





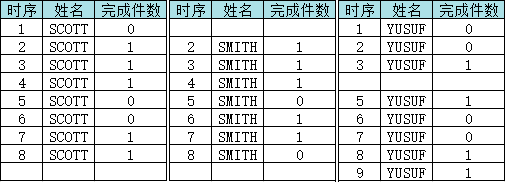


SQL> WITH sbq AS2 (SELECT time_seq3 ,complete_qty4 ,row_number() over(ORDER BY complete_qty, time_seq) rn5 FROM demo_completion6 WHERE ename = 'SCOTT')7 SELECT time_seq, complete_qty, time_seq - rn p FROM sbq ORDER BY time_seq;TIME_SEQ COMPLETE_QTY P---------- ------------ ----------1 0 02 1 -23 1 -24 1 -25 0 36 0 37 1 08 1 0
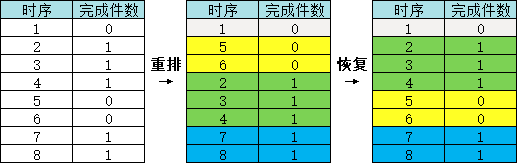
观察 P 列结果,我们发现:时序 2、3、4 的记录和 5、6 的记录已经被成功分离,但是 1 和 7、8 虽然完成件数不同,仍然 P 值相同,所以我们最终分组的依据还不能仅用 P 值,需要结合完成件数和 P 值来分组
SQL> WITH sbq AS2 (SELECT time_seq3 ,complete_qty4 ,time_seq - row_number() over(ORDER BY complete_qty, time_seq) p5 FROM demo_completion6 WHERE ename = 'SCOTT')7 SELECT time_seq8 ,complete_qty9 ,p10 ,SUM(complete_qty) over(PARTITION BY complete_qty, p ORDER BY time_seq) msum_cq11 FROM sbq12 ORDER BY time_seq;TIME_SEQ COMPLETE_QTY P MSUM_CQ---------- ------------ ---------- ----------1 0 0 02 1 -2 13 1 -2 24 1 -2 35 0 3 06 0 3 07 1 0 18 1 0 2
看到这里就有机谨的小伙伴要问了:难道能保证不会出现跨越分布的同值的“完成件数”小组对应一致的 P 值吗?出现这种情况不就将跨越分布的小组合到一起计算累计值了吗?

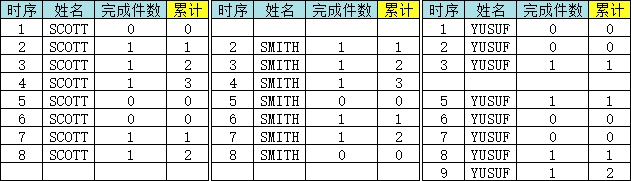
SQL> WITH sbq AS2 (SELECT time_seq3 ,ename4 ,complete_qty5 ,time_seq - row_number() over(PARTITION BY ename ORDER BY complete_qty, time_seq) p6 FROM demo_completion)7 SELECT time_seq8 ,ename9 ,complete_qty10 ,SUM(complete_qty) over(PARTITION BY ename, complete_qty, p ORDER BY time_seq) msum_cq11 FROM sbq12 ORDER BY ename, time_seq;TIME_SEQ ENAME COMPLETE_QTY MSUM_CQ---------- ----- ------------ ----------1 SCOTT 0 02 SCOTT 1 13 SCOTT 1 24 SCOTT 1 35 SCOTT 0 06 SCOTT 0 07 SCOTT 1 18 SCOTT 1 22 SMITH 1 13 SMITH 1 24 SMITH 1 35 SMITH 0 06 SMITH 1 17 SMITH 1 28 SMITH 0 01 YUSUF 0 02 YUSUF 0 03 YUSUF 1 15 YUSUF 1 16 YUSUF 0 07 YUSUF 0 08 YUSUF 1 19 YUSUF 1 2


文章转载自SQL干货分享,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
