




前言
大家好,今天我们来学习布隆索引。
Bloom filter
在介绍布隆索引之前,我们先简单的说一下布隆过滤。
布隆过滤的最大作用就是检查一个元素是否存在于某个集合当中,特别是一个庞大的集合。如果没有布隆过滤,就需要将庞大的集合加载到内存当中进行检查。所以Burton Howard Bloom发明了Bloom Filter算法,它的优势是只需要占用很小的内存空间,就可以提供高效的查询效率。但是缺点嘛?就是有一定的误判和还有删除困难。
我们从https://www.jasondavies.com/bloomfilter/
这个网站提供的demo,来了解一下布隆过滤的简单原理。
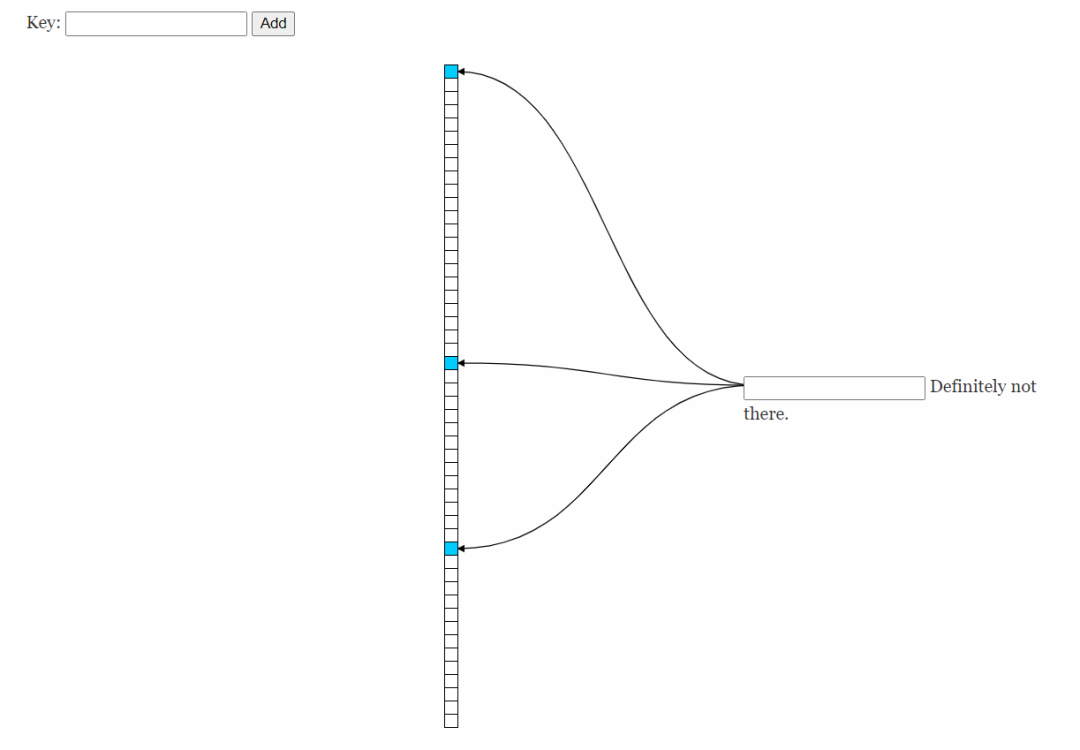
BloomFilter是由一个固定大小的二进制向量或者位图(bitmap)和一系列映射函数组成的。如上图所示,我们中间这一竖列就是二进制向量。作者这里的向量长度为m(此处设计如上图所示是50个白色格子)。
向布隆过滤器添加一个值,它会提供k个不同的hash函数(这个例子作者设置的是3个)。比如我往里面添加值1,2,3他们就会如下图所示。
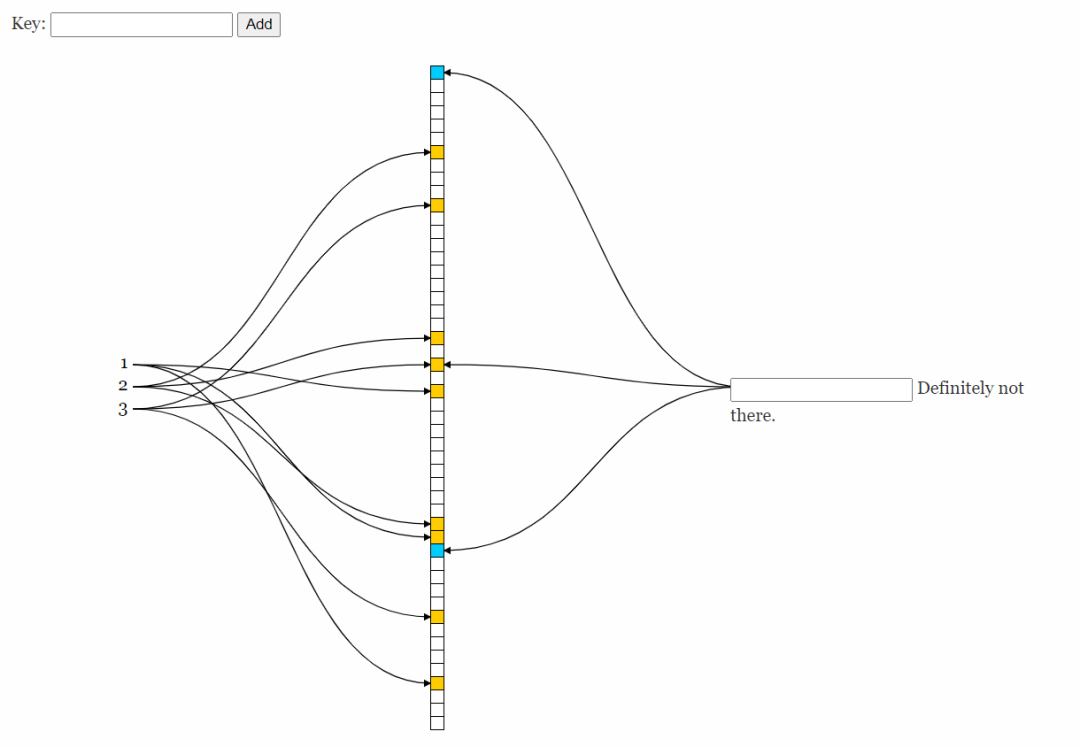
这样数据添加完成之后,1,2,3三个数据在内存中都相当于有了映射。如果我要查找1在不在集合中,只需要对1这个数据做三个hash函数运算,运算结果和二进制向量的位置一致,那就代表这个数字在集合当中了。
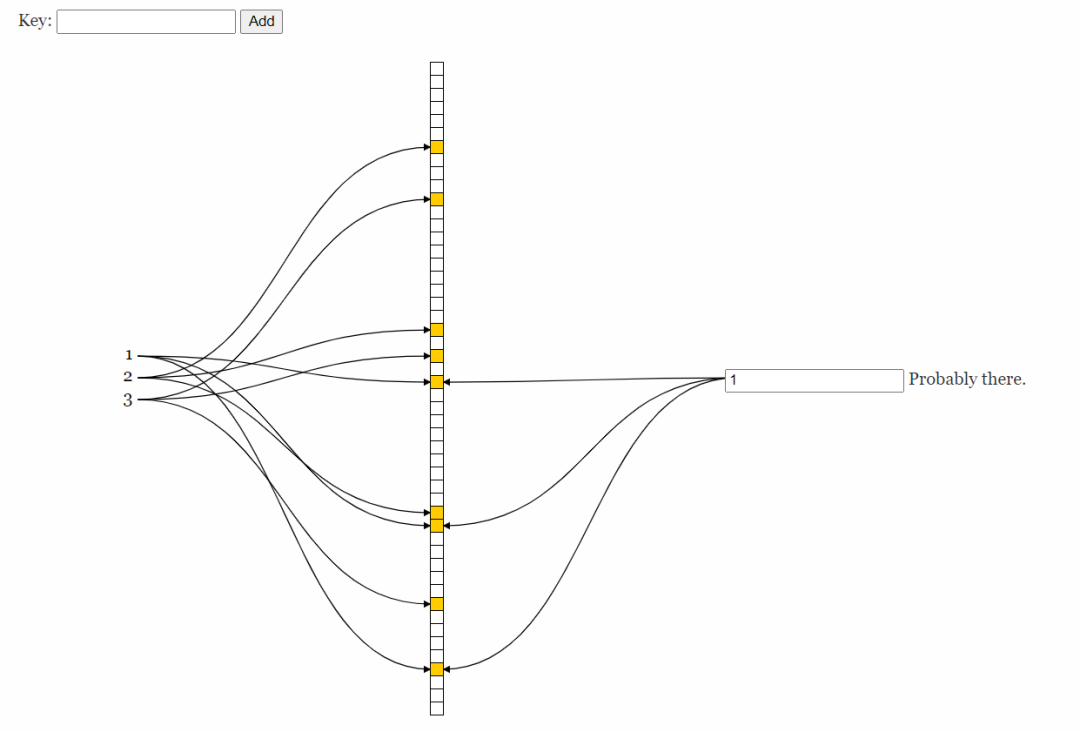
前面也说过,它也是有缺点的,就是误判,
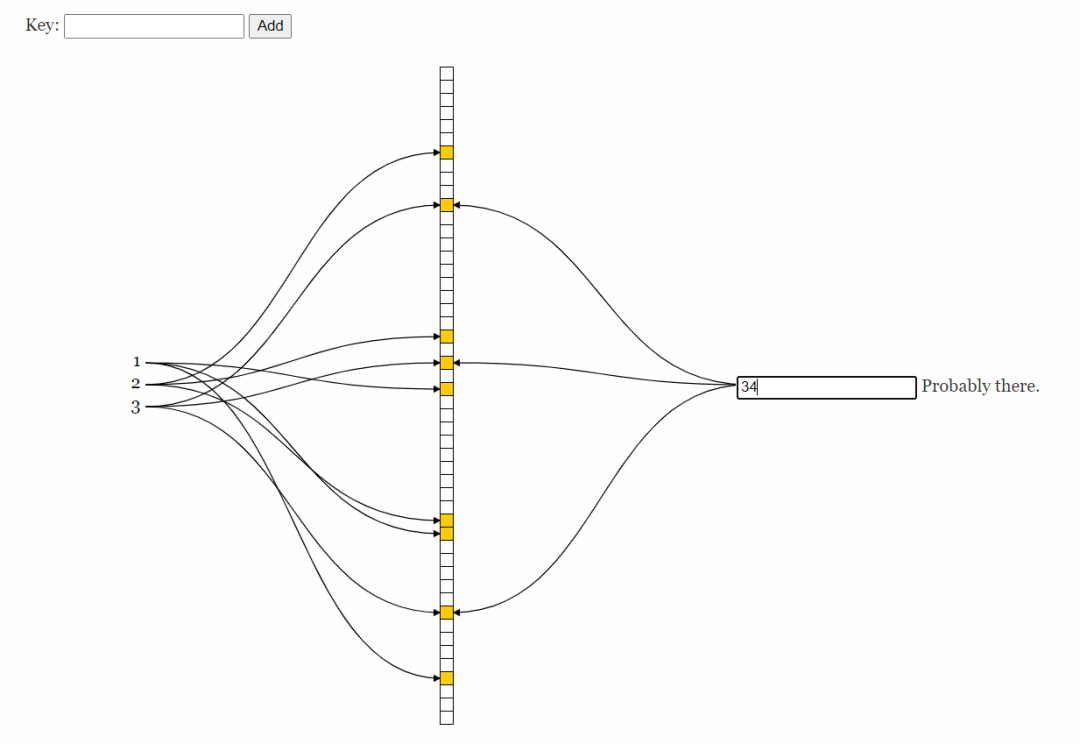
比如34这个值,就和我们的3是一致的。随着存入的元素数量增加,误判率也会随之增加。
PostgreSQL中的布隆索引
和布隆过滤的机制类似,当您有一个包含太多列的表,并且在这些表上使用太多列组合(作为谓词)的查询时,您可能需要很多索引。维护如此多的索引不仅对数据库来说成本高昂,而且在处理更大的数据集时也是一个定时炸弹。因此,如果您在所有这些列上创建一个布隆索引,则会为每一列计算一个哈希值,并将其合并到每行/记录的指定长度的单个索引条目中。当您指定需要布隆过滤器的列表时,您还可以选择每列需要设置多少位。
我们来实际测试一下,我采用的是cybertec的案例。
首先创建一张车辆信息表,并插入500万的数据。
create table vehicle (id bigserial primary key,brand_code int not null, -- n_distinct 200, imagine “brand_code”=0 => “Audi”model_code int not null, -- n_distinct 25, “model_code”=0 => “Q7”color_code int not null, -- n_distinct 25, “color_code”=0 => “silver” etc...year int not null, -- n_distinct 26body_type_code int not null, -- n_distinct 10doors int not null, -- n_distinct 5seats int not null, -- n_distinct 9gearbox_code int not null, -- n_distinct 3fuel_type_code int not null, -- n_distinct 10aircon_type_code int not null -- n_distinct 4);insert into vehicle (brand_code, model_code, color_code, year, body_type_code, doors, seats, gearbox_code, fuel_type_code, aircon_type_code)selectrandom()*200, --brandrandom()*25, --modelrandom()*25, --colorrandom()*26 + 1990, --yearrandom()*10, --body_typerandom()*4 + 1, --doorsrandom()*8 + 1, --seatsrandom()*3, --gearboxrandom()*10, --fuelrandom()*4 --airconfromgenerate_series(1, 5*1e6); test=# select count(1) from vehicle; count --------- 5000000(1 row)
我们分别来创建B树索引和布隆索引。
--普通B-Tree索引CREATE INDEX ON vehicle(brand_code, model_code);CREATE INDEX ON vehicle(color_code);CREATE INDEX ON vehicle(year);CREATE INDEX ON vehicle(body_type_code);CREATE INDEX ON vehicle(doors);CREATE INDEX ON vehicle(seats);CREATE INDEX ON vehicle(gearbox_code);CREATE INDEX ON vehicle(fuel_type_code);CREATE INDEX ON vehicle(aircon_type_code);--Bloom索引create extension bloom;CREATE INDEX bloom_80_bits ON vehicle USING bloom (brand_code,model_code,color_code,year,body_type_code,doors,seats,gearbox_code,fuel_type_code,aircon_type_code);
接下来我们运行查询测试,这个查询谓词条件很多。比如有汽车颜色的类型、汽车生产时间、门的类型、变速箱、空调类型等等
explain(ANALYZE,VERBOSE,BUFFERS) select * from vehicle where color_code = 12 and year > 2010and body_type_code = 5 and doors = 4 and gearbox_code = 2 and fuel_type_code = 5 and aircon_type_code = 2; Bitmap Heap Scan on public.vehicle (cost=21799.06..28346.67 rows=8 width=48) (actual time=128.535..131.658 rows=10 loops=1) Output: id, brand_code, model_code, color_code, year, body_type_code, doors, seats, gearbox_code, fuel_type_code, aircon_type_code Recheck Cond: ((vehicle.color_code = 12) AND (vehicle.body_type_code = 5) AND (vehicle.fuel_type_code = 5)) Filter: ((vehicle.year > 2010) AND (vehicle.doors = 4) AND (vehicle.gearbox_code = 2) AND (vehicle.aircon_type_code = 2)) Rows Removed by Filter: 2027 Heap Blocks: exact=1988 Buffers: shared hit=5274 -> BitmapAnd (cost=21799.06..21799.06 rows=1953 width=0) (actual time=127.589..127.591 rows=0 loops=1) Buffers: shared hit=3286 -> Bitmap Index Scan on vehicle_color_code_idx (cost=0.00..3822.43 rows=206667 width=0) (actual time=30.896..30.897 rows=200179 loops=1) Index Cond: (vehicle.color_code = 12) Buffers: shared hit=550 -> Bitmap Index Scan on vehicle_body_type_code_idx (cost=0.00..8897.19 rows=481167 width=0) (actual time=49.711..49.712 rows=499306 loops=1) Index Cond: (vehicle.body_type_code = 5) Buffers: shared hit=1367 -> Bitmap Index Scan on vehicle_fuel_type_code_idx (cost=0.00..9078.93 rows=491000 width=0) (actual time=41.284..41.284 rows=499693 loops=1) Index Cond: (vehicle.fuel_type_code = 5) Buffers: shared hit=1369 Planning Time: 0.770 ms Execution Time: 131.705 ms
优化器的选择非常聪明。使用了三个索引进行位图扫描,然后做bitmapand操作。
drop index vehicle_year_idx;drop index vehicle_seats_idx;drop index vehicle_gearbox_code_idx;drop index vehicle_fuel_type_code_idx;drop index vehicle_doors_idx;drop index vehicle_color_code_idx;drop index vehicle_brand_code_model_code_idx;drop index vehicle_body_type_code_idx;drop index vehicle_aircon_type_code_idx;
我们把其他索引都删除,再次测试,记住一定要把并行参数max_parallel_workers_per_gather关闭,不然它会使用并行全表扫描。
test=# set max_parallel_workers_per_gather=0;Bitmap Heap Scan on public.vehicle (cost=109804.96..109847.09 rows=9 width=48) (actual time=67.400..67.580 rows=10 loops=1) Output: id, brand_code, model_code, color_code, year, body_type_code, doors, seats, gearbox_code, fuel_type_code, aircon_type_code Recheck Cond: ((vehicle.color_code = 12) AND (vehicle.body_type_code = 5) AND (vehicle.doors = 4) AND (vehicle.gearbox_code = 2) AND (vehicle.fuel_type_code = 5) AND (vehicle.aircon_type_code = 2)) Rows Removed by Index Recheck: 29 Filter: (vehicle.year > 2010) Rows Removed by Filter: 35 Heap Blocks: exact=74 Buffers: shared hit=9878 -> Bitmap Index Scan on bloom_80_bits (cost=0.00..109804.96 rows=41 width=0) (actual time=67.344..67.345 rows=74 loops=1) Index Cond: ((vehicle.color_code = 12) AND (vehicle.body_type_code = 5) AND (vehicle.doors = 4) AND (vehicle.gearbox_code = 2) AND (vehicle.fuel_type_code = 5) AND (vehicle.aircon_type_code = 2)) Buffers: shared hit=9804 Planning Time: 0.209 ms Execution Time: 67.635 ms
这次我们使用了bloom索引。速度比上面快了一倍。而且这个索引的大小只有77mb,远远比刚刚那一堆索引要小。
test=# \di+ bloom_80_bits List of relations Schema | Name | Type | Owner | Table | Size | Description --------+---------------+-------+-------+---------+-------+------------- public | bloom_80_bits | index | root | vehicle | 77 MB | (1 row)
当然这里还有一点需要我们注意,bloom index过滤了74行出来了。但是最终查询出的结果是10行。因此有64行记录是误报.
(actual time=68.626..68.627 rows=74 loops=1)(actual time=68.684..68.866 rows=10 loops=1)
我们可以通过提高签名长度和每列的位数,让bloom index减少误报,但是缺点就是需要更多的存储空间。

随着签名长度和位数的增加,布隆索引的大小将不断地增加。这可以减少误报。如果因为布隆索引返回的误报数量而花费的时间更长,则可以增加长度,如果增加长度对性能没有太大影响,那么您可以保持长度不变。
后记
Bloom index的玩法基本上到此,本文只是简单体验一下。个人感觉非常适合那种OLAP场景中状态字段比较多的表。有兴趣的可以去读这篇文章:
Choosing PostgreSQL Bloom Index Parameters,
链接:http://blog.coelho.net/database/2016/12/11/postgresql-bloom-index.html
这里面的详细的讲述了一些很强大公式,来验证签名长度和位长度。
参考文献
1.https://www.cybertec-postgresql.com/en/trying-out-postgres-bloom-indexes/
2.https://www.percona.com/blog/2019/06/14/bloom-indexes-in-postgresql/
3.http://blog.coelho.net/database/2016/12/11/postgresql-bloom-index.html
