 100 1701 甲市 100 2705 戊市 300 5702 乙市 500 10706 rows selected
在循环到某一行时,我们比较将本行与前序行全部加起来后能不能满足新的总量,不能满足的话,那么本行数量必须全部留下;如果已经超过了,那么要调减掉冒出的数量;当然,如果冒出的数量比当前行都多了,说明到某前序行为止已经凑足总数了,本行应全部裁剪
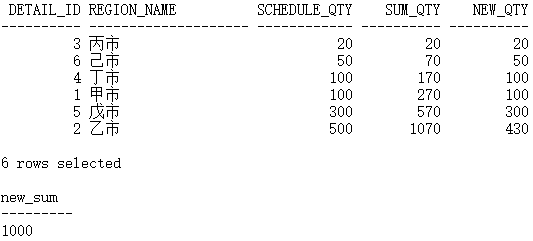
WITH sort_details AS(SELECT d.detail_id,d.region_name,d.schedule_qty,SUM(d.schedule_qty) over(ORDER BY d.schedule_qty, d.detail_id DESC) sum_qtyFROM demo_schedule_details d)SELECT s.detail_id,s.region_name,s.schedule_qty,s.sum_qty,CASEWHEN s.sum_qty <= 1000 THENs.schedule_qtyWHEN s.sum_qty - 1000 <= s.schedule_qty THENs.schedule_qty - (s.sum_qty - 1000)ELSE0END new_qtyFROM sort_details s
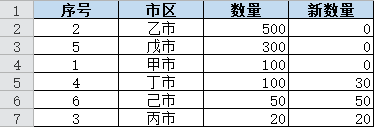
当总共调减 70,也就是新总量为 1000 时,最后一行减掉 70:
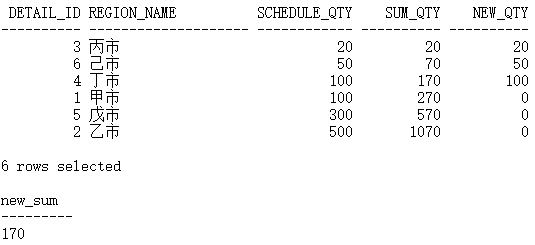

聪明的你,更喜欢哪种方法呢?

[2] 进发货报表问题
[3] 勘误声明

文章转载自SQL干货分享,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
